🔥博客主页: A_SHOWY
🎥系列专栏:力扣刷题总结录 数据结构 云计算
第一部分 创建实例过程
首先,需要创建3台EC2,一台作主节点 (master node),两台作从节点 (slaves node)。
1.镜像选择
EC2(弹性计算云):是AWS提供的最基本的云计算产品:虚拟专用服务器。这些“实例”可以运行大多数操作系统。
2.选择实例类型
实例类型这里我选择的t2.medium,虽然选择t2.micro或者t2.small可能便宜一些,但是性能和CPU运行速率相差较大,运用Hadoop会显得比较吃力。
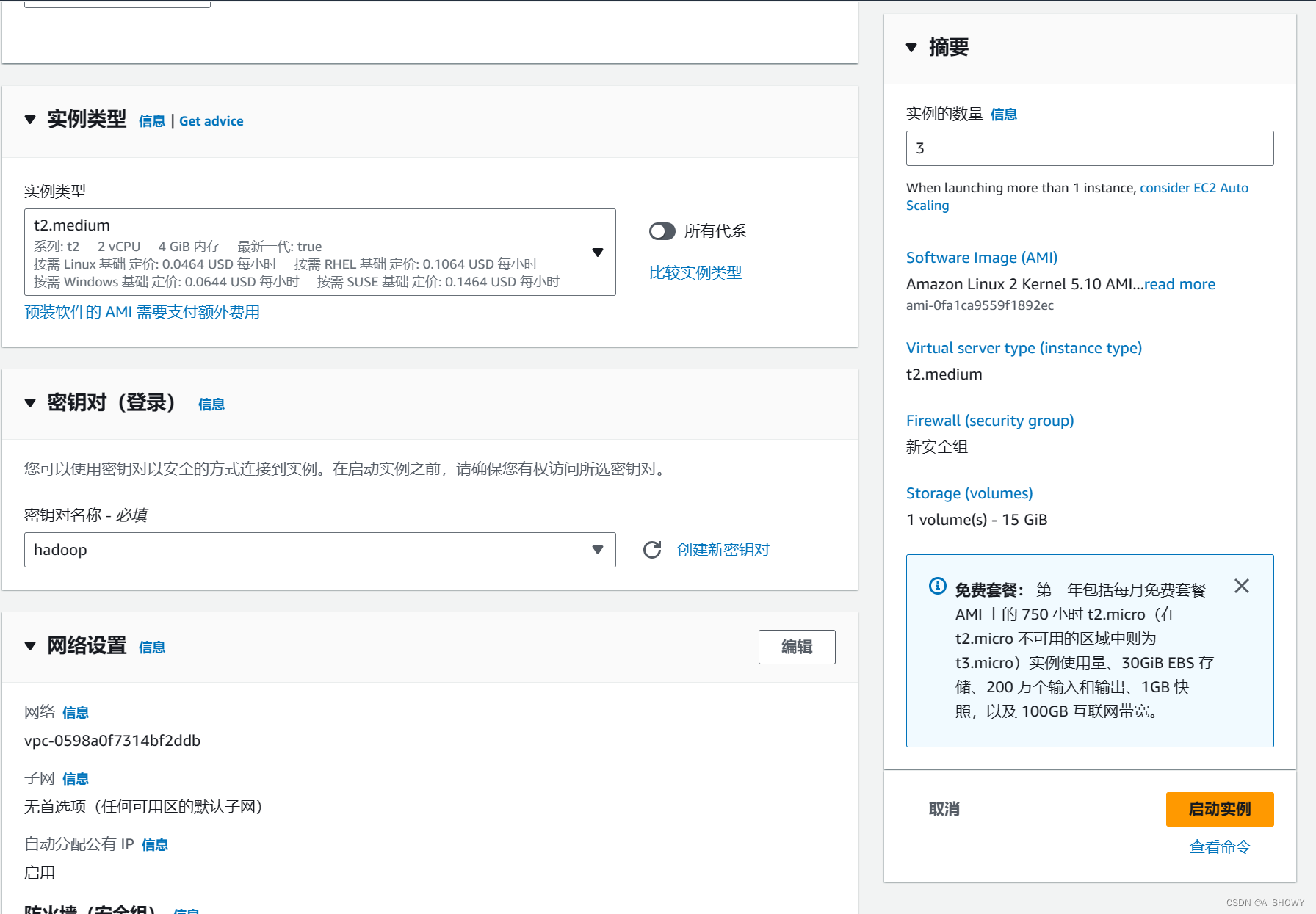
3.配置存储信息并设置实例数量
本次实验需要安装的文件大于8GiB,将默认的8GiB改成15GiB,由于需要创建3台EC2,一台作主节点 (master node),两台作从节点 (slaves node)。所以实例数量设置为3。
4.创建密钥对
密钥对名臣设置为hadoop,密钥对类型设置为RSA,私钥文件格式选择.pem(其实可以选择.ppk),由于面对EC2的操作我是用PuTTY来做的,所以将下载好的私钥还需通过PuTTYgen转换为.ppk格式。
成功创建SSH密钥对后:阿里云会保存SSH密钥对的公钥部分。自己需要下载并妥善保管私钥。当实例用公钥发送一段用于验证身份的密文,我们本地的SSH客户端便使用私钥将密文进行解密。
5.启动实例
实例创建成功
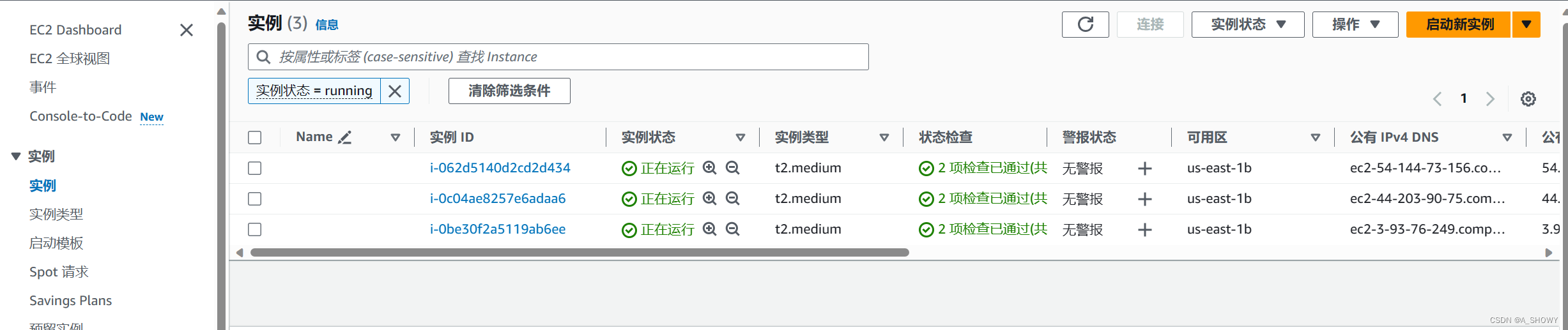
6.对三个实例进行重命名
一台作主节点 (master node),两台作从节点 (slaves node)。为了后续操作清晰进行,故三个实例分别命名为master、slave01、slave02。

第二部分 实例配置连接过程
1.配置PuTTY
启动实例后,需要对EC2实例进行环境配置,需要使用SSH软件来完成远程连接,可以使用tabby、Xshell、electerm,在这里我使用的是Putty,这款工具是款老牌工具,体积小,使用方便,功能强大。
下面我仅仅展示master的连接过程图,slave01和slave02的连接过程同master完全一致。
- 点击勾选master实例,从下方查看master实例的共有IPv4地址并复制。
- 打开PuTTY,在将复制的master的共有IPv4粘贴到Host Name一栏,并在Saved Sessions一栏中将名称改为master,点击load进行连接,然后点击save(这样可以保证在下次启动实例时可以点击名称直接连接相应的IPv4,当然重启实验,以及过了0点会让共有IPv4地址改变,此时需要从写在Host Name中重新粘贴新的IPv4地址并连接保存)
- 在PuTTYgen中将保存的.pem格式私密转为.ppk格式保存。
- 在Connection——SSH——Auth路径下,点击Browse,选择保存的私钥路径。
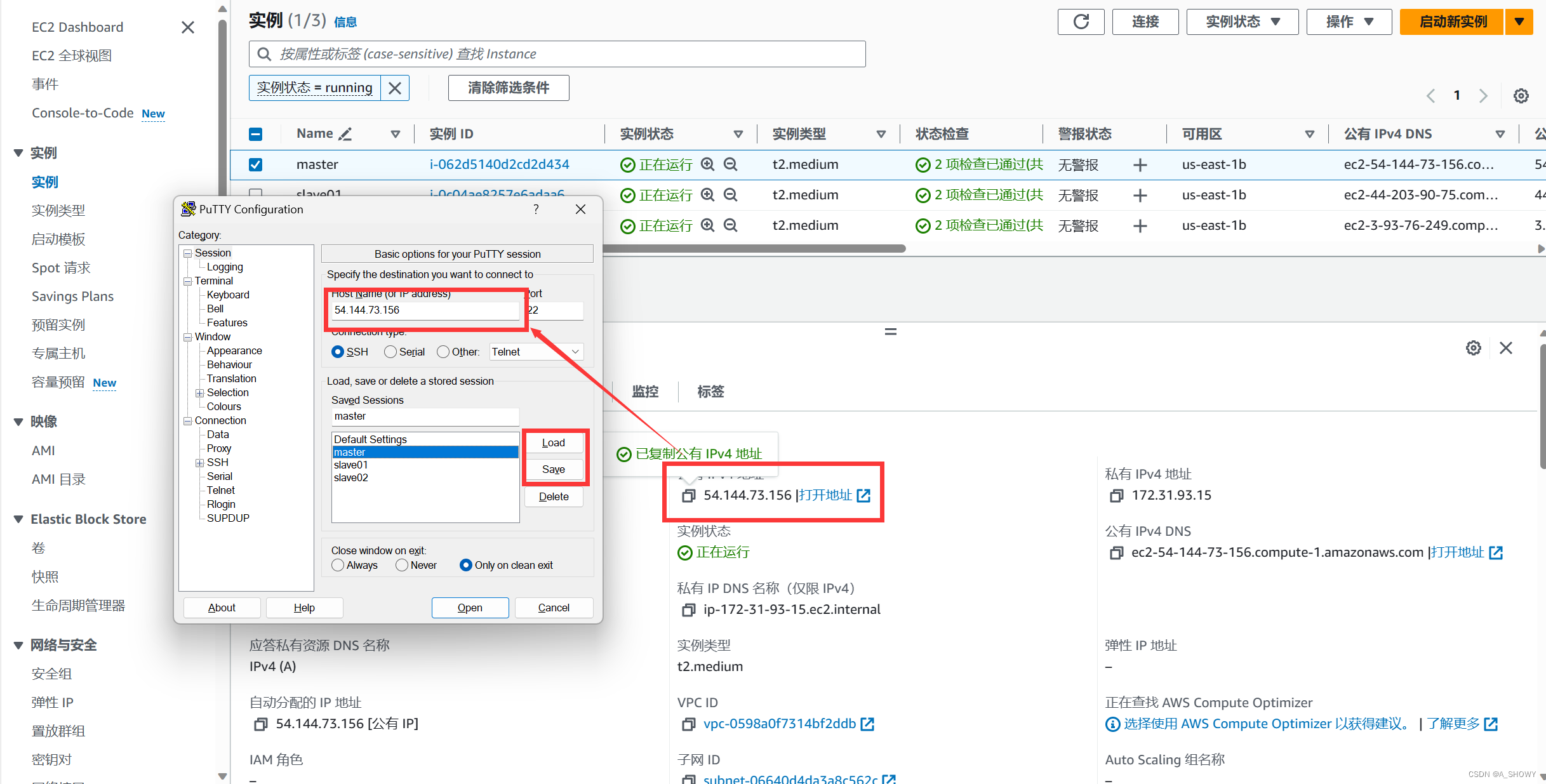

