strlne函数的使用
- 一.strlen函数的声明
- 二.strlen函数的头文件
- 三.相关题目
- 代码1
- 代码2
- 题目1
- 题目2
- 题目3
- 题目4
- 题目5
- 题目6
一.strlen函数的声明
size_t strlen ( const char * str );
二.strlen函数的头文件
使用strlen函数我们需要使用以下头文件
#include <string.h>
三.相关题目
下面我们来看几段代码
代码1
int main()
{
const char* p = "abcdefghi";
printf("%lld\n", strlen(p));
printf("%lld\n", strlen(p + 1));
printf("%lld\n", strlen(p[0]));
printf("%lld\n", strlen(&p));
printf("%lld\n", strlen(&p + 1));
printf("%lld\n", strlen(&p[0] + 1));
return 0;
}
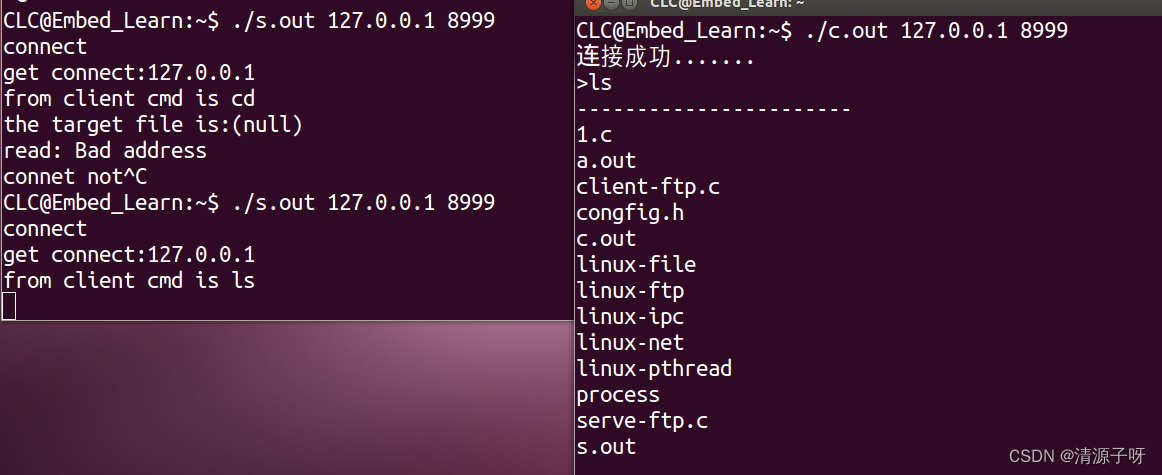
首先我们先看运行结果:

首先解释
strlen(p):字符串中有’\0’,而p中存放的是a的地址,所以值就是9
strlen(p + 1):是第一个字符的地址+1,就是第二个字符b,所以就是8
strlen(*p):把a的值传给strlen所以错误
strlen(p[0]):*p == *(p+0) == p[0]错误
strlen(&p):&p是p的地址,从p所占的空间位置开始查找,所以是随机值
strlen(&p + 1):&p是p的地址,&p + 1是p的地址+1,所以是随机值
strlen(&p[0] + 1):&p[0]是第一个元素的地址就是a,向后面找到’\0’前,就是8
代码2
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));
return 0;
}
首先看运行结果
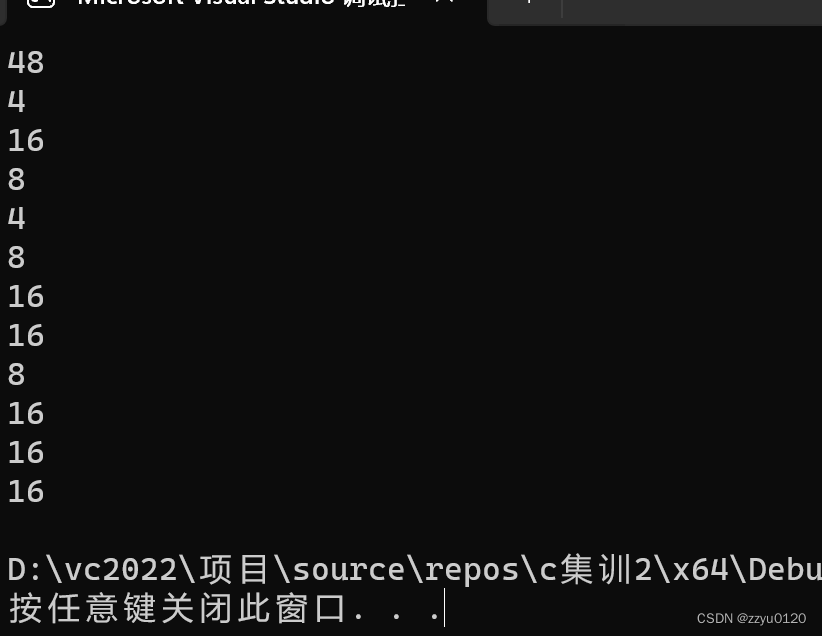
这里解释上面代码:
sizeof(a):计算的是整个二维数组地址的大小,一共有十二个元素,每个元素是整型占用4个字节的内存,所以结果就是48
sizeof(a[0][0]):a[0][0]是第一行的第一个元素,大小是4个字节
sizeof(a[0]):a[0]就是第一行的大小,第一行·的数组名单独放在sizeof内部,计算的就是第一行的元素大小就是16(sizeof操作符在之前的博客中也有介绍,感兴趣的小伙伴可以点击主页了解)
sizeof(a[0] + 1):a[0]是第一行数组的数组名,但是数组名不是单独放在sizeof内部,所以数组名表示首元素的地址也就是a[0][0]的地址,a[0]+1就是第一行第二个元素a[0][1]的地址,地址的大小就是4或者8个字节
