python pyaudio对音频进行端点检测,检测出说话区间
主要采用过零率和语音能量来进行检测,并设置双阈值。
代码如下:
# -*- coding: utf-8 -*-
import wave
import os
import matplotlib.pyplot as plt
import numpy as np
# 判断是否变号
def sgn(data):
if data >= 0:
return 1
else:
return 0
# 计算每一帧的能量,设定每 256 个采样点为一帧,一帧就是一个语音块
def calEnergy(wave_data):
energy = []
sum = 0
for i in range(len(wave_data)):
sum = sum + (int(wave_data[i]) * int(wave_data[i]))
if (i + 1) % 256 == 0:
energy.append(sum)
sum = 0
elif i == len(wave_data) - 1:
energy.append(sum)
return energy
# 计算过零率
def calZeroCrossingRate(wave_data):
zeroCrossingRate = []
sum = 0
for i in range(len(wave_data)):
# 判断当前索引 i 是否是 256 的倍数,为了避免从音频数据的开头和上一帧最后一个采样点计算过零率
if i % 256 == 0:
continue
sum = sum + np.abs(sgn(wave_data[i]) - sgn(wave_data[i - 1]))
if (i + 1) % 256 == 0:
zeroCrossingRate.append(float(sum) / 255)
sum = 0
elif i == len(wave_data) - 1:
zeroCrossingRate.append(float(sum) / 255)
return zeroCrossingRate
"""
当使用双门限法进行语音端点检测时,可以按照以下步骤实现:
计算语音信号的短时能量和过零率。可以使用算法或库函数来计算短时能量和过零率。
初始化参数。设定较高和较低能量阈值、过零率阈值等参数。
根据能量阈值进行初步检测。遍历短时能量序列,当能量超过较高能量阈值时,标记为起始点;
当能量低于较低能量阈值时,标记为结束点。
根据过零率阈值进行进一步检测。遍历起始点和结束点之间的时间窗口,在时间窗口内计算过零率,
并判断是否超过过零率阈值。若超过阈值,说明该点为语音信号的起始或结束点;
若未超过阈值,说明该点为语音信号的过渡点。
根据检测到的起始和结束点,得到语音信号的分段结果。
"""
# 利用短时能量,短时过零率,使用双门限法进行端点检测
def endPointDetect(wave_data, energy, zeroCrossingRate):
sum = 0
energyAverage = 0
# 短时能量平均数
for en in energy:
sum = sum + en
energyAverage = sum / len(energy)
# print(energyAverage)
# 首先计算语音前一段的静音部分的能量均值(前5帧)
sum = 0
for en in energy[:5]:
sum = sum + en
ML = sum / 5
# 将能量均值的1/4作为MH
MH = energyAverage / 4 # 较高的能量阈值
# 将静音部分的能量均值和MH的平均数的1/4作为ML。
ML = (ML + MH) / 4 # 较低的能量阈值
# 计算前5帧的过零率
sum = 0
for zcr in zeroCrossingRate[:5]:
sum = float(sum) + zcr
Zs = sum / 5 # 过零率阈值
A = []
B = []
C = []
# 首先利用较大能量阈值 MH 进行初步检测
flag = 0
for i in range(len(energy)):
if len(A) == 0 and flag == 0 and energy[i] > MH:
A.append(i)
flag = 1
# 如果当前点与上一个浊音的结束点之间的距离大于阈值(这里设为21),则将当前点设为新的浊音的起始点
elif flag == 0 and energy[i] > MH and i - 21 > A[len(A) - 1]:
A.append(i)
flag = 1
# 如果当前能量超过 MH,但当前点与上一个浊音的结束点之间的距离小于等于阈值 21,则将上一个浊音的结束点舍弃
elif flag == 0 and energy[i] > MH and i - 21 <= A[len(A) - 1]:
A = A[:len(A) - 1]
flag = 1
# 拿到结束点
if flag == 1 and energy[i] < MH:
A.append(i)
flag = 0
print("较高能量阈值,计算后的浊音A:" + str(A))
# 根据较低能量阈值,在基础 A 上增加一段语音
for j in range(len(A)):
i = A[j]
if j % 2 == 1: # 奇数下标为结束点
while i < len(energy) and energy[i] > ML:
i = i + 1
B.append(i)
