更好的观看体验,请点击——函数调用 | YinKai's Blog
本文将从函数的调用惯例和参数传递方法两个方面分别介绍函数执行的过程。
1、调用惯例
对于不同的编程语言, 它们在调用函数的时候往往都使用相同的语法:
somefunction(arg0, arg1)虽然它们调用函数的语法相似,但它们的调用习惯可能大不相同。调用管理是调用方和被调用方对于参数和返回值传递的约定,下面会对 Go 语言和 C 语言的调用惯例进行讲解。
C 语言
假设有以下 C 语言代码,包含一个主函数 main 和一个自定义函数 my_function:
int my_function(int arg1, int arg2) {
return arg1 + arg2;
}
int main() {
int i = my_function(1, 2);
}编译成汇编代码如下:
main:
pushq %rbp ; 保存主函数的栈帧
movq %rsp, %rbp ; 设置主函数的栈帧
subq $16, %rsp ; 为局部变量分配 16 字节的栈空间
movl $2, %esi ; 设置第二个参数 (esi = 2)
movl $1, %edi ; 设置第一个参数 (edi = 1)
call my_function ; 调用 my_function
movl %eax, -4(%rbp) ; 将 my_function 的返回值保存在主函数的局部变量中
; 继续执行主函数的其它部分
my_function:
pushq %rbp ; 保存 my_function 的栈帧
movq %rsp, %rbp ; 设置 my_function 的栈帧
movl %edi, -4(%rbp) ; 将第一个参数从寄存器 edi 放入 my_function 的栈帧中
movl %esi, -8(%rbp) ; 将第二个参数从寄存器 esi 放入 my_function 的栈帧中
movl -8(%rbp), %eax ; 将第二个参数(esi)加载到寄存器 eax (eax = 1)
movl -4(%rbp), %edx ; 将第一个参数(edi)加载到寄存器 edx (edx = 2)
addl %edx, %eax ; 计算 eax = eax + edx (eax = 1 + 2 = 3)
popq %rbp ; 恢复 my_function 的栈帧
ret ; 返回 my_function 的调用我们按照调用前、调用时以及调用后的顺序分析上述调用过程:
-
在
my_function调用前,调用方main函数将my_function的两个参数分别存到 edi 和 esi 寄存器中; -
在
my_function调用时,它会将寄存器 edi 和 esi 中的数据存储到 eax 和 edx 两个寄存器中,随后通过汇编指令addl计算两个入参之和; -
在
my_function调用后,使用寄存器 eax 传递返回值,main函数将my_function的返回值存储到栈上的i变量中;
int my_function(int arg1, int arg2, int ... arg8) {
return arg1 + arg2 + ... + arg8;
}如上述代码所示,当 my_function 函数的入参增加至八个时,重新编译当前程序可以会得到不同的汇编代码:
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp // 为参数传递申请 16 字节的栈空间
movl $8, 8(%rsp) // 传递第 8 个参数
movl $7, (%rsp) // 传递第 7 个参数
movl $6, %r9d
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movl $2, %esi
movl $1, %edi
call my_functionmain 函数调用 my_function 时,前六个参数会使用 edi、esi、edx、ecx、r8d 和 r9d 六个寄存器传递。寄存器的使用顺序也是调用惯例的一部分,函数的第一个参数一定会使用 edi 寄存去,第二个参数使用 esi 寄存器,以此推类。
最后两个参数与前面完全不同,调用方 main函数通过栈传递这两个参数,下图展示了 main 函数在调用 my_function 前的栈信息:

上图中 rbp 寄存器会存储函数调用栈的基址指针,即属于 main 函数的栈空间的起始位置,而另一个寄存器 rsp 存储的是 main 函数调用栈结束的位置,这两个寄存器共同表示了函数的栈空间。
在调用 my_function 之前,main 函数通过 subq $16, %rsp 指令分配了 16 个字节的栈地址,随后将第六个以上的参数按照从右到左的顺序存入栈中,即第八个和第七个,余下的六个参数会通过寄存器传递,接下来运行的 call my_function 指令会调用 my_function 函数:
my_function:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp) // rbp-4 = edi = 1
movl %esi, -8(%rbp) // rbp-8 = esi = 2
...
