06、基于内容的过滤算法Tensorflow实现
开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。全部工程可从最上方链接下载。
05、基于梯度下降的协同过滤算法中已经介绍了协同过滤算法的基本实现方法,但是这种方法仅根据用户的相似度进行推荐,而不关注用户或者电影本身的一些特征的匹配,基于内容的过滤算法正式为了对此进行改进。
此处还是以电影推荐作为实际的案例。
1、基于内容的过滤算法实现原理
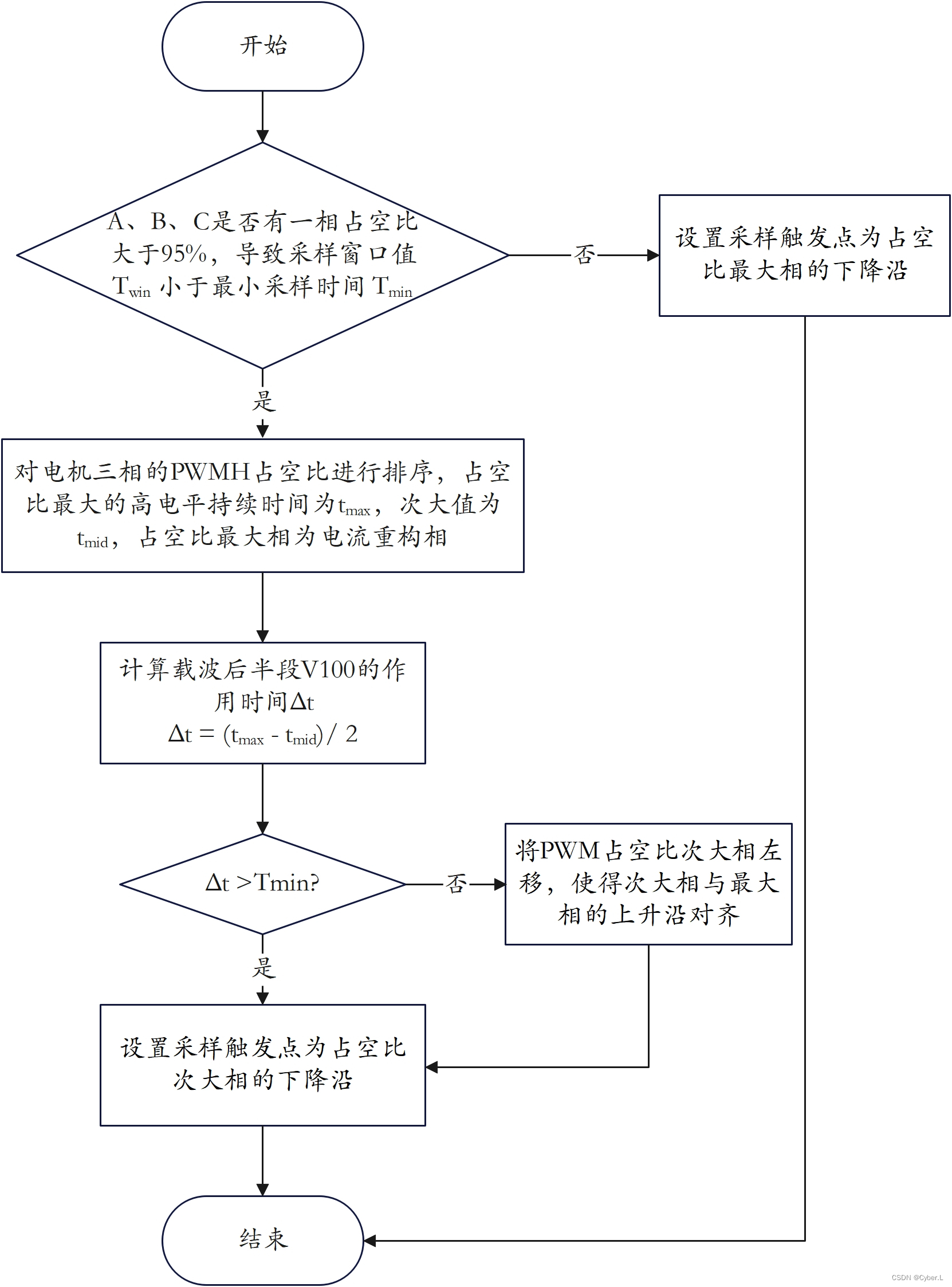
基于内容的过滤算法的神经网络实现依赖于现有的特征数据,这个特征数据包括用户的特征数据和电影本身的特征数据。常理来讲,最终的打分结果是用户自身的特征和电影本身的属性共同决定的,但是其互相影响的机制可能并不明确,因此可以使用如下的神经网络模型直接训练得到结果:
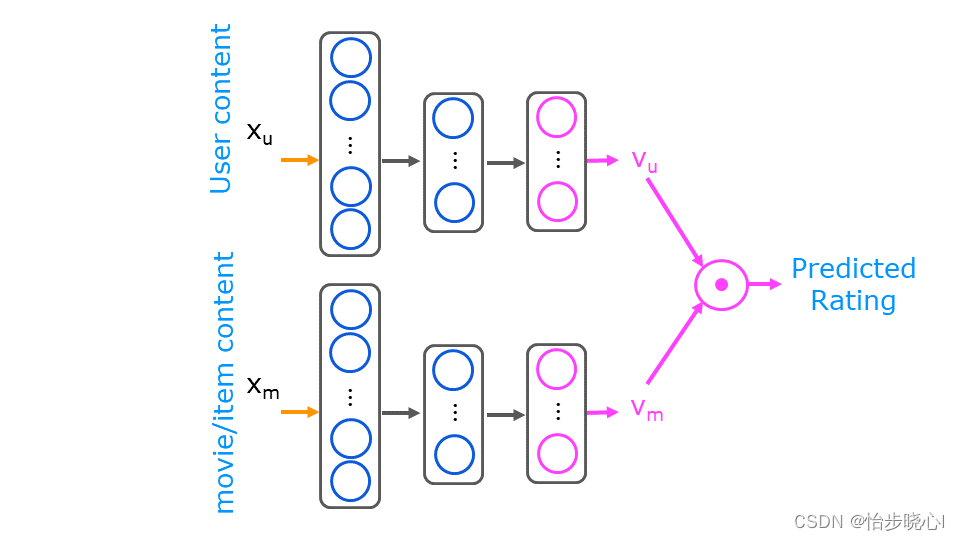
对于上图,在吴恩达的解释中,Vu和Vm分别是用户和电影的特征向量,这个特征是从原有的基础数据(如电影类型、用户爱好、用户年龄等等)中训练出来的,其并没有具体对应的特征含义。
因此,其所介绍的基于内容的过滤算法完全基于神经网络的模型得到预测的打分结果,进而进行推荐,下面对原理步骤进行解释。
2、数据集的简单解释
全部的工程文件可以在最上方的链接进行下载。这个数据集的来源是:dataset,吴恩达老师的数据在此基础上进行了二元化的处理,所以看着非常难以理解。
首先是content_user_train.csv这个文件,,其抬头在content_user_train_header.txt中将其组合即可得到用户的数据,如下所示:

但是值得注意的是,数据和很多的重复的,例如对于用户3,其第40-43行都是一样的数据,可以看到用户3给一个电影打过分:

而这代表用户3看过的电影在content_item_train.csv这个文件的第40-43行,可以看到只有72378这个代号的电影,这个电影占用四行,代表它在四个分类(比如爱情、浪漫、动作等等),电影的平均分是2.6。

content_item_train.csv这个文件的抬头在content_item_train_header.txt中,将其组合即可得到电影的数据,例如:

