def add_decomposed_rel_pos(
attn: torch.Tensor,
q: torch.Tensor,
rel_pos_h: torch.Tensor, 27,80的全零训练参数
rel_pos_w: torch.Tensor,
q_size: Tuple[int, int], (14,14)
k_size: Tuple[int, int],
) -> torch.Tensor:
计算相对位置嵌入
"""
Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
Args:
attn (Tensor): attention map.
q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
Returns:
attn (Tensor): attention map with added relative positional embeddings.
"""
q_h, q_w = q_size
k_h, k_w = k_size
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
总之计算得到的这俩位置嵌入都是14,14,80
B, _, dim = q.shape
r_q = q.reshape(B, q_h, q_w, dim)
400,14,14,80
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
400,14,14,14
attn = (
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
).view(B, q_h * q_w, k_h * k_w)
return attn
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
"""
Get relative positional embeddings according to the relative positions of
query and key sizes.
Args:
q_size (int): size of query q.
k_size (int): size of key k.
rel_pos (Tensor): relative position embeddings (L, C).
Returns:
Extracted positional embeddings according to relative positions.
"""
max_rel_dist = int(2 * max(q_size, k_size) - 1)
# Interpolate rel pos if needed.
if rel_pos.shape[0] != max_rel_dist:
如果输入的相对位置嵌入的长度不等于qk最大相对距离
# Interpolate rel pos.
rel_pos_resized = F.interpolate(
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
size=max_rel_dist,
mode="linear",
)
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
else:
rel_pos_resized = rel_pos
# Scale the coords with short length if shapes for q and k are different.
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
return rel_pos_resized[relative_coords.long()]
用的是default模型,大概2G
输入的图片是(480, 640, 3)的ndarray
transform成768,1024,3再改成1,3,768,1024的tensor
手写归一化后再pad成1,3,1024,1024
Sam(
(image_encoder): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1280, kernel_size=(16, 16), stride=(16, 16))
得到1,1280,64,64,并permute成1,64,64,1280。随后再加上1,64,64,1280位置编码(一个训练参数)
)
(blocks): ModuleList(
(0): Block(
拷贝一份当前输入x为shortcut
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(window_partition)
先把x给pad成1,70,70,1280
再view成1,5,14,5,14,1280
permuet得到25,14,14,1280 x,和pad_hw=(70,70)返回
(attn): Attention(输入x
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
得到25,14,14,3840,再reshape、permute得到3,25,16,196,80 qkv,再拆成q、k、v三个400,196,80
计算q@k后得到attn 400,196,196后通过add_decomposed_rel_pos得到400,196,196 attn
计算attn@v后再转转尺寸得到25,14,14,1280 x
(proj): Linear(in_features=1280, out_features=1280, bias=True)
得到25,14,14,1280 x
)
(window_unpartition)
把x各种调整尺寸得到1,64,64,1280 x
x = shortcut + x
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
还是1,64,64,1280 x
)
(1): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(2): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(3): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(4): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(5): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(6): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(7): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(8): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(9): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(10): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(11): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(12): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(13): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(14): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(15): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(16): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(17): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(18): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(19): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(20): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(21): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(22): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(23): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(24): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(25): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(26): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(27): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(28): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(29): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(30): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
(31): Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU()
)
)
)
(neck): Sequential(
(0): Conv2d(1280, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
得到1,256,64,64 features
)
(prompt_encoder): PromptEncoder(
没有点提示或bbox提示,所以稀疏嵌入为1,0,256的空张量
(pe_layer): PositionEmbeddingRandom()
里面有一个2,128的训练参数,叫做高斯位置编码矩阵
基于一个64,64的全一grid计算cumsum得到也是64,64的y_embed和x_embed
堆叠后有64,64,2 coords送入_pe_encoding
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
得到64,64,256 pe 再permute成1,256,64,64
(point_embeddings): ModuleList(
(0): Embedding(1, 256)
(1): Embedding(1, 256)
(2): Embedding(1, 256)
(3): Embedding(1, 256)
)
(not_a_point_embed): Embedding(1, 256)
(mask_downscaling): Sequential(
(0): Conv2d(1, 4, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU()
(3): Conv2d(4, 16, kernel_size=(2, 2), stride=(2, 2))
(4): LayerNorm2d()
(5): GELU()
(6): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1))
)
没有提供mask提示,所以稠密嵌入为训练参数self.no_mask_embed 1,256 reshape再expand得到的1,256,64,64
(no_mask_embed): Embedding(1, 256)
)
(mask_decoder): MaskDecoder(
这里有个输入image_pe来自提示编码器的get_dense_pe,其实就是pe_layer
(predict_masks)
将1,256的iou_token和4,256的mask_tokens拼接得到5,256,再修正一下尺寸得到1,5,256的output_tokens
再与sparse_prompt_embeddings拼接得到tokens 1,5,256
将features复制元素到1,256,64,64,再加上dense_prompt_embeddings得到src
将1,256,64,64的pe复制元素得到pos_src 1,256,64,64
(transformer): TwoWayTransformer(
输入src、pos_src、token(表示点提示)
src和pos_srcf分别permute成1,4096,256
token做query
(layers): ModuleList(
(0): TwoWayAttentionBlock(
(self_attn): Attention(
对query做自注意力
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
得到三个1,5,256
再分别分8头,即1,8,5,32
计算自注意力公式后再合头得到1,5,256
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
这样更新后的query经过norm1后再加上一开始的query得到q
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
k = src + pos_src
(cross_attn_token_to_image): Attention(
输入q,k,以及src作为v
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
k和v是分头得到1,8,4096,16
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
前面更新后的query加上交叉注意力的结果得到新的query,送入norm2
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=256, out_features=2048, bias=True)
(lin2): Linear(in_features=2048, out_features=256, bias=True)
(act): ReLU()
)
前面最新的query加上mlp的结果得到query送入norm3
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
此时更新后的query再加上一开始的query得到q
k = src + pos_src
(cross_attn_image_to_token): Attention(
输入k作为q,q作为k,最新更新后的query作为v
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
src加上交叉注意力的结果得到新的src再送入norm4
(norm4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
输入最新的query 1,5,256,和key=最新的src 1,4096,256
)
(1): TwoWayAttentionBlock(
(self_attn): Attention(
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn_token_to_image): Attention(
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=256, out_features=2048, bias=True)
(lin2): Linear(in_features=2048, out_features=256, bias=True)
(act): ReLU()
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn_image_to_token): Attention(
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
)
)
q=最终得到的query + token
k=最终得到的keys + pos_src
(final_attn_token_to_image): Attention(
输入q,k,keys做v
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
query+=交叉注意力的结果,再输入给下面的LN
(norm_final_attn): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
输出hs=query,src=key
)
iou_token_out = hs[:, 0, :]
1,256
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
1,4,256
src view成1,256,64,64后给下面
(output_upscaling): Sequential(
(0): ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU()
(3): ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2))
(4): GELU()
)得到1,32,256,256 upscaled_embedding
(output_hypernetworks_mlps): ModuleList(
把mask_tokens_out拆成4个1,1,256输入给下面的每一层
(0): MLP(
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=32, bias=True)
)
)
(1): MLP(
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=32, bias=True)
)
)
(2): MLP(
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=32, bias=True)
)
)
(3): MLP(
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=32, bias=True)
)
)
从而有四个1,1,32组成的list堆叠得到1,4,32的hyper_in
hyper_in和upscaled_embedding@乘法后再view得到masks 1,4,256,256
)
(iou_prediction_head): MLP(
输入iou_token_out
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=4, bias=True)
)得到iou_pred 1,4
返回得到masks和iou_pred
mask_slice = slice(1, None)
得到一个slice(1,None,None)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
)
返回low_res_masks 1,3,256,256和iou_predictions 1,3
(postprocess_masks)
一次双线性插值
masks = masks[..., : input_size[0], : input_size[1]]
二次双线性插值
得到1,3,480,640
)
)
顺便记一下保存特征图
import cv2
import numpy as np
image_array = x.squeeze()[:3].permute(1, 2, 0).cpu().numpy()
# image_array = x.squeeze()[:,:,:3].cpu().numpy()
# 将值缩放到0-255范围
image_array = (image_array * 255).astype(np.uint8)
# 保存图像
cv2.imwrite('3_image_encoder(1,1280,64,64).jpg', image_array)
sam = sam_model_registry["default"](checkpoint="sam_vit_h_4b8939.pth")
2023-12-04 16:09:13.740 | INFO | __main__:<module>:11 - 读取模型 (9.14878 s)
predictor = SamPredictor(sam)
2023-12-04 16:09:13.740 | INFO | __main__:<module>:17 - 创建模型 (0.03 ms)
predictor.set_image(image)
2023-12-04 16:09:53.530 | INFO | __main__:<module>:25 - 预处理图片 (39.78268 s)
masks, _, _ = predictor.predict()
2023-12-04 16:09:53.614 | INFO | __main__:<module>:31 - 分割 (83.36 ms)
cnm=masks.transpose(1,2,0)
cv2.imwrite(f"aaa.png",cnm.astype(np.uint8)*255)
2023-12-04 16:09:53.626 | INFO | __main__:<module>:41 - 保存剪影 (11.11 ms)
主要是预处理那里很慢