movl -8(%rbp), %eax // eax = 2
movl -4(%rbp), %edx // edx = 1
addl %eax, %edx // edx = eax + edx = 3
...
movl 16(%rbp), %eax // eax = 7
addl %eax, %edx // edx = eax + edx = 28
movl 24(%rbp), %eax // eax = 8
addl %edx, %eax // edx = eax + edx = 36
popq %rbpmy_function 会先将寄存器中的全部数据转移到栈上,然后利用 eax 寄存器计算所有入参的和并返回结果。
总结一下的话就是:
-
六个以及六个以下的参数,会按照顺序分别使用 edi、esi、edx、ecx、r8d、r9d 这六个寄存器传递;
-
六个以上的参数会使用栈传递,函数的参数会以从右到左的顺序依次存入栈中
而函数的返回值是通过 eax 寄存器进行传递的,由于只使用一个寄存器存储返回值,所以 C 语言的函数不能同时返回多个值。
Go 语言
同样,我们以一个简单的代码片段来分析 Go 语言函数的调用惯例:
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}上述的 myFunction 函数接受两个整数并返回两个整数,main 函数在调用 myFunction 时将 66 和 77 两个参数传递到当前函数中,使用 go tool compile -S -N -l main.go 编译上述代码可以得到如下所示的汇编指令:
如果编译时不使用 -N -l 参数,编译器会对汇编代码进行优化,编译结果会有较大差别。
"".main STEXT size=68 args=0x0 locals=0x28
0x0000 00000 (main.go:7) MOVQ (TLS), CX ; 将TLS(线程本地存储)中的指针加载到寄存器CX中
0x0009 00009 (main.go:7) CMPQ SP, 16(CX) ; 比较栈指针SP和16(CX)中的值
0x000d 00013 (main.go:7) JLS 61 ; 如果SP小于等于16(CX),则跳转到偏移地址61
0x000f 00015 (main.go:7) SUBQ $40, SP ; 为局部变量分配40字节的栈空间
0x0013 00019 (main.go:7) MOVQ BP, 32(SP) ; 将基址指针BP存储到32(SP)中
0x0018 00024 (main.go:7) LEAQ 32(SP), BP ; 设置BP为32(SP)
0x001d 00029 (main.go:8) MOVQ $66, (SP) ; 将值66存储到栈上的位置(SP)
0x0025 00037 (main.go:8) MOVQ $77, 8(SP) ; 将值77存储到栈上的位置8(SP)
0x002e 00046 (main.go:8) CALL "".myFunction(SB) ; 调用函数myFunction
0x0033 00051 (main.go:9) MOVQ 32(SP), BP ; 恢复基址指针BP
0x0038 00056 (main.go:9) ADDQ $40, SP ; 恢复栈指针SP
0x003c 00060 (main.go:9) RET ; 返回根据 main 函数生成的汇编指令,我们可以分析出 main 函数调用 myFunction 之前的栈:

main 函数通过 SUBQ $40, SP 指令一共在栈上分配了 40 字节的内存空间
| 空间 | 大小 | 作用 |
|---|---|---|
| SP+32 ~ BP | 8 字节 | main 函数的栈基址指针 |
| SP+16 ~ SP+32 | 16 字节 | 函数 myFunction 的两个返回值 |
| SP ~ SP+16 | 16 字节 | 函数 myFunction 的两个参数 |
myFunction 入参的压栈顺序和 C 语言一样,也是从右到左,即第一个参数 66 在栈顶的 SP ~ SP+8,第二个参数存储在 SP+8 ~ SP+16 的空间中。
当我们准备好函数的入参之后,会调用汇编指令 CALL "".myFunction(SB),这个指令首先会将 main 的返回地址存入栈中,然后改变当前的栈指针 SP 并执行 myFunction 的汇编指令:
"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (main.go:3) MOVQ $0, "".~r2+24(SP) // 初始化第一个返回值
0x0009 00009 (main.go:3) MOVQ $0, "".~r3+32(SP) // 初始化第二个返回值