为充分解释,再举一个用户2的例子,其重复占用从第1行到第39行:
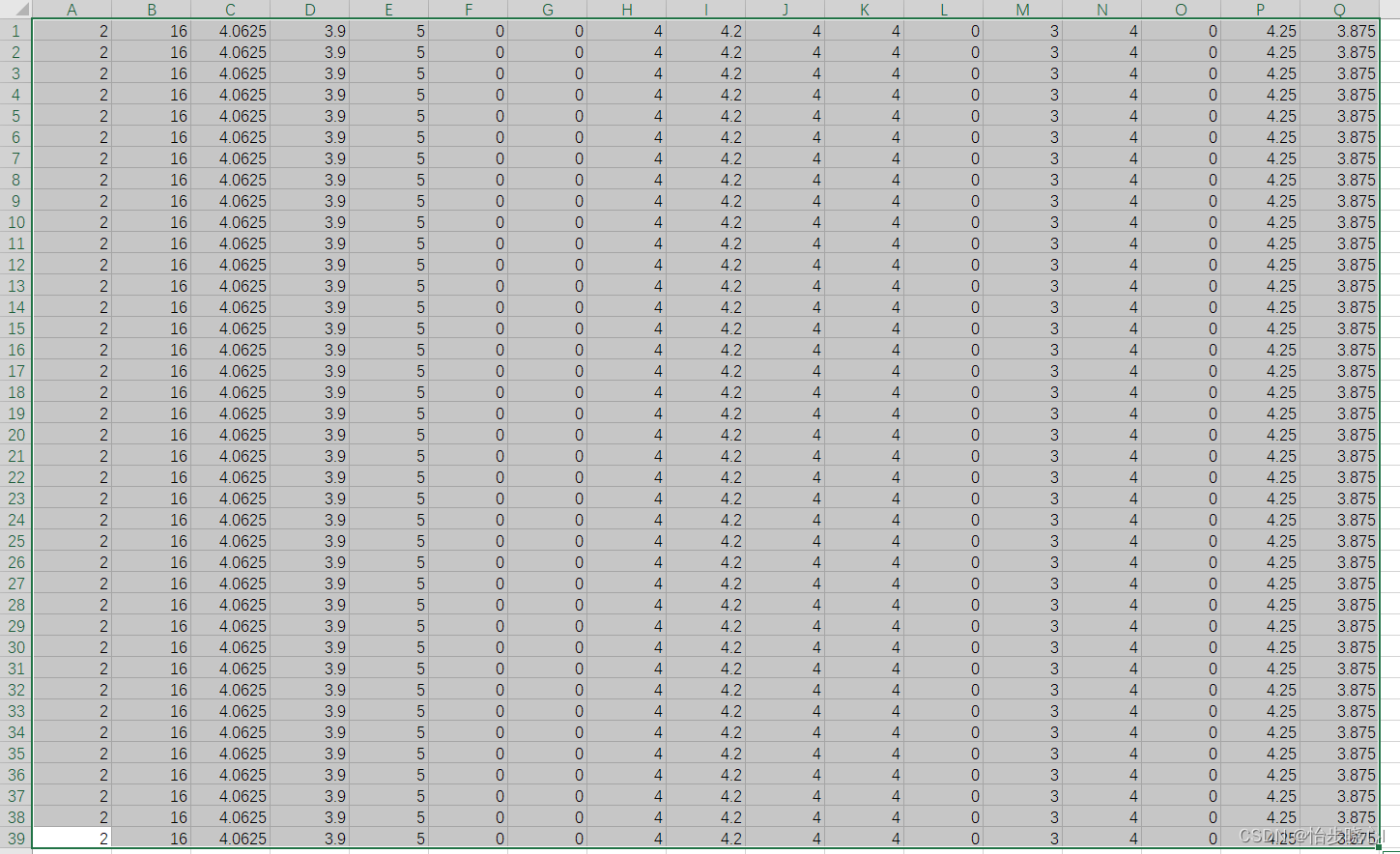
而在content_item_train.csv这个文件中的第1行到第39行,表示其看过6874、8798、46970等16个电影,每个电影属于多少个分类,每个电影就会占用多少行(6874占用3个分类就有三行):
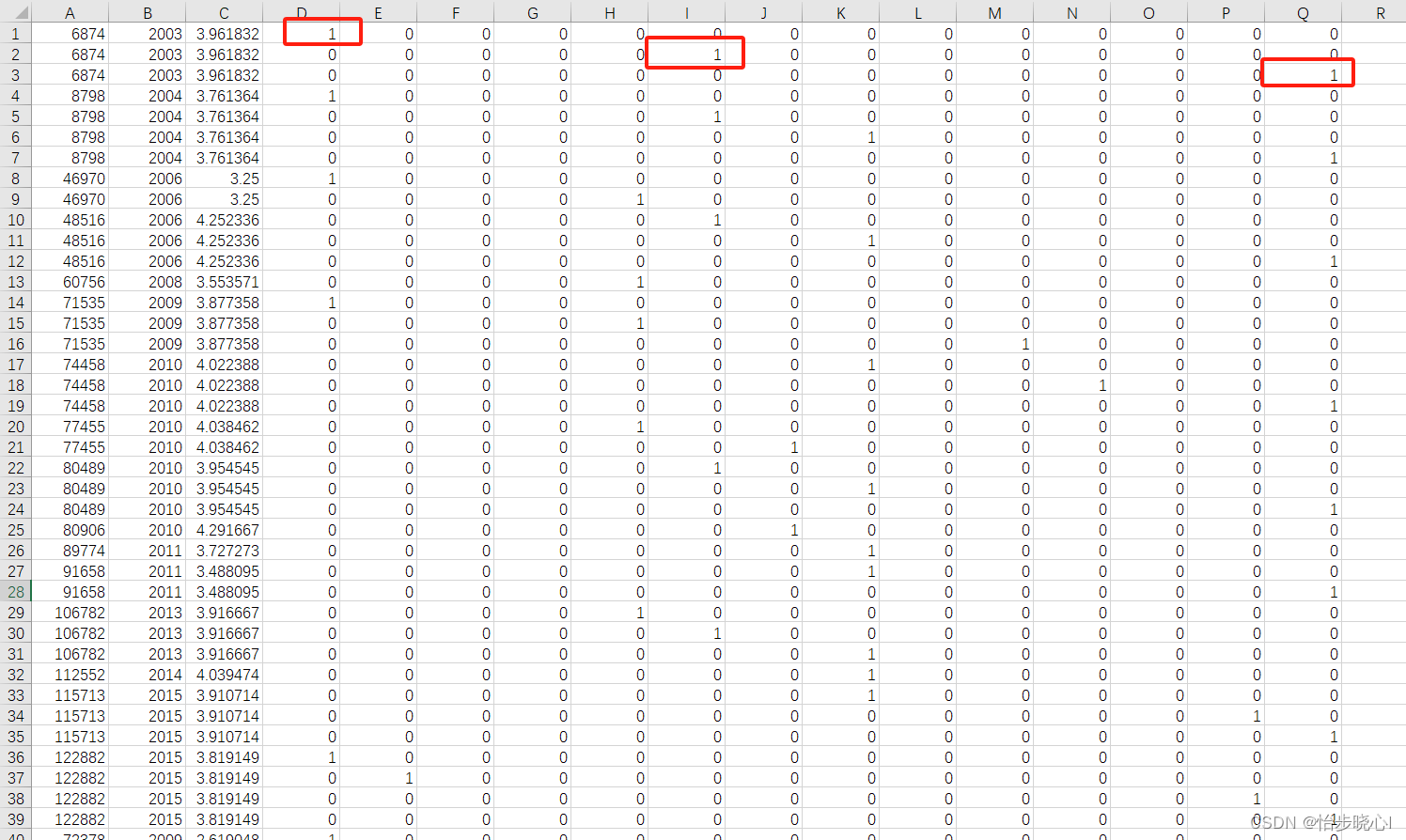
content_item_train.csv中的电影会有重复,毕竟可能不同用户都给同一电影打分,因此6874除了第一行有第474行也有,这么设计只是为了查找时方便对应,但是训练速度估计比较着急。

content_item_vecs.csv这里面存储的也是电影的相关原始特征,但是其不会出现上面的重复,因为其不需要和用户对应且电影id递增排列。
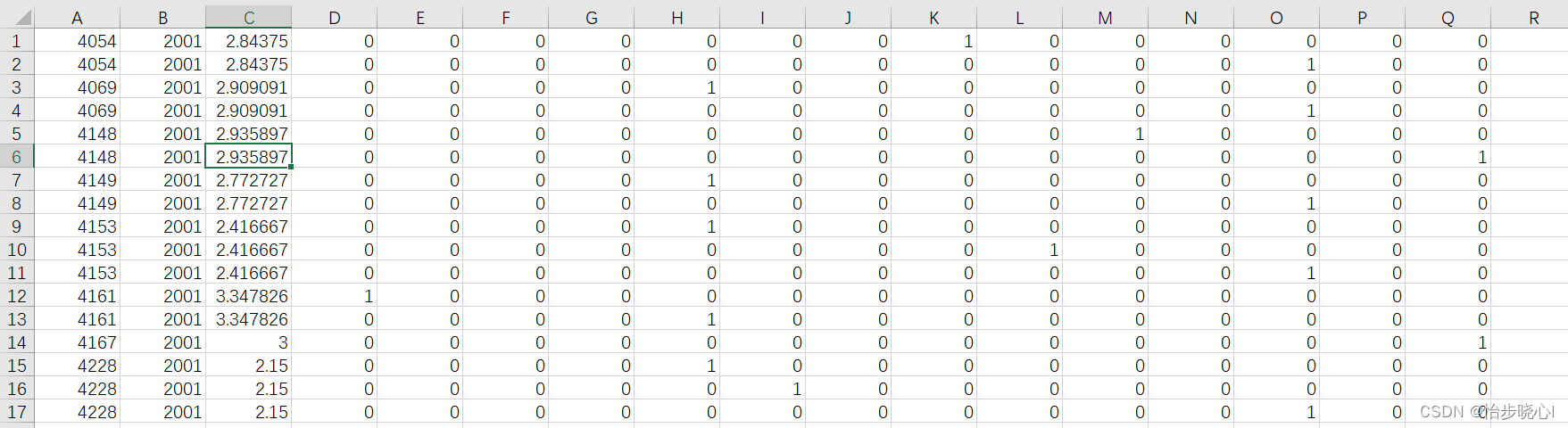
content_movie_list.csv这里面是id所对应的实际电影:
3、基于内容的过滤算法实现步骤
STEP1: 引入包并加载数据集(不考虑用户ID、评分次数和平均评分、电影ID,所以需要移除部分数据):
from keras import Model
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from Content_Based_Filtering_recsysNN_utils import *
pd.set_option("display.precision", 1)
# 加载数据,设置配置变量
item_train, user_train, y_train, item_features, user_features, item_vecs, movie_dict, user_to_genre = load_data()
# 计算用户特征的数量,训练时移除用户ID、评分次数和平均评分
num_user_features = user_train.shape[1] - 3
# 计算物品特征的数量,训练时移除电影ID
num_item_features = item_train.shape[1] - 1
