本节目录
随机森林
支持向量机
朴素贝叶斯
神经网络构建
将机器算法融入量化投资领域,不同于一般的量化交易策略,从一类数据中自动分析获得规律,利用规律对未知数据进行预测的算法。
决策树:决策树具有分层或者树状结构,其分支充当节点。我们可以通过遍历这些节点来做出某个决策,这些节点通过数据特征进行参数选择。但是,决策树存在过度拟合的问题。 过度拟合通常在树中添加越来越多的节点来增加树内的特异性以达到某个结论,从而增加树的深度并使其更复杂。
随机森林:是一种基于统计学习理论的机器算法。它可以对投资者自选的各个因子,以机器训练的方式进行自动分析,从而给投资者提供良好的投资建议。是一种使用集成方法的监督分类机器学习算法。 简而言之,随机森林由众多决策树组成,有助于解决决策树过度拟合的问题。 通过从给定数据集中选择随机特征来随机构造这些决策树。随机森林根据从决策树收到的最大投票数得出决策或预测。 通过众多决策树达到最大次数的结果被随机森林视为最终结果。
随机森林的构建:随机森林的构建包括两个方面,分别是数据的随机选取和决策点的随机选取。
1)数据的随机选取
第一,从初始的数据集中采取有放回的抽样方式,构造子数据集,子数据集的数据量和初始数据集相同。需要注意的是,不同子数据集的元素可以重复,同一个子数据集的元素也可以重复。
第二,利用子数据集来构造子决策树,将子数据集放到每个子决策树中,每个子决策树输出一个结果。
第三,如果有新的数据需要通过随机森林得到分类结果,可以通过对子决策树的判断结果进行投票,得到随机森林的输出结果。
2)决策点的随机选取
与数据集的随机选取相似,随机森林中的子决策树的每一个分裂过程并未用到所有的决策点,而是从所有的决策点中随机选取一定的决策点,再在随机选取的决策点中选取最优的决策点。这样能够使随机森林中的决策树彼此不同,以提升系统的多样性,从而提升分类性能。
工作原理:
随机森林基于集成学习技术,简单地表示一个组合或集合,在这种情况下,它是决策树的集合,一起称为随机森林。集合模型的准确性优于单个模型的准确性,因为它汇总了单个模型的结果并提供了最终结果。那么,如何从数据集中选择特征以构建随机森林的决策树呢?
使用称为 bagging 的方法随机选择特征。根据数据集中可用的特征集,通过选择具有替换的随机特征来创建许多训练子集。这意味着可以在不同的训练子集中同时重复一个特征。例如,如果数据集包含20个特征,并且要选择5个特征的子集来构建不同的决策树,则将随机选择这5个特征,并且任何特征都可以是多个子集的一部分。这确保了随机性,使树之间的相关性更小,从而克服了过度拟合的问题。选择特征后,将根据最佳分割构建树。每棵树都给出一个输出,该输出被认为是从该树到给定输出的“投票”。接收最大’投票’的随机森林选择最终输出/结果,或者在连续变量的情况下,所有输出的平均值被视为最终输出。
在上图中,我们可以观察到每个决策树已经投票或者预测了特定的类别。随机森林选择的最终输出或类别将是N类,因为它具有多数投票或者是四个决策树中的两个预测输出。
随机森林的优缺点
随机森林的优点有3项,具体如下:
第一,随机森林可以用于回归和分类任务,并且很容易查看模型输入特征的相对重要性。
第二,随机森林是一种非常方便且易于使用的算法,因为在默认参数情况下即可产生一个很好的预测结果。
第三,机器学习中的一个重大问题是过拟合,但大多数情况下随机森林分类器不会出现过拟合,因为只要森林中有足够多的树,分类器就不会过度拟合模型。
随机森林的缺点在于使用大量的树会使算法变得很慢,并且无法做到实时预测。一般来讲,这些算法训练速度很快,预测却十分缓慢。而且越准确的预测需要越大量的树,这将导致模型很慢。
随机森林应用
下面说明利用随机森林训练某只股票的均线指标、相对强弱指标、动量线指标后,来预测该股票下一个交易日的涨跌,即为投资者提供买进或卖出的投资建议。
首先导入需要的数据包,具体代码如下:
import talib # 导入talib库
from jqdata import * # 导入聚宽函数库接下来设置要操作的股票,即利用随机森林训练的股票。同时要设置训练股票的开始时间和结束时间,具体代码如下:
test stock = '600600.XSHG' # 设置测试标的为青岛啤酒
start_date = datetime.date(2018, 12, 1) # 设置开始时间
end_date = datetime.date(2023, 12, 1) # 设置结束时间接下来,利用get_all_trade_days)函数获取所有交易日;再定义两个变量,将其分别赋值为随机森林训练开始时间和结束时间,具体代码如下:
trading days = list(get_all_trade_days()) # 获取所有交易日
start_date_index = trading_days.index(start_date) # 获取开始时间
end_date_index = trading_days.index(end_date) # 获取结束时间然后再定义两个列表变量,接着利用for循环语句计算3个指标,即均线指标、相对强弱指标、动量线指标的数据,并添加到列表变量中,具体代码如下:
x_all = [] # 定义两个列表变量
y_all = []
for index in range(start_date_index, end_date_index):
# 得到计算指标的所有数据
start_day = trading_days[index-30]
end_day = trading_days[index]
# 利用get_price()函数获得股票数据
stock_data =get_price(test_stock, start_date = start_day, end_date = end day,frequency='daily', fields=['close'])
# 定义变量并赋值为收盘价
close_prices = stock_data('close').values
# 通过数据计算指标
# -2是保证获取的数据是昨天的,-1就是通过今天的数据计算出来的指标
ma_data = talib.MA(close_prices)[-2]
rsi_data = talib.RSI(close_prices)[-2]
mom_data = talib.MOM(close_prices) [-2]
features = []
# 添加均线指标、相对强弱指标和动量线指标
features.append(ma_data)
features.append(rsi_data)
features.append(mom_data)
# 设置变量label 为布尔变量,并赋值为False
label = False
# 如果今天收盘价大于昨天收盘价,则变量 label为True
if close_prices[-1] > close_prices[-2]:
label = True
x_all.append(features)
y_all.append(label)最后准备随机森林算法需要用到的数据,并显示提示信息,具代码如下:
x_train = x_all[:-1]
y_train = y_all[:-1]
x_test = x_all[-1]
y_test= y_al1[-1]
print('数据已准备好了!')接下来导入随机森林分类器,训练样本的特征是根据2018年12月1日至2023年12月1日每一天的之前的交易日的收盘价计算的均线指标、相对强弱指标和动量线指标,训练样本的标类别是2018年12月1日至2023年12月1日每一天的涨跌情况,涨是True,跌是False,测试样本是2023年12月4日的3个指标以及涨跌情况,具体代码如下:
from sklearn.ensemble import RandomForestClassifier # 调用随机森林分类器
clf = RandomForestClassifier()
clf.fit(x_train, y_train) # 训练的代码
prediction = clf.predict(x_test) # 得到测试结果
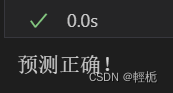
if prediction == y_test: # 利用if语句判断是否预测正确
print("预测正确!")
else:
print("预测错误!")得到结果为:
支持向量机:是一种有监督得机器学习模型,通常用来进行模式识别、分类和回归分析,在解决小样本、非线性样本和高维模式识别中表现出许多特有的优势,广泛推广到其他函数拟合等其他机器学习中。


![C++:智能指针[重点!]](https://img-blog.csdnimg.cn/direct/a30e37a2b3304962a6dbb6f8211b115a.png)