文章目录
- 11. ArrayList 和 LinkedList 的区别是什么?
- 12. 说一下HashMap的实现原理?
- 13. HashMap的put方法的具体流程?
- 14. 讲一讲HashMap的扩容机制
- 15. ConcurrentHashMap 底层具体实现知道吗?
- 16. 创建线程的四种方式
- 17. runnable 和 callable 有什么区别
- 18. 加锁的方式有哪些 ?
- 19. 如果你提交任务时,线程池队列已满,这时会发生什么
- 19. 在你们的项目中有没有使用到线程池
- 20. 你了解的线程池的种类有哪些 ?
11. ArrayList 和 LinkedList 的区别是什么?
-
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实 现。
-
随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数 据存储方式,所以需要移动指针从前往后依次查找。
-
增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
-
内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储 了两个引用,一个指向前一个元素,一个指向后一个元素。
-
线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
12. 说一下HashMap的实现原理?
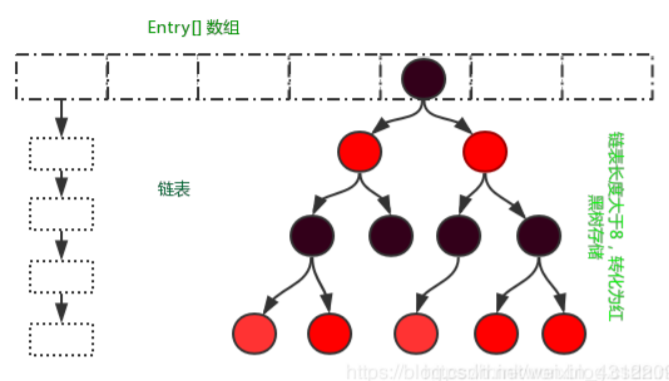
HashMap的数据结构: HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap 基于 Hash 算法实现的
- 当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数 组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。
- 如果key相同,则覆盖原始值;
- 如果key不同(出现冲突),则将当前的key-value放入链表中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
HashMap JDK1.8之前
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
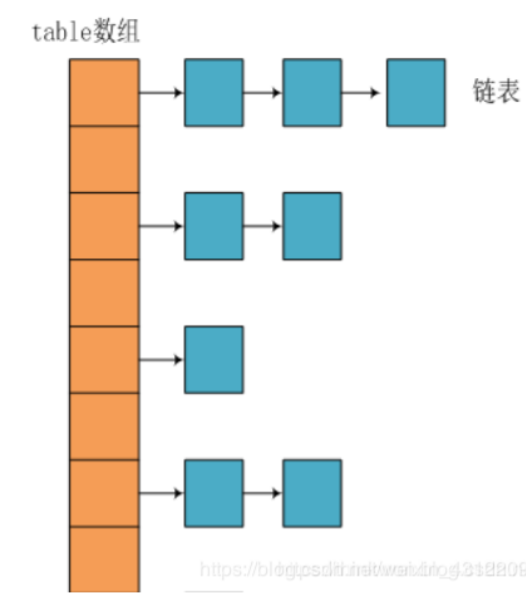
HashMap JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的 树的结点数小于等于临界值6个,则退化成链表。
13. HashMap的put方法的具体流程?
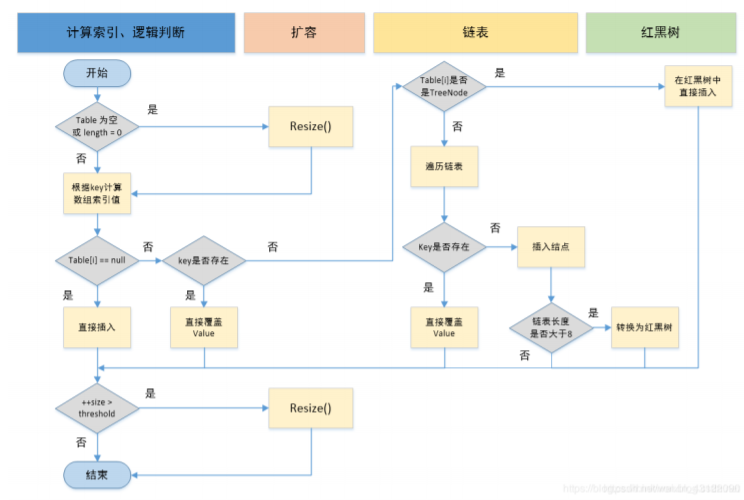
- 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
- 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向 ⑥,如果table[i]不为空,转向③;
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的 是hashCode以及equals;
- 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值 对,否则转向5;
- 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩 容。
14. 讲一讲HashMap的扩容机制
- 在jdk1.8中,resize方法是在hashmap中的键值对大于阀值(0.75)时或者初始化时,就调用resize方法进 行扩容;
- 每次扩展的时候,都是扩展2倍;
- 扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一 次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12) , 这个时候在扩 容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,在1.7 中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据 在同一个桶的位置中进行判断(e.hash & oldCap)是否为0,重新进行hash分配后,该元素的位置 要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
15. ConcurrentHashMap 底层具体实现知道吗?
ConcurrentHashMap 是一种线程安全的高效Map集合
底层数据结构:
-
JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,
-
JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段 数据时,其他段的数据也能被其他线程访问。
在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现