# 用户向量的起始位置
uvs = 3
# 物品向量的起始位置
ivs = 3
# 在训练中使用的用户列的起始位置
u_s = 3
# 在训练中使用的物品列的起始位置
i_s = 1
STEP2: 数据标准化与测试集的分割:
# 如果为True,则对数据应用标准化
scaledata = True
# 归一化训练数据
if scaledata:
# 保存原始的item_train和user_train数据
item_train_save = item_train
user_train_save = user_train
# 对item_train数据进行标准化处理
scalerItem = StandardScaler()
scalerItem.fit(item_train)
item_train = scalerItem.transform(item_train)
# 对user_train数据进行标准化处理
scalerUser = StandardScaler()
scalerUser.fit(user_train)
user_train = scalerUser.transform(user_train)
# 对y_train数据进行归一化处理,使其值在-1到1之间
scaler = MinMaxScaler((-1, 1))
scaler.fit(y_train.reshape(-1, 1))
y_train = scaler.transform(y_train.reshape(-1, 1))
# 使用train_test_split函数将数据集分割为训练集和测试集,其中训练集占比为80%
item_train, item_test = train_test_split(item_train, train_size=0.80, shuffle=True, random_state=1)
user_train, user_test = train_test_split(user_train, train_size=0.80, shuffle=True, random_state=1)
y_train, y_test = train_test_split(y_train, train_size=0.80, shuffle=True, random_state=1)