- 已经成功连接。
2.创建 hadoop 用户
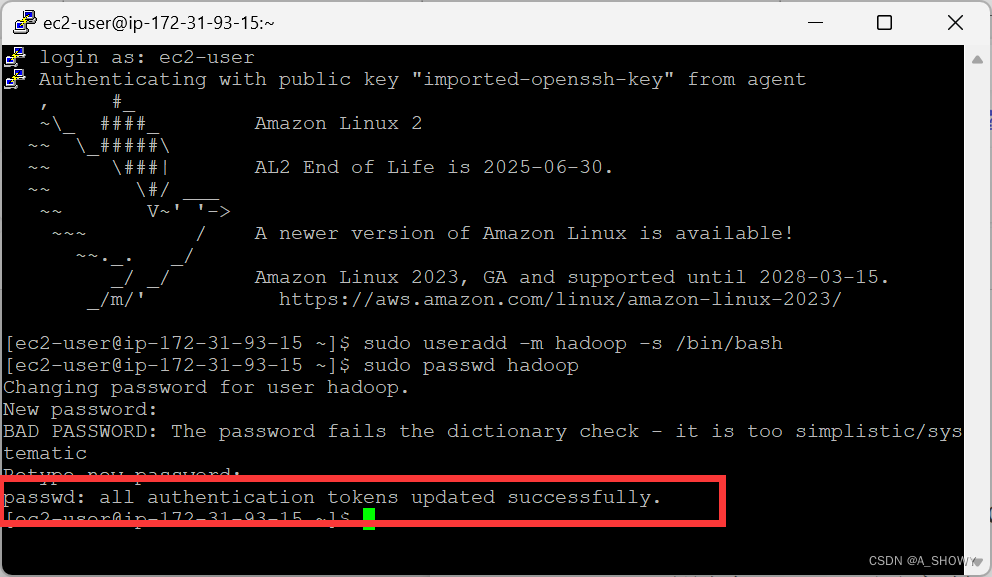
- sudo useradd -m hadoop -s /bin/bash//创建hadoop用户
- sudo passwd Hadoop//设置 hadoop 用户的密码,需要输入两遍
- sudo adduser hadoop sudo//为 hadoop 用户添加权限
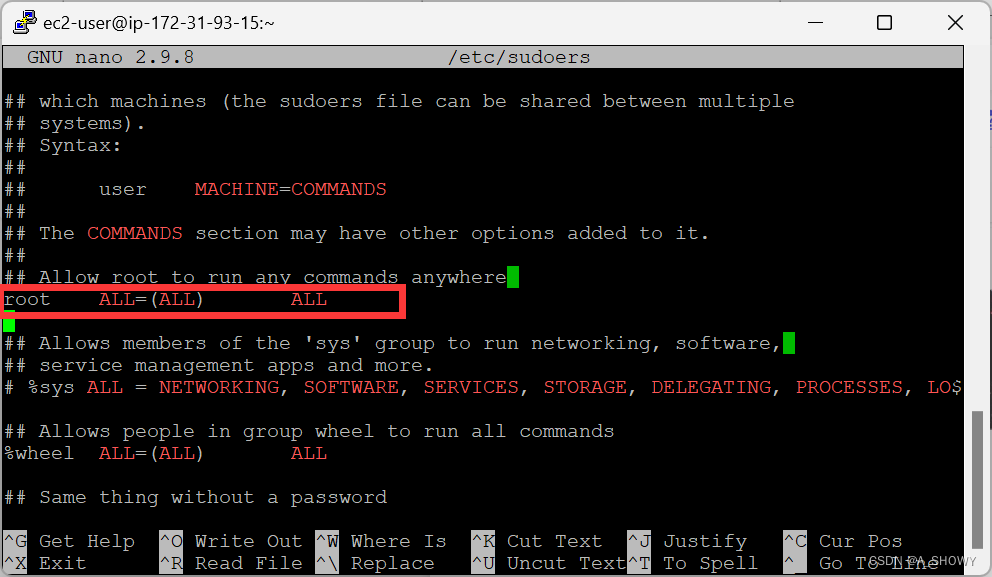
- sudo nano /etc/sudoers//打开权限相关文件
- 在root下面添加一条属于hadoop的权限

第三部分 安装JDK
- su hadoop//切换到 hadoop 用户
- sudo yum updateinfo//安装 updateinfo
- sudo yum install java-1.8.0-openjdk-devel.x86_64//指定安装版本
- 如果看到complete信息,则表明JDK安装成功
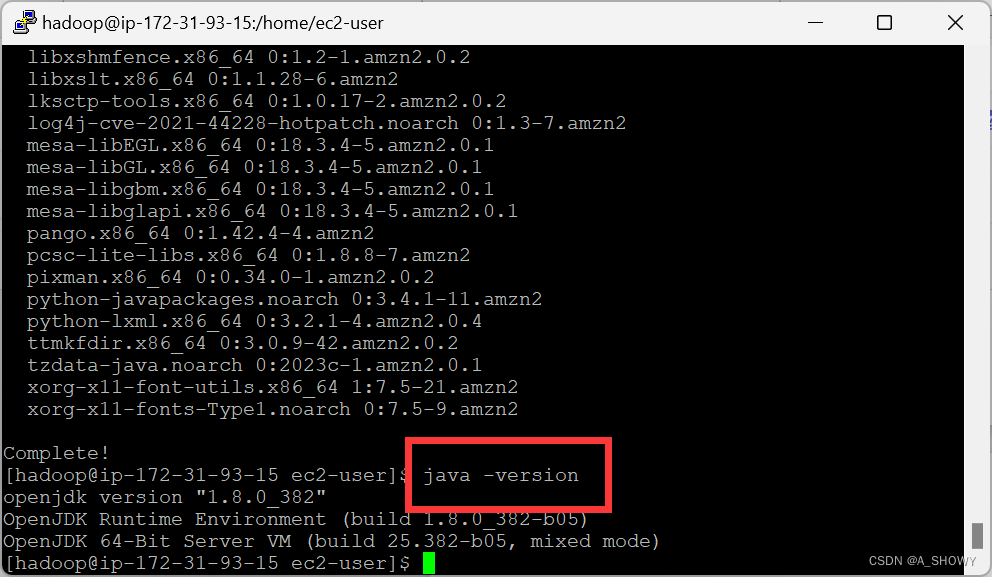
- java -version//查看java安装的版本