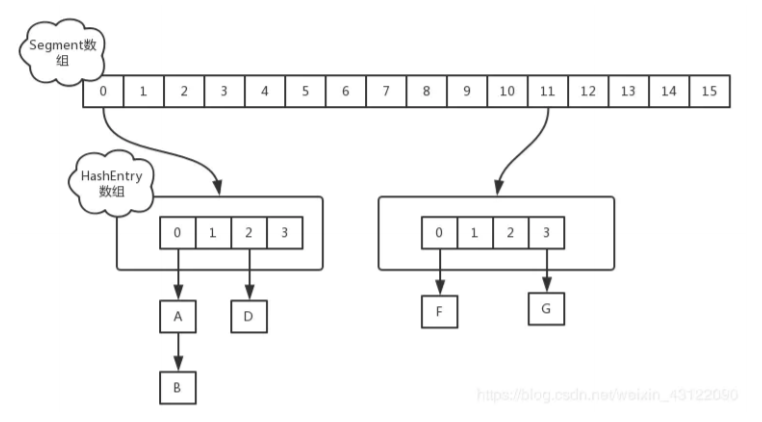
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一 种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构 的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修 改时,必须首先获得对应的 Segment的锁。
Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元 素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
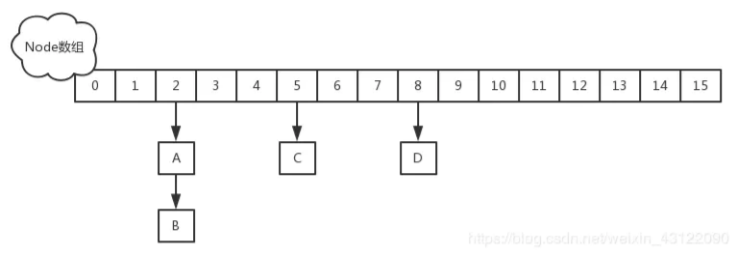
JDK1.8
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保 证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲 突,就不会产生并发 , 效率得到提升
16. 创建线程的四种方式
-
继承 Thread 类;
-
实现 Runnable 接口;
-
实现 Callable 接口;
-
使用匿名内部类方式
17. runnable 和 callable 有什么区别
- Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、 FutureTask配合可以用来获取异步执行的结果
- Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出 异常,可以获取异常信息 注:Callalbe接口支持返回执行结果,需要调用FutureTask.get()得到, 此方法会阻塞主进程的继续往下执行,如果不调用不会阻塞。
18. 加锁的方式有哪些 ?
使用synchronized关键字
使用Lock锁
synchronized和Lock有什么区别 ?
首先synchronized是Java内置关键字,在JVM层面,Lock是个Java类;
synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁; 而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
19. 如果你提交任务时,线程池队列已满,这时会发生什么
有俩种可能:
- 如果使用的是无界队列 LinkedBlockingQueue,也就是无界队列的话,没关系,继续添加任务到 阻塞队列中等待执行,因为 LinkedBlockingQueue 可以近乎认为是一个无穷大的队列,可以无限存放 任务
- 如果使用的是有界队列比如 ArrayBlockingQueue,任务首先会被添加到ArrayBlockingQueue 中ArrayBlockingQueue 满了,会根据maximumPoolSize 的值增加线程数量,如果增加了线程数量 还是处理不过来,ArrayBlockingQueue 继续满,那么则会使用拒绝策略RejectedExecutionHandler 处理满了的任务,默认是 AbortPolicy
19. 在你们的项目中有没有使用到线程池
我们的项目中很多地方使用了线程池 , 使用的场景经常有如下几种情况
-
业务层处理分多个业务线 , 多条业务线的优先级有高有低 , 使用异步线程池执行优先级较低的业务
比如: 搜索历史记录的异步保存 , 用户行为数据异步入库
-
任务很多很重 , 比如说 : 现在有1000w数据需要进行统计运算 (10个线程 每个线程计算100w数据 , 计算完毕之后把10个线程结算结果合并即可)
每天晚上计算运营统计数据 , 售货机补货数据计算
20. 你了解的线程池的种类有哪些 ?
-
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回 收空闲线程,若无可回收,则新建线程。
-
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列 中等待。
-
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
-
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。

![[ISCTF 2023]——Web、Misc较全详细Writeup、Re、Crypto部分Writeup](https://img-blog.csdnimg.cn/img_convert/24a49828657632c6ba5c7dbabeaceb60.png)




![[ 蓝桥杯Web真题 ]-视频弹幕](https://img-blog.csdnimg.cn/direct/b351eae9d647428e85bfe751cfedc070.gif)

![[SHCTF 2023]——week1-week3 Web方向详细Writeup](https://img-blog.csdnimg.cn/img_convert/37948bbb1fcd133814c65bbaa7ac813e.png)