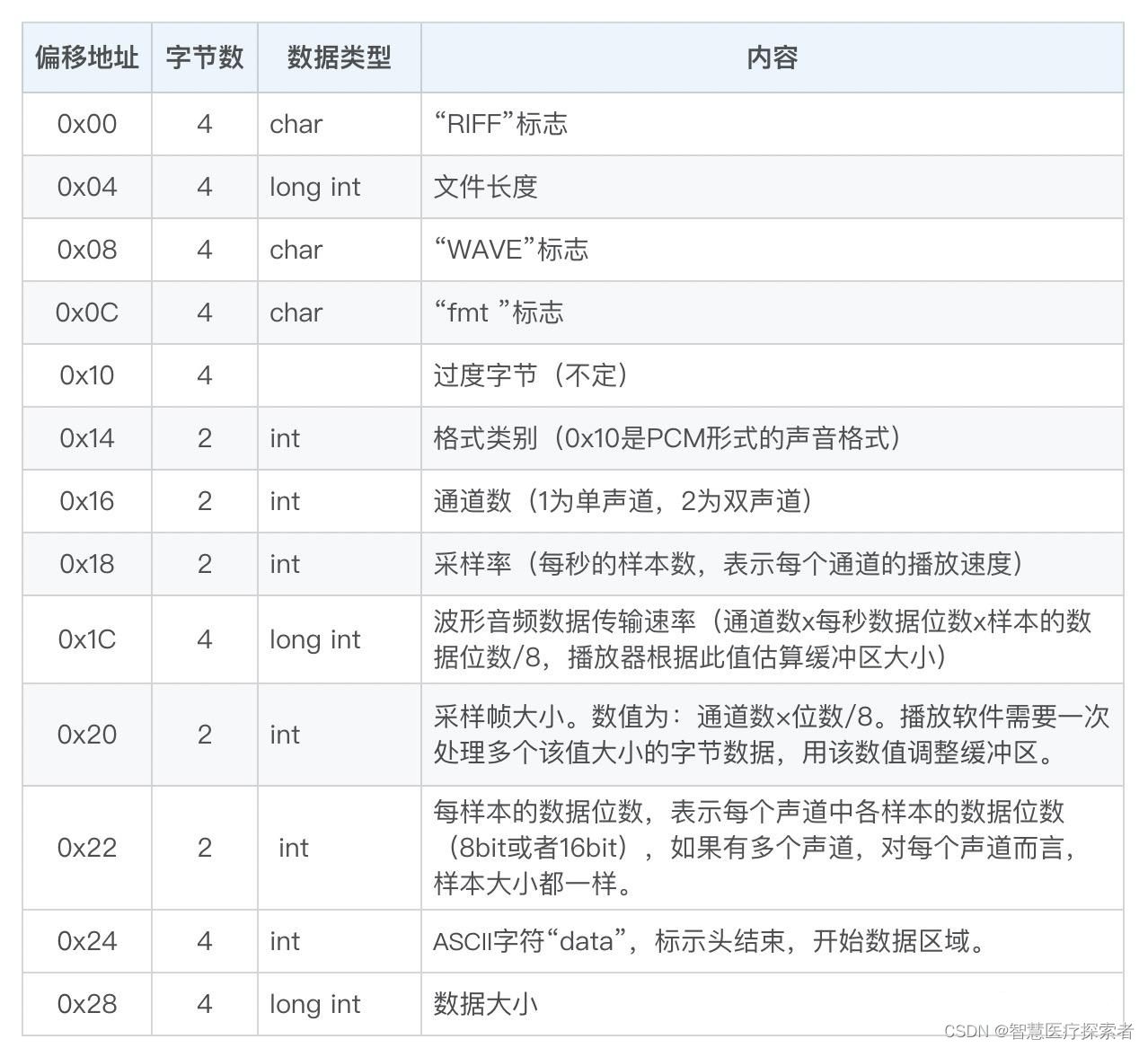
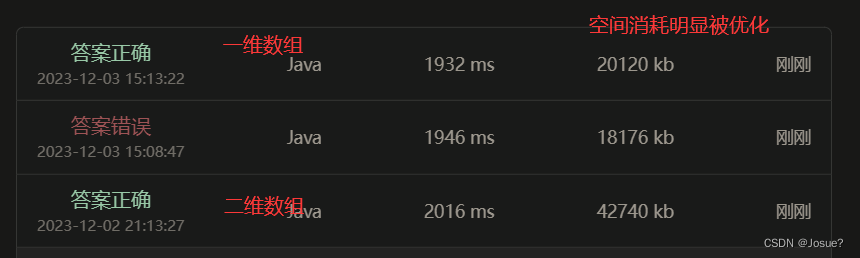
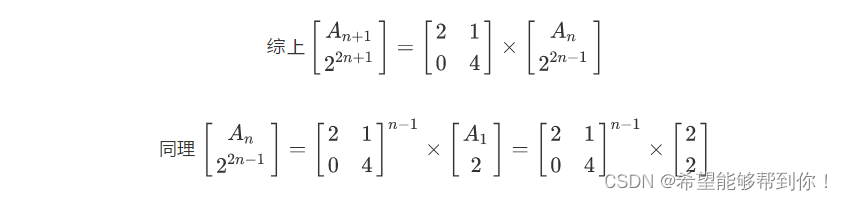关于SQL优化的思路,一般都是使用执行计划看看是否用到了索引,主要可能有两大类情况:
对业务字段建立了二级联合索引,但是MySQL错误地觉得走主键聚族索引全表扫描效率更高,而没有走二级索引
走二级索引,但是引起了几万、几十万的回表,此时还不如利用聚簇索引进行正序或者倒序的全表扫描,配合limit n,全表扫描只需要扫到符合条件的n条就停止
主从架构
采用主从半同步的机制,保证至少主的binlog成功写到从才返回,然后通过sharding-sphere做主从读写分离
案例二:亿级商品按类别/子类别查询的SQL优化-force index强制走某索引