由于master、slave01、slave02的配置方法是一样的,故上述只以master为例。
第四部分 网络配置

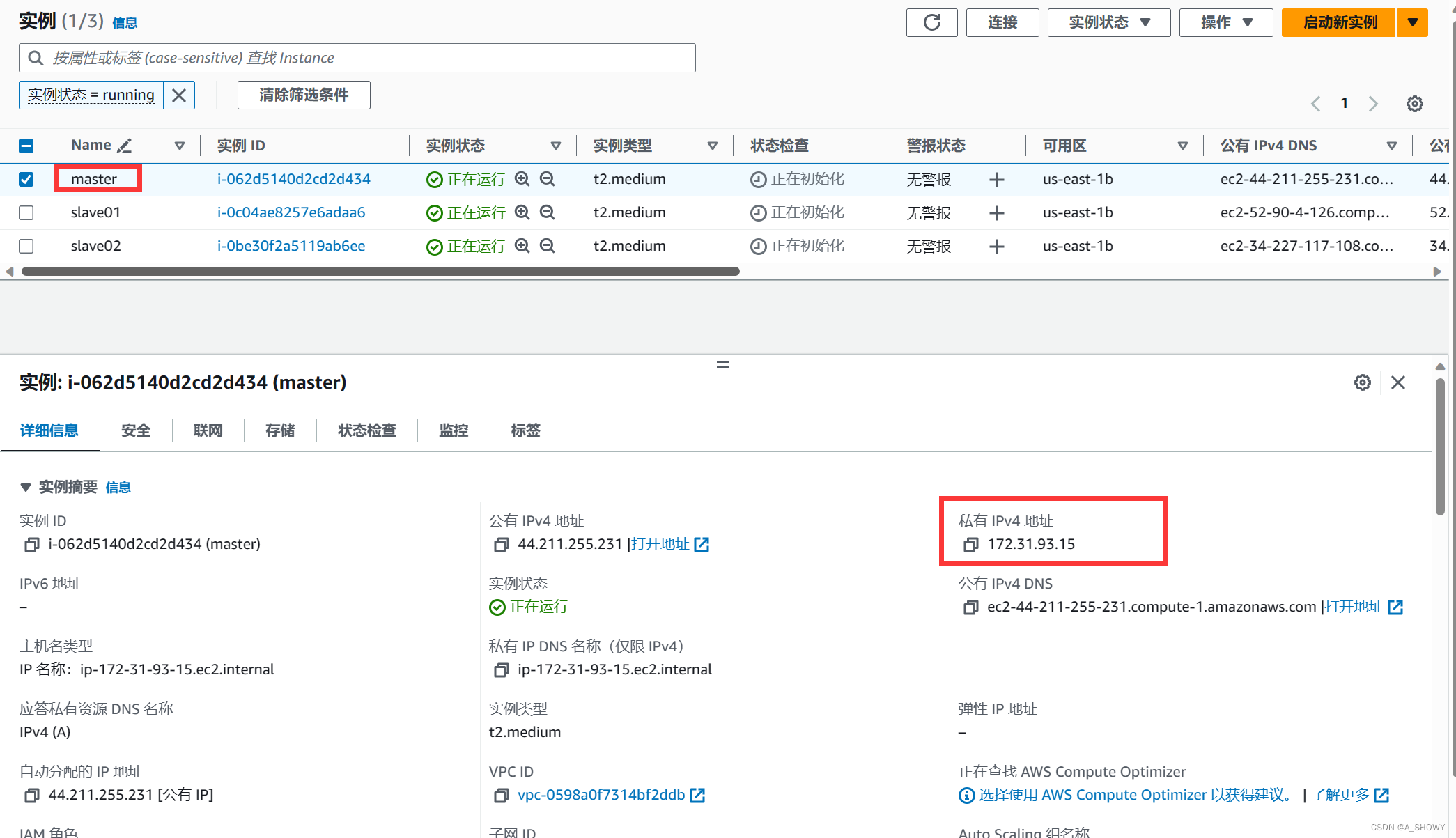
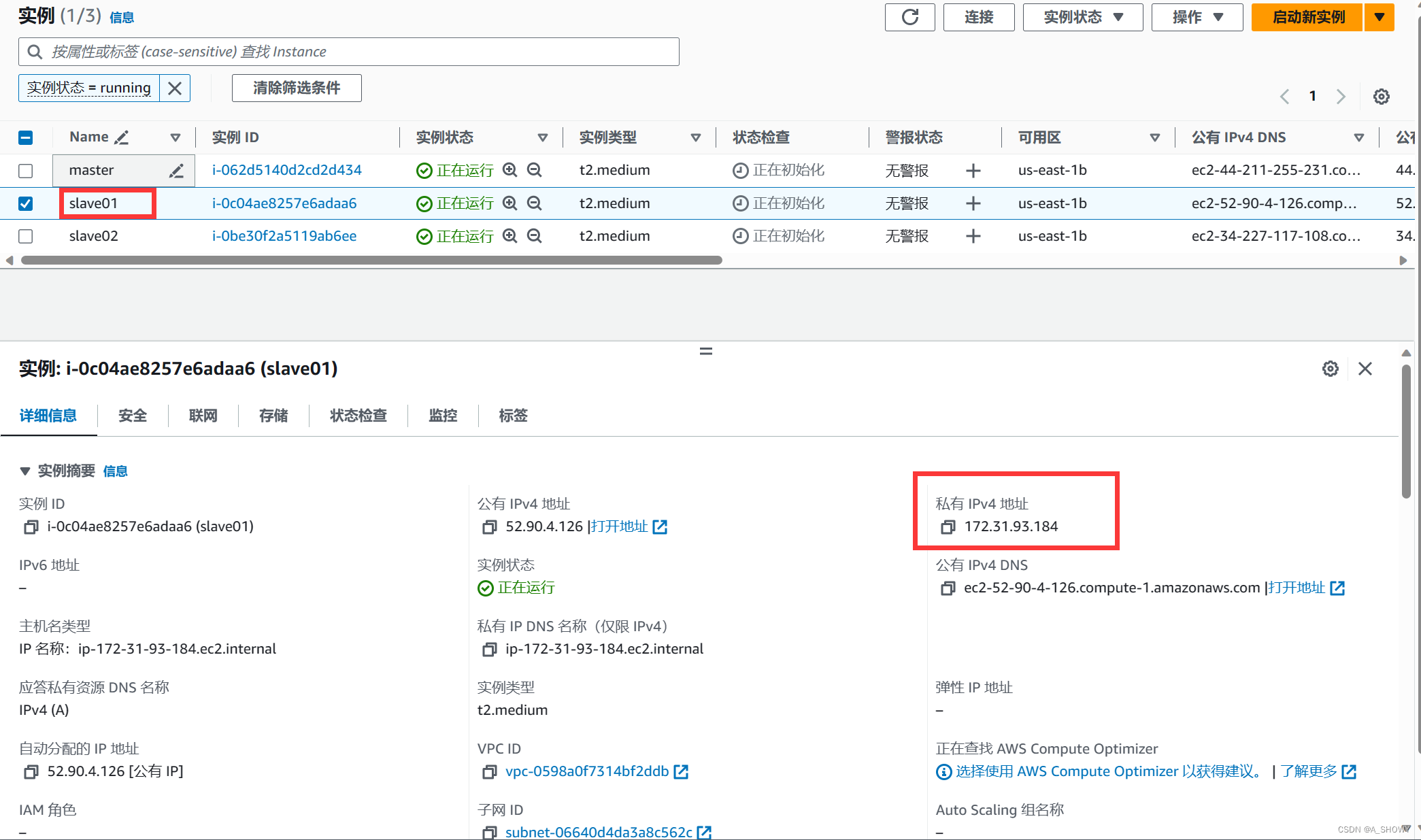
如果要想实现通过主机名进行通信,不需要记录对应的IP地址,需要将主机名和IP地址为组存入hosts中。这样的操作就可以避免了通多较为麻烦的局域网内的本地IP进行通信。从三个实例中找到三个实例的私有IP地址