# 打印训练集和测试集的形状
print(f"movie/item training data shape: {item_train.shape}")
print(f"movie/item test data shape: {item_test.shape}")
STEP3: 模型构建与训练(其中特征数量num_outputs 指的是训练最终得到的特征数量,即Vu和Vm的维度,理论上可以随意选取):
# 构建模型
# 输出的电影特征和用户特征数量,都是32
num_outputs = 32
tf.random.set_seed(1) # 设置随机种子以确保结果的可复现性
# 定义用户神经网络
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu'), # 第一层有256个神经元,使用ReLU激活函数
tf.keras.layers.Dense(128, activation='relu'), # 第二层有128个神经元,使用ReLU激活函数
tf.keras.layers.Dense(num_outputs), # 输出层有32个神经元
])
# 定义物品神经网络
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu'), # 第一层有256个神经元,使用ReLU激活函数
tf.keras.layers.Dense(128, activation='relu'), # 第二层有128个神经元,使用ReLU激活函数
tf.keras.layers.Dense(num_outputs), # 输出层有32个神经元
])
# 创建用户输入并连接到基础网络
input_user = tf.keras.layers.Input(shape=(num_user_features)) # 定义用户输入层
vu = user_NN(input_user) # 将用户输入传入用户神经网络
vu = tf.linalg.l2_normalize(vu, axis=1) # 对用户向量进行L2正则化
# 创建物品输入并连接到基础网络
input_item = tf.keras.layers.Input(shape=(num_item_features)) # 定义物品输入层