sizeof(*(a[0] + 1)):a[0] + 1是第一行第二个元素(a[0][1])的地址,(a[0] + 1)就是第一行第二个元素,大小是4个字节
sizeof(a + 1):a没有单独放在sizeof内部。+1就是第一行的地址,第一行有4个元素,所以大小是16个字节
sizeof(a[1]):等价于sizeof((a+1)),也是第一行的地址,16个字节
sizeof(&a[0] + 1):a[0]是第一行的地址,&a[0] + 1就是第二行的地址,4或者8个字节
sizeof(*(&a[0] + 1)):&a[0] + 1就是第二行的地址,第二行有4个元素,所以就是16个字节
sizeof(*a):数组名a就是数组首元素地址,就是第一行的地址*a就是第一行的地址(*a == *(a+0) == a[0])所以就是16个字节
sizeof(a[3]):是第四行的地址,所以就是16个字节
题目1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d, %d", *(a + 1), *(ptr - 1));
return 0;
}
首先看一下运行结果
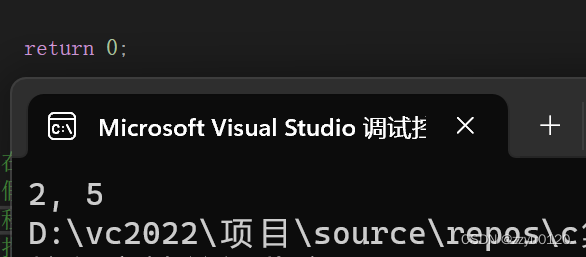
这里解释
(int*)(&a + 1):&a是数组的地址,在+1就是跳过整个数组
*(a + 1):a是首元素地址,+1就是第二个元素地址,在解引用就是2
*(ptr - 1):ptr是数组的地址,在-1就是第五个元素,就是5
题目2
在X86环境下
假设结构体的⼤⼩是20个字节
程序输出的结构是啥?
指针运算中的指针±整数
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
} * p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
p + 0x1:0x1是十六进制里面的1,十六进制的1和十进制里的1是一样的,所以就是0x00100014
unsigned long:是整型,整形加减就是整型,所以就是+1结果就是0x00100001
(unsigned int*)p:是整型指针,整型指针+1就是4个字节,所以结果就是0x00100004
题目3
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5)};
int* p;
p = a[0];
printf("%d", p[0]);
return 0;
}
int a[3][2] = { (0, 1), (2, 3), (4, 5)};:数组内是逗号表达式,所以值是1,3,5
此时数组内的元素就是
p[0]:等价于*(p+0),就是第一个元素,就是1

下面是运行结果:

题目4
假设环境是x86环境,程序输出的结果是啥?