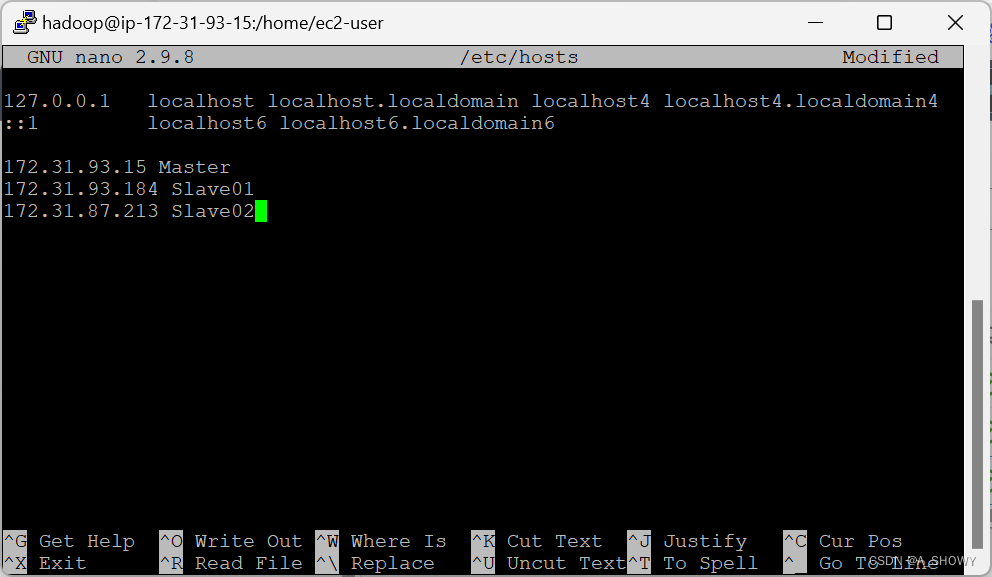

1.sudo nano /etc/hosts//修改hosts文件内容

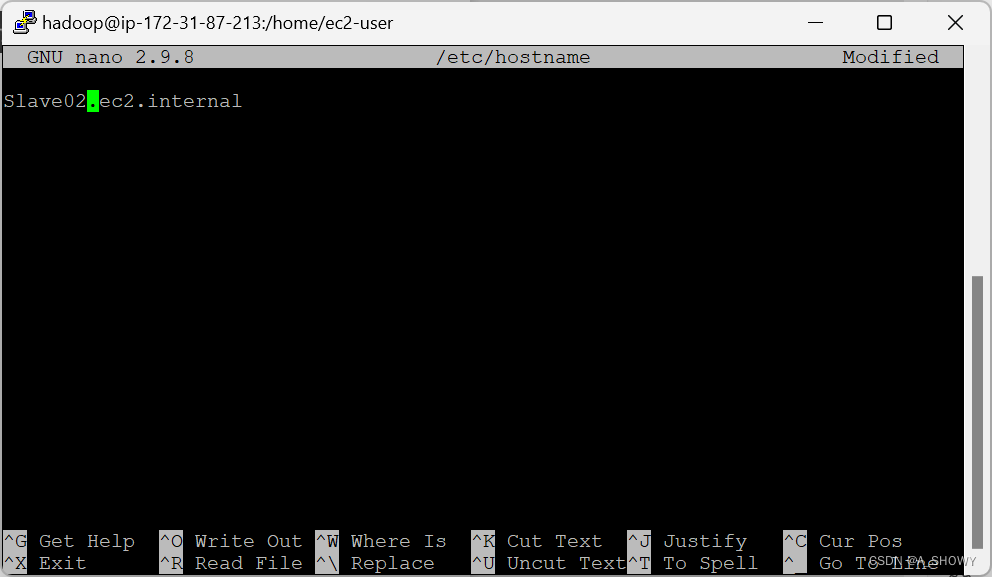

(slave01,slave02内容修改),可以看到将3个主机名和对应的IP地址都输入到了hosts文件内容中。
2.重启实例
3.设置安全组,使三台主机的通信不被拦截
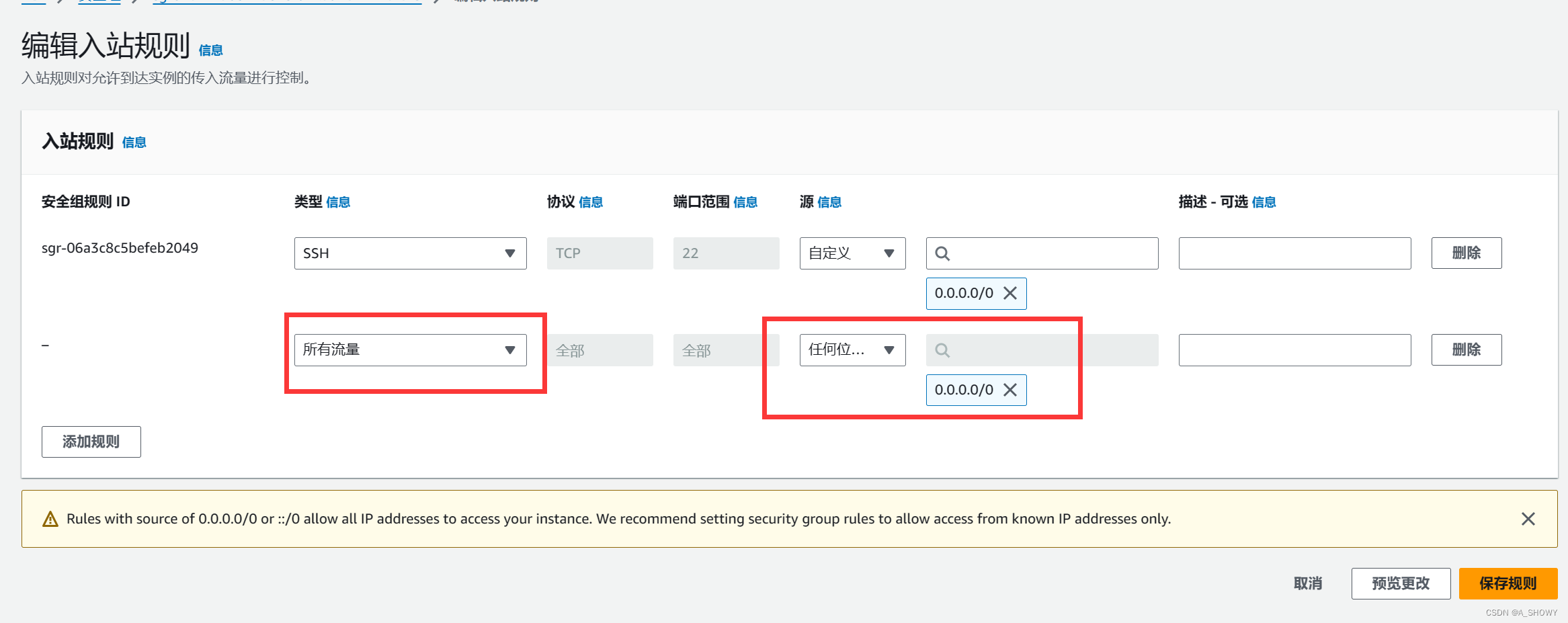
- 选择实例,选择安全,后选择安全组,选择编辑入站规则
- 编辑安全组类型选择所有流量,源选择任何位置的IPv4,保存规则
- 通过ping操作,测试主机之间的连通性
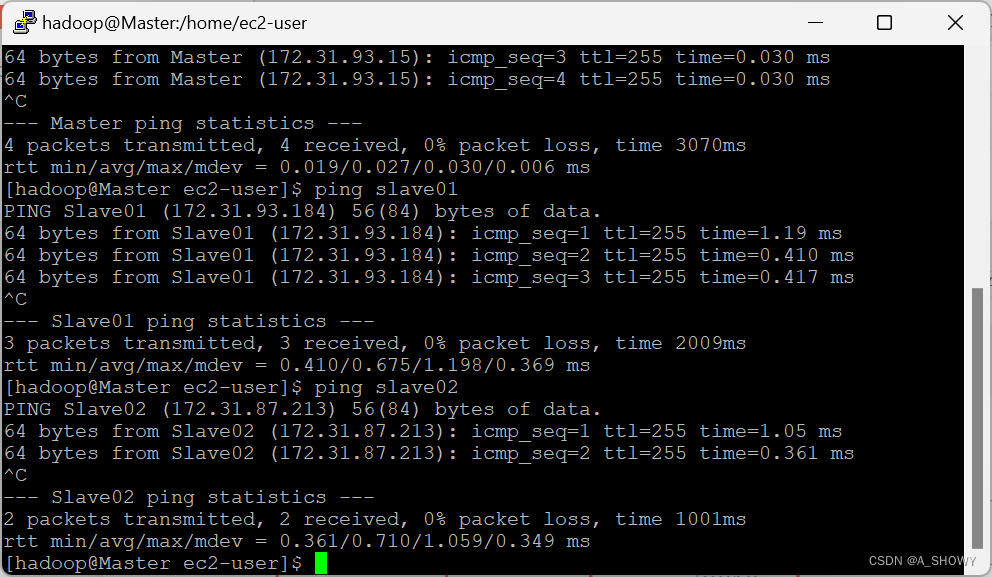
测试可知,Master主机ping Master是通的
测试可知,Master主机ping Slave01 是通的
测试可知,Master主机ping Slave02 是通的
同理,在Slave01主机和Slave02主机上分别ping包括自己的3台z主机都是通的
4.安装 SSH Server
切换到 Master 主机对应的 putty 界面,首先查看 ssh 目录是否存在,如果不存在就创建该目录。
- cd ~/.ssh/
mkdir ~/.ssh
- cd ~/.ssh/ //进入ssh目录


- 将密钥加入授权
cat ./id_rsa.pub >> ./authorized_keys
- 接下来切换到 Slave01 对应的 putty 界面
- cd ~/.ssh/
mkdir ~/.ssh
- cd ~ //返回用户主目录
- touch id_rsa.pub//创建 id_rsa.pub 文件
sudo nano id_rsa.pub//输入内容
- 打开 Master 对应的 putty 界面
cd ~/.ssh/ //进入 ssh 目录。
sudo vim id_rsa.pub //打开 id_rsa.pub 文件
- 复制其中的内容并粘贴到Slave01 对应的 putty 界面
- 在Slave2中完成相同的操作

