Flink 系列文章
1、Flink 专栏等系列综合文章链接
文章目录
- Flink 系列文章
- 一、Flink的23种算子说明及示例
- 6、KeyBy
- 7、Reduce
- 8、Aggregations
本文主要介绍Flink 的3种常用的operator(keyby、reduce和Aggregations)及以具体可运行示例进行说明.
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
一、Flink的23种算子说明及示例
本文示例中使用的maven依赖和java bean 参考本专题的第一篇中的maven和java bean。
6、KeyBy
DataStream → KeyedStream
按照指定的key来对流中的数据进行分组
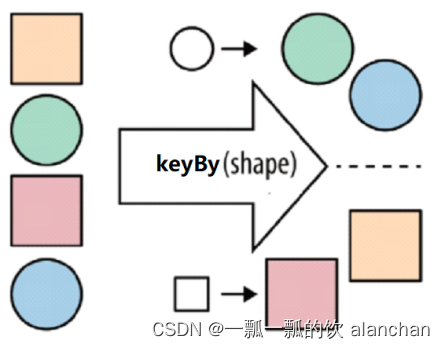
KeyBy 在逻辑上是基于 key 对流进行分区。在内部,它使用 hash 函数对流进行分区。它返回 KeyedDataStream 数据流。将同一Key的数据放到同一个分区。
分区结果和KeyBy下游算子的并行度强相关。如下游算子只有一个并行度,不管怎么分,都会分到一起。
对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区。
对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {…})指定字段进行分区。
import java.util.Arrays;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestKeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(4);// 设置数据分区数量
keyByFunction6(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
// 按照name进行keyby 对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区
public static void keyByFunction1(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
return value.getName();
}
});
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// lambda 对于POJO类型,KeyBy可以通过keyBy(fieldName)指定字段进行分区
public static void keyByFunction2(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(user -> user.getName());
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// 对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。lambda
public static void keyByFunction3(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
SingleOutputStreamOperator<Tuple2<String, User>> userTemp = source.map((MapFunction<User, Tuple2<String, User>>) user -> {
return new Tuple2<String, User>(user.getName(), user);
}).returns(Types.TUPLE(Types.STRING, Types.POJO(User.class)));
KeyedStream<Tuple2<String, User>, Tuple> sink = userTemp.keyBy(0);
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.f1.toString());
return user.f1;
});
sink.print();
}
// 对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
public static void keyByFunction4(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
SingleOutputStreamOperator<Tuple2<String, User>> userTemp = source.map(new MapFunction<User, Tuple2<String, User>>() {
@Override
public Tuple2<String, User> map(User value) throws Exception {
return new Tuple2<String, User>(value.getName(), value);
}
});
KeyedStream<Tuple2<String, User>, String> sink = userTemp.keyBy(new KeySelector<Tuple2<String, User>, String>() {
@Override
public String getKey(Tuple2<String, User> value) throws Exception {
return value.f0;
}
});
// 演示keyby后的数据输出
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.f1.toString());
return user.f1;
});
// sink.map(new MapFunction<Tuple2<String, User>, String>() {
//
// @Override
// public String map(Tuple2<String, User> value) throws Exception {
// System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + value.f1.toString());
// return null;
// }});
sink.print();
}
// 对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。
// 按照name的前4位进行keyby
public static void keyByFunction5(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User value) throws Exception {
// String temp = value.getName().substring(0, 4);
return value.getName().substring(0, 4);
}
});
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
// 对于一般类型,如上,KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。 lambda
// 按照name的前4位进行keyby
public static void keyByFunction6(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> sink = source.keyBy(user -> user.getName().substring(0, 4));
sink.map(user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
});
sink.print();
}
}
7、Reduce
KeyedStream → DataStream
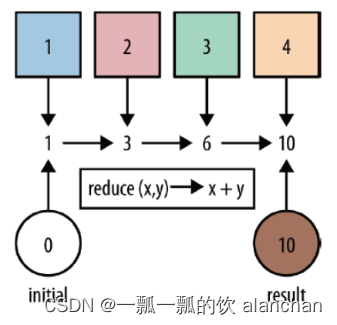
对集合中的元素进行聚合。Reduce 返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average, sum, min, max, count,使用 reduce 方法都可实现。基于ReduceFunction进行滚动聚合,并向下游算子输出每次滚动聚合后的结果。
注意: Reduce会输出每一次滚动聚合的结果。
import java.util.Arrays;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(4);// 设置数据分区数量
reduceFunction2(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
// 按照name进行balance进行sum
public static void reduceFunction1(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> keyedStream = source.keyBy(user -> user.getName());
SingleOutputStreamOperator<User> sink = keyedStream.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User value1, User value2) throws Exception {
double balance = value1.getBalance() + value2.getBalance();
