一,什么是coredump
我们经常听到大家说到程序core掉了,需要定位解决,这里说的大部分是指对应程序由于各种异常或者bug导致在运行过程中异常退出或者中止,并且在满足一定条件下(这里为什么说需要满足一定的条件呢?下面会分析)会产生一个叫做core的文件。
通常情况下,core文件会包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息还有各种函数调用堆栈信息等,我们可以理解为是程序工作当前状态存储生成第一个文件,许多的程序出错的时候都会产生一个core文件,通过工具分析这个文件,我们可以定位到程序异常退出的时候对应的堆栈调用等信息,找出问题所在并进行及时解决。
二,coredump文件的存储位置
core文件默认的存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到core文件的存在位置:
cat /proc/sys/kernel/core_pattern
缺省值是core
注意:这里是指在进程当前工作目录的下创建。通常与程序在相同的路径下。但如果程序中调用了chdir函数,则有可能改变了当前工作目录。这时core文件创建在chdir指定的路径下。有好多程序崩溃了,我们却找不到core文件放在什么位置。和chdir函数就有关系。当然程序崩溃了不一定都产生 core文件。
如下程序代码:则会把生成的core文件存储在/data/coredump/wd,而不是大家认为的跟可执行文件在同一目录。
#include <stdio.h>
#include <unistd.h>
int main(){
//change the current working directory to "/data/coredump/wd"
const char *wdir = "/data/coredump/wd";
int ret = -1;
ret = chdir(wdir);
if(0 != ret) {
printf("chdir fails, ret : %d", ret);
retrun 0;
}
char *ptr = "linux.xxx";
*ptr = 0;
return 0;
}通过下面的命令可以更改coredump文件的存储位置,若你希望把core文件生成到/data/coredump/core目录下:
echo “/data/coredump/core”> /proc/sys/kernel/core_pattern
注意,这里当前用户必须具有对/proc/sys/kernel/core_pattern的写权限。一般来讲最好用root用户来修改,切换到root用户命令sudo su。
缺省情况下,内核在coredump时所产生的core文件放在与该程序相同的目录中,并且文件名固定为core。很显然,如果有多个程序产生core文件,或者同一个程序多次崩溃,就会重复覆盖同一个core文件,因此我们有必要对不同程序生成的core文件进行分别命名。
我们通过修改kernel的参数,可以指定内核所生成的coredump文件的文件名。例如,使用下面的命令使kernel生成名字为core.filename.pid格式的core dump文件:
echo “/data/coredump/core.%e.%p” >/proc/sys/kernel/core_pattern
如果想在程序运行同目录生成,则如下修改。
echo “./core.%e.%p” >/proc/sys/kernel/core_pattern
这样配置后,产生的core文件中将带有崩溃的程序名、以及它的进程ID。上面的%e和%p会被替换成程序文件名以及进程ID。
如果在上述文件名中包含目录分隔符“/”,那么所生成的core文件将会被放到指定的目录中。 需要说明的是,在内核中还有一个与coredump相关的设置,就是/proc/sys/kernel/core_uses_pid。如果这个文件的内容被配置成1,那么即使core_pattern中没有设置%p,最后生成的core dump文件名仍会加上进程ID。
Core_pattern的格式
可以在core_pattern模板中使用变量还很多,见下面的列表:
%% 单个%字符
%p 所dump进程的进程ID
%u 所dump进程的实际用户ID
%g 所dump进程的实际组ID
%s 导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h 主机名
%e 程序文件名
三,如何判断一个文件是coredump文件?
在类unix系统下,coredump文件本身主要的格式也是ELF格式,因此,我们可以通过readelf命令进行判断。
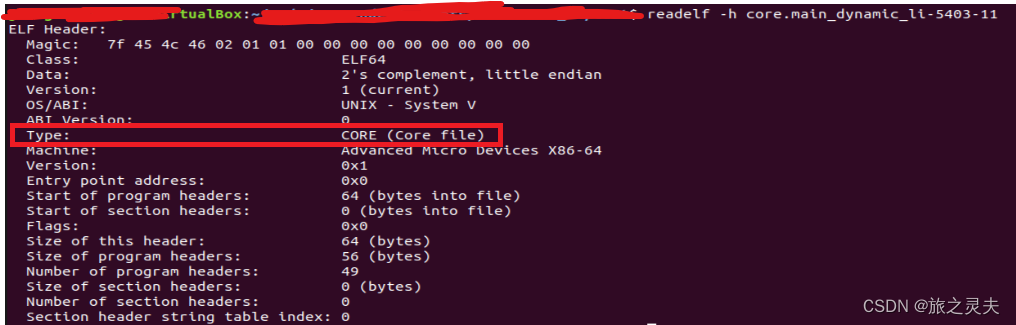
可以看到ELF文件头的Type字段的类型是:CORE (Core file)
可以通过简单的file命令进行快速判断:

四,产生coredum的一些条件总结
1, 产生coredump的条件,首先需要确认当前会话的ulimit –c,若为0,则不会产生对应的coredump,需要进行修改和设置。
ulimit -c unlimited (可以产生coredump且不受大小限制)
若想甚至对应的字符大小,则可以指定:
ulimit –c [size]
五,coredump产生的几种可能情况
造成程序coredump的原因有很多,这里总结一些比较常用的经验吧:
1,内存访问越界
a) 由于使用错误的下标,导致数组访问越界。
b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串没有正常的使用结束符。
c) 使用strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,将目标字符串读/写爆。应该使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防止读写越界。
2,多线程程序使用了线程不安全的函数。
3,多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成coredump
4,非法指针
a) 使用空指针
b) 随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump。
5,堆栈溢出
不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
六,利用gdb进行coredump的定位
其实分析coredump的工具有很多,现在大部分类unix系统都提供了分析coredump文件的工具,不过,我们经常用到的工具是gdb。
gdb 程序名 core文件名记住几个常用的gdb命令:
l(list) ,显示源代码,并且可以看到对应的行号;
b(break)x, x是行号,表示在对应的行号位置设置断点;
p(print)x, x是变量名,表示打印变量x的值
r(run), 表示继续执行到断点的位置
n(next),表示执行下一步
c(continue),表示继续执行
q(quit),表示退出gdb
启动gdb,注意该程序编译需要-g选项进行。
参考:coredump详解_51CTO博客_coredump文件位置