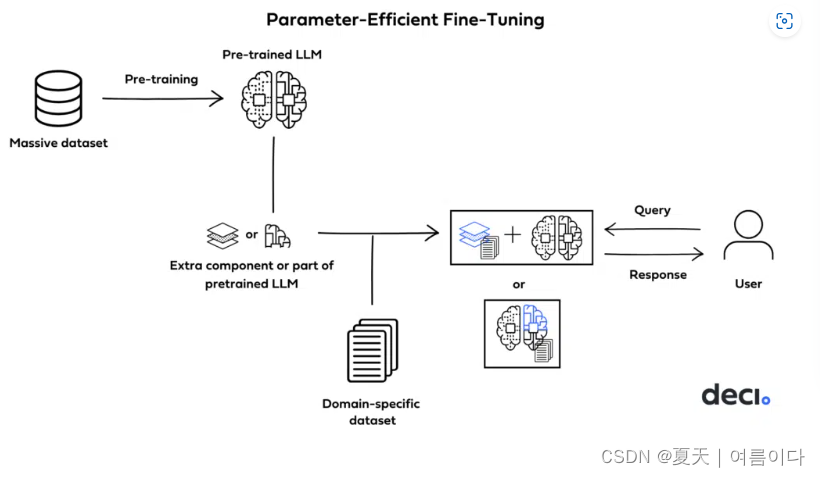
Parameter Efficient Fine Tuning(PEFT)也就是参数高效微调,是一种用于微调大型语言模型 (LLM) 的方法,与传统方法相比,它有效地降低了计算和内存需求。PEFT仅对模型参数的一小部分进行微调,同时冻结大部分预训练网络。这种策略减轻了大语言模型灾难性的遗忘,并显著降低了计算和存储成本。本博客主要内容如下
1.PEFT方法
2.训练、微调和提示工程:主要区别
3.LLM使用PEFT进行微调的过程
4.实例:使用参数高效微调(PEFT)微调预训练的语言模型,以进行情感分析
总结
1.PEFT方法
PEFT方法在确定模型的哪些组件是可训练的方法上有所不同。有的会优先训练原始模型参数的选定部分。有的人则在不修改原始结构的情况下集成和训练较小的附加组件,例如适配器层。
- 任务引导式提示调优:该技术利用特定于任务的提示来指导 LLM 的输出,无需为特定任务重新训练整个模型。
- 低秩适应 (LoRA):Low-Rank Adaptation 通过使用低秩矩阵近似 LLM 的参数,LoRA 减少了微调参数的数量,从而提高了 LLM 的性能。#LoRA论文【6】
- 适配器:这些小的专用层可以添加到 LLM 中以进行任务调整,从而提供灵活性和性能改进。
- 与任务相关的前缀调整:根据与手头任务相关的代表性前缀微调 LLM,可以提高性能和任务适应性。
2.训练、微调和提示工程:主要区别
在深入研究 PEFT 之前,让我们先了解一下训练、微调和提示工程之间的区别。这些术语通常可以互换使用,但在 LLM 的上下文中具有特定的含义。
- 训练:从头开始创建模型时,会对其进行训练。这涉及调整模型的所有系数或权重,以学习数据中的模式和关系。这就像教模型语言的基础知识一样。
- 微调:微调假设模型已经对语言有基本的了解(通过训练实现)。它涉及进行有针对性的调整,使模型适应特定的任务或领域。可以把它想象成为特定工作(例如回答问题或生成文本)完善受过良好教育的模型。
- 提示工程:提示工程涉及制作输入提示或问题,以指导 LLM 提供所需的输出。这是关于定制与模型交互的方式,以获得想要的结果。
3.LLM使用PEFT进行微调的过程
现在,让我们将注意力转移到PEFT的实际应用上。以下是使用 PEFT 进行微调所涉及的步骤:
- 数据准备:首先,以适合特定任务的方式构建数据集。定义输入和所需的输出。
- 库设置:安装必要的库,如 HuggingFace Transformers、Datasets、BitsandBytes 和 WandB,以监控训练进度。
- 模型:选择要微调的 LLM 模型。
- PEFT配置:配置 PEFT 参数,包括层的选择和 LoRA 中的“R”值。这些选择将确定您计划修改的系数子集。
- 量化:确定要应用的量化级别,在内存效率与可接受的错误率之间取得平衡。
- 训练参数:定义训练参数,例如批量大小、优化器、学习率调度器和微调过程的检查点。
- 微调:将 HuggingFace Trainer 与您的 PEFT 配置一起使用,以微调您的 LLM。使用 WandB 等库监控训练进度。
- 验证:密切关注训练和验证损失,以确保模型不会过度拟合。
- 检查点:如果需要,保存检查点以从特定点恢复训练。
***微调 LLM,尤其是使用 PEFT,是在高效参数修改和维护模型性能之间取得微妙的平衡***
语言模型和微调是自然语言处理领域的强大工具。PEFT技术与LoRA和量化等参数效率策略相结合,使我们能够有效地充分利用这些模型。
4.实例:使用参数高效微调(PEFT)微调预训练的语言模型,以进行情感分析
使用 TextClassificationPipeline 在 IMDb 数据集上微调预训练的 BERT 模型,以进行情感分析。
import torch
from transformers import BertTokenizer, BertForSequenceClassification, AdamW, pipeline
from datasets import load_dataset
# 加载imdb数据集
dataset = load_dataset("imdb")
# 加载Bert预训练模型和tokenizer
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # Binary sentiment analysis
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 划分数据集的训练集和测试集
train_dataset, val_dataset = tokenized_dataset["train"], tokenized_dataset["test"].train_test_split(test_size=0.1)
# 超参数和数据集配置
learning_rate = 2e-5
batch_size = 16
num_epochs = 3
# 确定优化器
optimizer = AdamW(model.parameters(), lr=learning_rate)
# 利用PEFT创建一个微调类
def fine_tune(model, train_dataset, optimizer, num_epochs, batch_size):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
total_loss = 0
model.train()
for i in range(0, len(train_dataset), batch_size):
batch = train_dataset[i:i+batch_size]
input_ids = torch.tensor(batch["input_ids"]).to(device)
attention_mask = torch.tensor(batch["attention_mask"]).to(device)
labels = torch.tensor(batch["label"]).to(device)
optimizer.zero_grad()
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch: {epoch+1}/{num_epochs}, Average Loss: {total_loss / len(train_dataset)}")
# 利用PEFT进行微调
fine_tune(model, train_dataset, optimizer, num_epochs, batch_size)
# 保存微调模型
output_dir = "fine_tuned_model/"
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# 加载微调模型进行文本分类
classifier = pipeline("text-classification", model=output_dir, tokenizer=output_dir)
# 测试
sample_text = "This movie was fantastic! I loved every bit of it."
result = classifier(sample_text)
print(result)总结
PEFT(参数高效微调)通过有针对性的系数调整来减少大型语言模型的计算和内存需求。
LoRA(低秩采用)选择重要系数,而量化通过将高精度系数转换为较低精度的形式来减少内存使用,这两者在 PEFT 中都至关重要。
使用 PEFT 微调 LLM 涉及结构化数据准备、库设置、模型选择、PEFT 配置、量化选择以及对训练和验证损失的监控,以平衡效率和模型性能。
参考文献
【1】What is Parameter-Efficient Fine-Tuning (PEFT) of LLMs? - Hopsworks
【2】 Parameter-Efficient Fine-Tuning using 🤗 PEFT (huggingface.co)
【3】 LLM Fine Tuning with PEFT Techniques (analyticsvidhya.com)
【4】Parameter-Efficient Fine-Tuning (PEFT): a novel approach for fine-tuning LLMs | by Tales Matos | Medium 【5】Full Fine-Tuning, PEFT, Prompt Engineering, or RAG? (deci.ai)
【6】 2106.09685.pdf (arxiv.org)