# 精辟总结
其实各种八股文资料,他也就是围绕着核心知识展开提问的,你只要根据八股文把核心知识提炼出来,形成核心知识体系!
Java集合那是重点中的重点。最基本的概念要懂,核心的概念,那要滚瓜烂熟。
Java集合俩大接口:Collection(子接口List、Set、Queue)、Map
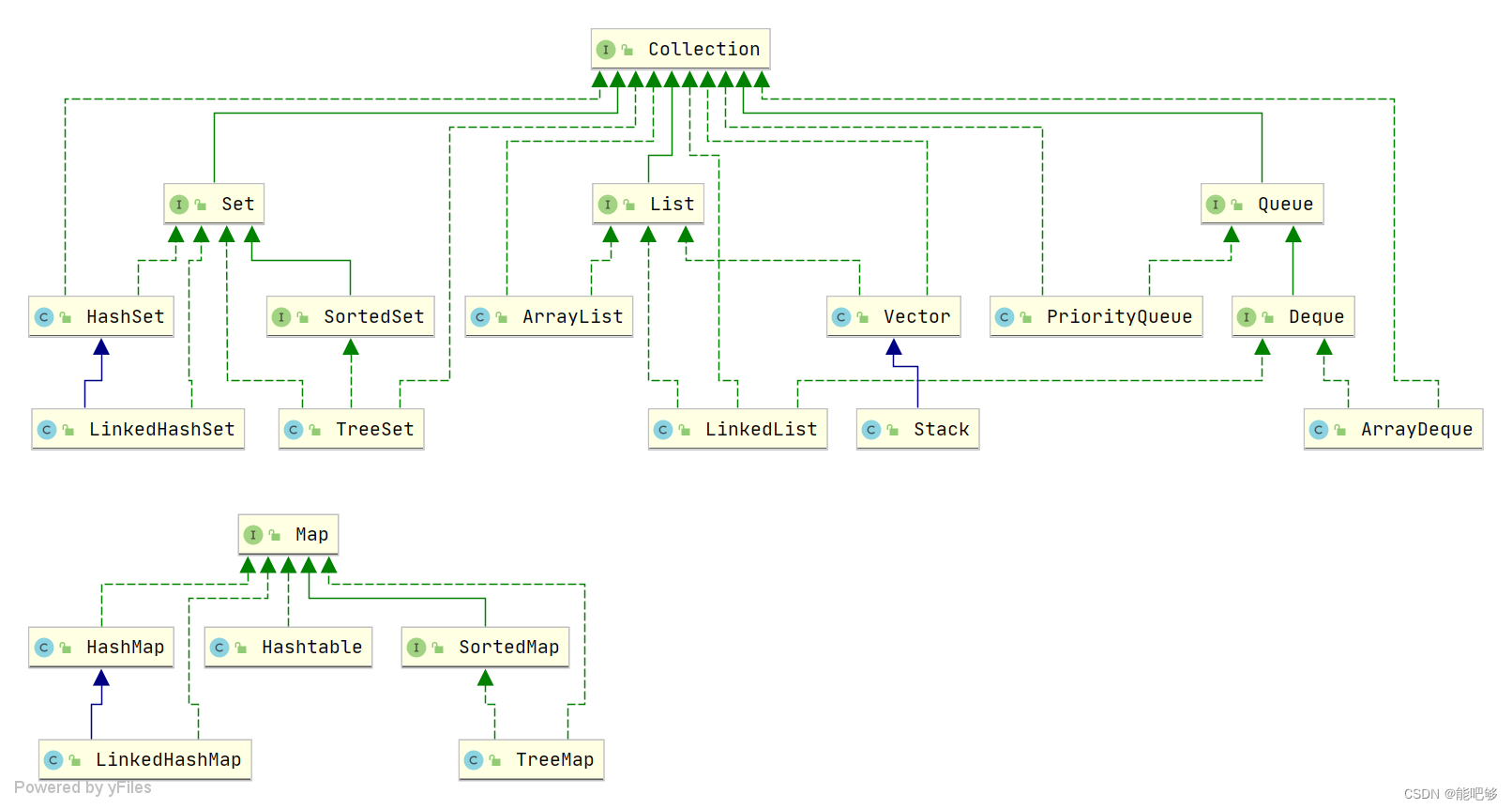
掌握四个接口以及每个接口的重要实现类,再加上一些细节点。
有些压根就是看一下,但是重点就是那几个!!写下来,不断回看。
# 总述对比
0、为啥要使用集合?
- 使用数组存储对象不灵活。使用集合存储数据大小可变、支持泛型、存在内建算法等,方便。
1、List、Set、Queue、Map区别?
- List存储元素有序可重复;
- Set存储元素不可重复;
- Queue存储元素有序可重复;
- Map存储元素key有序不可重复,Value有序可重复,一个键可映射对应多个值。
2、集合底层数据结构说说
- List:ArrayList,Vector底层数据结构是Object[]数组;LinkedList是双向链表
- Set:HashSet基于HashMap实现,底层是HashMap存数据;LinkedHashSet基于LinkedHashMap实现;TreeSet底层红黑树
- Queue:PriorityQueue是Object[]数组实现小顶堆;ArrayDeque为可扩容动态数组
- Map:HashMap为数组+链表/红黑树;LinkedHashMap继承HashMap,在此基础上增加了一条双向链表。
3、怎么选择合适的集合?