else: # 偶数下标为起始点
while i > 0 and energy[i] > ML:
i = i - 1
B.append(i)
print("较低能量阈值,增加一段语言B:" + str(B))
# 利用过零率进行最后一步检测,过零率高表示活跃语音
print(B)
for j in range(len(B)):
i = B[j]
if j % 2 == 1: # 奇数下标为结束点
while i < len(zeroCrossingRate) and zeroCrossingRate[i] >= 3 * Zs:
i = i + 1
C.append(i)
else: # 偶数下标为起始点
while i > 0 and zeroCrossingRate[i] >= 3 * Zs:
i = i - 1
C.append(i)
print("过零率阈值,最终语音分段C:" + str(C))
return C
f = wave.open("./output.wav", "rb")
# getparams() 一次性返回所有的WAV文件的格式信息
params = f.getparams()
# nframes 采样点数目 帧数
nchannels, sampwidth, framerate, nframes = params[:4]
# readframes() 按照采样点读取数据
str_data = f.readframes(nframes) # str_data 是二进制字符串
# 以上可以直接写成 str_data = f.readframes(f.getnframes())
# 转成二字节数组形式(每个采样点占两个字节)
wave_data = np.fromstring(str_data, dtype=np.short)
f.close()
# 转成双声道
wave_data.shape = -1, 2
wave_data = wave_data.T
time = np.arange(0, nframes) * (1.0 / framerate) # 每个采样点对应的时间,单位是 s
waveDate = wave_data[0] # 提取一个声道的数据
print("采样点数目:" + str(len(waveDate))) # 输出一个声道应为采样点数目
print("采样率:" + str(framerate))
plt.plot(waveDate)
plt.ylabel("voiceprint")
plt.xlabel("nframes")
plt.show()
minvalue = min(waveDate)
maxvalue = max(waveDate)
energy = calEnergy(waveDate) # 每 256 为一帧,energy 为语音块的能量
plt.subplot(211)
plt.plot(energy)
plt.ylabel("energy")
plt.xlabel("frame")
# 保存 energy
with open("./energy/1_en.txt", "w") as f:
for en in energy:
f.write(str(en) + "\n")
zeroCrossingRate = calZeroCrossingRate(waveDate)
plt.subplot(212)
plt.plot(zeroCrossingRate) # 同样是以帧为单位的过零率
plt.ylabel("zeroCrossingRate")
plt.xlabel("frame")
plt.show()
# 保存过零率
with open("./zero/1_zero.txt", "w") as f:
for zcr in zeroCrossingRate:
f.write(str(zcr) + "\n")
# 双门限法进行端点检测
N = endPointDetect(waveDate, energy, zeroCrossingRate)
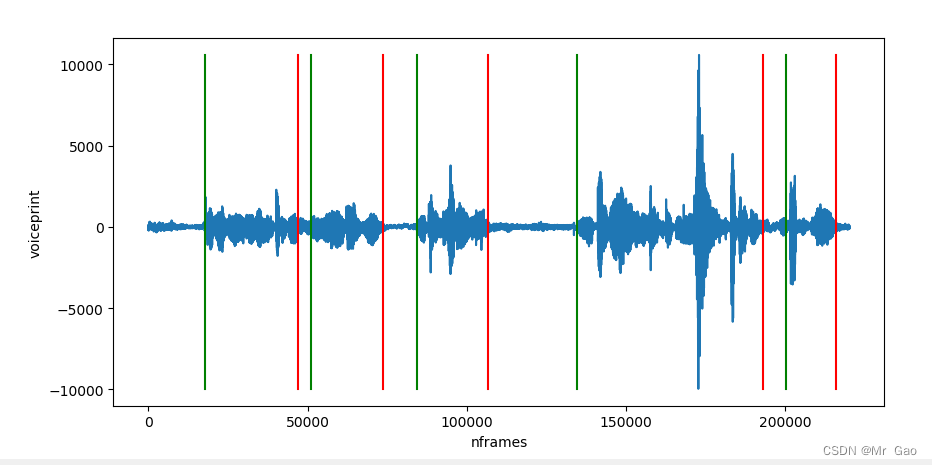
plt.plot(waveDate)
for i in range(0,len(N),2):
print(i)
x = [N[i] * 256, N[i] * 256] # * 256 放大到原来的采样点上
x1 = [N[i+1] * 256, N[i+1] * 256]
y = [minvalue, maxvalue]
plt.plot(x, y, "-g")
plt.plot(x1, y, "-r")
plt.plot()
plt.ylabel("voiceprint")
plt.xlabel("nframes")
plt.show()
# 输出为 pcm 格式
with open("./corpus/1.pcm", "wb") as f:
i = 0
while i < len(N):
for num in waveDate[N[i] * 256: N[i + 1] * 256]:
f.write(num)
i = i + 2
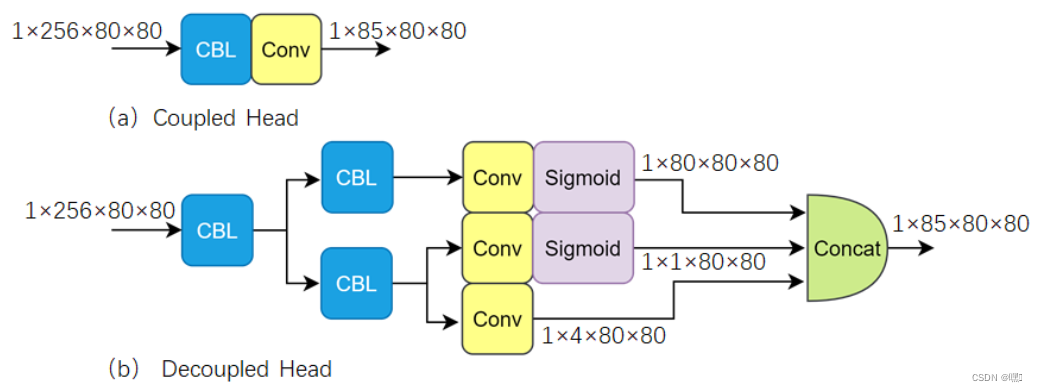
运行结果如下:







![[GPT-1]论文实现:Improving Language Understanding by Generative Pre-Training](https://img-blog.csdnimg.cn/direct/21324314bc49456c9bf1342508890f1f.png)