vm = item_NN(input_item) # 将物品输入传入物品神经网络
vm = tf.linalg.l2_normalize(vm, axis=1) # 对物品向量进行L2正则化
# 计算两个向量vu和vm的点积
output = tf.keras.layers.Dot(axes=1)([vu, vm]) # 计算点积作为输出
# 指定模型的输入和输出
model = Model([input_user, input_item], output) # 定义模型
model.summary() # 打印模型概要
# 设置模型的优化器和损失函数
tf.random.set_seed(1)
cost_fn = tf.keras.losses.MeanSquaredError() # 使用均方误差作为损失函数
opt = keras.optimizers.Adam(learning_rate=0.01) # 使用Adam优化器,学习率为0.01
model.compile(optimizer=opt, loss=cost_fn) # 编译模型
# 训练模型
tf.random.set_seed(1)
model.fit([user_train[:, u_s:], item_train[:, i_s:]], y_train, epochs=20) # 对模型进行20轮训练
# 评估模型在测试集上的表现
model.evaluate([user_test[:, u_s:], item_test[:, i_s:]], y_test) # 计算模型在测试集上的损失值
STEP4: 基于模型的新用户最佳推荐
首先要构建新用户的特征:
# 给新用户推荐
new_user_id = 5000
new_rating_ave = 1.0
new_action = 5
new_adventure = 1
new_animation = 1
new_childrens = 5
new_comedy = 1
new_crime = 5
new_documentary = 1
new_drama = 1
new_fantasy = 1
new_horror = 1
new_mystery = 1