return new User(value1.getId(), value1.getName(), "", "", 0, balance);
}
});
//
sink.print();
}
// 按照name进行balance进行sum lambda
public static void reduceFunction2(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> userKeyBy = source.keyBy(user -> user.getName());
SingleOutputStreamOperator<User> sink = userKeyBy.reduce((user1, user2) -> {
User user = user1;
user.setBalance(user1.getBalance() + user2.getBalance());
return user;
});
sink.print();
}
}
8、Aggregations
KeyedStream → DataStream
DataStream API 支持各种聚合,例如 min,max,sum 等。 这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
Aggregate 对KeyedStream按指定字段滚动聚合并输出每一次滚动聚合后的结果。默认的聚合函数有:sum、min、minBy、max、maxBy。
注意:
max(field)与maxBy(field)的区别: maxBy返回field最大的那条数据;而max则是将最大的field的值赋值给第一条数据并返回第一条数据。同理,min与minBy。
Aggregate聚合算子会滚动输出每一次聚合后的结果
max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。
max以第一个比较对象的比较列值进行替换,maxBy是以整个比较对象进行替换。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestAggregationsDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
aggregationsFunction2(env);
env.execute();
}
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(Arrays.asList(
new User(1, "alan1", "1", "1@1.com", 12, 1000),
new User(2, "alan2", "2", "2@2.com", 19, 200),
new User(3, "alan1", "3", "3@3.com", 28, 1500),
new User(5, "alan1", "5", "5@5.com", 15, 500),
new User(4, "alan2", "4", "4@4.com", 30, 400)));
return source;
}
//分组统计sum、max、min、maxby、minby
public static void aggregationsFunction(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
KeyedStream<User, String> userTemp= source.keyBy(user->user.getName());
DataStream sink = null;
//1、根据name进行分区统计balance之和 alan1----2500/alan2----600
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=2500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=600.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=3000.0)
sink = userTemp.sum("balance");
//2、根据name进行分区统计balance的max alan1----1500/alan2----400
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=400.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1500.0)
sink = userTemp.max("balance");//1@1.com-3000 -- 2@2.com-300
//3、根据name进行分区统计balance的min alan1----500/alan2---200
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=500.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
sink = userTemp.min("balance");
//4、根据name进行分区统计balance的maxBy alan2----400/alan1----1500
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 1> User(id=4, name=alan2, pwd=4, email=4@4.com, age=30, balance=400.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=3, name=alan1, pwd=3, email=3@3.com, age=28, balance=1500.0)
// 16> User(id=3, name=alan1, pwd=3, email=3@3.com, age=28, balance=1500.0)
sink = userTemp.maxBy("balance");
//5、根据name进行分区统计balance的minBy alan2----200/alan1----500
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 1> User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=1, name=alan1, pwd=1, email=1@1.com, age=12, balance=1000.0)
// 16> User(id=5, name=alan1, pwd=5, email=5@5.com, age=15, balance=500.0)
sink = userTemp.minBy("balance");
sink.print();
}
public static void aggregationsFunction2(StreamExecutionEnvironment env) throws Exception {
List list = new ArrayList<Tuple3<Integer, Integer, Integer>>();
list.add(new Tuple3<>(0,3,6));
list.add(new Tuple3<>(0,2,5));
list.add(new Tuple3<>(0,1,6));
list.add(new Tuple3<>(0,4,3));
list.add(new Tuple3<>(1,1,9));
list.add(new Tuple3<>(1,2,8));
list.add(new Tuple3<>(1,3,10));
list.add(new Tuple3<>(1,2,9));
list.add(new Tuple3<>(1,5,7));
DataStreamSource<Tuple3<Integer, Integer, Integer>> source = env.fromCollection(list);
KeyedStream<Tuple3<Integer, Integer, Integer>, Integer> tTemp= source.keyBy(t->t.f0);
DataStream<Tuple3<Integer, Integer, Integer>> sink =null;
//按照分区,以第一个Tuple3的元素为基础进行第三列值比较,如果第三列值小于第一个tuple3的第三列值,则进行第三列值替换,其他的不变
// 12> (0,3,6)
// 11> (1,1,9)
// 11> (1,1,8)
// 12> (0,3,5)
// 11> (1,1,8)
// 12> (0,3,5)
// 11> (1,1,8)
// 12> (0,3,3)
// 11> (1,1,7)
sink = tTemp.min(2);
// 按照数据分区,以第一个tuple3的元素为基础进行第三列值比较,如果第三列值小于第一个tuple3的第三列值,则进行整个tuple3的替换
// 12> (0,3,6)
// 11> (1,1,9)
// 12> (0,2,5)
// 11> (1,2,8)
// 12> (0,2,5)
// 11> (1,2,8)
// 12> (0,4,3)
// 11> (1,2,8)
// 11> (1,5,7)
sink = tTemp.minBy(2);
sink.print();
}
}
以上,本文主要介绍Flink 的3种常用的operator(keyby、reduce和Aggregations)及以具体可运行示例进行说明.
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)