文章目录
- 函数介绍
- 实例
- Step1:整理数据
- Step2:挖掘频繁项集
- Step3:挖掘关联规则
- Step4:进一步筛选规则
作者:李雪茸
函数介绍
实现Apriori关联规则挖掘是借助mlxtend第三方包,使用步骤如下:
1、调用apriori算法挖掘频繁项集,apriori()中min_support也就是最小支持度,默认为0.5;
2、根据频繁项集,计算出它们的关联规则,使用association_rules()函数,如下
association_rules(df, metric=“confidence”,
min_threshold=0.8,
support_only=False)
参数介绍:
-
df:就是 apriori 计算后的频繁项集
-
metric:可选值有’support’,‘confidence’,‘lift’,‘leverage’,‘conviction’
-
min_threshold:参数类型是浮点型,根据 metric 不同可选值有不同的范围
-
support_only:默认是 False。仅计算有支持度的项集,若缺失支持度则用 NaNs 填充。
实例
Step1:整理数据
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder#编码
from mlxtend.frequent_patterns import apriori#Apriori
from mlxtend.frequent_patterns import association_rules#导入关联规则包
###数据准备,每一行为一位购物者的购物篮
dataset = [['牛奶','面包','鸡蛋'],
['牛奶','鸡蛋'],
['面包','鸡蛋','酸奶'],
['牛奶','酸奶']]
#进行 one-hot 编码
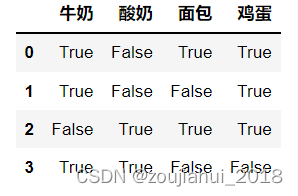
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
df
Step2:挖掘频繁项集
###挖掘频繁项集
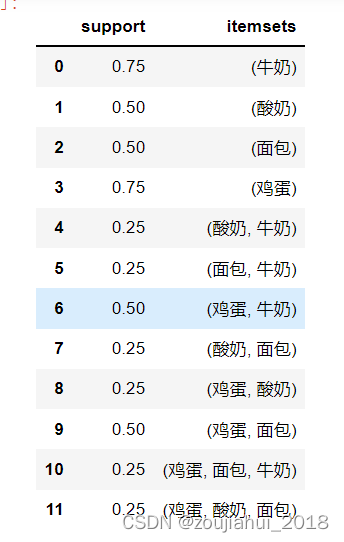
#利用 Apriori 的支持度找出频繁项集,阈值为0.2
freq = apriori(df, min_support=0.2, use_colnames=True)
freq
Step3:挖掘关联规则
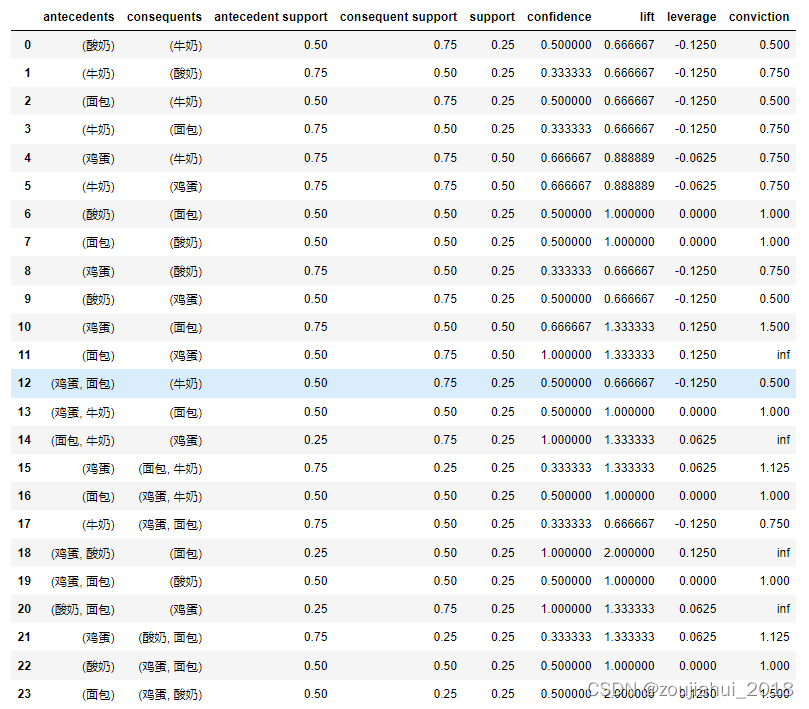
#挖掘关联规则
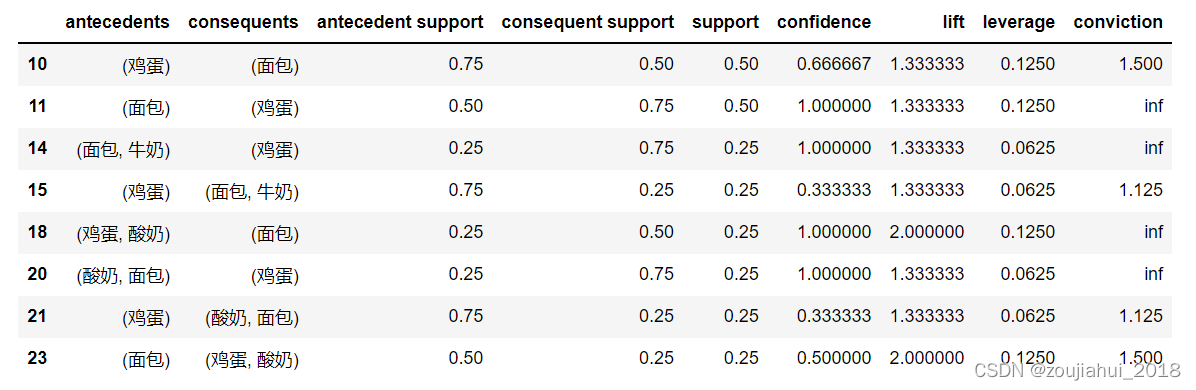
result = association_rules(freq, metric="lift", min_threshold=0.6)
result
Step4:进一步筛选规则
##利用兴趣因子(lift)筛选掉无意的规则
result[result["lift"]>1]








![[虚幻引擎][UE][UE5]在UE中画一个线框球,网格连接画球,高阶画球并操控](https://img-blog.csdnimg.cn/83bffe4796d54301b935daa86d88be73.png)