目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十七、安装Spark2
1.安装
添加Spark2服务
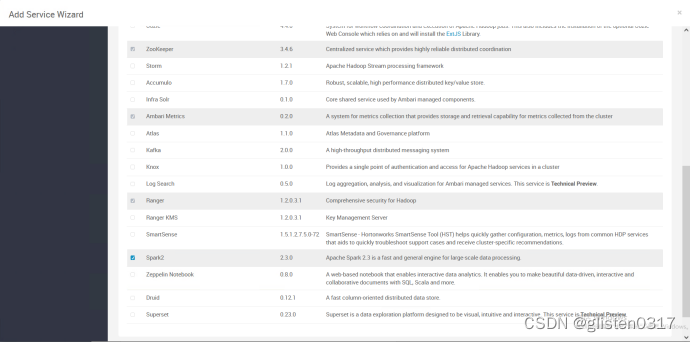
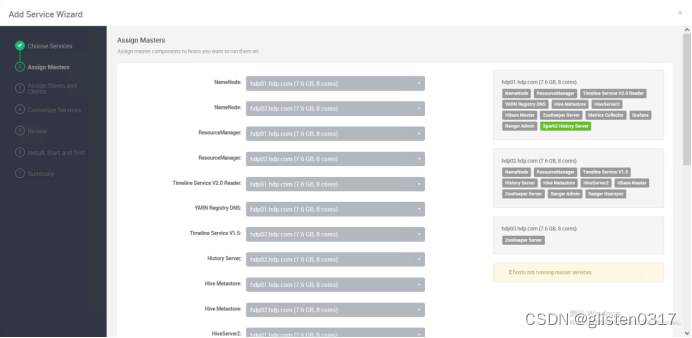
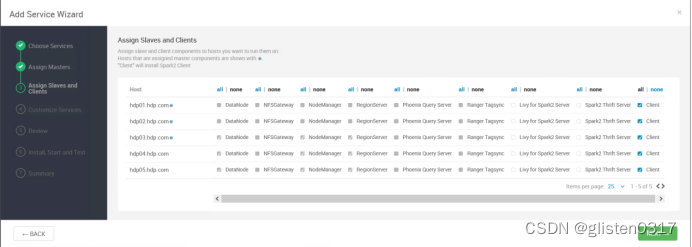
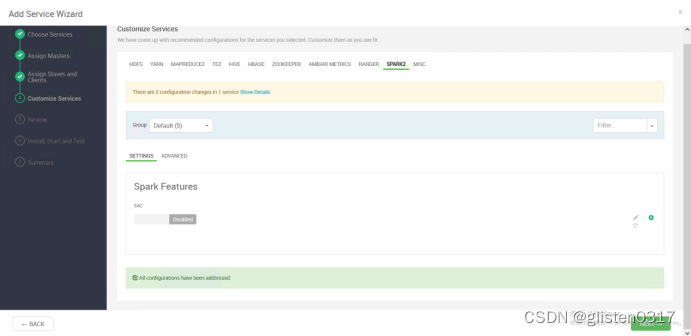
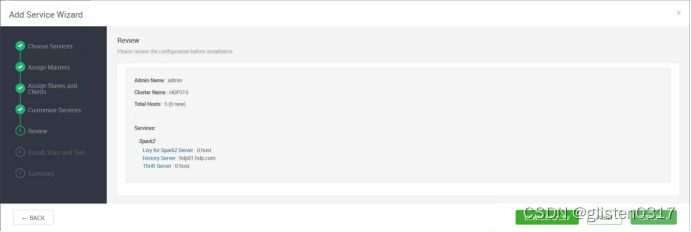
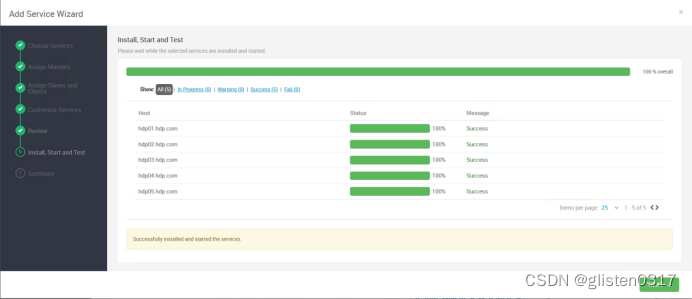
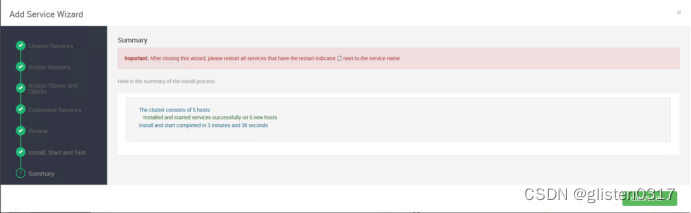
需要重启HDFS、YARN、MapReduce2、Hive、HBase等相关服务
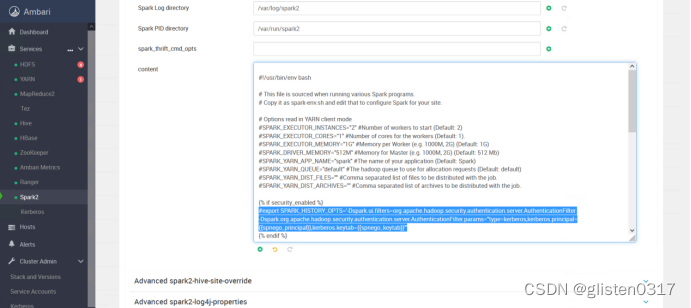
2.取消kerberos对页面的认证
在CONFIGS->Advanced spark2-env下的content里,将下面内容加#注释掉
export SPARK_HISTORY_OPTS='-Dspark.ui.filters=org.apache.hadoop.security.authentication.server.AuthenticationFilter -Dspark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.params="type=kerberos,kerberos.principal={{spnego_principal}},kerberos.keytab={{spnego_keytab}}"'
访问页面,http://hdp01.hdp.com:18081/
3.确认Spark on Yarn配置
查看/usr/hdp/3.1.5.0-152/spark2/conf/spark-env.sh
export HADOOP_HOME=${HADOOP_HOME:-/usr/hdp/3.1.5.0-152/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/usr/hdp/3.1.5.0-152/hadoop/conf}
