
文章目录
- 常用的命令
- 开始爬虫
- 请求与响应
- 让控制台只输出想要的信息
- 创建一个py 文件来帮忙运行爬虫
- 工作原理图
- 实战
常用的命令
Scrapy是一个用于爬取网站数据的Python框架,以下是一些常用的Scrapy命令:
开始的时候 用 cd 进入你想创建scrapy 的文件夹 ,然后开始下面的操作
-
创建新的Scrapy项目:
scrapy startproject project_name这个命令会创建一个新的Scrapy项目,其中
project_name是你为项目指定的名称。 -
创建一个新的Spider:
scrapy genspider spider_name website_url这个命令会生成一个新的Spider文件,你需要提供
spider_name作为Spider的名称和website_url作为爬取的起始网址。 -
运行Spider:
scrapy crawl spider_name这个命令会启动指定的Spider,开始爬取数据。你需要将
spider_name替换为你要运行的Spider的名称。 -
导出爬取数据为JSON文件:
scrapy crawl spider_name -o output.json这个命令会运行Spider并将爬取的数据导出为一个JSON文件。你可以将
output.json替换为你想要的输出文件名和格式。 -
导出爬取数据为CSV文件:
scrapy crawl spider_name -o output.csv这个命令与上面的命令类似,不过它将数据导出为CSV格式。
-
查看可用的Spider:
scrapy list这个命令会列出项目中所有可用的Spider,你可以选择其中一个来运行。
-
检查Spider的数据爬取情况:
scrapy crawl spider_name --loglevel=INFO这个命令会以INFO级别的日志显示Spider的爬取情况,有助于调试和监视爬取过程。
-
检查Spider的爬取速度和性能:
scrapy crawl spider_name --profile=output.cprofile这个命令会生成性能分析文件,你可以使用工具来分析Spider的性能瓶颈。
开始爬虫
请求与响应
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example" #爬虫的名字(唯一)
allowed_domains = ["ssr1.scrape.center"] # 限定的域名,可选
start_urls = ["https://ssr1.scrape.center/"] #当前的域名
def parse(self, response):
# 当在命令行运行scrapy crawl example 之后会发送请求,得到一个响应对象responce
print(response.text)
print(response.status)
pass
让控制台只输出想要的信息
在你的settings 文件中加入
LOG_FILE = "爬虫名字.log"
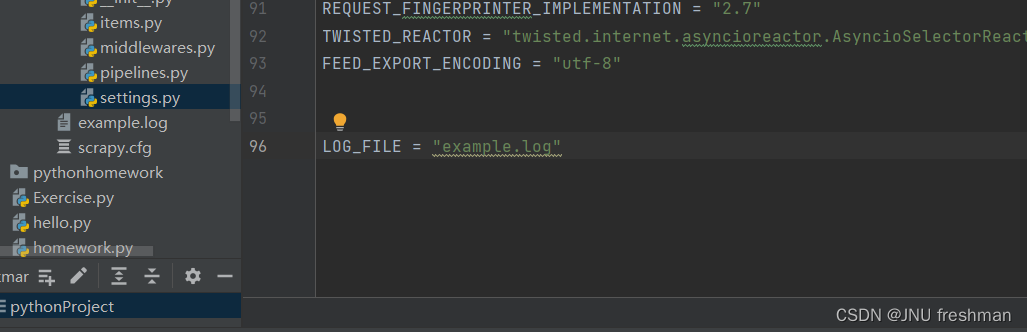
这样,那些日志就只会存储在日志文件中,而不是在控制台中
创建一个py 文件来帮忙运行爬虫
在你的爬虫项目里创建一个py 文件
在你的run 文件中
from scrapy.cmdline import execute
execute(["scrapy","crawl","example"])
# 对应于你的运行scrapy crawl example
#这样你就可以直接运行run 文件来实现你的结果了
工作原理图
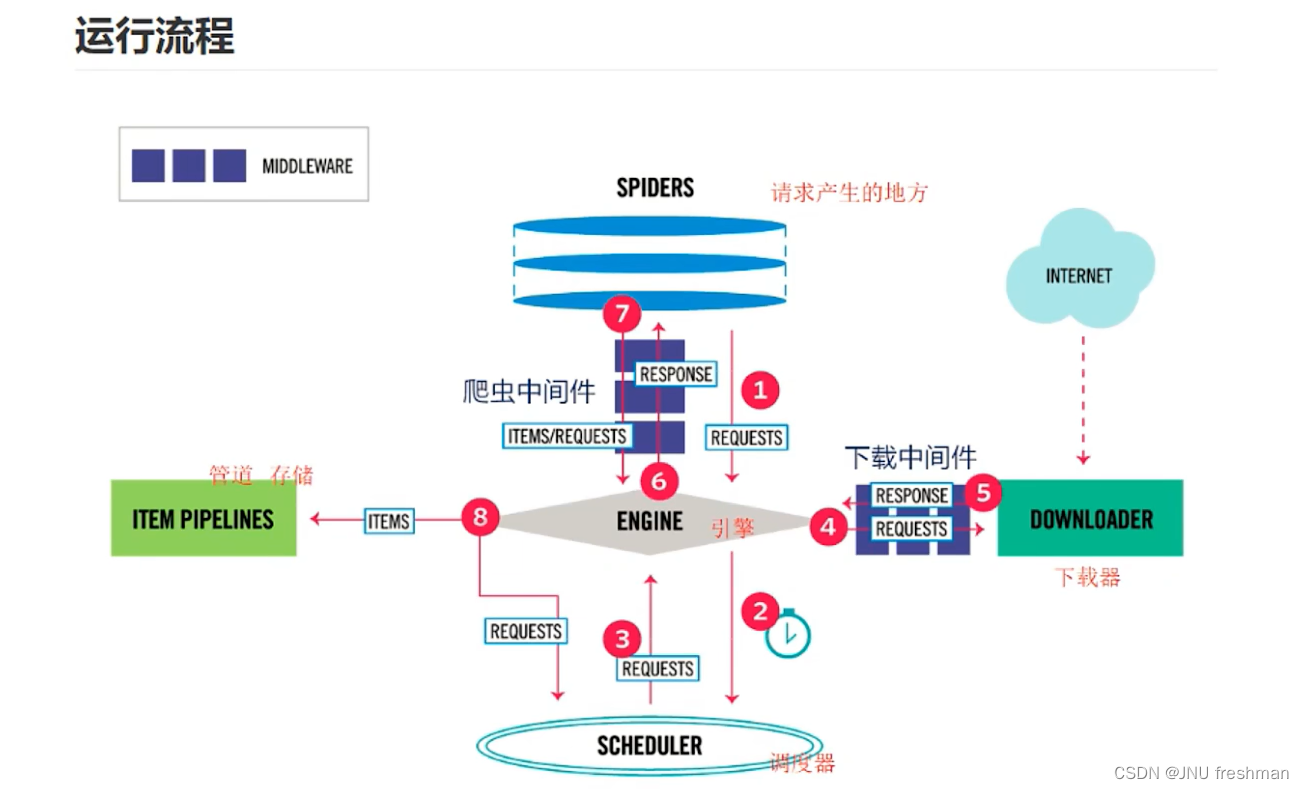
实战
网站https://ssr1.scrape.center/爬取电影名

import scrapy
from lxml import etree
class ExampleSpider(scrapy.Spider):
name = "example" #爬虫名字
allowed_domains = ["ssr1.scrape.center"] #限定的域名(可选)
start_urls = ["https://ssr1.scrape.center/"]# 起始的域名
def parse(self, response):
html = etree.HTML(response.text)#对返回的html 文本进行解析
allname = html.xpath(r'//h2[@class="m-b-sm"]/text()')# 寻找电影名字
print(allname)
pass
效果:





![[蓝桥杯 2019 省 B] 特别数的和-C语言的解法](https://img-blog.csdnimg.cn/65eed59a4f1044378c95f3d03e7d3cd1.png)

![[论文阅读]Generalized Attention——空间注意力机制](https://img-blog.csdnimg.cn/direct/07f66202a6d842c5b395748444d84719.png)