- 进行键值对存储,选用Map接口下集合
需要排序选择TreeMap,不需要就选HashMap,要求保证线程安全选ConcurrentHashMap
- 只存储元素值,选用Collection接口下集合
要求元素唯一(不可重复)选择Set接口下集合,TreeSet、HashSet,不要求就选ArrayList、LinkedList等
# List
List = ArrayList + LinkedList
## ArrayList简述
- ArrayList基于动态数组实现,根据实际存储的元素动态的扩容缩容;
- 允许使用泛型确保类型安全;
- 存储任意类型对象(包括null值),基本数据类型要使用对应的包装类(eg.Integer、Double);
- 支持插入删除遍历等操作(eg. add()、remove());
- 创建不需要指定大小
## ArrayList扩容机制
新容量 = 旧容量 * 1.5
触发扩容 -> 新开1.5倍容量 -> 复制 -> 清空原空间 -> 扩容中检查是否超出最大容量限制
## ArrayList插入删除时间复杂度
分析时间复杂度,注意要分类讨论!
插入:
头插元素后移O(n);尾插不扩容O(1),扩容O(n);指定位插O(n)
删除:
头删前移O(n);尾删O(1);指定删O(n)
## LinkedList为啥不能实现RandomAccess接口?
randomaccess接口是标记接口,表明实现该接口的类支持随机访问(通过索引快速访问元素),
LinkedList底层数据接口是双向链表,内存地址不连续只能通过指针索引,不能随机访问,所以不能实现randomaccess接口。
## ArrayList与LinkedList区别
- 线程安全:ArrayList与LinkedList都是非同步的,即不保证线程安全;
- 底层数据结构:ArrayList底层是Object[]数组,LinkedList底层是双向链表;
- 快速访问:ArrayList支持,而LinkedList不支持;
- 内存占用:ArrayList内存浪费在List列表尾部预留一定的容量;LinkedList空间花费主要在每一个元素都要存放前驱后继;
- 插入删除:ArrayList数组存储,插入删除时间复杂度受位置影响;LinkedList链表存储,头部插入删除不受位置影响,指定位置插入删除需要定位后再操作。
# Set
## HashSet如何检查重复
HashSet底层数据结构是哈希表(基于HashMap实现)查重时:
- 比较哈希码:先计算该元素的哈希码,并查找哈希表中是否存在相同的哈希码;
- equals方法比较:若存在相同哈希码,调用equals方法,返回true代表已存在不添加,否则就添加
HashSet添加元素条件:哈希码不同;哈希码相同但equals方法返回false
## Comparable与Comparator区别
实现Comparable接口要重写CompareTo(Object obj)方法,由自定义类内部实现排序方法;
实现Comaprator接口要重写Compare(Object obj1 , Object obj2)方法,由外部定义实现排序
重写Comparable接口的CompareTo方法:
public class Person implements Comparable<Person> {
......
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
重写Compare:
Collections.sort(arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});# Map
Map = HashMap + TreeMap + ConcurrentHashMap
## hash表基础
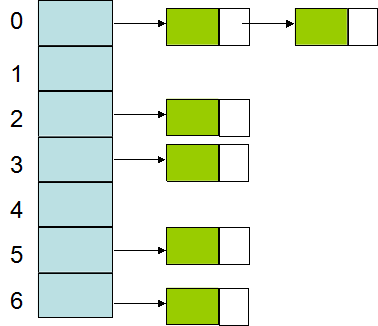
计算数组下标:
- 计算Key的哈希码 hashcode = hsahCode(Key)
- 计算数组下标 index = hashcode & (Entry.length - 1) || 取余 index = hashcode % (length-1)
左侧一维数组,数组元素内容是指向另一个链式数组的指针。绿色部分是<Key,Value>,绿色部分右侧的白色部分是指向下一对键值对的指针。
hash表的工作原理:
- 先根据给定的key和散列算法hash()得到具体的散列值hashcode,也就是对应的数组下标。
- 根据数组下标得到此下标里存储的指针,若指针为空,则不存在这样的键值对,否则根据此指针得到此链式数组。(此链式数组里存放的均为一对对<Key,Value>)。
- 遍历此链式数组,分别取出Key与给定的Key比较,若找到与给定key相等的Key,即在此hash表中存在此要查找的<Key,Value>键值对,此后便可以对此键值对进行相关操作;若找不到,即为不存在此 键值对。
## HashMap底层实现
HashMap基于哈希表的Map接口实现,存储键值对,支持快速插入删除查找;底层数据结构为数组 + 链表/红黑树
具体实现:
put()插入值:jdk1.8之前,底层为数组+链表。HashMap通过hashcode经过扰动函数处理得到hash值,再通过(Entry.length - 1)&hash得到元素存放位置,如果该位置存在元素,就判断该元素与要存入的元素的Key和哈希码hashcode是否相同,相同则直接覆盖,不相同,则通过拉链法解决哈希冲突;
jdk1.8之后,变化就是优化了解决哈希冲突,当链表长度大于阈值(8)这时会判断若当前数组长度小于64先进行数组扩容,不然就将链表转换成红黑树以减少搜索时间。
链表法:将链表和数组结合。创建一个链表数组,数组中每一格就是一个链表,若遇到哈希冲突,就将冲突的值加到链表中即可。
get()取出值也是类似的过程。
## ConcurrentHashMap底层原理
1、整体架构:与HashMap相同 数组 + 链表/红黑树
2、基本功能:在HashMap基础上增加了并发安全,并发安全的实现是通过对Node节点加锁来保证数据更新的安全性
性能优化:为了平衡并发性能与数据安全性,jdk1.8之前锁的粒度是segment,jdk1.8之后锁的粒度为Node节点,缩小锁的范围提高并发性能,引入多线程并发扩容
(多线程并发扩容:多个线程对原数组进行分片,分片后每个线程负责一个分片的数据迁移,从而提升扩容效率)