/usr/hdp/3.1.5.0-152/hadoop-yarn/conf/yarn-site.xml
4.spark-shell交互式命令
每个Spark应用程序都需要一个Spark环境,这是Spark RDD API的主要入口点。Spark Shell提供了一个名为“sc”的预配置Spark环境和一个名为“spark”的预配置Spark会话。使用Spark Shell的时候,本身是预配置了sc,即SparkConf和SparkContext的,但是在实际使用编辑器编程过程中是需要设置这些配置的。
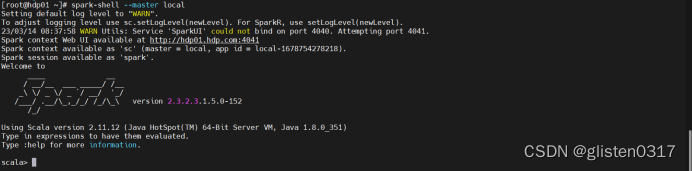
(1)启动
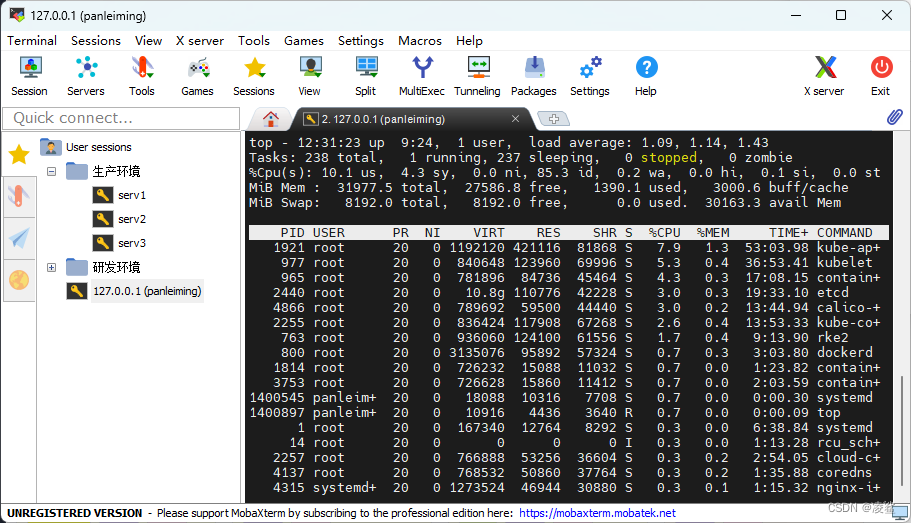
启动spark-shell
spark-shell --master local
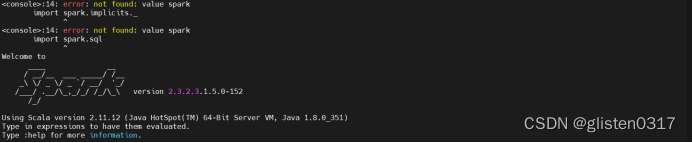
正确界面如下:
(2)加载本地文件
通过预置sc加载本地文件
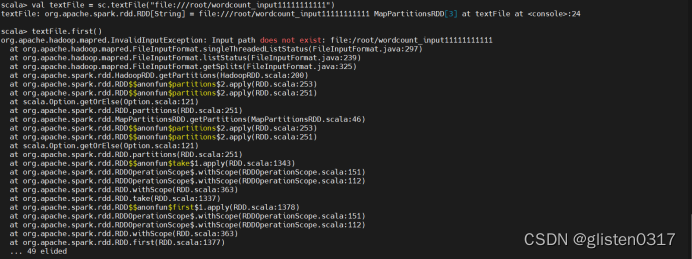
val textFile = sc.textFile("file:///root/wordcount_input")
val后面的是变量textFile,而sc.textFile()中的这个textFile是sc的一个方法名称,这个方法用来加载文件数据。这两个textFile不是一个东西,不要混淆。实际上,val后面的是变量textFile。
要加载本地文件,必须采用“file:///”开头的这种格式。执行上上面这条命令以后,并不会马上显示结果,因为,Spark采用惰性机制,只有遇到“行动”类型的操作,才会从头到尾执行所有操作。
textFile.first()
first()是一个“行动”(Action)类型的操作,会启动真正的计算过程,从文件中加载数据到变量textFile中,并取出第一行文本。屏幕上会显示很多反馈信息,这里不再给出,你可以从这些结果信息中,找到word.txt文件中的第一行的内容。