0x0012 00018 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0017 00023 (main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
0x001c 00028 (main.go:4) MOVQ AX, "".~r2+24(SP) // (24)SP = AX = 143
0x0021 00033 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0026 00038 (main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
0x002b 00043 (main.go:4) MOVQ AX, "".~r3+32(SP) // (32)SP = AX = -11
0x0030 00048 (main.go:4) RET从上述的汇编代码中我们可以看出,当前函数在执行时首先会将 main 函数中预留的两个返回值地址置成 int 类型的默认值 0,然后根据栈的相对位置获取参数并进行加减操作并将值存回栈中,在 myFunction 函数返回之间,栈中的数据如下图所示:

在 myFunction 返回后,main 函数会通过以下的指令来恢复栈基址指针并销毁已经失去作用的 40 字节栈内存:
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET通过分析 Go 语言编译后的汇编指令,我们发现 Go 语言使用栈传递参数和接收返回值,所以它只需要在栈上多分配一些内存就可以返回多个值。
对比
Go 语言和 C 语言在设计函数的调用惯例时选择了不同实现方法。C 语言同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值;而 Go 语言使用栈传递参数和返回值。这两种设计的优缺点如下:
-
C 语言的方式能够大幅度减少函数调用时的额外开销,但也增加了实现的复杂度
-
CPU 访问栈的开销比访问寄存器高几十倍
-
需要单独处理函数参数过多的情况。
-
-
Go 语言实现的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能:
-
不需要考虑超过寄存器数量的参数应该如何传递
-
不需要考虑不同架构上寄存器差异
-
函数入参和出参的内存空间需要在栈上进行分配
-
Go 语言使用栈作为参数的返回值传递的方法是综合考虑后的设计,这样意味着编译器会更加简单、更容易维护
2、参数传递
除了函数的调用惯例之外,我们还需要关心的另一个问题就是:Go 语言在参数传递时时传值还是传引用,不同的方式会影响我们的函数中修改入参时是否会影响我们的原数据。
-
传值:函数调用时会对参数进行拷贝,被调用方和调用方两者持有不相关的两份数据;
-
传引用:函数调用时会传递参数的指针,被调用方和调用方两者持有相同数据,任意一方做出修改都会影响到另一方。
在 Go 语言中,参数传递的方式是传值,也就是说:不论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。
整型和数组
如下示例,我们在 myFunction 内和 main 函数内分别打印参数的地址:
func myFunction(i int, arr [2]int) {
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := [2]int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc00009a000) arr=([66 77], 0xc00009a010)
in my_funciton - i=(30, 0xc00009a008) arr=([66 77], 0xc00009a020)
after calling - i=(30, 0xc00009a000) arr=([66 77], 0xc00009a010)会发现,main 函数和被调用者 myFunction 中参数的地址是完全不同的。
不过从 main 函数的角度来看,在调用 myFunction 前后,整数 i 和数组 arr 两个参数的地址都没有变化。
然后我们试着在 myFunction 函数中对参数进行修改:
func myFunction(i int, arr [2]int) {
i = 29
arr[1] = 88
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc000072008) arr=([66 77], 0xc000072010)
in my_funciton - i=(29, 0xc000072028) arr=([66 88], 0xc000072040)
