目录
- 一、概述
- 1.1 服务化部署
- 1.2 FastDeploy简介
- 二、搭建线上证件照制作系统
- 2.1 准备环境
- 2.1.1 安装Docker
- 2.1.2 安装NVIDIA Container Toolkit
- 2.1.3 获取FastDeploy Serving镜像
- 2.2 部署模型
- 2.2.1 准备模型仓库
- 2.2.2 编写配置文件config.pbtxt
- 2.2.3 服务启动
- 2.3.4 测试访问
- 2.3 后端开发
- 2.3.1 安装FastAPI
- 2.3.2 编写后端服务脚本
- 2.4 性能测试
- 2.4.1 统计各模块处理时间
- 2.4.2 压力测试
- 2.5 前端开发
- 2.5.1 准备前端资源
- 2.5.2 编写前端页面
- 三、小结
一、概述
进入21世纪以来,计算机软硬件得到飞速发展,促成了人工智能产生了质的进步,以深度学习为主的算法开始成为学术界和工业界的主流,涉及领域包括图像,文本,音频等。与此同时,随着开源项目的不断贡献以及深度学习框架的高度普及,深度学习算法的组网、训练和推理变得越来越容易。但是,由于部署环境的多样性,在深度学习产业落地过程中,走通深度学习模型部署的最后一公里是不容易的,其中涉及的问题很多,包括:显卡利用率低、内存溢出、多线程调度奔溃、加速算子不支持等等。
本文借助飞桨推出的最新部署工具FastDeploy,对深度学习服务化部署问题进行研究,将以人像抠图模型PP-Matting为研究对象,实现一种快速的、稳定的、高效的线上证件照制作系统。
1.1 服务化部署
通过深度学习训练得到的模型主要目的还是为了更有效地解决实际生产中的问题,因此部署是一个非常重要的阶段。本文所讨论的服务化部署就是将深度学习模型封装到一个web服务里去,对外暴露调用接口(HTTP,RPC等协议),实现线上推理。
模型服务化是近两年伴随微服务概念被“炒”得愈发热门的话题。模型服务化的核心功能包括:接收请求+前向推理计算。这种类似微服务的深度学习部署方式功能结构简单,客户端完全可以脱离“笨重”的环境依赖,只需要浏览器或http访问工具即可调用深度学习服务,因此服务化部署成为了当下非常热门的部署方式,被广泛用于各大公司的实际业务产品中。
Google早在2016年就针对TensorFlow推出了服务化框架TensorFlow Serving,能够把TensorFlow模型以web服务的方式对外暴露接口,通过网络请求方式接受来自客户端的请求数据,然后执行前向计算得到推理结果并返回。除了TensorFlow Serving以外,目前业界还有很多类似的服务化部署框架,比较流行的有英伟达推出的Triton Inference Server、Meta推出的TorchServe、百度推出的FastDeploy等。
考虑到国产化需求,本文将介绍如何使用FastDeploy来实现服务化部署任务。
1.2 FastDeploy简介
FastDeploy是百度飞桨(PaddlePaddle)推出的一款全场景、易用灵活、极致高效的AI推理部署工具,尤其是针对使用PaddlePaddle深度学习框架的用户来说,使用FastDeploy来部署所训练的模型极其方便。
在服务化部署方面,FastDeploy基于Triton Inference Server搭建了端到端的服务化部署方案,其底层后端使用FastDeploy高性能Runtime模块,并串联FastDeploy前后处理模块实现端到端的服务化部署,具有快速部署、使用简单、性能卓越的特性。
二、搭建线上证件照制作系统
证件照制作最关键的在于人像边界的准确提取,也就是所谓的抠图(Image Matting)。这个过程类似于语义分割任务,需要深度学习模型根据输入的人像照片从复杂的照片背景中预测出一个高精度的人像掩码图,然后再根据这个掩码图准确提取出人像区域,最后再将人像区域与纯色背景合成。在本文中,假设我们想要制作的证件照是蓝色背景的,那么整个执行流程如下所示:

本文重在讲解服务化的应用部署方法,不涉及算法原理和训练过程,对人像抠图算法PP-Matting原理或训练过程感兴趣的读者可以参阅官方教程,也可以参考我的另一篇博客。
2.1 准备环境
由于FastDeploy的Serving部署方案高度依赖Docker工具,因此部署环境建议是Linux系统(Ubuntu)。本文使用Ubuntu20.04来实现接下来的任务。
2.1.1 安装Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上。简单来看,Docker类似于一个轻量级的虚拟机。
使用Docker技术来实现深度学习模型的服务化部署非常方便,不管是服务的启动、暂停、销毁其速度都非常快,开销很低。
Docker的安装可以参照Docker官网。对于国内用户,建议使用下面的命令“傻瓜式”的完成Docker安装:
curl -sSL https://get.daocloud.io/docker | sh
2.1.2 安装NVIDIA Container Toolkit
由于我们需要在Docker中启动英伟达的GPU服务,因此需要安装英伟达容器化工具NVIDIA Container Toolkit,该工具使Docker的容器能与主机的Nvidia显卡进行交互。安装前要求nvidia的驱动已安装,但不要求安装CUDA。
需要注意的是,英伟达官网给出的是在线安装方法,但是由于国内网络原因,在线安装NVIDIA Container Toolkit存在一定问题。本文推荐使用离线安装方法,具体安装步骤如下。
- 下载5个deb文件
5个文件分别是:libnvidia-container1、libnvidia-container-tools、nvidia-container-toolkit、nvidia-container-runtime、nvidia-docker2。
下载网址为:http://mirror.cs.uchicago.edu/nvidia-docker/libnvidia-container/stable/ubuntu20.04/amd64/
上述网址对于不同的操作系统只需要修改网址中对应的操作系统路径即可,本文使用的是ubuntu20.04版本。下载时需要注意各个文件版本的一致性,本文下载的5个文件其文件名分别是:
libnvidia-container1_1.11.0-1_amd64.deb
libnvidia-container-tools_1.11.0-1_amd64.deb
nvidia-container-toolkit_1.11.0-1_amd64.deb
nvidia-container-runtime_3.11.0-1_all.deb
nvidia-docker2_2.11.0-1_all.deb
- 安装5个deb文件
将下载下来的5个文件放置到一个专门的文件夹中,然后cd到该文件夹下,使用下面的命令按次序进行安装:
sudo dpkg -i libnvidia-container1_1.11.0-1_amd64.deb
sudo dpkg -i libnvidia-container-tools_1.11.0-1_amd64.deb
sudo dpkg -i nvidia-container-toolkit_1.11.0-1_amd64.deb
sudo dpkg -i nvidia-container-runtime_3.11.0-1_all.deb
sudo dpkg -i nvidia-docker2_2.11.0-1_all.deb
- 重启Docker服务
查看所有容器运行状态:
sudo docker ps -a
确保没有正在运行的容器。如果有则用docker stop 来停止相关容器的运行。
重启Docker服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
- 验证nvidia-docker
执行命令:
nvidia-docker -v
正常输出如下所示:
Docker version 20.10.21, build baeda1f
2.1.3 获取FastDeploy Serving镜像
参考官方教程拉取合适的镜像:
sudo docker pull registry.baidubce.com/paddlepaddle/fastdeploy:1.0.1-gpu-cuda11.4-trt8.4-21.10
该镜像已经安装好相关的cuda、cudnn、tensorrt、fastdeploy、fastapi环境,只需要拉取镜像下来并且进入镜像即可正常使用。由于FastDeploy是国内百度研发的,镜像拉取速度是比较快的。
接下来基于拉取的镜像可以创建一个容器并进入:
sudo nvidia-docker run -it --net=host --name fd_serving registry.baidubce.com/paddlepaddle/fastdeploy:1.0.1-gpu-cuda11.4-trt8.4-21.10 bash
正常效果如下所示:
root@pu-Precision-7920-Tower:/#
此时已经进入了该镜像容器,并且在容器的bash命令行中,用户也已经切换成了容器中的root管理员用户。
此时输入命令:
nvidia-smi
如果出现类似下图所示效果说明一切都已经安装完毕:

2.2 部署模型
2.2.1 准备模型仓库
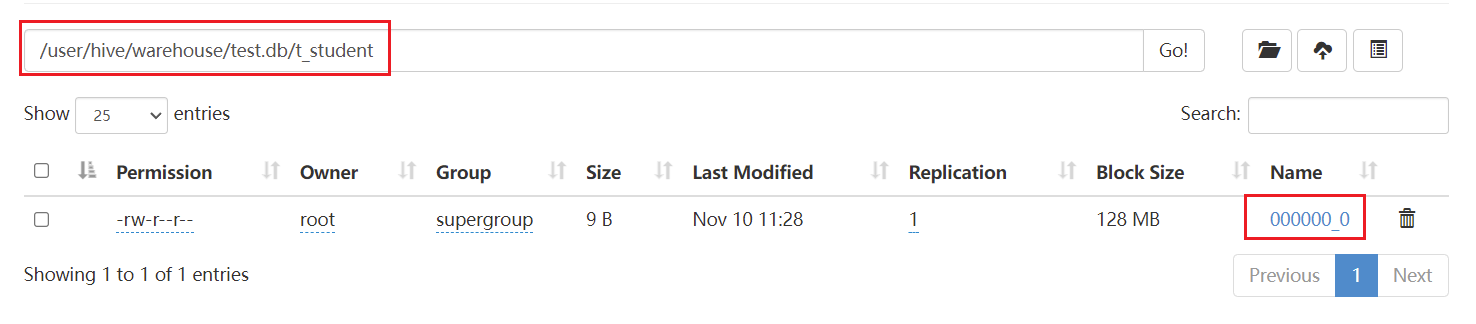
FastDeploy启动服务时需要指定模型仓库,也就是需要将训练好的静态图模型按照一定结构形式组织起来,这样FastDeploy的服务才能准确加载到模型。
首先我们创建一个文件夹专门用于部署,文件夹名称为MattingDeploy,然后进入到这个MattingDeploy文件夹内。
接下来下载PPMatting对应的静态图模型,下载网址:https://bj.bcebos.com/paddlehub/fastdeploy/PP-Matting-1024.tgz
这是一个适合高分辨率(1024像素)的图像抠图模型,解压后可以看到其中有4个文件:model.pdiparams、model.pdmodel、model.pdiparams.info、deploy.yaml。其中model.pdiparams和model.pdmodel这两个文件是我们真正需要的模型参数文件。deploy.yaml是配置文件,这个配置文件对于本文服务化部署来说并不需要,但是我们需要参考这个配置文件内容来编写前后处理代码。
下载完模型以后我们按照下面的结构进行组织:
MattingDeploy
└── models
└── ppmatting
├── 1
│ ├── model.pdiparams
│ └── model.pdmodel
└── config.pbtxt
在MattingDeploy根目录下建立模型仓库文件夹models。然后在模型仓库目录models下,必须有0个或多个模型名字的子目录,这里我们只有1个模型,即为ppmatting。每个模型名字子目录包含部署模型相应的信息,包括表示模型版本的数字子目录,在本文我们使用版本号1,另外还包含一个描述模型配置的config.pbtxt文件,这个文件我们暂时什么都不写,后面需要来编写其中的内容。在版本号文件夹1中存放真正的模型参数文件。由于本文使用的是PaddlePaddle框架训练出来的模型,所以,这里存放前面下载的PaddlePaddle静态图模型model.pdiparams和model.pdmodel即可(注意,这两个文件名称不要随意修改)。当然,FastDeploy是基于Triton Inference Server开发的,因此也支持onnx、pt(PyTorch静态图)、pb(Tensorflow)等模型。
到这里,完整的模型仓库就已经准备好了。可以看到,准备这样一个模型仓库还是比较简单的,只需要将训练好的静态图文件按照上述目录结构进行组织即可,不需要对模型做什么变换。
FastDeploy的Serving是通过读取模型仓库下的config.pbtxt配置文件来进行准确推理的,因此,接下来我们就来编写这个config.pbtxt文件。
2.2.2 编写配置文件config.pbtxt
对照本文任务,下面首先给出config.pbtxt的完整内容,然后再详细分析:
name: "ppmatting"
backend: "fastdeploy"
max_batch_size: 1
# Input configuration of the model
input [
{
# input name
name: "img"
# input type such as TYPE_FP32、TYPE_UINT8、TYPE_INT8、TYPE_INT16、TYPE_INT32、TYPE_INT64、TYPE_FP16、TYPE_STRING
data_type: TYPE_FP32
# input shape, The batch dimension is omitted and the actual shape is [batch, c, h, w]
dims: [ 3, -1, -1 ]
}
]
# The output of the model is configured in the same format as the input
output [
{
name: "tmp_75"
data_type: TYPE_FP32
dims: [ 1, -1, -1 ]
}
]
# Number of instances of the model
instance_group [
{
# The number of instances is 1
count: 1
# Use GPU, CPU inference option is:KIND_CPU
kind: KIND_GPU
# The instance is deployed on the 0th GPU card
gpus: [0]
}
]
optimization {
execution_accelerators {
# GPU推理配置, 配合KIND_GPU使用
gpu_execution_accelerator : [
{
name : "paddle"
# 设置推理并行计算线程数为1
parameters { key: "cpu_threads" value: "1" }
# 开启mkldnn加速,设置为0关闭mkldnn
parameters { key: "use_mkldnn" value: "1" }
}
]
}
}
- 模型服务名称name:开始的name字段定义了模型服务名称,后面我们在使用fastdeploy命令启动服务的时候需要用到这个名称,这个名称需要与存放模型的文件夹对应;
- 后端backend:由于本模型是一个深度学习推理模型,因此backend属性设置为fastdeploy;如果模型不是一个深度学习推理模型,是一个基于python的前处理或后处理脚本,那么这里的backend就设置为python;
- 输入input和输入output:在input和output字段,需要结合实际模型结构来编写其中的字段属性。其中一共需要知道3个属性:输入和输出名称name、输入和输出数据类型data_type、输入和输入数据维度dims。那么怎么知道模型的这些信息呢?这里我们可以借助飞桨提供的可视化工具visualdl来实现。如果没有安装过visualdl,可以使用下面的命令进行安装:
pip install visualdl -i https://mirror.baidu.com/pypi/simple
然后使用下面的命令启动visualdl:
visualdl --logdir log
成功启动后,通过浏览器打开网址:http://localhost:8040/,效果如下所示:
 由于当前我们并不是需要查看模型训练日志,因此,打开后是没有训练日志类可视化结果的。
由于当前我们并不是需要查看模型训练日志,因此,打开后是没有训练日志类可视化结果的。
单击顶部菜单栏“网络结构”->“网络结构-静态”,然后按照页面提示把前面下载的模型文件model.pdmodel拖到这个页面上即可打开模型,同时在右侧勾上“显示节点名称”,这样就可以查看该模型完整结构以及节点名称。如下所示:

单击图形上顶部的0,会弹出模型的输入输出完整信息:

根据这些信息,我们就可以知道模型的输入名称为img,形状为[1,3,1024,1024],类型为float32;输出名称为tmp_75,输出形状为[1,1,1024,1024],输出类型为float32;将这些信息对应的填入到config.pbtxt的输入输出字段即可。需要注意的是,在填写形状信息的时候,第一个batch字段可以默认不填写,后面的特征高度和宽度字段可以填[-1,-1],这样表示模型对输入的特征形状可变,我们只需要填写对应的特征通道即可。
- 模型分配实例instance_group:这个字段内用来填写我们的模型最终运行在GPU还是CPU上,并且运行在哪几个GPU上。本文count设置为1表示每个GPU上只跑1个模型,gpus设置为[0]表示只在0号GPU上运行;如果想要在多个GPU上运行,可以设置为[0,1,2,3]这种形式。
- 加速方案optimization:本文上述代码的设置是对应GPU的方案,并且推理引擎使用的是Paddle,如果想要使用其他引擎,例如ONNXRuntime或OpenVINO或TensorRT,那么可以参考官方文档。
到这里,我们就完成了模型服务化的准备工作,可以看到整个服务化部署过程是非常简单的。下面介绍如何在Docker中启动服务。
2.2.3 服务启动
首先确保当前位于项目根目录MattingDeploy文件夹下面。根据前面拉取的fastdeploy,建立matting容器:
sudo nvidia-docker run -dit --net=host --name matting --shm-size="1g" -v $PWD:/matting registry.baidubce.com/paddlepaddle/fastdeploy:1.0.1-gpu-cuda11.4-trt8.4-21.10 bash
然后进入该容器命令行:
sudo docker exec -it -u root matting bash
进入以后,可以运行nvidia-smi命令检查容器是否能正常调用GPU。正常如下图所示:

然后在docker内安装libgl1依赖,使用下面的命令完成安装:
ldconfig
apt-get install libgl1
最后使用下面的命令来启动FastDeploy的serving服务:
fastdeployserver --model-repository=/matting/models
相关参数如下:
- model-repository(required): 模型存放的路径,当前我们把本地的MattingDeploy文件夹映射到了Docker中的matting文件夹,因此启动命令中该字段为/matting/models;
- http-port(optional): HTTP服务的端口号. 默认: 8000;
- grpc-port(optional): GRPC服务的端口号. 默认: 8001;
- metrics-port(optional): 服务端指标的端口号. 默认: 8002;
启动成功后如下图所示:

2.3.4 测试访问
本小节内容我们在非docker容器内实现(保持上一小节中Docker内的fastdeploy服务一直开着不要关),通过编写python脚本用于访问测试。需要注意的是,前面我们将模型推理部分进行了服务化部署,但是没有做任何的数据前处理和后处理。一种解决方法就是将前处理和后处理也各自作为一个推理服务,按照前面的方式进行组织,最后使用一个串联服务将所有任务进行串联。这种方式也是目前FastDeploy官网各个示例程序使用的方式,在后期成熟以后可以采用这种方式,但是在前期部署时建议还是采用本文的更简单的方式。本文将前处理和后处理放在客户端完成,服务端仅实现深度学习模型推理,这样方便调试和维护。
编写模型的前处理和后处理流程需要对模型有一定的认识,也可以参考前面下载的deploy.yaml文件,结合里面的前后处理参数设置来实现。虽然没有固定的套路,但是总结起来无非就是图像空间转换、尺寸缩放、归一化等步骤,这些都可以通过查阅模型的推理代码来获得。另外,由于前后处理都在一个前端python脚本实现,因此,debug非常方便。
服务的调用有两种方式:GRPC和Http。相对来说,GRPC调用速度更快、连接更稳定,但是其依赖特定的库,通用性不强。Http方式更通用,但是速度一般。本节内容我们采用GRPC方式来实现。
首先安装tritonclient[grpc]
pip install tritonclient[grpc] -i https://mirror.baidu.com/pypi/simple
tritonclient[grpc]提供了使用GRPC的客户端,并且对GRPC的交互进行了封装,使得用户不用手动和服务端建立连接,接口调用会更加简单。
在当前项目根目录准备一张人像照片1.jpg,然后创建一个客户端脚本文件client.py,其内容如下:
import numpy as np
import cv2
# 导入grpc客户端
import tritonclient.grpc as grpcclient
# 定义grpc服务器的地址
server_addr = 'localhost:8001'
# 创建grpcclient
client = grpcclient.InferenceServerClient(server_addr)
# 读取图像
image = cv2.imread('1.jpg', cv2.IMREAD_COLOR)
# 图像缩放(对于抠图任务,短边对齐1024,长边保证为32的整数倍)
ref_size = 1024
im_h, im_w, _ = image.shape
if im_w >= im_h:
im_rh = ref_size
im_rw = int(im_w * 1.0 / im_h * ref_size)
elif im_w < im_h:
im_rw = ref_size
im_rh = int(im_h * 1.0 / im_w * ref_size)
im_rw = im_rw - im_rw % 32
im_rh = im_rh - im_rh % 32
im = cv2.resize(image, (im_rw, im_rh))
# 归一化
im = im / 255.0
# 扩充batch通道并调整通道顺序
im = np.transpose(im[np.newaxis, :, :, :], (0, 3, 1, 2)).astype(np.float32)
# 构造输入数据
inputs = []
infer_input = grpcclient.InferInput('img', im.shape, 'FP32')
infer_input.set_data_from_numpy(im) # 载入输入数据
inputs.append(infer_input)
# 构造输出数据
outputs = []
infer_output = grpcclient.InferRequestedOutput('tmp_75') # 构造输出
outputs.append(infer_output)
# 请求推理
response = client.infer('ppmatting',
inputs,
model_version='1',
outputs=outputs)
response_output = response.as_numpy('tmp_75') # 根据输出变量名获取结果
# 后处理
alpha = response_output.squeeze(0).squeeze(0)
alpha = (alpha * 255).astype('uint8')
alpha = cv2.resize(alpha, (im_w, im_h))
#与新背景合成(证件照蓝色底)
bg = np.zeros(image.shape, np.uint8)
bg[:] = [219, 142, 67]
alpha = cv2.cvtColor(alpha, cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = image * alpha_f + bg * (1. - alpha_f)
cv2.imwrite('comp.jpg', comp.astype(np.uint8))
处理前后效果如下所示:

从上图中可以看到整体效果还是不错的。上述代码给出了详细的注释,其他类似的任务也可以参照上述代码稍作修改即可方便的进行服务测试。
2.3 后端开发
前面完成了模型部署和测试脚本开发,我们将相关前后处理代码都放在了测试脚本中,这样一种方式对前端并不友好。本小节我们将基于fastapi框架开发一套后端微服务,封装相关的前后处理代码并且优化对外请求接口。
之所以选用fastapi作为后端框架,有两个重要因素:
- 语言环境:从前面的测试脚本看到,tritonclient[grpc]客户端提供了python语言用于实现GRPC请求,并且我们的前后处理流程都是通过python实现的,因此选择基于python的fastapi框架进行微服务开发尤为合适;
- 框架速度:在众多python web框架中,fastapi是响应速度最快、微服务开发最便捷的,在fastapi官网上写着“可与 NodeJS 和 Go 比肩的极高性能”;
2.3.1 安装FastAPI
fastapi的安装非常简单:
pip install fastapi -i https://mirror.baidu.com/pypi/simple
pip install "uvicorn[standard]" -i https://mirror.baidu.com/pypi/simple
pip install python-multipart -i https://mirror.baidu.com/pypi/simple
2.3.2 编写后端服务脚本
在当前根目录下新建一个脚本main.py,其内容如下:
import numpy as np
import cv2
import base64
from fastapi import FastAPI, File, UploadFile
import tritonclient.grpc as grpcclient
# 定义fastapi的启动app
app = FastAPI()
# 定义grpc服务器的地址
server_addr = 'localhost:8001'
# 创建grpcclient
client = grpcclient.InferenceServerClient(server_addr)
# 定义访问接口
@app.post("/matting/")
async def get_image(file: UploadFile =File(...)):
# 接收前端上传的图片
imgdata = await file.read()
imgdata = np.frombuffer(imgdata, np.uint8)
image = cv2.imdecode(imgdata, cv2.IMREAD_COLOR)
# 图像缩放(对于抠图任务,短边对齐1024,长边保证为32的整数倍)
ref_size = 1024
im_h, im_w, _ = image.shape
if im_w >= im_h:
im_rh = ref_size
im_rw = int(im_w * 1.0 / im_h * ref_size)
elif im_w < im_h:
im_rw = ref_size
im_rh = int(im_h * 1.0 / im_w * ref_size)
im_rw = im_rw - im_rw % 32
im_rh = im_rh - im_rh % 32
im = cv2.resize(image, (im_rw, im_rh))
# 归一化
im = im / 255.0
# 扩充batch通道并调整通道顺序
im = np.transpose(im[np.newaxis, :, :, :], (0, 3, 1, 2)).astype(np.float32)
# 构造输入数据
inputs = []
infer_input = grpcclient.InferInput('img', im.shape, 'FP32')
infer_input.set_data_from_numpy(im)
inputs.append(infer_input)
# 构造输出数据
outputs = []
infer_output = grpcclient.InferRequestedOutput('tmp_75')
outputs.append(infer_output)
# 请求推理
response = client.infer('ppmatting',
inputs,
model_version='1',
outputs=outputs)
response_output = response.as_numpy('tmp_75')
# 后处理
alpha = response_output.squeeze(0).squeeze(0)
alpha = (alpha * 255).astype('uint8')
alpha = cv2.resize(alpha, (im_w, im_h))
#与新背景合成(证件照蓝色底)
bg = np.zeros(image.shape, np.uint8)
bg[:] = [219, 142, 67]
alpha = cv2.cvtColor(alpha, cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = image * alpha_f + bg * (1. - alpha_f)
# 返回处理后的图像数据
_, buffer_img = cv2.imencode('.jpg', comp)
img64 = base64.b64encode(buffer_img)
img64 = str(img64, encoding='utf-8')
return {"img": img64}
# if __name__ == "__main__":
# '''程序启动入口'''
# import uvicorn
# uvicorn.run(app, host="0.0.0.0", port=8040)
上述代码我们将前面编写的client.py脚本中相关处理代码融入了进来,并且定义了一个get_image()函数用来响应路由@app.post(“/matting/”)。这个路由通过fastapi启动后完整的访问链接为:http://127.0.0.1:8040/matting。
接下来使用下面的命令启动微服务,启动端口为8040:
uvicorn matting/main_fastapi:app --host 0.0.0.0 --port 8040
当然,我们也可以将这个微服务在docker中启动,这样,就把自定义微服务和fastdeploy这两个服务一起打包在了Docker容器中。
具体的,进入到前面创建的docker容器中,我们可以使用下面的命令启动fastdeployserver:
fastdeployserver --model-repository=/matting/models &
后面加个&符号可以让fastdeployserver在后台一直运行,想要关掉服务可以使用pkill fastdeployserver将服务进程停掉。
然后再使用命令下面的命令启动自定义微服务:
cd matting
uvicorn main_fastapi:app --host 0.0.0.0 --port 8040 &
想要停止微服务可以使用命令pkill uvicorn实现。
把fastdeployserver和自定义的fastapi微服务都启动后,接下来我们就可以写个更简单的测试脚本来进行测试了。
新建一个脚本文件new_client.py,其内容如下:
# 导入依赖库
import numpy as np
import requests
import cv2
import base64
# 定义http接口
url = "http://127.0.0.1:8040/matting"
# 发送请求
files = {'file':open('1.jpg','rb'),}
result = requests.post(url=url, files=files)
# 解析返回值
result = result.json()
# 解码返回的图像数据
img = result["img"]
img = bytes(img, encoding='utf-8') # str转bytes
img = base64.b64decode(img) # base64解码
img = np.asarray(bytearray(img), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_UNCHANGED)
# 保存图像到本地
if img is None:
print('调用失败')
else:
cv2.imwrite('result.png',img)
print('完成')
正常运行后,可以将本地名为1.jpg的图像发送给微服务,并获得响应,最后对响应结果进行解析并将解析后的图像保存到本地。可以看到,上述脚本代码不再需要复杂的前处理和后处理代码了,更适合前端工程师按照这个脚本逻辑开发相应的前端代码。
2.4 性能测试
2.4.1 统计各模块处理时间
针对2.3节中创建的client.py脚本,我们修改少量代码,统计前处理、模型预测、后处理这三大模块的单张图像推理时间。我们采用1张500x719像素大小的jpeg图像进行测试。
本文测试的服务器是两卡NVIDIA Geforce 3080Ti,单张显卡显存12G。
修改后的client.py文件其内容如下:
import numpy as np
import cv2
import time
# 导入grpc客户端
import tritonclient.grpc as grpcclient
# 定义grpc服务器的地址
server_addr = 'localhost:8001'
# 创建grpcclient
client = grpcclient.InferenceServerClient(server_addr)
preprocess_time = 0
runtime_time = 0
postprocess_time = 0
# 读取图像
n = 20
for i in range(n):
print(i)
start_time = time.time()
image = cv2.imread('2.jpeg', cv2.IMREAD_COLOR)
# 图像缩放(对于抠图任务,短边对齐1024,长边保证为32的整数倍)
ref_size = 1024
im_h, im_w, _ = image.shape
if im_w >= im_h:
im_rh = ref_size
im_rw = int(im_w * 1.0 / im_h * ref_size)
elif im_w < im_h:
im_rw = ref_size
im_rh = int(im_h * 1.0 / im_w * ref_size)
im_rw = im_rw - im_rw % 32
im_rh = im_rh - im_rh % 32
im = cv2.resize(image, (im_rw, im_rh))
# 归一化
im = im / 255.0
# 扩充batch通道并调整通道顺序
im = np.transpose(im[np.newaxis, :, :, :], (0, 3, 1, 2)).astype(np.float32)
# 构造输入数据
inputs = []
infer_input = grpcclient.InferInput('img', im.shape, 'FP32')
infer_input.set_data_from_numpy(im) # 载入输入数据
inputs.append(infer_input)
# 构造输出数据
outputs = []
infer_output = grpcclient.InferRequestedOutput('tmp_75') # 构造输出
outputs.append(infer_output)
end_time = time.time()
preprocess_time += end_time-start_time
# 请求推理
start_time = time.time()
response = client.infer('ppmatting',
inputs,
model_version='1',
outputs=outputs)
response_output = response.as_numpy('tmp_75') # 根据输出变量名获取结果
end_time = time.time()
runtime_time += end_time-start_time
# 后处理
start_time = time.time()
alpha = response_output.squeeze(0).squeeze(0)
alpha = (alpha * 255).astype('uint8')
alpha = cv2.resize(alpha, (im_w, im_h))
#与新背景合成(证件照蓝色底)
bg = np.zeros(image.shape, np.uint8)
bg[:] = [219, 142, 67]
alpha = cv2.cvtColor(alpha, cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = image * alpha_f + bg * (1. - alpha_f)
cv2.imwrite('comp.jpg', comp.astype(np.uint8))
end_time = time.time()
postprocess_time += end_time-start_time
print('preprocess_time %f' % (preprocess_time/n))
print('runtime_time %f' % (runtime_time/n))
print('postprocess_time %f' % (postprocess_time/n))
统计结果如下:
preprocess_time 0.075146
runtime_time 0.448024
postprocess_time 0.038143
可以看到预处理时间大概是70ms,模型预测时间大概是448ms,后处理时间大概是38ms。值得注意的是,本文采用的抠图模型是一个适合1024x1024高分辨率图像的算法,模型本身比较重,因此,模型推理比较耗时。
接下里我们停止docker环境中的fastdeployserver服务,修改模型的config.pbtxt参数。由于本服务器有两个GPU,因此我们对instance_group属性修改如下:
instance_group [
{
# The number of instances is 1
count: 1
# Use GPU, CPU inference option is:KIND_CPU
kind: KIND_GPU
# The instance is deployed on the 0th GPU card
gpus: [0,1]
}
]
同时,我们修改optimization中的并行计算线程数,修改为4,如下所示:
optimization {
execution_accelerators {
# GPU推理配置, 配合KIND_GPU使用
gpu_execution_accelerator : [
{
name : "paddle"
# 设置推理并行计算线程数为4
parameters { key: "cpu_threads" value: "4" }
# 开启mkldnn加速,设置为0关闭mkldnn
parameters { key: "use_mkldnn" value: "1" }
}
]
}
}
改完后重启fastdeployserve并再次进行测试,结果如下:
preprocess_time 0.072160
runtime_time 0.286153
postprocess_time 0.037918
可以看到,修改后的模型预测速度有了明显提升,说明两张显卡的作用发挥了出来。
2.4.2 压力测试
下面我们在本地建立一个脚本文件test.py,专门用来测试整个服务的QPS性能,内容如下:
# 导入库
import threading
import time
import requests
# 参数设置
url = "http://127.0.0.1:8040/matting" # 访问接口
imgPath = "2.jpeg" # 图像路径
NUM_REQUESTS = 100 # 并发请求数
SLEEP_COUNT = 0.05 # 请求间隔
def call_matting():
"""并行发送线程"""
# 发送请求
files = {
'file': open(imgPath, 'rb'),
}
result = requests.post(url=url, files=files)
# 接收并显示结果
result = result.json()
img = result["img"]
print('线程 %s 请求成功' % (threading.current_thread().name))
time.sleep(SLEEP_COUNT)
if __name__ == '__main__':
# 创建并发访问线程池
thread_list = []
for i in range(NUM_REQUESTS):
t = threading.Thread(target=call_matting)
thread_list.append(t)
# 启动线程池
start_time = time.time()
for t in thread_list:
t.setDaemon(True)
t.start()
# 设置主线程等所有子线程运行完毕
for t in thread_list:
t.join()
# 结束后统计QPS
end_time = time.time()
print("全部结束 QPS: %f" % (NUM_REQUESTS/(end_time-start_time)))
输出结果如下:
全部结束 QPS: 2.674852
这个QPS数值跟上一小节各个模块测试时间累加和是吻合的。想要进一步提高速度,可以尝试用tensorrt引擎替换掉paddle,或者换用更好的GPU,本文不再深入阐述。
2.5 前端开发
前面的内容其实已经把整个的fastdeployserver部署讲解完了,本小节的内容我们将开发一个简易的前端模块,通过搭建一个网页界面用于图形化展示功能。我们将借用前面的fastapi框架继续开发前端界面,当然,如果读者使用的是其他web框架(例如java spring、asp.net、php等)也没关系,因为我们已经把访问接口通用化了,只需要按照上述格式封装请求即可。另外,本文只是一个简单的演示项目,因此不采用vue3、react等功能强大的前端框架,而是尽可能使用原生的js语法即可。
2.5.1 准备前端资源
综合考虑到界面美观和简单,我们使用一个免费的界面模板,这个模板是基于bootstrap开发的。下载后将其解压。
在项目根目录MattingDeploy文件夹下新建两个子文件夹:static和templates。然后将前面下载的模板文件中的assets、css、js文件夹整个拷贝到MattingDeploy/static文件下面,然后将index.html文件拷贝到MattingDeploy/templates文件夹中。到这里,前端所需要的静态资源就导入完成了。
下面我们完善一下前面开发的微服务脚本main_fastapi.py,让这个微服务具备html页面渲染的能力。由于fastapi是使用jinja2来渲染html文本的,因此首先安装一下jinja2:
pip install jinja2
在main_fastapi.py文件最后,添加下面的代码:
# 开发前端界面
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
from fastapi.responses import HTMLResponse
from fastapi import Request
from fastapi.middleware.cors import CORSMiddleware
# 挂载静态资源目录
app.mount("/static", StaticFiles(directory="static"), name="static")
# 定义页面模板库位置
templates = Jinja2Templates(directory="templates")
# 解除跨域访问限制
origins = ["*"]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义首页
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
接下来修改相应的home.html文件完成前端静态资源的导入,修改方法很简单,只需要在类似css/styles.css这种资源引用的地方统一添加一个/static目录前缀,如下所示:
将:
<link href="css/styles.css" rel="stylesheet" />
修改为:
<link href="/static/css/styles.css" rel="stylesheet" />
将:
<script src="js/scripts.js"></script>
修改为:
<script src="/static/js/scripts.js"></script>
最后再适当修改home.html文字内容,然后重启fastapi微服务,效果如下所示:

由于Bootstrap 的所有 JavaScript 插件都依赖 jQuery,而我们下载的这个模板中并没有提供jQuery,因此我们要下载jQuery并且放到js文件夹中并引用进来。下载地址:https://cdn.jsdelivr.net/npm/jquery@1.12.4/dist/jquery.min.js。将上述地址用浏览器打开,然后右键页面另存为jquery.min.js,将这个jquery.min.js放在static/js目录下。最后在home.html中引用这个js:
<script src="/static/js/jquery.min.js"></script>
2.5.2 编写前端页面
编写index.html,完整内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no" />
<meta name="description" content="" />
<meta name="author" content="" />
<title>证件照制作系统</title>
<link rel="icon" type="image/x-icon" href="/static/assets/favicon.ico" />
<!-- Core theme CSS (includes Bootstrap)-->
<link href="/static/css/styles.css" rel="stylesheet" />
<!-- Bootstrap core JS-->
<script src="/static/js/jquery.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/js/bootstrap.bundle.min.js"></script>
<!-- Core theme JS-->
<script src="/static/js/scripts.js"></script>
</head>
<body id="page-top">
<!-- Navigation-->
<nav class="navbar navbar-expand-lg navbar-dark bg-dark fixed-top" id="mainNav">
<div class="container px-4">
<a class="navbar-brand" href="#page-top">在线证件照制作</a>
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarResponsive"
aria-controls="navbarResponsive" aria-expanded="false" aria-label="Toggle navigation"><span
class="navbar-toggler-icon"></span></button>
<div class="collapse navbar-collapse" id="navbarResponsive">
<ul class="navbar-nav ms-auto">
<li class="nav-item"><a class="nav-link" href="#about">关于我们</a></li>
</ul>
</div>
</div>
</nav>
<!-- Header-->
<header class="bg-primary bg-gradient text-white">
<div class="container px-4 text-center">
<h1 class="fw-bolder">欢 迎 使 用</h1>
<p class="lead">一键搞定证件照制作</p>
<a class="btn btn-lg btn-light" data-bs-toggle="modal" data-bs-target="#myModal">开始使用</a>
</div>
</header>
<!-- 模态框(Modal) -->
<div class="modal fade" id="myModal" tabindex="-1" aria-labelledby="mattingModalLabel" aria-hidden="true">
<div class="modal-dialog modal-lg">
<div class="modal-content">
<div class="modal-header">
<h1 class="modal-title fs-5" id="mattingModalLabel">在线证件照制作</h1>
<button type="button" class="btn-close" data-bs-dismiss="modal" aria-label="Close"></button>
</div>
<div class="modal-body">
<div class="container-fluid">
<div class="row">
<div class="col-md-6 col-lg-6 col-xs-6">
<img id="photoIn" src="/static/img/sample.png" class="img-responsive"
style="max-width:200px">
<input type="file" id="photo" name="photo" />
</div>
<div class="col-md-6 col-lg-6 col-xs-6">
<img id="photoOut" class="img-responsive" style="max-width:200px">
</div>
</div>
</div>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary" data-bs-dismiss="modal">关闭</button>
<button type="button" id="btn_process" class="btn btn-primary"
onclick="ProcessImg(this);">制作</button>
</div>
</div>
</div>
</div>
<script>
//图像改变时显示内容切换
$(function () {
$('#photo').on('change', function () {
var r = new FileReader();
f = document.getElementById('photo').files[0];
r.readAsDataURL(f);
r.onload = function (e) {
document.getElementById('photoIn').src = this.result;
};
});
});
//展示制作结果
function ShowResult(data) {
var str_img = data['img'];
var str_b64_type = "data:image/jpg;base64,";
document.getElementById('photoOut').src = str_b64_type + str_img;
}
//在线抠图推理
function ProcessImg(obj) {
//提取图像数据
var str_img_data = document.getElementById('photoIn').src;
var dst_img_data = document.getElementById('photoOut').src;
var file = document.getElementById('photo').files[0];
if (file == "") {
alert("请先选择要测试的图片!");
return;
}
//封装请求
var formdata = new FormData();
var file = $("#photo")[0].files[0];
formdata.append("file", file);
//通过ajax发送数据
$.ajax({
url: 'http://127.0.0.1:8040/matting/', //调用微服务
type: 'POST', //请求类型
data: formdata,
dataType: 'json',
processData: false,
contentType: false,
success: ShowResult //在请求成功之后的回调函数
})
}
</script>
<!-- About section-->
<section id="about">
<div class="container px-4">
<div class="row gx-4 justify-content-center">
<div class="col-lg-8">
<h2>标准证件照基本要求</h2>
<p class="lead">证件照的要求是免冠(不戴帽子)正面照片,照片上正常应该看到人的两耳轮廓和相当于男士的喉结处的地方,照片尺寸可以为一寸或二寸,
拍照时不得上唇膏等影响真实面貌的化妆色彩</p>
<ul>
<li>分辨率: 350dpi</li>
<li>照片规格: 358像素(宽)×441像素</li>
<li>颜色模式: 24位RGB真彩色</li>
</ul>
</div>
</div>
</div>
</section>
<!-- Footer-->
<footer class="py-5 bg-dark">
<div class="container px-4">
<p class="m-0 text-center text-white">Copyright © 证件照制作系统 2022</p>
</div>
</footer>
</body>
</html>
修改完成后单击重启微服务,然后访问网站http://0.0.0.0:8040/,单击主页上的开始使用按钮,然后在弹出的模态框中单击Browse按钮从本地选择一张图片,然后单击“制作”按钮执行证件照在线制作。最终展示效果如下:

三、小结
本文基于FastDeploy实现了完整的线上证件照制作系统,通过FastDeploy Serving完成了人像抠图模型部署。本文更偏重应用,对于亟需通过serving服务化方式部署深度学习模型的相关读者可以参考本文来实现。对于抠图(matting)感兴趣的读者,也可以在本文基础上,继续深入研究算法原理,结合本文部署流程,开发出更高精度、更商业级别的抠图产品。
最后打个软广,在2023年6月将会出版一本实战书籍《深度学习与图像处理—基于PaddlePaddle》—钱彬和朱会杰著,清华大学出版社出版。除了本文内容以外,书中会有更多精彩的实战案例分享(包含源码),同时也会补足算法原理部分,想要继续深入学习PaddlePaddle的读者欢迎关注和支持。
由于水平有限,文中难免有错误或者不当的地方,请读者随时批评指正!
本文代码和相关素材下载链接:https://pan.baidu.com/s/15A9CDB5ubJZ7aJRlWnwG_g?pwd=bgx5 提取码: bgx5



![写作历时一个月,长达8000字的年终总结——[2022年终总结]不要怕,请勇敢的向前走](https://img-blog.csdnimg.cn/img_convert/521792c93ed164bdb60b45bef8593c80.png)