正因为Spark采用了惰性机制,在执行转换操作的时候,即使我们输入了错误的语句,spark-shell也不会马上报错,而是等到执行“行动”类型的语句时启动真正的计算,那个时候“转换”操作语句中的错误就会显示出来。
(3)变量回写到本地文件
将变量中的内容写回到本地文件/root/output中
val textFile = sc.textFile("file:///root/wordcount_input")
textFile.saveAsTextFile("file:///root/output")
上面的saveAsTextFile()括号里面的参数是保存文件的路径,不是文件名。saveAsTextFile()是一个“行动”(Action)类型的操作,所以,马上会执行真正的计算过程,从wordcount_input中加载数据到变量textFile中,然后,又把textFile中的数据写回到本地文件目录“/root/output”下面
ll /root/output/
cat /root/output/part-00000

(4)加载HDFS中文件
与加载本地文件类似
val textFile = sc.textFile("hdfs://hdp315/testhdfs/tenant1/wordcount_input")
textFile.first()

实验:Spark SQL-词频统计
(1)spark-shell方式
待统计文件为/root/wordcount_input
spark-shell --master local
val textFile = sc.textFile("file:///root/wordcount_input")
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).ruduceByKey((a,b) => a + b)
wordCount.collect()

textFile包含了多行文本内容,textFile.flatMap(line => line.split(" “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line => line.split(” “)。line => line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” "),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
然后,针对这个大的单词集合,执行map()操作,也就是map(word => (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word => (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey((a, b) => a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:(a, b) => a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
(2)spark-submit方式
建议找一台有外网的服务器来做sbt,因为需要下载很多依赖包
安装sbt
tar -zxvf /opt/sbt-1.8.2.tgz -C /usr/local/
将位于sbt/bin下面的sbt-launch.jar文件放在sbt目录下。
cp /usr/local/sbt/bin/sbt-launch.jar /usr/local/sbt/
在sbt目录下创建sbt脚本
chmod u+x /usr/local/sbt/sbt
确认是否成功
/usr/local/sbt/sbt sbtVersion

创建工程目录及相关文件

scala文件,/data01/project/wordcount/src/main/scala/wordcount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "hdfs://hdp315/testhdfs/ranger_yarn/wordcount_input"
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
sbt文件,/data01/project/wordcount/wordcount.sbt
name := "WordCount Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
进入到工程目录下,将整个工程打成jar包
/usr/local/sbt/sbt package