new_romance = 1
new_scifi = 5
new_thriller = 1
new_rating_count = 1
user_vec = np.array([[new_user_id, new_rating_count, new_rating_ave,
new_action, new_adventure, new_animation, new_childrens,
new_comedy, new_crime, new_documentary,
new_drama, new_fantasy, new_horror, new_mystery,
new_romance, new_scifi, new_thriller]])
下面是基于新用户特征、所有的电影特征和现有模型进行预测:
# generate and replicate the user vector to match the number movies in the data set.
user_vecs = gen_user_vecs(user_vec,len(item_vecs))
# 进行预测并按照推荐程度进行排序
sorted_index, sorted_ypu, sorted_items, sorted_user = predict_uservec(user_vecs, item_vecs, model, u_s, i_s,
scaler, scalerUser, scalerItem, scaledata=scaledata)
# 打印结果
print_pred_movies(sorted_ypu, sorted_user, sorted_items, movie_dict, maxcount = 10)
其中预测函数中需要先进行归一化,如何进行预测:
def predict_uservec(user_vecs, item_vecs, model, u_s, i_s, scaler, ScalerUser, ScalerItem, scaledata=False):
"""
给定一个用户向量,对item_vecs中的所有电影进行预测,返回一个按预测评分排序的数组预测值,
以及按预测评分排序索引排序的用户和物品数组。
"""
# 判断是否需要缩放数据
if scaledata:
# 如果需要缩放,则使用ScalerUser和ScalerItem对user_vecs和item_vecs进行缩放
scaled_user_vecs = ScalerUser.transform(user_vecs)
scaled_item_vecs = ScalerItem.transform(item_vecs)
# 使用缩放后的数据进行预测
y_p = model.predict([scaled_user_vecs[:, u_s:], scaled_item_vecs[:, i_s:]])
else:
# 如果不需要缩放,则直接使用原始数据进行预测
y_p = model.predict([user_vecs[:, u_s:], item_vecs[:, i_s:]])
# 使用scaler对预测结果进行逆变换
y_pu = scaler.inverse_transform(y_p)
# 检查预测结果中是否有负数,如果有则打印错误信息
if np.any(y_pu < 0):
print("Error, expected all positive predictions")
# 对预测结果进行排序,获取排序索引,并按照排序索引对预测结果、物品和用户进行排序
sorted_index = np.argsort(-y_pu, axis=0).reshape(-1).tolist() # 取反以获得最高评分在前
sorted_ypu = y_pu[sorted_index]
sorted_items = item_vecs[sorted_index]
sorted_user = user_vecs[sorted_index]
# 返回排序索引、排序后的预测结果、排序后的物品和用户
return (sorted_index, sorted_ypu, sorted_items, sorted_user)
4、结果分析
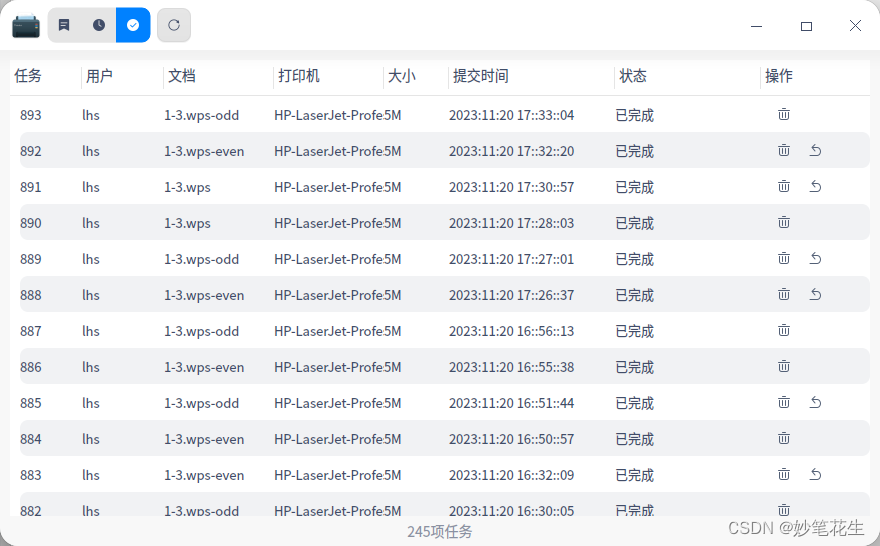
按照我给出的新用户的特性:action、childrens、crime、scifi是其比较喜欢的,推荐的排名前十的电影如下:
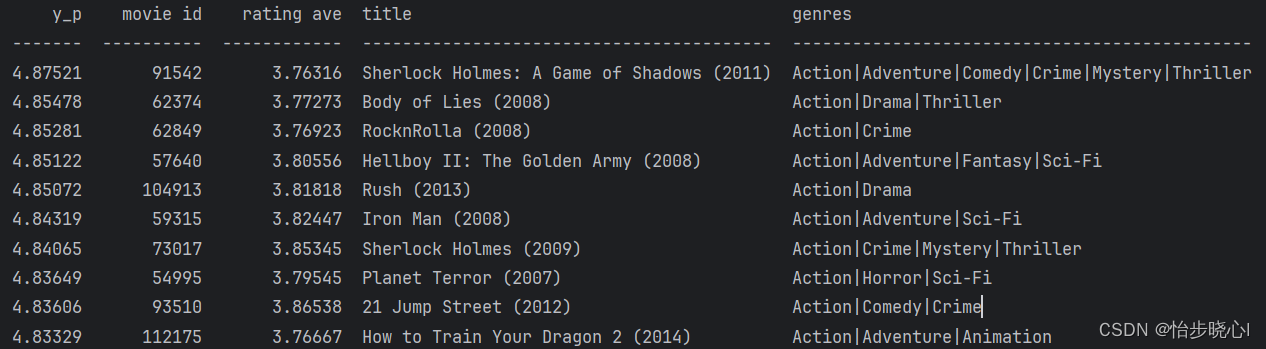
可以看到其推荐的东西也比较符合这些特征。