原图1,3,480,640

刚transform 1,3,768,1024

网络的输入 1,3,1024,1024

网络中的参数pos_embed(1,64,64,1280)

pos_embed(1,1280,64,64)

neck(1,256,64,64)

upscaled_embedding(1,32,256,256)(可视化的后三通道)
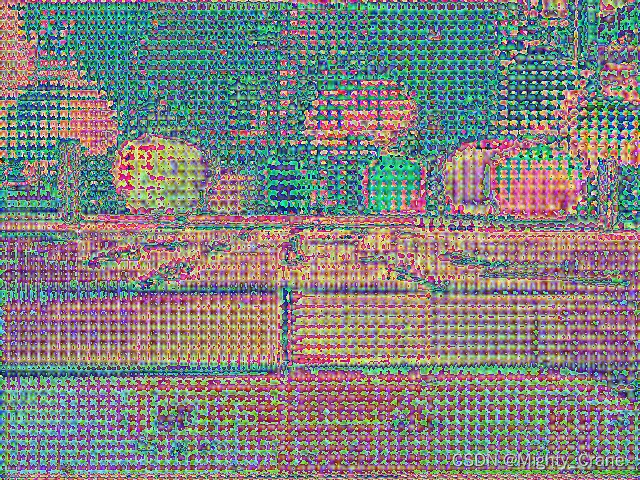
阈值过滤之前的masks(1,3,480,640)

过滤后的masks[1],应该是关注前景([0]全黑)

过滤后的masks[0]