根据DGL 来做的,按照DGL 实现来讲述
1. GCN Cora 训练代码:
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(GCN, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats)
self.conv2 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feat):
h = self.conv1(g, in_feat)
h = F.relu(h)
h = self.conv2(g, h)
return h
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
features = g.ndata["feat"]
labels = g.ndata["label"]
train_mask = g.ndata["train_mask"]
val_mask = g.ndata["val_mask"]
test_mask = g.ndata["test_mask"]
for e in range(100):
# Forward
logits = model(g, features)
# Compute prediction
pred = logits.argmax(1)
# Compute loss
# Note that you should only compute the losses of the nodes in the training set.
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print(
f"In epoch {e}, loss: {loss:.3f}, val acc: {val_acc:.3f} (best {best_val_acc:.3f}), test acc: {test_acc:.3f} (best {best_test_acc:.3f})"
)
if __name__ == "__main__" :
dataset = dgl.data.CoraGraphDataset()
# print(f"Number of categories: {dataset.num_classes}")
g = dataset[0]
g = g.to('cuda')
model = GCN(g.ndata["feat"].shape[1], 16, dataset.num_classes).to('cuda')
train(g, model)
一些基础python torch.tensor语法概述:
1.
if __name__ == "__main__" :
XXXXXXX
XXXXXXX当我们直接执行这个脚本时,__name__属性被设置为__main__,因此满足if条件,语句块中的代码被调用。
但如果我们将该脚本作为模块导入到另一个脚本中,则__name__属性会被设置为模块的名称(例如"example"),语句块中的代码不会被执行。
2.
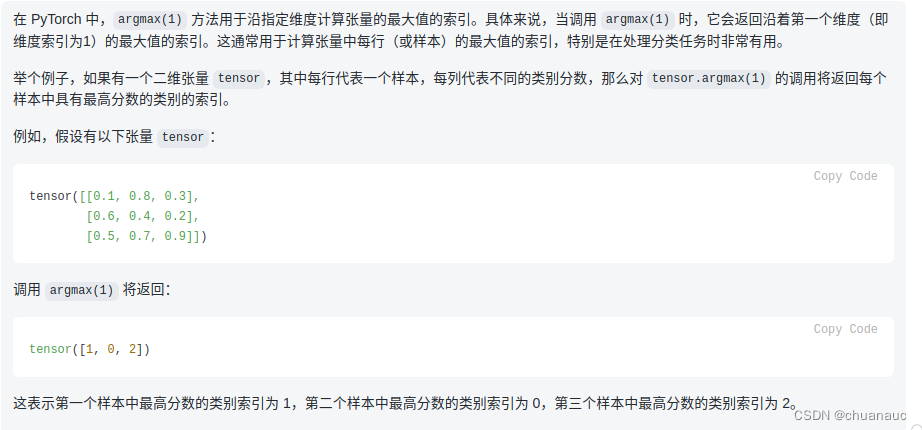
# Compute prediction
pred = logits.argmax(1) # 返回沿着第一个维度(即维度索引为1)的最大值的索引。
# 即,加入有5个样本,每个样本有3个维度的评分,那么就会给出没个样本3中维度评分最高的哪个维度的索引序号
3. numpy 关于 tensor 的一个用法:
在DGL 中使用一串 True 或 False 组成的 一维tensor 来标识 这个节点到底是属于 train test val 哪一类
train_mask = g.ndata["train_mask"]
val_mask = g.ndata["val_mask"]
test_mask = g.ndata["test_mask"]而后,由于对于torch中的tensor来说:
就可以:select_label_tensor = labels[train_mask] 了
import torch
# 定义一个Tensor
tensor = torch.tensor([1, 2, 3, 4, 5])
# 定义一个布尔数组,选择索引为1和4的元素
mask = torch.tensor([False, True, False, False, True])
# 通过布尔索引选择元素
selected_tensor = tensor[mask]
print(selected_tensor) # tensor([2, 5])顺便,查看一个变量到底是什么类型可以使用 type() 函数:
train_mask = g.ndata["train_mask"]
print(type(train_mask))
# 输出为:
# <class 'torch.Tensor'>