- 在 Slave01 对应的 putty 界面中和 Slave02 对应的 putty 界面中分别输入:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
- 切换到 Master 主机对应的 putty 界面中输入
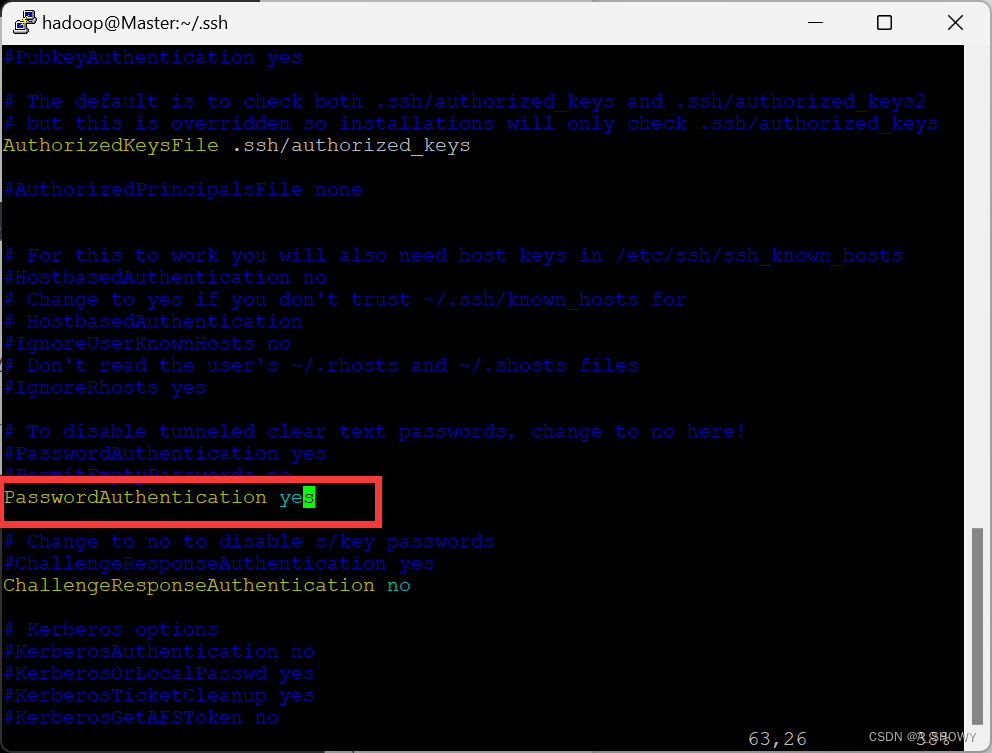
sudo vim /etc/ssh/sshd_config //打开文件
- 将 PasswordAuthentication no 改为 PasswordAuthentication yes
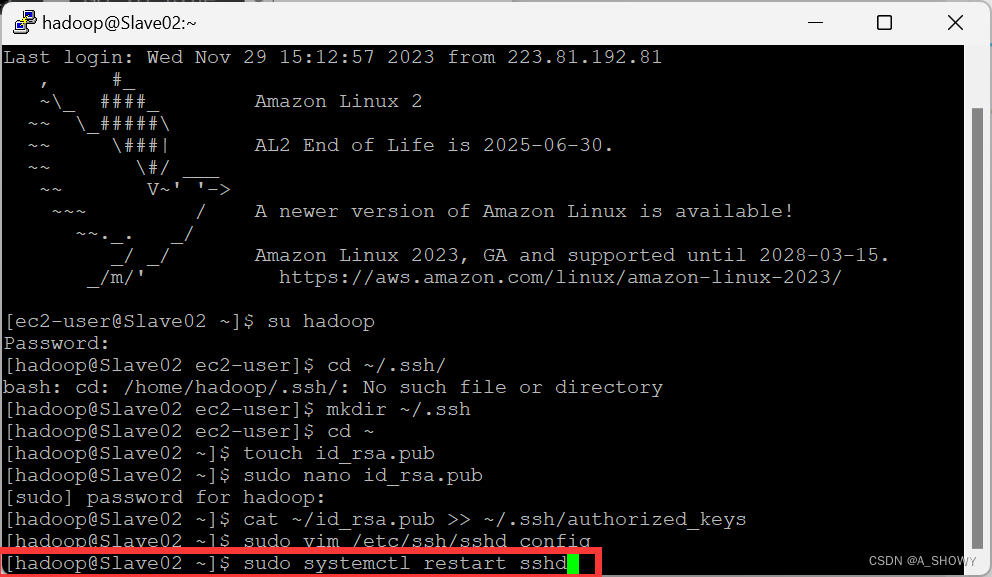
- 重新启动 sshd,检查是否能实现用户之间的切换,测试 ssh 是否配置成功。若能够完成用户之间的切换,表明配置成功,否则表明配置失败。
以下两图可以看出Master用户成功转换为Slave01,接着转换为Slave02,表面配置成功。
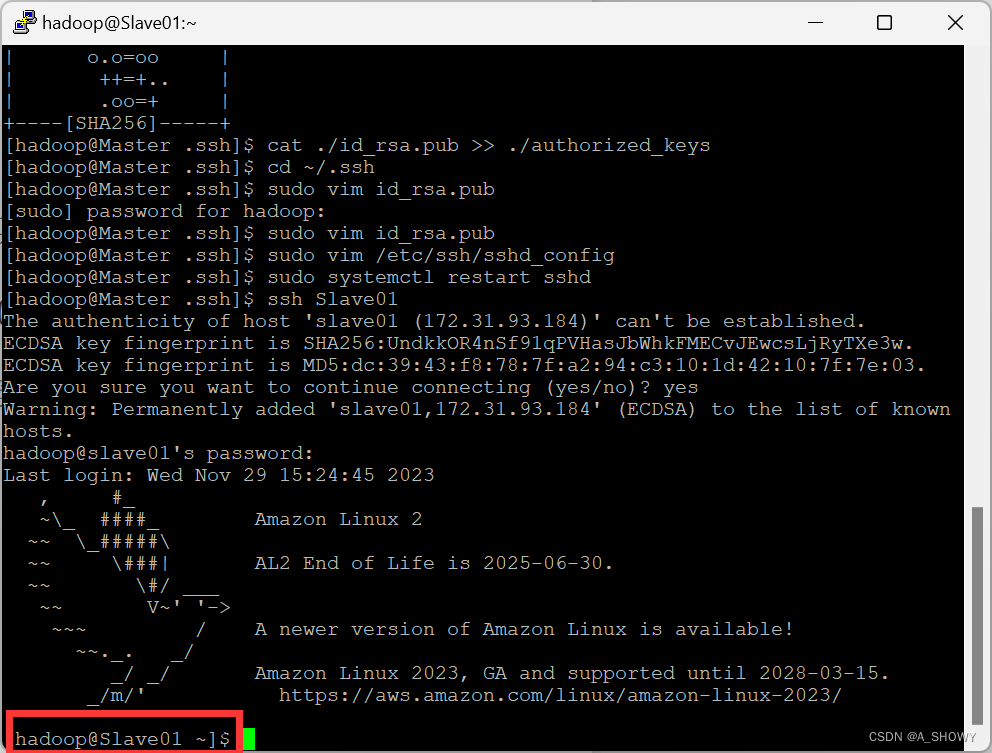
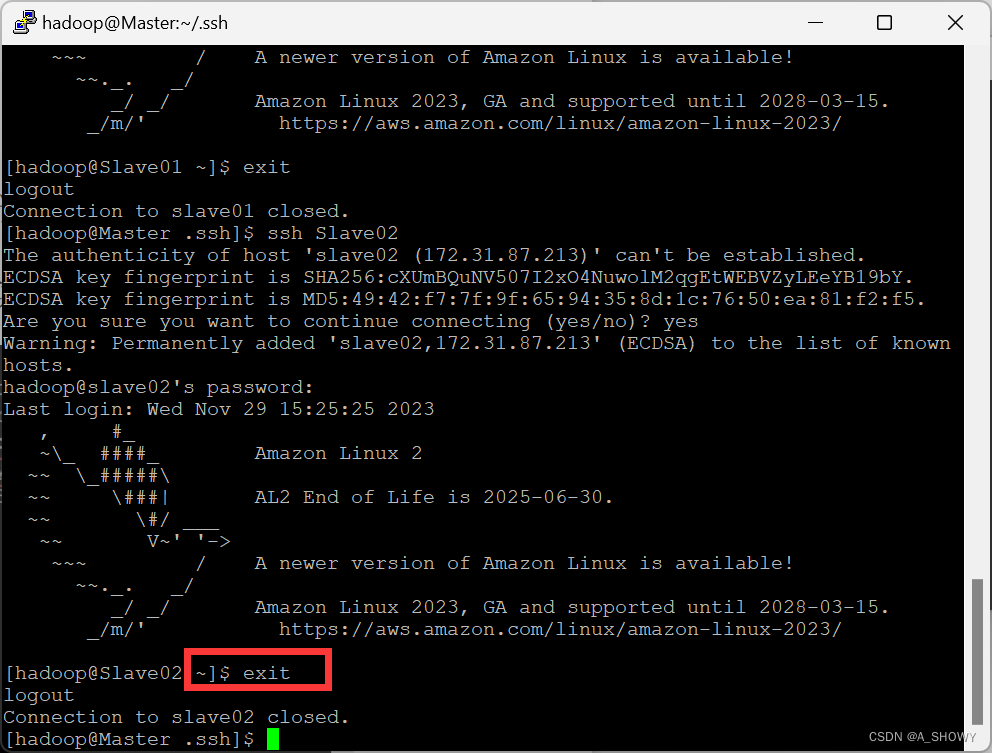
第五部分 安装Hadoop
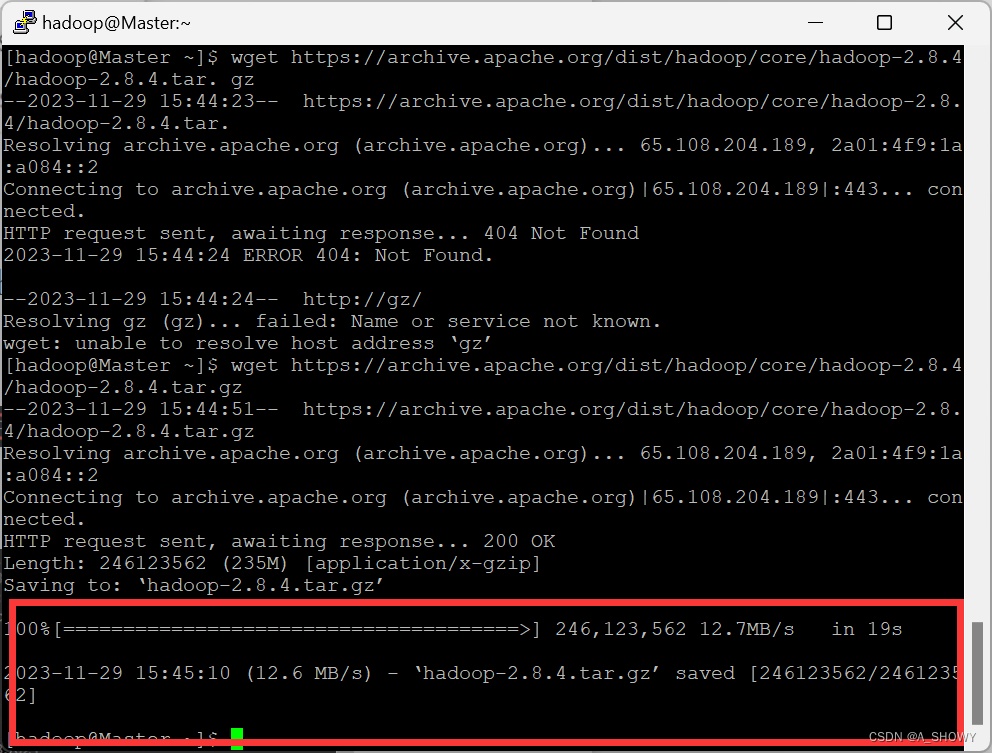
1.下载并安装Hadoop:出现以下提示表明下载成功。

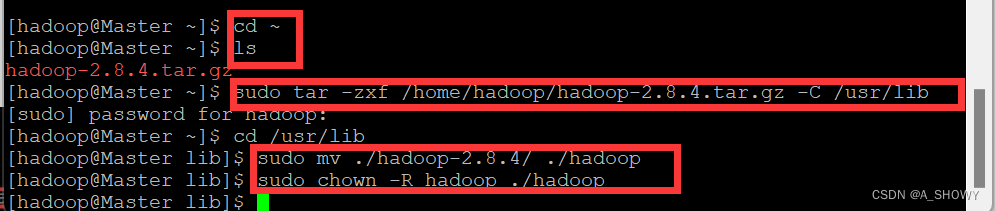
2.进入用户主目录,查看下载好的文件,并将其解压到/usr/lib,之后将文件夹名改为 hadoop,并修改 hadoop 用户对其的文件权限
- cd ~
ls - sudo tar -zxf /home/hadoop/hadoop-2.8.4.tar.gz -C /usr/lib
cd /usr/lib
sudo mv ./hadoop-2.8.4/ ./hadoop
sudo chown -R hadoop ./hadoop

3.修改环境变量文件
sudo nano ~/.bashrc //打开文件的原始内容
在文件中的末尾加上export PATH=$PATH:/usr/lib/hadoop/bin:/usr/lib/hadoop/sbin

- 配置文件使其生效
source ~/.bashrc
- 进入 hadoop 文件目录
cd /usr/lib/hadoop/etc/Hadoop
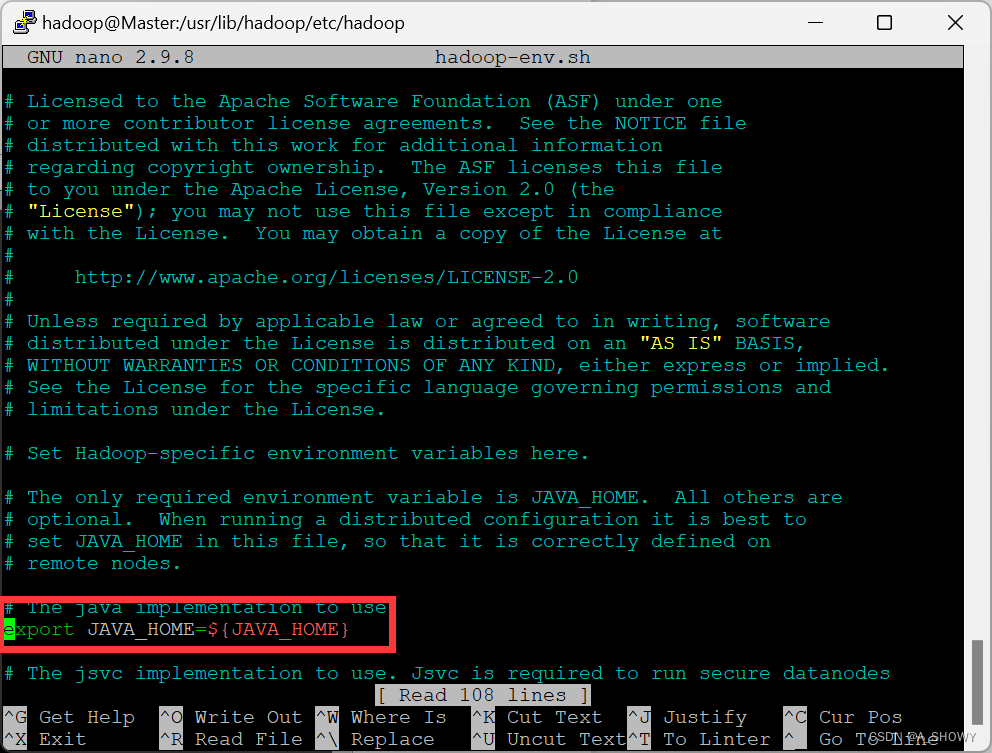
4.修改 hadoop-env.sh 文件
sudo nano hadoop-env.sh
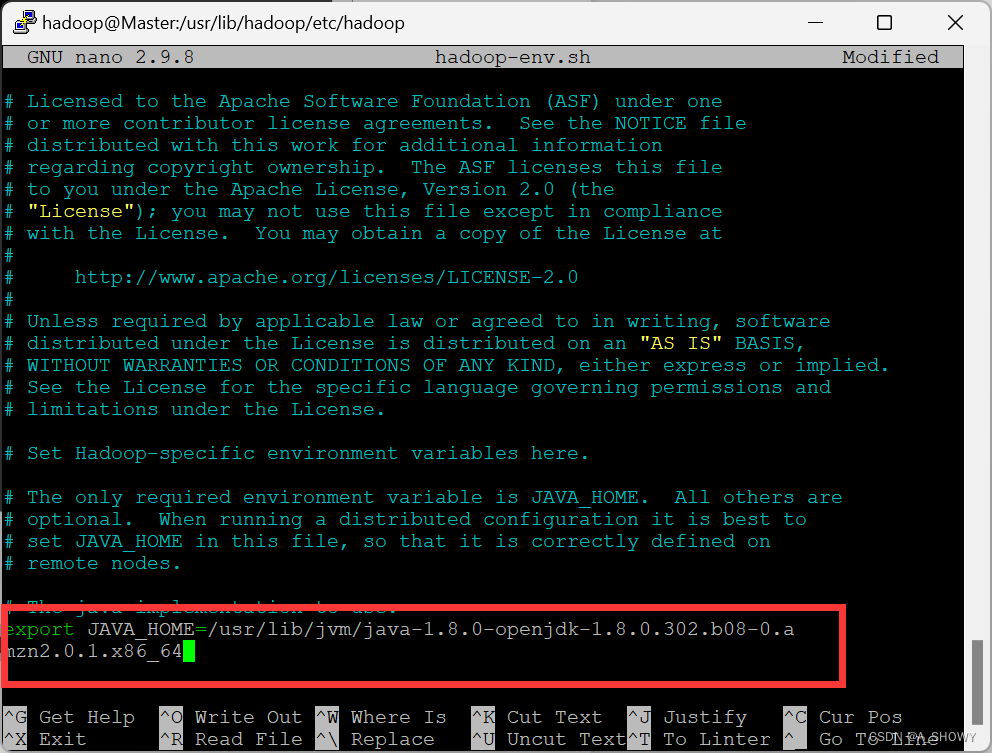
- 此时,可以通过java-bose找到自己的路径将这个路径设置到JAVA_Home中
根据查到的地址在文件中进行修改。
 5.修改slaves文件
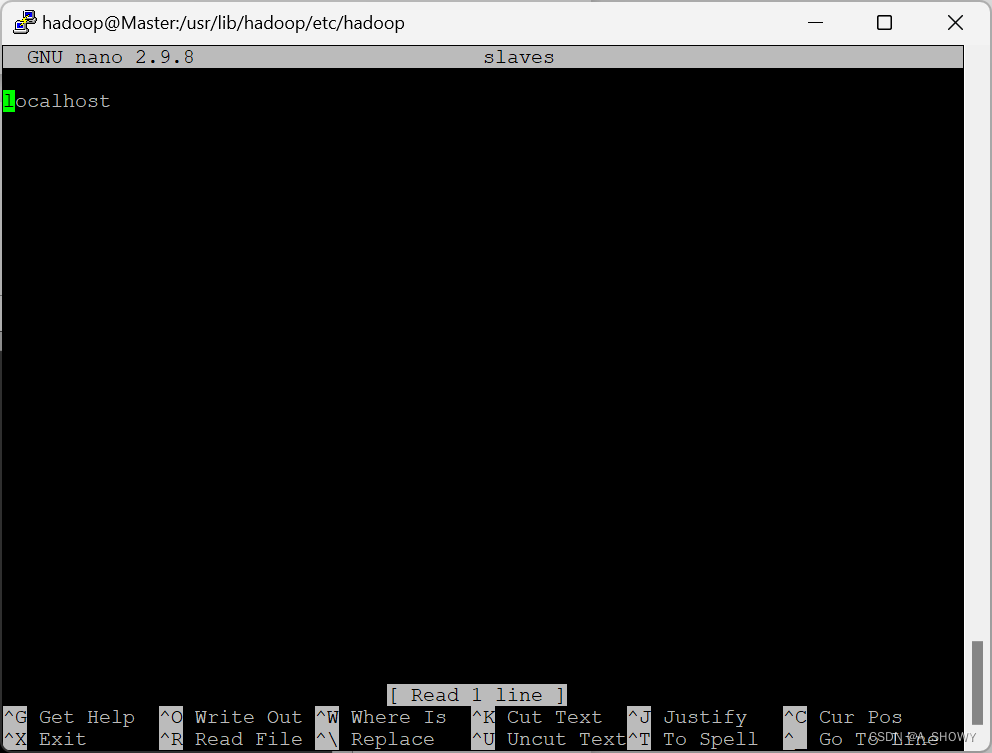
5.修改slaves文件
sudo nano slaves
修改后的内容如下
 6.修改 core-site.xml 文件
6.修改 core-site.xml 文件
sudo nano core-site.xml
替换成以下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/lib/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
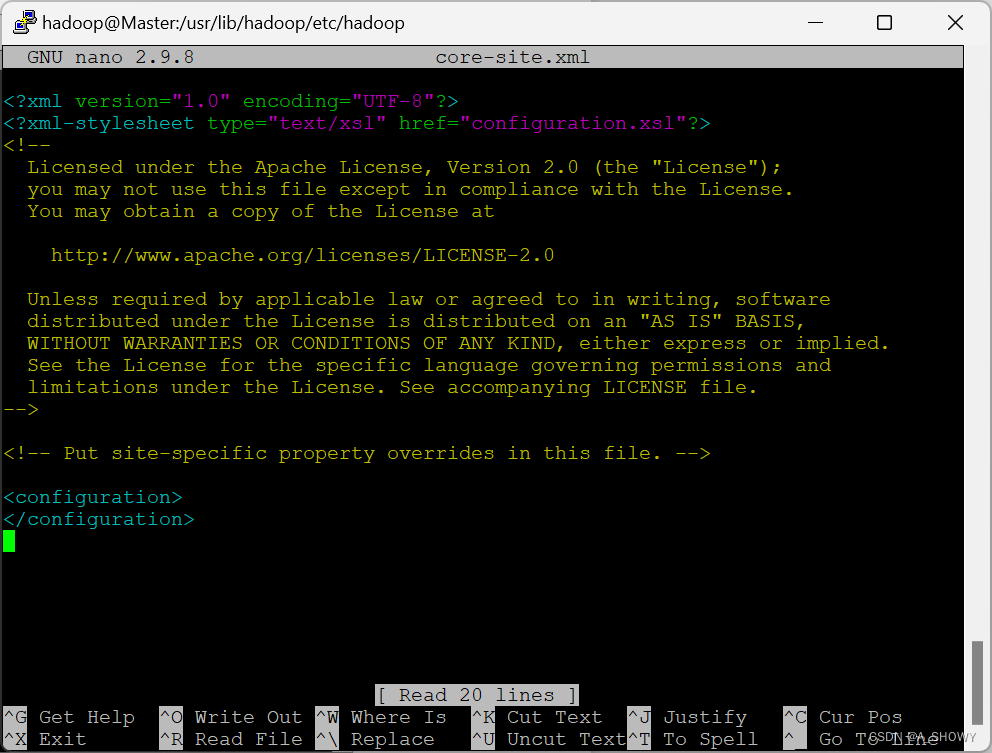 7.修改 hdfs-site.xml 文件
7.修改 hdfs-site.xml 文件
sudo nano hdfs-site.xml
将内容替换为
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/data</value>
</property>
</configuration>
 8.将mapred-site.xml.template改名为 mapred-site.xml并进行修改。
8.将mapred-site.xml.template改名为 mapred-site.xml并进行修改。
内容替换成
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
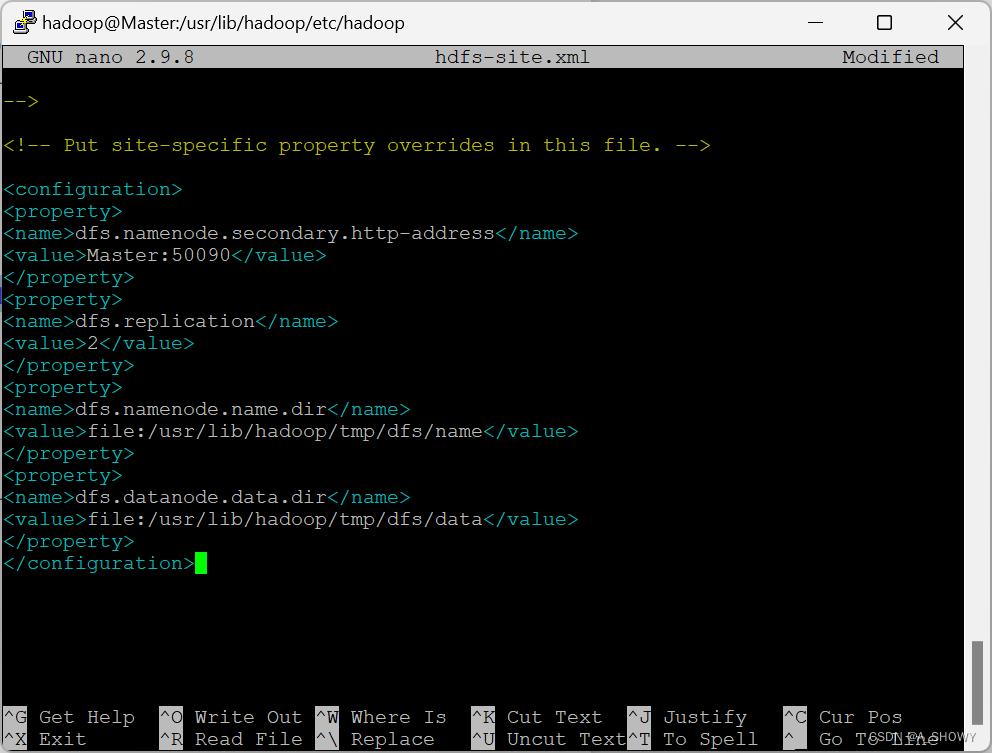
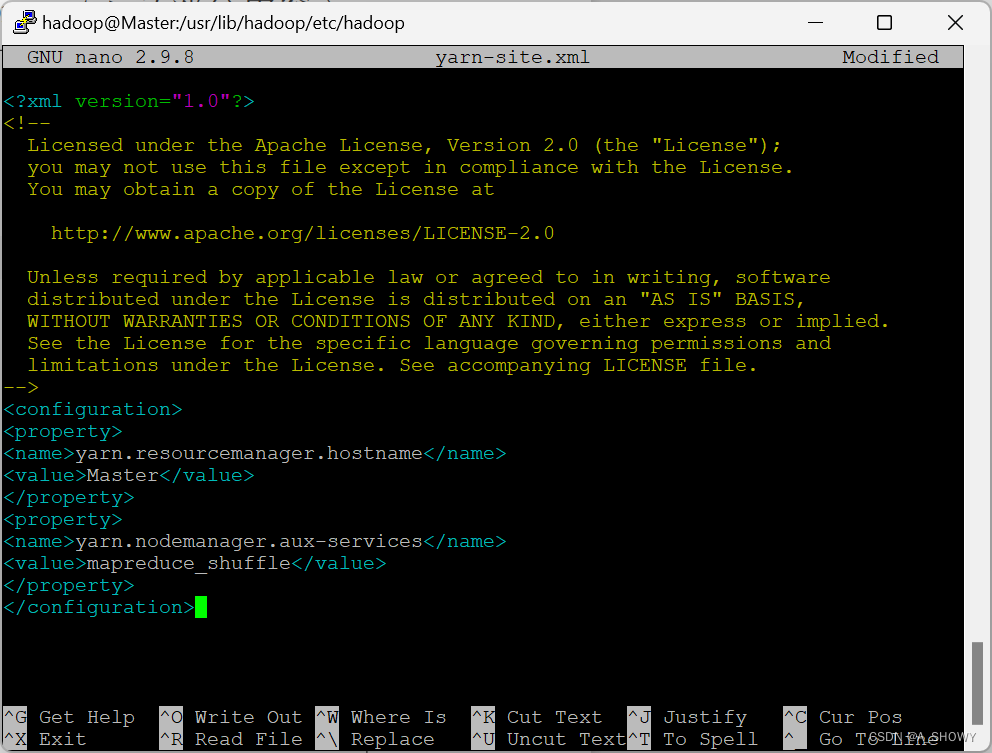
 9.修改 yarn-site.xml 文件
9.修改 yarn-site.xml 文件
sudo nano yarn-site.xml
将其修改为
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
 10.将改好的文件部署到从节点
10.将改好的文件部署到从节点
- 把修改后的文件内容压缩成压缩包
cd /usr/lib
tar -zcf ~/hadoop.master.tar.gz ./hadoop
- 使用 scp 命令进行传输,将修改好的文件传输到 Slave01 和 Slave02的用户文件夹下。
scp -r ~/hadoop.master.tar.gz Slave01:/home/hadoop
scp -r ~/hadoop.master.tar.gz Slave02:/home/hadoop