也就是说这里的问题,
其实如果就算MySQL判断走错了索引,但是,因为只limit 10,如果能在全表扫描的过程中很快的就找到了满足条件的10条元素,那么就能很快的截断执行流程并直接返回,从而避免对整张表一扫到底,结果还没有凑齐满足条件的10条元素
案例三:十亿级评论表单商品几十万评论的深分页问题-优先主键全表扫描




案例四:千万级数据删除导致的慢查询



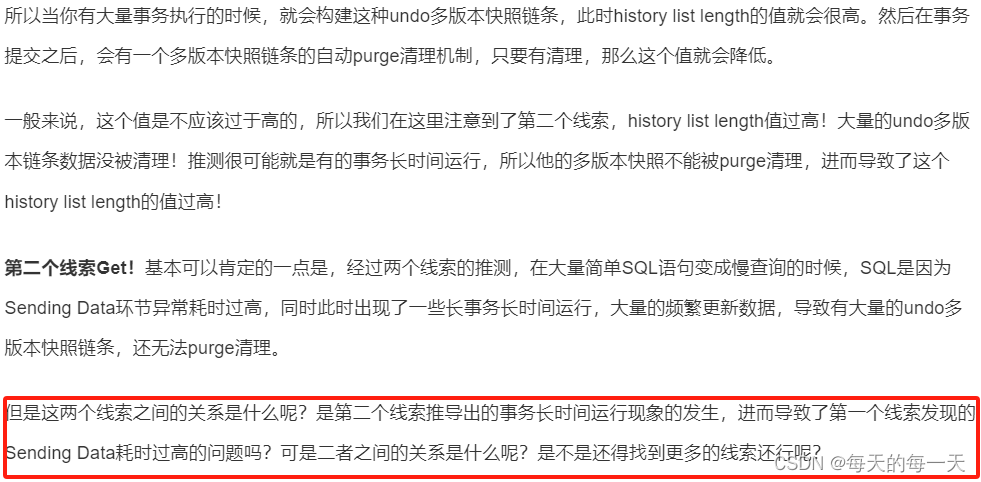



上面就是核心问题,就是每条数据都要去undo log中往前追溯,找属于自己能看到的版本对应的数据,一条两条可能速度不影响,如果上千万的数据都是这种,那么就影响很大了