jar包在工程目录下的./target/scala-2.11/下

回到hdp01上,通过spark-submit提交jar包执行
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
spark-submit --class "WordCount" /root/wordcount-project_2.11-1.0.jar --deploy-mode cluster --master yarn
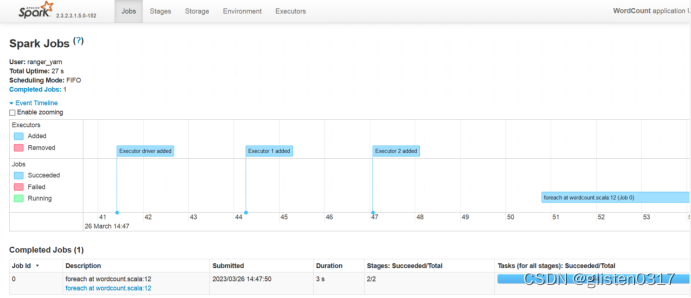
查看结果
在spark中可以查看任务信息,已经结果
6.实验:Spark Streaming-显示实时流内容
将nc作为服务器端,用户产生数据;启动sparkstreaming客户端程序,监听服务器端发送过来的数据,并对其数据进行显示。
在测试的nc服务端,启动nc程序,端口为1234
nc -l 1234
配置sbt文件,增加sparking-streaming依赖包,/data01/project/streamPrint/streamPrint.sbt
name := "streamPrint Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.3.0",
"org.apache.spark" %% "spark-streaming" % "2.3.0"
)
配置scala文件,/data01/project/streamPrint/src/main/scala/streamPrint.scala
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object StreamPrint {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("streamPrint")
val sc = new StreamingContext(conf, Seconds(5))
val lines = sc.socketTextStream("192.168.111.1", 1234, StorageLevel.MEMORY_AND_DISK)
if (lines != null) {
lines.print()
println("start!")
}
sc.start()
sc.awaitTermination()
}
}
进入到工程目录下,将整个工程打成jar包
/usr/local/sbt/sbt package
回到hdp01上,通过spark-submit提交jar包执行
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
spark-submit --class "StreamPrint" /root/streamprint-project_2.11-1.0.jar --deploy-mode cluster --master yarn
此时在nc服务端输入内容后,可在spark streaming中看到相应的内容

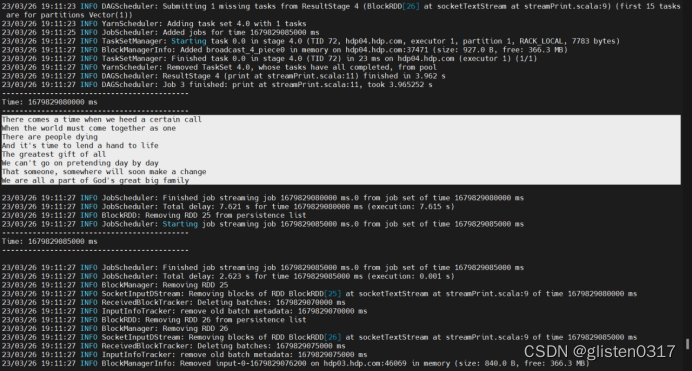
Spark streaming中的间隔,是在scala程序中设置的,val sc = new StreamingContext(conf, Seconds(5))因此是5秒输出一次。
7.spark-submit参数
–master
master的地址,提交任务到哪里执行
常见的选项有
local:提交到本地服务器执行,并分配单个线程
local[k]:提交到本地服务器执行,并分配k个线程
spark://HOST:PORT:提交到standalone模式部署的spark集群中,并指定主节点的IP与端口
mesos://HOST:PORT:提交到mesos模式部署的集群中,并指定主节点的IP与端口
yarn:提交到yarn模式部署的集群中
–deploy-mode
在本地(client)启动driver或在cluster上启动,默认是client
DEPLOY_MODE:设置driver启动的位置,可选项如下,默认为client
client:在客户端上启动driver,这样逻辑运算在client上执行,任务执行在cluster上
cluster:逻辑运算与任务执行均在cluster上,cluster模式暂时不支持于Mesos集群或Python应用程序
–class
应用程序的主类,仅针对java或scala应用
CLASS_NAME:指定应用程序的类入口,即主类,仅针对java、scala程序,不作用于python程序
–name
应用程序的名称
–jars
用逗号分隔的本地jar包,设置后,jar包将包含在driver和executor的classpath下
–packages
包含在driver和executor的classpath中的jar的maven坐标
–exclude-packages
为了避免冲突,指定的参数–package中不包含的jars包
–repositories
远程repository
附加的远程资源库(包含jars包)等,可以通过maven坐标进行搜索
–py-files
PY_FILES:逗号隔开的的.zip、.egg、.py文件,这些文件会放置在PYTHONPATH下,该参数仅针对python应用程序
–files
FILES:逗号隔开的文件列表,这些文件将存放于每一个工作节点进程目录下
–conf PROP=VALUE
指定spark配置属性的值,格式为PROP=VALUE,例如–confspark.executor.extraJavaOptions=“-XX:MaxPermSize=256m”
–properties-file
指定需要额外加载的配置文件,用逗号分隔,如果不指定,默认为conf/spark-defaults.conf
–driver-memory
Driver内存,默认1G
–driver-java-options
传给driver的额外的Java选项
–driver-library-path
传给driver的额外的库路径
–driver-class-path
传给driver的额外的类路径,用–jars添加的jar包会自动包含在类路径里
–driver-cores
Driver的核数,默认是1。在yarn或者standalone下使用
–executor-memory
每个executor的内存,默认是1G
–total-executor-cores
所有executor总共的核数。仅仅在mesos或者standalone下使用
–num-executors
启动的executor数量。默认为2。在yarn下使用
–executor-core
每个executor的核数。在yarn或者standalone下使用