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
p[4][2]和a[4][2]之间相差4个元素,但是p[4][2]是小地址,a[4][2]是大地址,所以结果是复数如下图
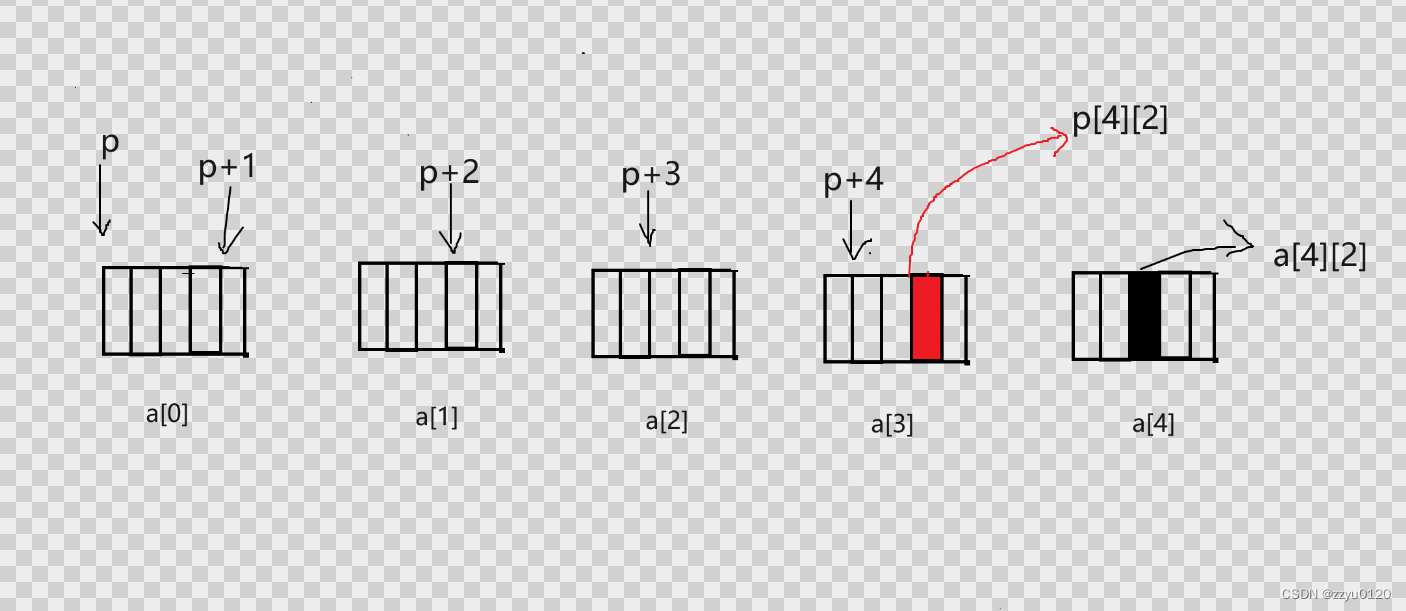
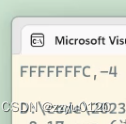
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); :这段代码,第一是以%p的方式打印,-4要存在内存当中存的是补码,地址没有原反补的概念所以直接打印F F F F F F F C,但是以%d的方式打印存的就是源码
-4的
源码:10000000 00000000 00000000 00000100
反码:111111111 111111111 111111111 11111101
补码:111111111 111111111 111111111 11111110
换成十六进制就是
F F F F F F F C
运行结果:
题目5