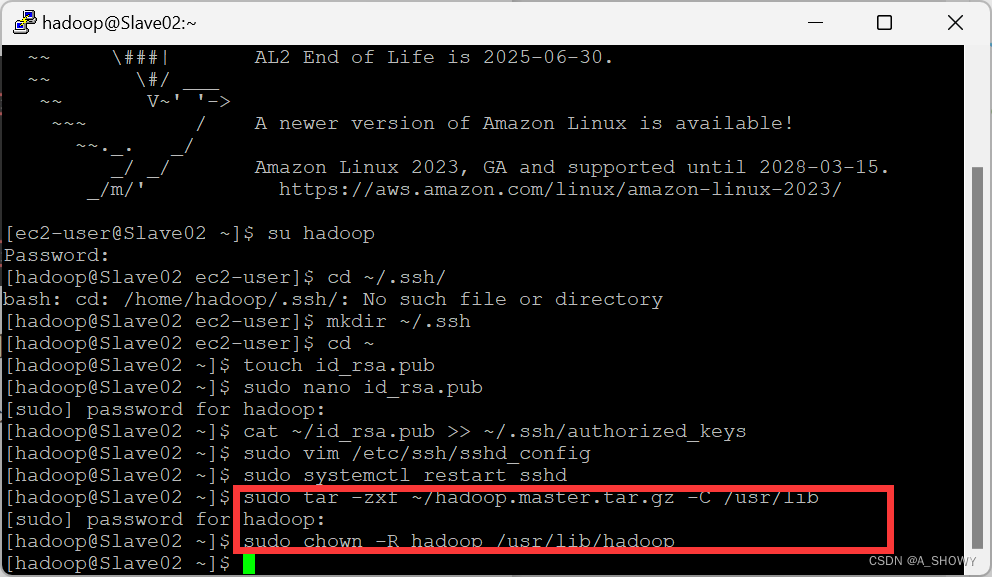
11.在从节点解压刚刚传输来的文件
在两个子节点分别输入
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/lib
sudo chown -R hadoop /usr/lib/hadoop
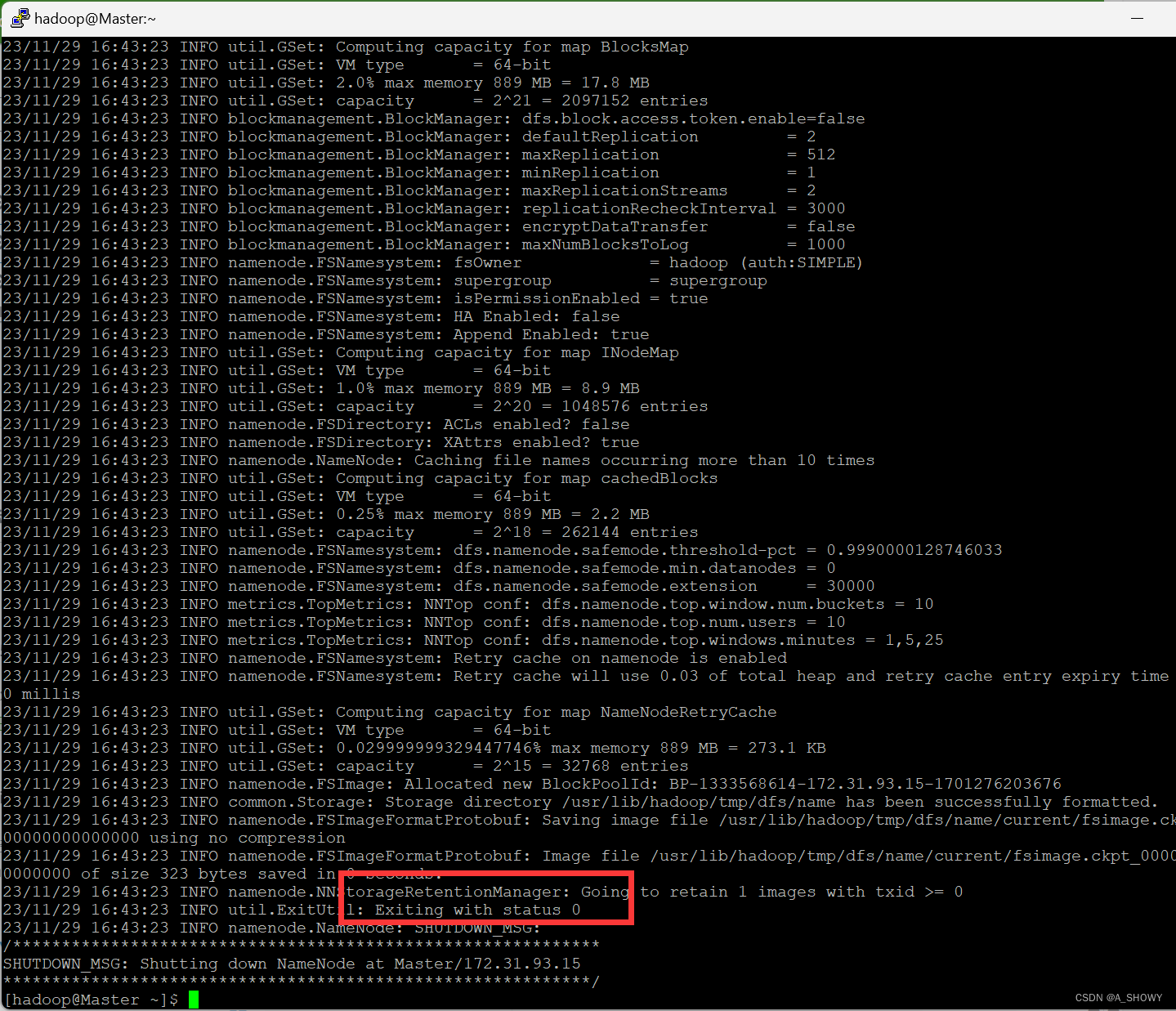
12.在Master节点执行 NameNode 的格式化
hdfs namenode -format
出现Exiting with status 0表明格式化成功
- 启动Hadoop程序
当完成初始化后,要进行启动服务
- 首先先看看目前有什么服务,发现仅有一个服务
- 在 Master 中启动 dfs
start-dfs.sh
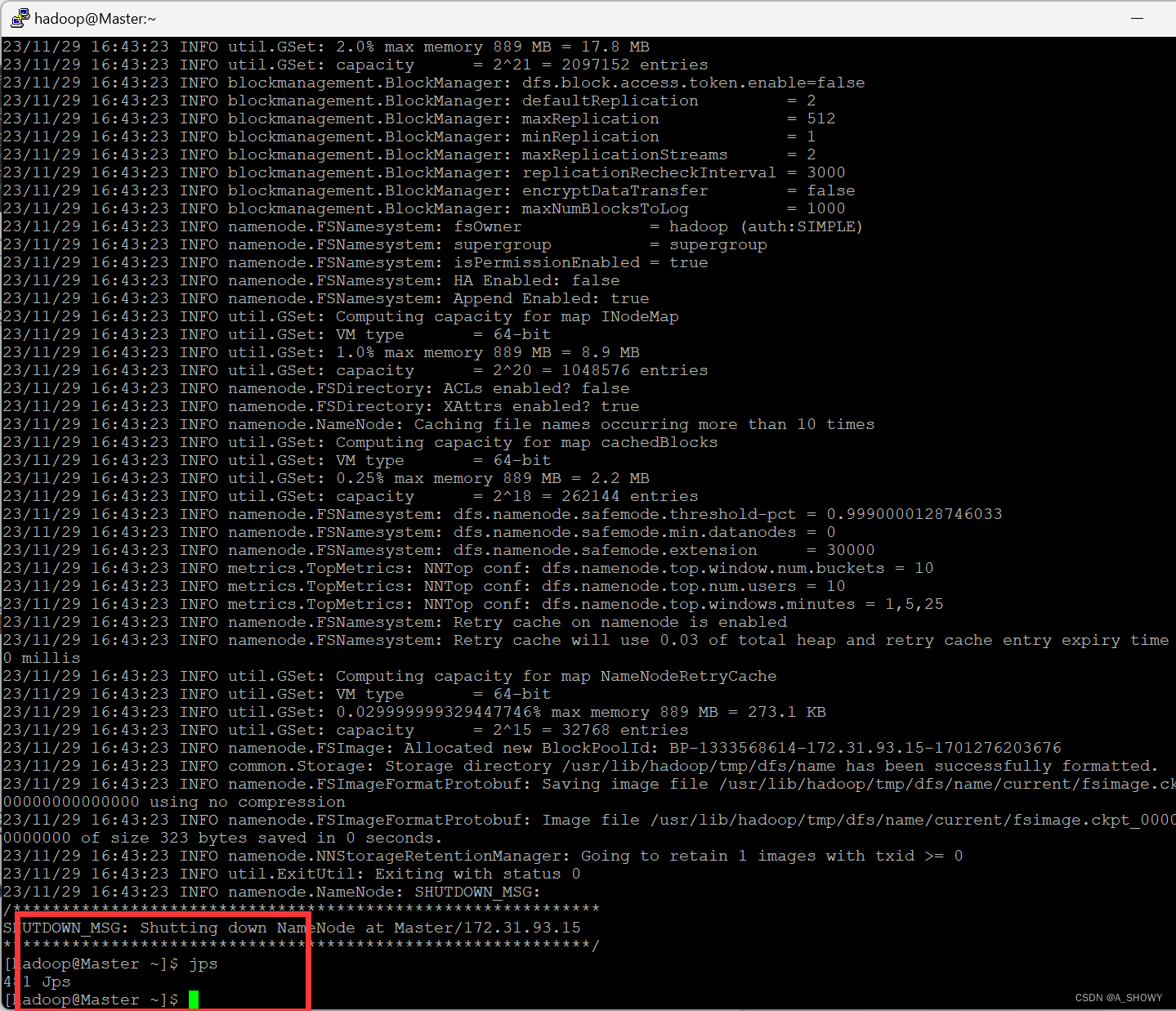
可以看到有三个服务
- 查看 Slave01 和Slave02服务是否开启成功,可以看到均有两个服务,开启成功。
- 启动Yarn程序
-
start-yarn.sh
- 查看 Master 服务是否开启成功
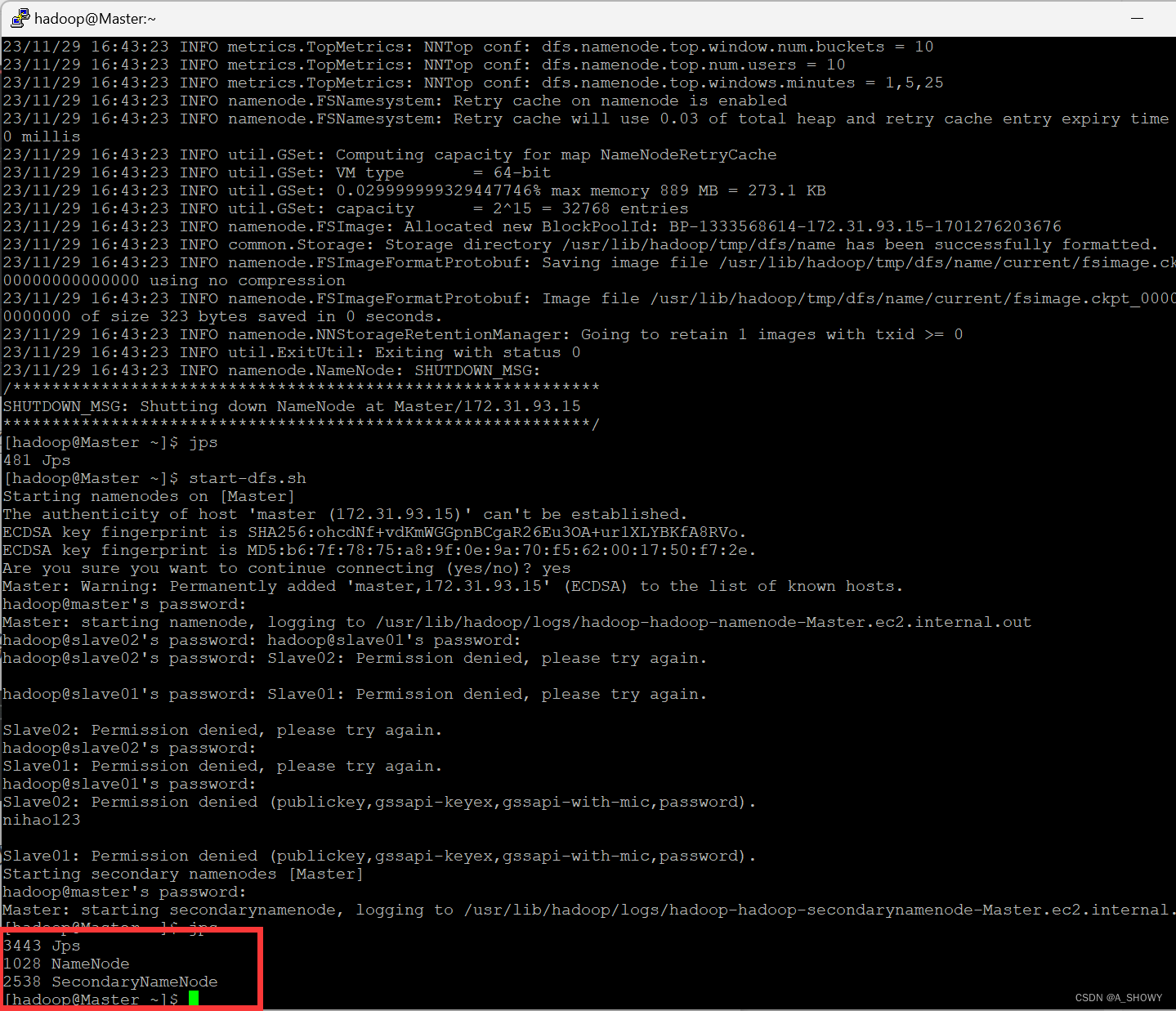
可以看到有4个服务,说明启动成功
- 切换到 Slave01和Slave02 对应的 putty 界面,查看服务是否开启成功。
均有3个启动起来的服务,说明Slave01和Slave02均开启成功。
13.在Master主机开启 historyserver 服务
mr-jobhistory-daemon.sh start historyserver,可以看到有5个服务,说明启动成功。


14.通过 hdfs dfsadmin -report 查看集群状态
hdfs dfsadmin -report

其中 Live datanodes (2) 表明两个从节点都已正常启动,启动成功。
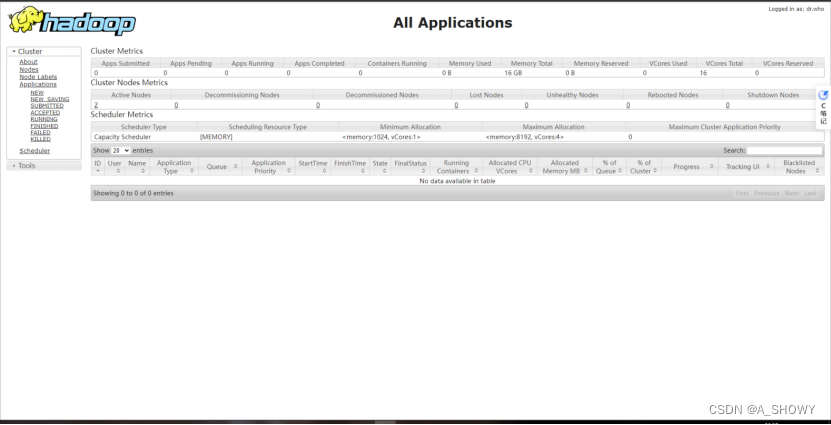
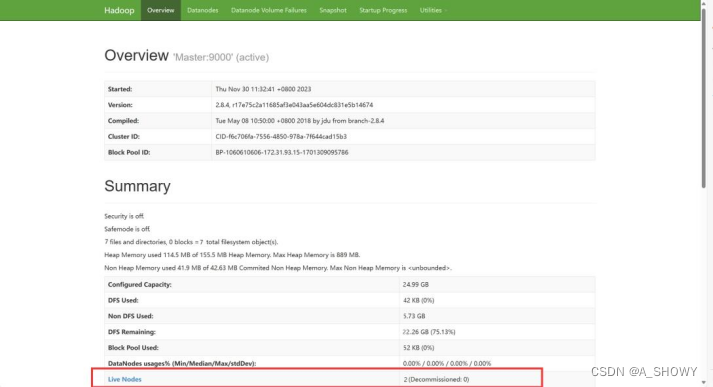
15.通过web查看集群的一些信息
将复制的公有 IPv4 地址复制到浏览器地址栏后加上:50070打开此页面
将复制的公有 IPv4 地址复制到浏览器地址栏后加上 :8088打开此页面