after calling - i=(30, 0xc000072008) arr=([66 77], 0xc000072010)发现 myFunction 中对参数的修改也就仅仅影响了当前函数,并没有影响调用方 main 函数中的值。所以:Go 语言中对于基本类型和数组都是值传递的,即调用函数时会对参数进行拷贝。所以我们在传参的时候,如果参数所占空间特别大,这张传值的方式会特别影响性能。
结构体和指针
然后再可靠另外两种结构体和指针:
type MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
$ go run main.go
before calling - a=({30}, 0xc000018178) b=(&{40}, 0xc00000c028)
in my_function - a=({31}, 0xc000018198) b=(&{41}, 0xc00000c038)
after calling - a=({30}, 0xc000018178) b=(&{41}, 0xc00000c028)从结果可以得出结果:
-
传递结构体时:会拷贝结构体中的全部内容
-
传递结构体指针时:会拷贝结构体指针
修改结构体指针指向的内容,相当于改变了指针指向的结构体,所以在函数内部对结构体的修改是可以被 main 函数看到的。
我们简单修改上述代码,分析一下 Go 语言结构体在内存中的布局:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) {
ptr := unsafe.Pointer(ms)
for i := 0; i < 2; i++ {
c := (*int)(unsafe.Pointer((uintptr(ptr) + uintptr(8*i))))
*c += i + 1
fmt.Printf("[%p] %d\n", c, *c)
}
}
func main() {
a := &MyStruct{i: 40, j: 50}
myFunction(a)
fmt.Printf("[%p] %v\n", a, a)
}
$ go run main.go
[0xc000018180] 41
[0xc000018188] 52
[0xc000018180] &{41 52}从打印的地址可以看出,结构体在内存中是一片连续的内存空间,指向结构体的指针也就指向结构体的首地址。我们可以通过 通用指针类型unsafe.Pointer 和 指针运算类型uintptr 将普通指针进行转化和计算,可以通过偏移指针来访问对应的结构体的元素。
如果我们将上述代码简化成如下所示的代码片段并使用 go tool compile 进行编译会得到如下的结果:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) *MyStruct {
return ms
}
$ go tool compile -S -N -l main.go
"".myFunction STEXT nosplit size=20 args=0x10 locals=0x0
0x0000 00000 (main.go:8) MOVQ $0, "".~r1+16(SP) // 初始化返回值
0x0009 00009 (main.go:9) MOVQ "".ms+8(SP), AX // 复制引用
0x000e 00014 (main.go:9) MOVQ AX, "".~r1+16(SP) // 返回引用
0x0013 00019 (main.go:9) RET在这段汇编语言中,我们发现当参数是指针时,也会使用 MOVQ "".ms+8(SP), AX 指令复制引用,然后将复制后的指针作为返回值传递回调用方。
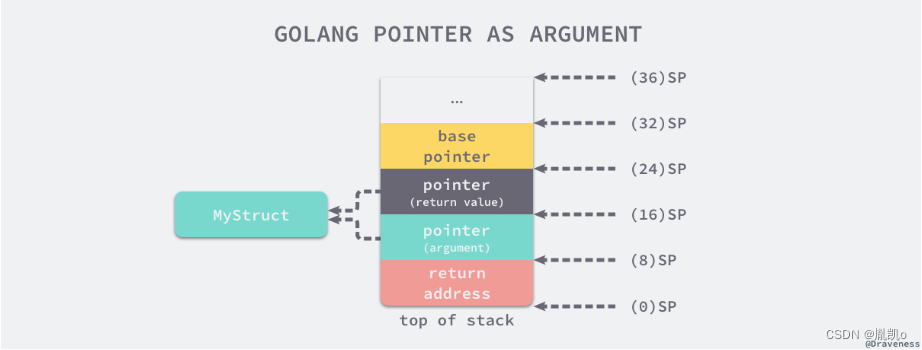
所以指针作为参数传入某个函数时,函数内部会复制指针,也就是会同时出现两个指针指向原有的内存空间。所以 Go 语言中传指针也是传值。
传值
当我们验证了 Go 语言中大多数常见的数据结构之后,其实能够推测出 Go 语言在传递参数时使用了传值的方式,接收方收到参数时会对这些参数进行复制;了解到这一点之后,在传递数组或者内存占用非常大的结构体时,我们应该尽量使用指针作为参数类型来避免发生数据拷贝进而影响性能。
3、小结
本文讲述了 Go 语言函数的调用惯例,是使用栈传递参数和返回值的,在调用函数之前会在栈上为返回值分配合适的内存空间,随后将入参从右到左按顺序压栈并拷贝参数,返回值会被存储到调用方预先留好的存储空间上。
关于 Go 语言函数调用,可以总结以下几点:
-
通过堆栈传递参数,入栈的顺序是从右到左,而参数的计算是从左到右;
-
函数返回值通过堆栈传递并由调用者预先分配内存空间;
-
调用函数时都是传值,接收方会对入参进行复制再计算;







![[足式机器人]Part2 Dr. CAN学习笔记-Ch0-1矩阵的导数运算](https://img-blog.csdnimg.cn/direct/c7499731c8c04e97a668d03762c8104c.png)