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));//10 5
return 0;
}
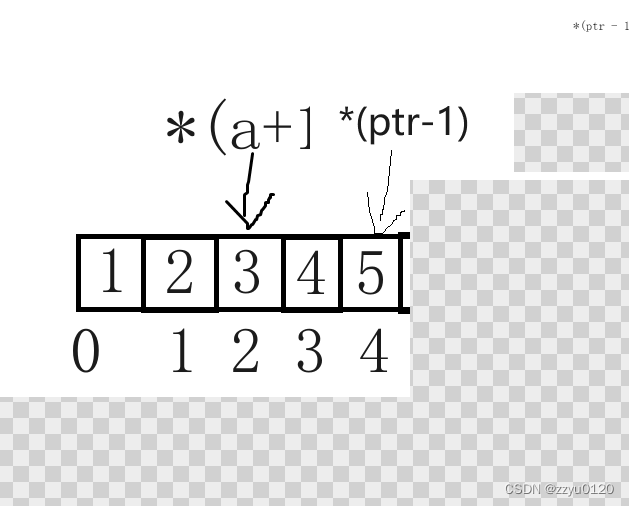
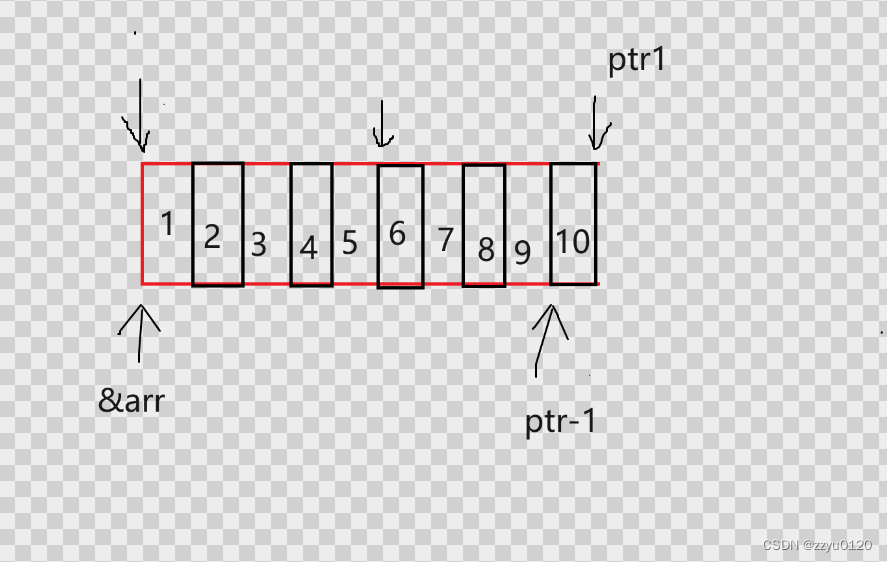
&aa + 1:&aa是数组名,数组名+1就是跳过整个数组,所以*(ptr1 - 1)就是10,如下图:
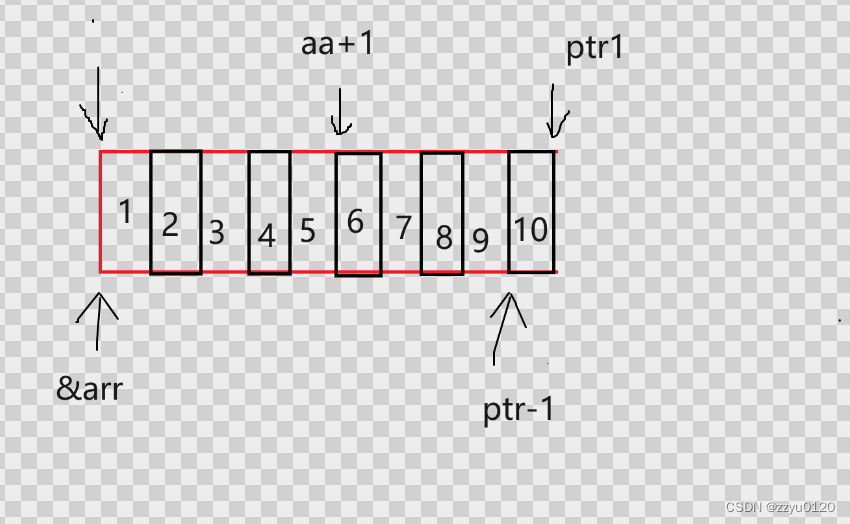
*(aa + 1):aa是数组首元素地址,+1就是第二行地址,*(aa+1)等价于aa[1],就是5,如下图
下面代码的运行结果是

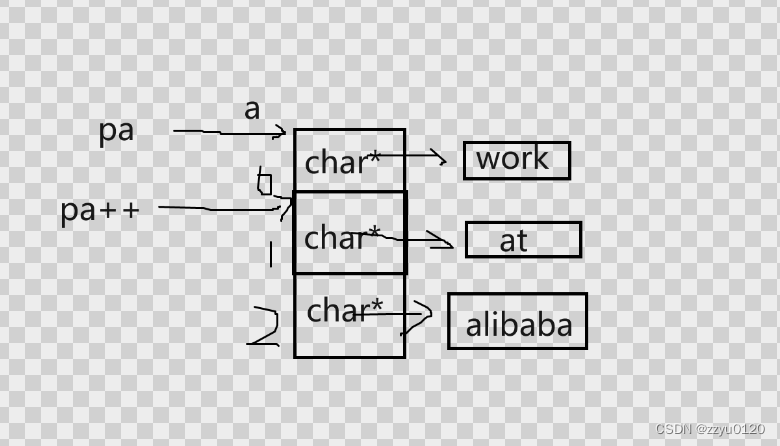
题目6
int main()
{
const char* a[] = { "work","at","alibaba" };
const char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
a是首元素地址,所以pa就是第一个元素地址,
pa++就是第二个元素地址,在解引用拿到第二个元素,如下图: