前言
最近两周为了课程汇报学习了intel PIN这个动态插桩(dynamic instrument)工具,总体的学习感受还是挺累的。一方面,这个方向比较小众,相关的二手资料比较少,能参考的也就只有官方手册这种一手资料;另一方面,自己关于系统底层的知识还是有点不扎实,比如看到operand和opcode好久都没反应过来是什么。
总之这是一次学习曲线非常非常陡峭的学习经历,anyway,这次也是收获颇丰的。写这篇博客也是希望能帮助到一些有遇到相似问题的uu们。
这篇博客将主要包含以下几部分的内容:
- PIN的基础用法(看这部分之前建议先阅读《Practical Binary Analysis》第九章)
- 实例1:动态UPX脱壳器
- 实例2:动态RC4解密数据导出
参考资料
参考书:《Practical Binary Analysis》的第九章
官方手册:https://software.intel.com/sites/landingpage/pintool/docs/98749/Pin/doc/html/index.html
PIN基础知识
(注:基础知识部分建议参考《Practical Binary Analysis》第九章,这里只是补充一下我学习时感到疑惑的地方)
插桩大致流程
(这部分我没找到官方资料,所以是凭借自己的认识+部分实验结果推测的,如果有误,恳请指正)
以下以Instruction粒度进行展开,首先要调用INS_AddInstrumentFunction函数,传入一个形如static void instrument_insn(INS ins, void* v)的函数,这个函数会在PIN遇到一条新的指令的时候被调用
接下来,我们需要在这个传入的函数里面做判断,判断当前这条指令是不是我想要插桩的(例如,我只想要插桩MOV指令,那就是在这里做判断)
判断完成,确定要插桩之后,就需要调用INS_InsertCall等函数进行插桩,这个函数会要求你传入一个函数指针,这个函数指针对应的函数,在每次这条指令被执行时,都会被调用。被调用时,函数的参数就由INS_InsertCall后面跟的参数决定,例如,后面跟一个IARG_MEMORYREAD_EA,那么这个函数就会收到这条指令读内存的有效地址(effective address);如果后面跟一个IARG_UINT32和一个114514,那么这个函数每次被调用时,都会有个UINT32类型的参数,其值始终是114514
(具体IARG参数该怎么写,请参考官方文档https://software.intel.com/sites/landingpage/pintool/docs/98749/Pin/doc/html/group__INST__ARGS.html)
示例
main函数
int main(int argc, char* argv[])
{
PIN_InitSymbols();
if (PIN_Init(argc, argv)) {
return 1;
}
INS_AddInstrumentFunction(instrument_insn, NULL);
PIN_AddFiniFunction(print_results, NULL);
/* Never returns */
PIN_StartProgram();
return 0;
}
instrument_insn函数
static void instrument_insn(INS ins, void* v)
{
OPCODE code = INS_Opcode(ins);
if (INS_IsMemoryRead(ins) && INS_OperandCount(ins) == 2 && INS_OperandIsReg(ins, 0) && INS_OperandWrittenOnly(ins, 0)) {
UINT32 opCnt = INS_OperandCount(ins);
if (opCnt != 2)
return;
if (!INS_OperandIsReg(ins, 0) || !INS_OperandIsMemory(ins, 1))
return;
REG tmpOpReg = INS_OperandReg(ins, 0);
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR)trace_mov,
IARG_MEMORYREAD_EA,
IARG_MEMORYREAD_SIZE,
IARG_UINT32,(UINT32)tmpOpReg,
IARG_END
);
}
}
trace_mov函数
static void trace_mov(ADDRINT ea,UINT32 size,UINT32 tmpReg) {
lastModifyAddr[tmpReg] = ea;
lastModifySize[tmpReg] = size;
}
首先,每当PIN发现一条之前没看过的指令时,都会调用一次instrument_insn函数,并把那条指令作为参数传递过去,然后在instrument_insn里面就可以通过各种INS_开头的函数来间接获取关于这条指令的信息,例如获取操作码(opcode),操作数(operand)个数,第一个操作数是不是寄存器等
然后在instrument_insn函数里就可以根据这些信息作出判断是否需要插桩,如果需要,那么就调用INS_InsertPredicatedCall正式进行插桩(INS_InsertPredicatedCall 和 INS_InsertCall 的区别请自行查阅官方文档)
下面来看INS_InsertPredicatedCall的参数,第二个IPOINT_BEFORE表示在指令执行之前插桩,也就是在指令执行之前先调用我们的trace_mov函数
从第四个参数开始,就是trace_mov函数的参数了,第一个是IARG_MEMORYREAD_EA,查阅官方文档可以知道,这个表示读内存的有效地址,那么trace_mov函数的第一个参数就是ADDRINT的,代表这条指令读内存时的有效地址,trace_mov接收到的这个参数值是随着指令执行而动态计算出的(区别于后面的IARG_UINT32);第六个参数是IARG_UINT32,表示后面跟的一个UINT32类型的数字是参数值,trace_mov接收到的这个参数值是不会随着指令执行而动态计算的,也就是说,它接收到的永远都是最开始插桩时传入的那个值
如何运行
这部分参考了官方文档,最简单的办法就是修改source/tools/MyPinTool/MyPinTool.cpp,然后在这个目录下make clean && make即可
然后退到pin的根目录,运行
./pin -t /home/qzero/pin-3.28-98749-g6643ecee5-gcc-linux/source/tools/MyPinTool/obj-intel64/MyPinTool.so -- ~/rc4
其中-t后面跟的是刚才编译产生的so文件的路径,两个–符号后面跟的是要执行插桩的可执行文件
(官方手册里面也提到了通过attach的方式对正在运行的程序进行插桩的方法,这里不赘述了)
动态UPX脱壳器
加壳原理
这部分建议配合《Practical Binary Analysis》的第九章第五小节食用
这里引用书上的图片来说明加壳的原理

UPX在加壳时会通过压缩算法把原来的可执行程序压缩,变成一堆二进制数据,然后制造一个新的程序,把刚才压缩得到的二进制数据放进这个程序的数据段里面,这个新的程序主要是起一个引导的作用(类似于GRUB?),这个新的程序首先会把数据段里的压缩数据解压到内存里面,然后跳转到解压后的程序的入口处(即OEP),至此,新程序的使命完成
前提假设
不同的加壳软件会有不同的处理方式,加壳算法可以设计的十分复杂,这里为了后续的讨论能继续进行,参照书上,做出如下假设:我们要处理的加壳后的可执行文件在执行的时候,会一下子把所有的原可执行文件解压到一块连续的内存中
脱壳思路
突破点在于程序最终会跳转到OEP去,而OEP所在的内存区域是程序有写操作的内存区域
那么就可以记录程序所有写操作发生的内存地址,然后每当出现一次跳转时,都判断一下目标地址是不是之前写操作发生的地址,一般而言,跳转只会在代码之间发生,不会跳转到可读写的区域去,所以这种跳转大概率就是往OEP的跳转
具体实现
完整的实现代码在附录中给出(由于PIN版本更新,有些api已废弃,所以在原书代码基础上做了少许修改)
以下只针对关键部分展开
首先在main函数里添加两个插桩函数,一个用于监控每一条指令,另一个则是在程序执行结束之后,用来打印日志的
INS_AddInstrumentFunction(instrument_mem_cflow, NULL);
PIN_AddFiniFunction(fini, NULL);
接下来是监控每条指令的函数代码,在这里首先会判断指令是否有写内存的操作,如果有,那么在指令执行之前把写内存区域的有效地址保存到一个全局临时变量里面,然后在指令执行完成之后,根据实际写入的大小,把写入后内存给复制一份,进行存档,用于之后的导出操作
if (INS_IsMemoryWrite(ins)){
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR)queue_memwrite,
IARG_MEMORYWRITE_EA,
IARG_END
);
if (INS_HasFallThrough(ins)) {
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)log_memwrite,
IARG_MEMORYWRITE_SIZE,
IARG_END
);
}
if (INS_IsBranch(ins) || INS_IsCall(ins)) {
INS_InsertPredicatedCall(
ins, IPOINT_TAKEN_BRANCH, (AFUNPTR)log_memwrite,
IARG_MEMORYWRITE_SIZE,
IARG_END
);
}
}
这是两个监控内存的函数实现(具体细节建议看书,这里只理一下大致思路)
static void
queue_memwrite(ADDRINT addr)
{
saved_addr = addr;
}
static void
log_memwrite(UINT32 size)
{
ADDRINT addr = saved_addr;
for (ADDRINT i = addr; i < addr + size; i++) {
shadow_mem[i].w = true;
PIN_SafeCopy(&shadow_mem[i].val, (const void*)i, 1);
}
}
关于为什么要添加两个函数,为什么不能在指令执行完成之后把实际写入大小和有效地址都获取:
因为官方文档写了,IARG_MEMORYWRITE_EA只适用于IPOINT_BEFORE

所以这也是个无奈之举
回到正题,如果这个指令是跳转指令呢?那么就判断它跳入的地址是不是之前写过的地址
if (CaptureAllJumps.Value()) {
if (INS_IsControlFlow(ins) && INS_OperandCount(ins) > 0) {
INS_InsertCall(
ins, IPOINT_BEFORE, (AFUNPTR)check_indirect_ctransfer,
IARG_INST_PTR, IARG_BRANCH_TARGET_ADDR,
IARG_END
);
}
}
else {
if ((INS_IsIndirectControlFlow(ins)) && INS_OperandCount(ins) > 0) {
INS_InsertCall(
ins, IPOINT_BEFORE, (AFUNPTR)check_indirect_ctransfer,
IARG_INST_PTR, IARG_BRANCH_TARGET_ADDR,
IARG_END
);
}
}
这里传给check_indirect_ctransfer函数的参数就是当前的地址,和目标地址
以下是check_indirect_ctransfer函数的实现
static void
check_indirect_ctransfer(ADDRINT ip, ADDRINT target)
{
mem_cluster_t c;
shadow_mem[target].x = true;
if (shadow_mem[target].w && !in_cluster(target)) {
/* control transfer to a once-writable memory region, suspected transfer
* to original entry point of an unpacked binary */
set_cluster(target, &c);
clusters.push_back(c);
/* dump the new cluster containing the unpacked region to file */
mem_to_file(&c, target,ip);
/* we don't stop here because there might be multiple unpacking stages */
}
}
这个函数做的事情就是判断跳转过去的地址是不是被写过,如果是,那就把这个地址附近连续被写过的内存区域导出到文件里
由于打印日志的部分和二进制插桩无关,所以这里就不分析了
实验验证
实验环境
upx 3.96
pin-3.28-98749-g6643ecee5-gcc-linux
kali linux
VMware workstation 16 pro
实验操作
使用upx加壳后进行脱壳操作
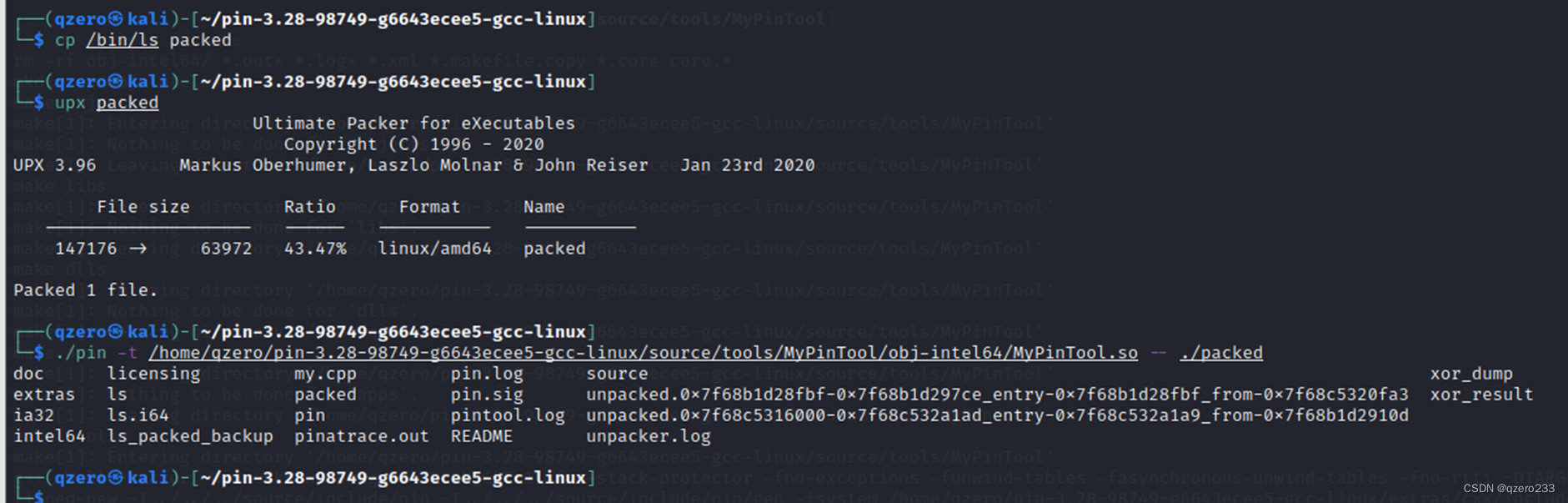
发现最后导出了两个文件,先看大小比较大的那个,这不是一个完整的elf格式的文件(如果按照书上的说法的话,导出的应该是一个完整的elf文件,可能是upx版本的原因)
分析大文件
但是使用十六进制编辑器可以得知,导出的文件的确是原始文件/bin/ls的一部分
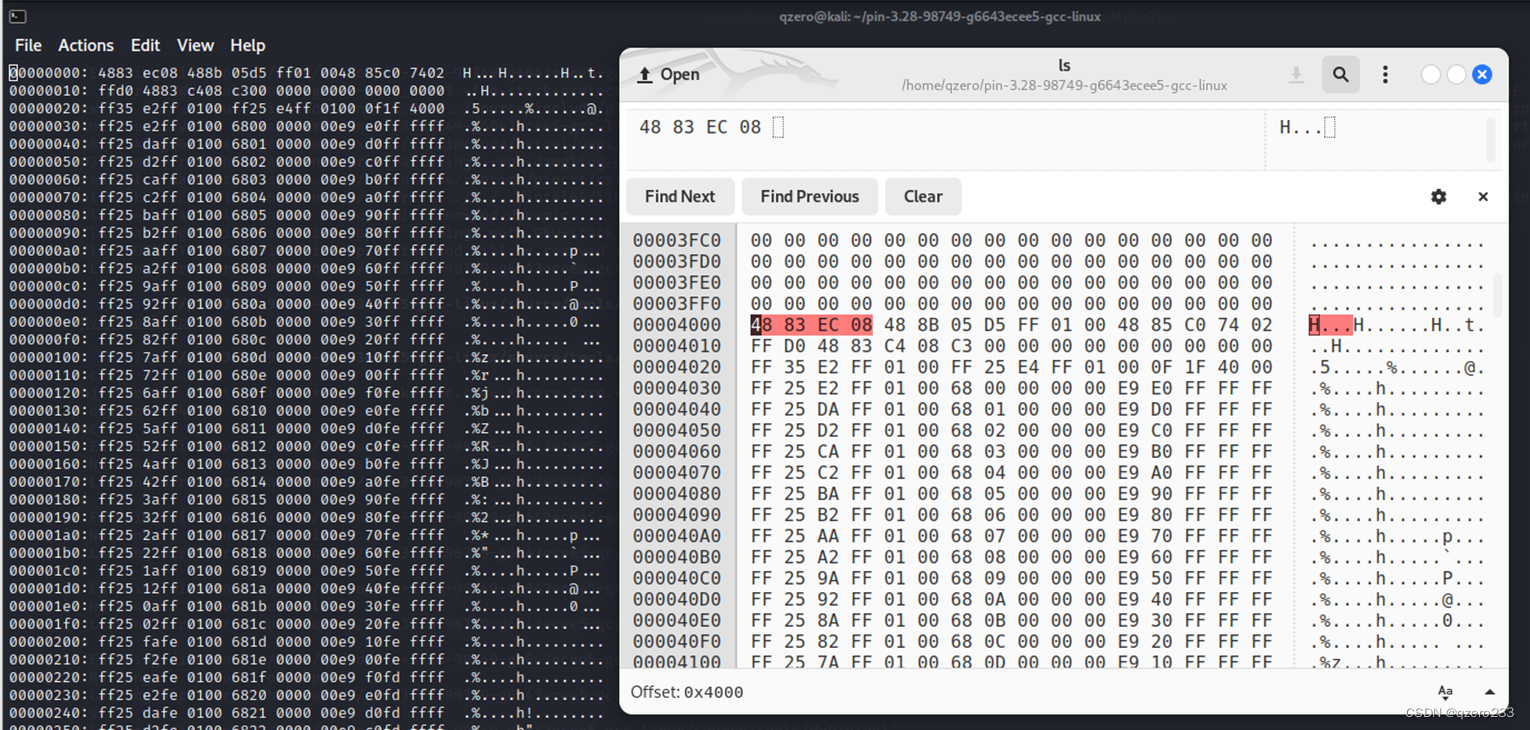
并且进一步的,使用readelf可以知道,这个大文件的内容是对应了原始文件的init代码段到fini代码段的内容
所以导出的大文件是原始文件代码段的内容,是纯由指令组成的文件,这个文件没有elf头和数据段,无法运行,但是可以使用一些开源工具直接进行反汇编
这里我使用的是udcli进行反汇编(github链接https://github.com/vmt/udis86),按照提示编译即可
注意在反汇编时要加-64这个参数,实验时使用的是64位的系统,如果不指定的话可能会导致反汇编出现错误结果(例如64位的立即数地址被解读为32位的立即数地址和下一条指令)
分析小文件
使用udcli对小文件进行反汇编之后,发现它有很多的call和jmp指令
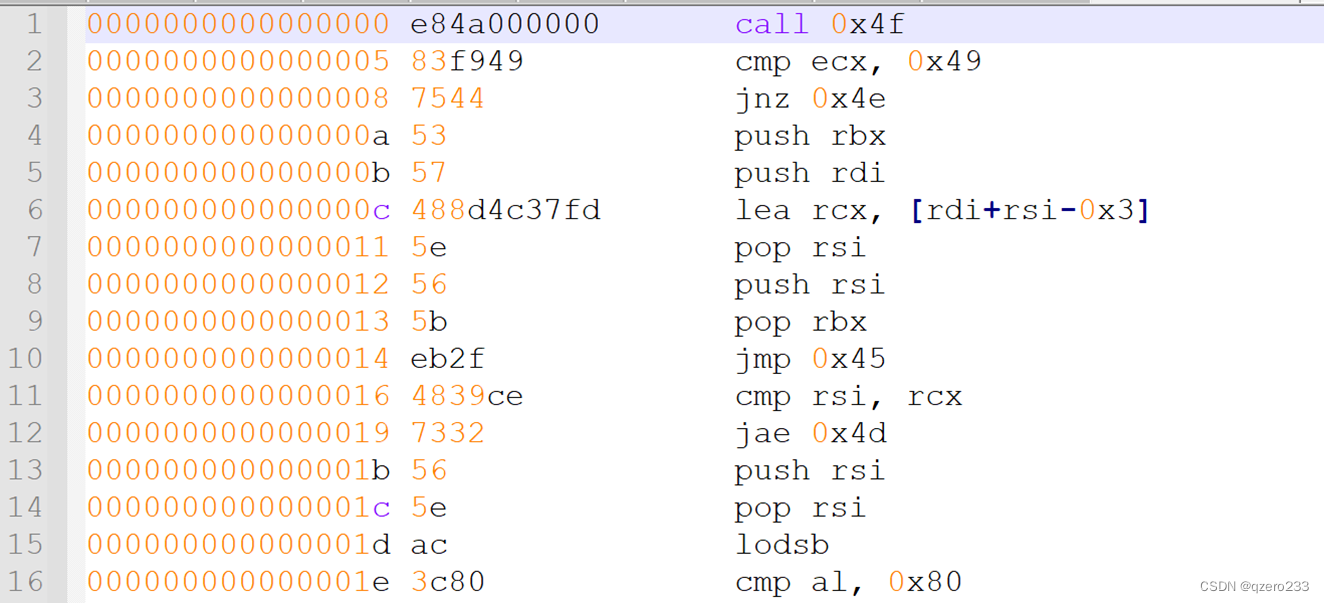
这个时候已经开始怀疑这个小文件也是一个UPX的引导程序的代码
更进一步的,通过实验发现,不同文件通过相同版本的upx加壳之后再脱壳,得到的这个小文件是一样的

并且还可以验证,对于不同版本的upx,最后得到的这个小文件不一样,此时已经有80%的把握认为我的猜想是正确的
最终石锤的证据是:跳转到原程序OEP的jmp指令恰好是在这个小文件里的,因为如下图

小文件所在的内存区域:0x7efc0e43f10f-0x7efc0e43f91e
跳转到大文件的jmp指令地址:0x7efc0e43f25d
这个值恰好位于以上两者之间,所以由此可以确定,这个小文件就是upx的一个引导程序的,并且不同版本的upx有着不同的引导程序
由此也可以大致推断出UPX加壳的具体实现方法,如下图
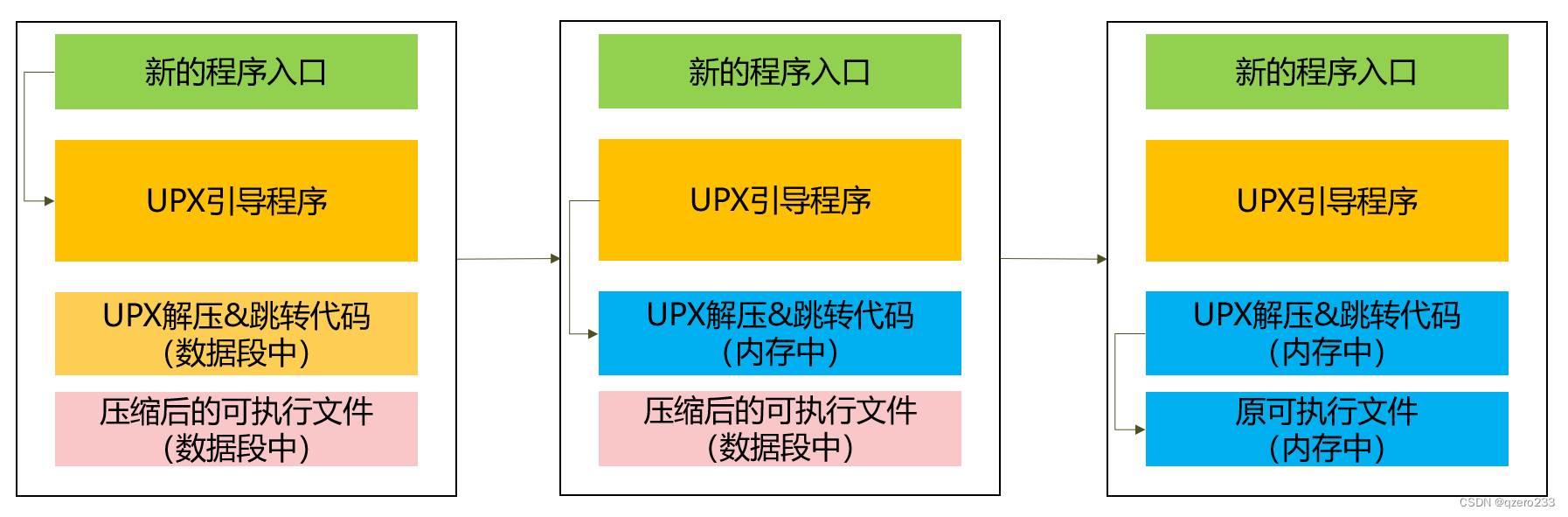
(注:上图中的"UPX解压&跳转代码"就是上文中提到的“引导程序”,这图是汇报ppt上截的,不好改了呜呜呜)
UPX加壳经历了两次解压和跳转,一次是解压&跳转到一个引导程序中,另一个是从引导程序跳转到真正的OEP
动态RC4解密数据导出
RC4算法
RC4算法可以分为两个部分,一个是密钥生成部分(init),一个是加解密部分,其中密钥生成部分会得到一个长度为256字节的s数组,而加解密部分的操作是遍历待处理的数据,把其中的每个字节都和s数组中的某一个数进行异或操作
这种加解密操作的原理是:一个数和另一个数异或两次之后,得到的结果仍然是最初的那个数,即 a xor b xor b = a
所以说,只要输入进加解密函数中的s数组相同,那么密文经过一通异或操作之后就一定会得到最初的明文
RC4具体实现代码如下(来源:百度百科)
/*初始化函数*/
void rc4_init(unsigned char*s,unsigned char*key, unsigned long Len)
{
int i=0,j=0;
//char k[256]={0};
unsigned char k[256]={0};
unsigned char tmp=0;
for(i=0;i<256;i++) {
s[i]=i;
k[i]=key[i%Len];
}
for(i=0;i<256;i++) {
j=(j+s[i]+k[i])%256;
tmp=s[i];
s[i]=s[j];//交换s[i]和s[j]
s[j]=tmp;
}
}
/*加解密*/
void rc4_crypt(unsigned char*s,unsigned char*Data,unsigned long Len)
{
int i=0,j=0,t=0;
unsigned long k=0;
unsigned char tmp;
for(k=0;k<Len;k++)
{
i=(i+1)%256;
j=(j+s[i])%256;
tmp=s[i];
s[i]=s[j];//交换s[x]和s[y]
s[j]=tmp;
t=(s[i]+s[j])%256;
Data[k]^=s[t];
}
}
分析
首先可以明白一点,那就是我们不能区分一个RC4操作是加密还是解密,因为它们的操作都一模一样,一个密文扔进rc4_crypt可以得到明文,一个明文扔进去可以得到密文,所以误判是一定会存在的
接下来可以注意到,整个RC4加解密操作最具有特征的地方就是:它会对一个连续的内存空间的每一个字节都进行一次异或操作,这就是我们的突破口
实现思路
和上面的脱壳器类似,记录发生异或操作的每一个内存地址,并且记录内存地址的内容,程序执行结束之后,找到连续的被异或过的内存块,导出即可
但是这里的难点在于,写内存肯定有一个明确的地址,但是进行异或操作的可以是一个寄存器,可以是一个立即数,所以操作数到内存的映射是比较困难的部分
具体实现时,可以劫持所有的MOV系列的指令,记录每一个寄存器存储的值所来自的内存地址,然后当遇到XOR指令时,就根据这个记录来获取寄存器对应的数的内存地址
具体实现
这里就偷了个懒,由于RC4的加解密操作是分别从两个数组中取数来进行异或,所以大概率会被编译成REG XOR REG的情况,所以以下的代码也只考虑这种情况
(代码里还偷了个懒,XOR操作数有两个寄存器,其中一个是src一个是dst,我这里把两个对应的地址的内容都记录为了XOR的结果,反正最后被导出的解密内容一定是正确的,其实现在细想应该学脱壳器,使用内存复制的)
同样的,这里也只解释关键部分,完整代码见附录
首先是插桩MOV指令的代码,这里判断一下,这里要求MOV的dst是寄存器并且src是内存区域,传入trace_xor的参数是读取的有效地址和读取大小,以及这个寄存器的编号(其实REG是一个enum的对象,可以强转成int)
注意,这里使用到了EA,按照官方文档,只能是在IPOINT_BEFORE使用
if (INS_IsMov(ins)) {
UINT32 opCnt = INS_OperandCount(ins);
if (opCnt != 2)
return;
if (!INS_OperandIsReg(ins, 0) || !INS_OperandIsMemory(ins, 1))
return;
REG tmpOpReg = INS_OperandReg(ins, 0);
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR)trace_mov,
IARG_MEMORYREAD_EA,
IARG_MEMORYREAD_SIZE,
IARG_UINT32,(UINT32)tmpOpReg,
IARG_END
);
}
trace函数就用一个map记录一下每个寄存器所存储值的地址即可
map<UINT32, ADDRINT> lastModifyAddr;
map<UINT32, UINT32> lastModifySize;
static void trace_mov(ADDRINT ea,UINT32 size,UINT32 tmpReg) {
lastModifyAddr[tmpReg] = ea;
lastModifySize[tmpReg] = size;
}
接下来插桩XOR指令,按照上面的简化,只考虑REG XOR REG
传递给trace函数的参数就是寄存器类型和目标寄存器中存储的值
OPCODE code = INS_Opcode(ins);
if (code == XED_ICLASS_XOR) {
if (!INS_OperandIsReg(ins, 0) || !INS_OperandIsReg(ins,1)) {
return;
}
REG opReg0 = INS_OperandReg(ins, 0);
REG opReg1 = INS_OperandReg(ins, 1);
REG dstReg;
if (INS_OperandWritten(ins, 0))
dstReg = opReg0;
else
dstReg = opReg1;
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)trace_xor,
IARG_UINT32,(UINT32)opReg0,
IARG_REG_VALUE, dstReg,
IARG_END
);
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)trace_xor,
IARG_UINT32, (UINT32)opReg1,
IARG_REG_VALUE, dstReg,
IARG_END
);
}
trace函数里面就把目标寄存器中存储的值赋值给地址
注意:这里存储result要用小端存储
static void trace_xor(UINT32 opReg,ADDRINT result) {
if (lastModifyAddr.count(opReg) <= 0)
return;
ADDRINT xorEa = lastModifyAddr[opReg];
UINT32 size = lastModifySize[opReg];
if (xorEa != 0) {
for (UINT32 j = 0; j < size; j++) {
xorAddrs.push_back(xorEa + j);
UINT8 byte = (result >> (j * 8)) & 0xFF;
memRecord[xorEa + j] = byte;
}
}
}
最后在程序执行结束之后,找到连续的异或过的内存区域,把它们导出到文件即可
注意这里要考虑阈值的问题,因为一个int就4字节了,连续4字节异或都进行导出,那么误判率会很高,这里的阈值设置的是4字节以上才会导出
具体实现时,首先对地址vector进行排序,去重,然后查找连续区域,大于4字节的就保存下来
最终导出部分的代码如下:
class mem_cluster {
public:
ADDRINT start;
UINT32 size;
mem_cluster(ADDRINT start, UINT32 size) :start(start), size(size) {}
};
static void print_results(INT32 code, void* v) {
sort(xorAddrs.begin(), xorAddrs.end());
xorAddrs.erase(unique(xorAddrs.begin(), xorAddrs.end()), xorAddrs.end());
vector<mem_cluster> clusters;
ADDRINT start = xorAddrs[0];
ADDRINT last = xorAddrs[0];
for (vector<long unsigned int>::size_type i = 1; i < xorAddrs.size(); i++) {
ADDRINT current = xorAddrs[i];
if (current == last) {
continue;
}
if (current - last > 1) {
//Not continue
UINT32 clusterSize = last - start + 1;
//TODO only those chunks whose size > 4 bytes accepted
if (clusterSize > 4) {
clusters.push_back(mem_cluster(start, clusterSize));
}
start = current;
}
last = current;
}
for (mem_cluster cluster : clusters) {
cout << "From " << (UINT64)cluster.start << " size " << (UINT64)cluster.size << endl;
//Dump it
char filename[256];
snprintf(filename, sizeof(filename), "dump_from_0x%jx_size_%d",cluster.start,cluster.size);
FILE* f = fopen(filename, "wb");
if (!f) {
printf("failed to open file '%s' for writing\n", filename);
}else {
for (UINT32 i = 0; i < cluster.size; i++) {
fwrite((const void*)&memRecord[cluster.start + i], 1, 1, f);
}
fclose(f);
}
cout << "Write to file " << filename << endl;
}
}
实验验证
编写一个简单的RC4测试程序,其中RC4实现部分参考了百度百科
这个程序做的事情就是生成30字节的数据,第i字节的值就是i(从0开始计数),然后对这个数据进行加密,输出一次数据,然后再解密一次,输出一次数据
验证程序如下
#include <iostream>
#include <string.h>
using namespace std;
void rc4(const char* key, int key_len, unsigned char* data,int data_len) {
unsigned char T[256];
unsigned char S[256];
for (int i = 0; i < 256; i++) {
S[i] = i;
T[i] = key[i % key_len];
}
int i = 0, j = 0;
for (i = 0; i < 256; i++) {
j = (j + S[i] + T[i]) % 256;
swap(S[i], S[j]);
}
i = 0;
j = 0;
for (int k = 0; k < data_len; k++)
{
i = (i + 1) % 256;
j = (j + S[i]) % 256;
swap(S[i], S[j]);
int t = (S[i] + S[j]) % 256;
data[k] ^= S[t];
}
}
int main() {
const char* key = "this is a key";
int data_len = 30;
unsigned char* data = new unsigned char[data_len];
for (int i = 0; i < data_len; i++) {
data[i] = i;
}
rc4(key, strlen(key), data, data_len);
for (int i = 0; i < data_len; i++) {
cout << (int)data[i] << " ";
}
cout << endl;
rc4(key, strlen(key), data, data_len);
for (int i = 0; i < data_len; i++) {
cout << (int)data[i] << " ";
}
return 0;
}
编译,对这个程序使用编写的Pin tool进行插桩分析,得到导出的文件

可以看到,导出了非常多的文件,这里我们直接打开大小为30字节的文件
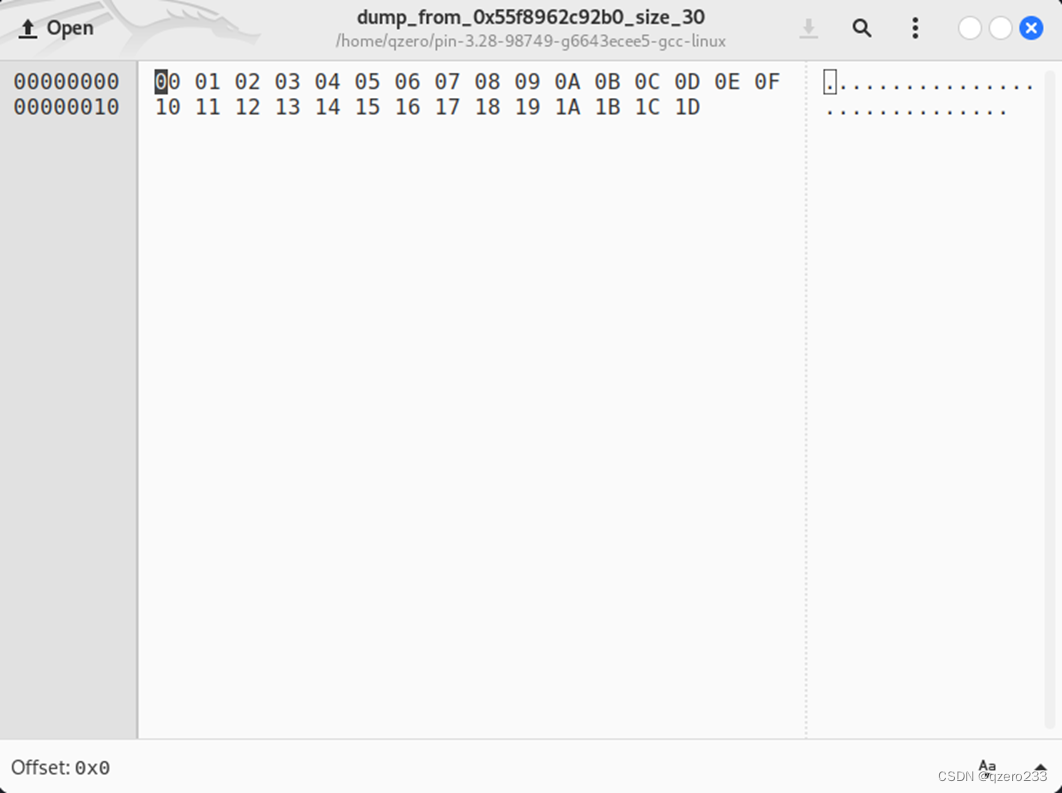
可以看到,文件内容和预期相符
不足与展望
首先,False Positive的问题依然严重,原因之一是:一个int就4字节,阈值很难把握
其次,MOV指令类型很多,比如MOVZX,代码并没有完全覆盖到
另外,XOR的种类也有很多,如下图
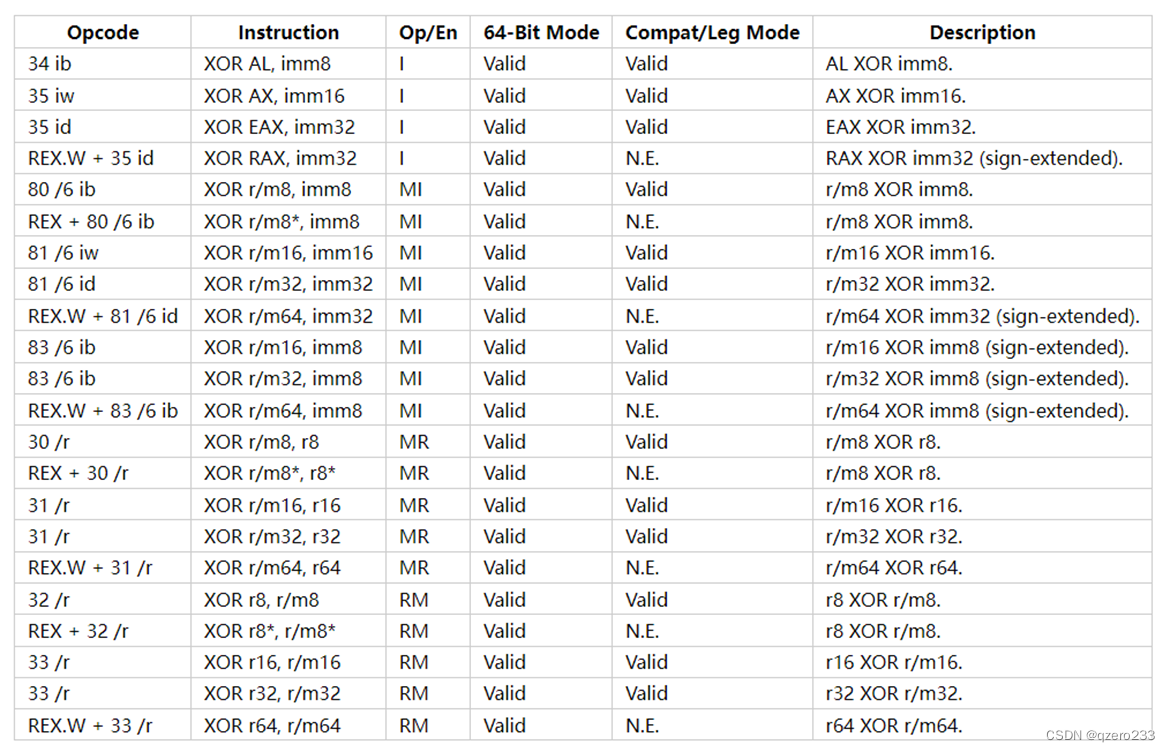
在x86_64的指令集里面,XOR有22种类型,不只有REG XOR REG的类型。事实上,我也用我这个pin tool尝试过去导出《Practical Binary Analysis》第五章给出的ctf文件的RC4解密内容,但是没成功,通过ida进行逆向发现,它的XOR类型是 XOR [rax] reg,这是代码没有涵盖到的,所以没能成功导出解密内容
心得体会
二进制动态插桩是一个很有用的工具,尤其是当目标操作的signature非常明确的情况下,但是如何排除false positive是个需要仔细思考的问题
就学习体验而言,整个过程的学习曲线是非常陡峭的,这部分相关的中文资料几乎是没有,英文资料也很少,大多数时候只能是看官方的手册,然后通过实验进行学习
但是整个过程还是收获颇多的,这次学习过程中,我学到了一种比单步调试更有效的对二进制代码进行动态分析的方法,而且也顺带学习了怎么去阅读intel x86_64 指令集手册(说实话,最开始看到opcode那里一大堆符号还是挺懵逼的)
最后的最后,创作不易,如果这篇文章对你有帮助,希望能得到你的一个点赞和收藏
附录
动态UPX脱壳器 完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <map>
#include <vector>
#include <algorithm>
#include <string>
#include <iostream>
#include "pin.H"
using namespace std;
typedef struct mem_access {
mem_access() : w(false), x(false), val(0) {}
mem_access(bool ww, bool xx, unsigned char v) : w(ww), x(xx), val(v) {}
bool w;
bool x;
unsigned char val;
} mem_access_t;
typedef struct mem_cluster {
mem_cluster() : base(0), size(0), w(false), x(false) {}
mem_cluster(ADDRINT b, unsigned long s, bool ww, bool xx) : base(b), size(s), w(ww), x(xx) {}
ADDRINT base;
unsigned long size;
bool w;
bool x;
} mem_cluster_t;
FILE* logfile;
std::map<ADDRINT, mem_access_t> shadow_mem;
std::vector<mem_cluster_t> clusters;
ADDRINT saved_addr;
KNOB<string> KnobLogFile(KNOB_MODE_WRITEONCE, "pintool", "l", "unpacker.log", "log file");
KNOB<bool> CaptureAllJumps(KNOB_MODE_WRITEONCE, "pintool", "a", "0", "Capture all jumps");
/*****************************************************************************
* Analysis functions *
*****************************************************************************/
void
fsize_to_str(unsigned long size, char* buf, unsigned len)
{
int i;
double d;
const char* units[] = { "B", "kB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB" };
i = 0;
d = (double)size;
while (d > 1024) {
d /= 1024;
i++;
}
if (!strcmp(units[i], "B")) {
snprintf(buf, len, "%.0f%s", d, units[i]);
}
else {
snprintf(buf, len, "%.1f%s", d, units[i]);
}
}
static void
mem_to_file(mem_cluster_t* c, ADDRINT entry, ADDRINT from)
{
FILE* f;
char buf[128];
fsize_to_str(c->size, buf, 128);
fprintf(logfile, "extracting unpacked region 0x%016jx (%9s) %s%s entry 0x%016jx\n",
c->base, buf, c->w ? "w" : "-", c->x ? "x" : "-", entry);
snprintf(buf, sizeof(buf), "unpacked.0x%jx-0x%jx_entry-0x%jx_from-0x%jx",
c->base, c->base + c->size, entry,from);
f = fopen(buf, "wb");
if (!f) {
fprintf(logfile, "failed to open file '%s' for writing\n", buf);
}
else {
for (ADDRINT i = c->base; i < c->base + c->size; i++) {
if (fwrite((const void*)&shadow_mem[i].val, 1, 1, f) != 1) {
fprintf(logfile, "failed to write unpacked byte 0x%jx to file '%s'\n", i, buf);
}
}
fclose(f);
}
}
static void
set_cluster(ADDRINT target, mem_cluster_t* c)
{
ADDRINT addr, base;
unsigned long size;
bool w, x;
std::map<ADDRINT, mem_access_t>::iterator i, j;
j = shadow_mem.find(target);
assert(j != shadow_mem.end());
/* scan back to base of cluster */
base = target;
w = false;
x = false;
for (i = j; ; i--) {
addr = i->first;
if (addr == base) {
/* this address is one less than the previous one, so this is still the
* same cluster */
if (i->second.w) w = true;
if (i->second.x) x = true;
base--;
}
else {
/* we've reached the start of the cluster but overshot it by one byte */
base++;
break;
}
if (i == shadow_mem.begin()) {
base++;
break;
}
}
/* scan forward to end of cluster */
size = target - base;
for (i = j; i != shadow_mem.end(); i++) {
addr = i->first;
if (addr == base + size) {
if (i->second.w) w = true;
if (i->second.x) x = true;
size++;
}
else {
break;
}
}
c->base = base;
c->size = size;
c->w = w;
c->x = x;
}
static bool
in_cluster(ADDRINT target)
{
mem_cluster_t* c;
for (unsigned i = 0; i < clusters.size(); i++) {
c = &clusters[i];
if (c->base <= target && target < c->base + c->size) {
return true;
}
}
return false;
}
static void
check_indirect_ctransfer(ADDRINT ip, ADDRINT target)
{
mem_cluster_t c;
shadow_mem[target].x = true;
if (shadow_mem[target].w && !in_cluster(target)) {
/* control transfer to a once-writable memory region, suspected transfer
* to original entry point of an unpacked binary */
set_cluster(target, &c);
clusters.push_back(c);
/* dump the new cluster containing the unpacked region to file */
mem_to_file(&c, target,ip);
/* we don't stop here because there might be multiple unpacking stages */
}
}
static void
queue_memwrite(ADDRINT addr)
{
saved_addr = addr;
}
static void
log_memwrite(UINT32 size)
{
ADDRINT addr = saved_addr;
for (ADDRINT i = addr; i < addr + size; i++) {
shadow_mem[i].w = true;
PIN_SafeCopy(&shadow_mem[i].val, (const void*)i, 1);
}
}
static void
instrument_mem_cflow(INS ins, void* v)
{
if (INS_IsMemoryWrite(ins)){
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR)queue_memwrite,
IARG_MEMORYWRITE_EA,
IARG_END
);
if (INS_HasFallThrough(ins)) {
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)log_memwrite,
IARG_MEMORYWRITE_SIZE,
IARG_END
);
}
if (INS_IsBranch(ins) || INS_IsCall(ins)) {
INS_InsertPredicatedCall(
ins, IPOINT_TAKEN_BRANCH, (AFUNPTR)log_memwrite,
IARG_MEMORYWRITE_SIZE,
IARG_END
);
}
}
if (CaptureAllJumps.Value()) {
if (INS_IsControlFlow(ins) && INS_OperandCount(ins) > 0) {
INS_InsertCall(
ins, IPOINT_BEFORE, (AFUNPTR)check_indirect_ctransfer,
IARG_INST_PTR, IARG_BRANCH_TARGET_ADDR,
IARG_END
);
}
}
else {
if ((INS_IsIndirectControlFlow(ins)) && INS_OperandCount(ins) > 0) {
INS_InsertCall(
ins, IPOINT_BEFORE, (AFUNPTR)check_indirect_ctransfer,
IARG_INST_PTR, IARG_BRANCH_TARGET_ADDR,
IARG_END
);
}
}
}
/*****************************************************************************
* Other functions *
*****************************************************************************/
static bool
cmp_cluster_size(const mem_cluster_t& c, const mem_cluster_t& d)
{
return c.size > d.size;
}
static void
print_clusters()
{
ADDRINT addr, base;
unsigned long size;
bool w, x;
unsigned j, n, m;
char buf[32];
std::vector<mem_cluster_t> clusters;
std::map<ADDRINT, mem_access_t>::iterator i;
/* group shadow_mem into consecutive clusters */
base = 0;
size = 0;
w = false;
x = false;
for (i = shadow_mem.begin(); i != shadow_mem.end(); i++) {
addr = i->first;
if (addr == base + size) {
if (i->second.w) w = true;
if (i->second.x) x = true;
size++;
}
else {
if (base > 0) {
clusters.push_back(mem_cluster_t(base, size, w, x));
}
base = addr;
size = 1;
w = i->second.w;
x = i->second.x;
}
}
/* find largest cluster */
size = 0;
for (j = 0; j < clusters.size(); j++) {
if (clusters[j].size > size) {
size = clusters[j].size;
}
}
/* sort by largest cluster */
std::sort(clusters.begin(), clusters.end(), cmp_cluster_size);
/* print cluster bar graph */
fprintf(logfile, "******* Memory access clusters *******\n");
for (j = 0; j < clusters.size(); j++) {
n = ((float)clusters[j].size / size) * 80;
fsize_to_str(clusters[j].size, buf, 32);
fprintf(logfile, "0x%016jx (%9s) %s%s: ",
clusters[j].base, buf,
clusters[j].w ? "w" : "-", clusters[j].x ? "x" : "-");
for (m = 0; m < n; m++) {
fprintf(logfile, "=");
}
fprintf(logfile, "\n");
}
}
static void
fini(INT32 code, void* v)
{
print_clusters();
fprintf(logfile, "------- unpacking complete -------\n");
fclose(logfile);
}
int
main(int argc, char* argv[])
{
if (PIN_Init(argc, argv) != 0) {
fprintf(stderr, "PIN_Init failed\n");
return 1;
}
logfile = fopen(KnobLogFile.Value().c_str(), "a");
if (!logfile) {
fprintf(stderr, "failed to open '%s'\n", KnobLogFile.Value().c_str());
return 1;
}
fprintf(logfile, "------- unpacking binary -------\n");
INS_AddInstrumentFunction(instrument_mem_cflow, NULL);
PIN_AddFiniFunction(fini, NULL);
PIN_StartProgram();
return 1;
}
动态RC4解密数据导出 完整代码
#include <asm-generic/unistd.h>
#include <stdio.h>
#include <iostream>
#include <map>
#include <vector>
#include <algorithm>
#include "pin.H"
using namespace std;
map<UINT32, ADDRINT> lastModifyAddr;
map<UINT32, UINT32> lastModifySize;
vector<ADDRINT> xorAddrs;
map<ADDRINT, UINT8> memRecord;
class mem_cluster {
public:
ADDRINT start;
UINT32 size;
mem_cluster(ADDRINT start, UINT32 size) :start(start), size(size) {}
};
static void trace_mov(ADDRINT ea,UINT32 size,UINT32 tmpReg) {
lastModifyAddr[tmpReg] = ea;
lastModifySize[tmpReg] = size;
}
static void trace_xor(UINT32 opReg,ADDRINT result) {
if (lastModifyAddr.count(opReg) <= 0)
return;
ADDRINT xorEa = lastModifyAddr[opReg];
UINT32 size = lastModifySize[opReg];
if (xorEa != 0) {
for (UINT32 j = 0; j < size; j++) {
xorAddrs.push_back(xorEa + j);
UINT8 byte = (result >> (j * 8)) & 0xFF;
memRecord[xorEa + j] = byte;
}
}
}
static void instrument_insn(INS ins, void* v)
{
OPCODE code = INS_Opcode(ins);
if (INS_IsMov(ins)) {
UINT32 opCnt = INS_OperandCount(ins);
if (opCnt != 2)
return;
if (!INS_OperandIsReg(ins, 0) || !INS_OperandIsMemory(ins, 1))
return;
REG tmpOpReg = INS_OperandReg(ins, 0);
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR)trace_mov,
IARG_MEMORYREAD_EA,
IARG_MEMORYREAD_SIZE,
IARG_UINT32,(UINT32)tmpOpReg,
IARG_END
);
}
if (code == XED_ICLASS_XOR) {
if (!INS_OperandIsReg(ins, 0) || !INS_OperandIsReg(ins,1)) {
return;
}
REG opReg0 = INS_OperandReg(ins, 0);
REG opReg1 = INS_OperandReg(ins, 1);
REG dstReg;
if (INS_OperandWritten(ins, 0))
dstReg = opReg0;
else
dstReg = opReg1;
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)trace_xor,
IARG_UINT32,(UINT32)opReg0,
IARG_REG_VALUE, dstReg,
IARG_END
);
INS_InsertPredicatedCall(
ins, IPOINT_AFTER, (AFUNPTR)trace_xor,
IARG_UINT32, (UINT32)opReg1,
IARG_REG_VALUE, dstReg,
IARG_END
);
}
}
static void print_results(INT32 code, void* v) {
sort(xorAddrs.begin(), xorAddrs.end());
xorAddrs.erase(unique(xorAddrs.begin(), xorAddrs.end()), xorAddrs.end());
vector<mem_cluster> clusters;
ADDRINT start = xorAddrs[0];
ADDRINT last = xorAddrs[0];
for (vector<long unsigned int>::size_type i = 1; i < xorAddrs.size(); i++) {
ADDRINT current = xorAddrs[i];
if (current == last) {
continue;
}
if (current - last > 1) {
//Not continue
UINT32 clusterSize = last - start + 1;
//TODO only those chunks whose size > 4 bytes accepted
if (clusterSize > 4) {
clusters.push_back(mem_cluster(start, clusterSize));
}
start = current;
}
last = current;
}
for (mem_cluster cluster : clusters) {
cout << "From " << (UINT64)cluster.start << " size " << (UINT64)cluster.size << endl;
//Dump it
char filename[256];
snprintf(filename, sizeof(filename), "dump_from_0x%jx_size_%d",cluster.start,cluster.size);
FILE* f = fopen(filename, "wb");
if (!f) {
printf("failed to open file '%s' for writing\n", filename);
}else {
for (UINT32 i = 0; i < cluster.size; i++) {
fwrite((const void*)&memRecord[cluster.start + i], 1, 1, f);
}
fclose(f);
}
cout << "Write to file " << filename << endl;
}
}
int main(int argc, char* argv[])
{
PIN_InitSymbols();
if (PIN_Init(argc, argv)) {
return 1;
}
INS_AddInstrumentFunction(instrument_insn, NULL);
PIN_AddFiniFunction(print_results, NULL);
/* Never returns */
PIN_StartProgram();
return 0;
}