- 一、索引
- 1.1 概念
- 1.2 作用
- 1.3 讨论-如何提高查询的速度
- 合适的数据结构:
- 二叉搜索树
- AVL 树
- 红黑树
- 哈希表
- 以上数据结构的问题:
- N 叉搜索树
- B 树
- B+ 树
- 1.4 索引的使用场景
- 1.5 索引的使用
- 1.6 聚簇索引与非聚簇索引
- 聚簇索引
- 非聚簇索引
- 1.7 索引 - 小结
- 二、事务
- 2.1 为什么使用事务
- 2.2 事务的概念
- 2.3 事务的四个核心特性
一、索引
1.1 概念
索引是一种特殊的文件,包含对数据表中所有记录的引用指针。
可以对表中的一列或者多列创建索引,并且指定索引的类型,各类索引有各自的数据结构来实现。
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引的作用类似于书籍目录,可以用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大帮助。
1.3 讨论-如何提高查询的速度
MySQL 查找主要是 select.
select 的基本执行过程,遍历表,依次取出每个记录,根据 where 子句的条件,决定这个记录要保留还是过滤。
这样的遍历操作,本身是比较低效的(尤其是数据量很大的情况下).
MySQL 是把数据存储在硬盘上,取出每个记录(意味着都需要访问硬盘),相比之下,就更希望访问硬盘的次数能尽量少,才能节省资源。
现在的数据库,要想提高查找的速度,就需要一定的数据结构来辅助,数据库本质上也是基于数据结构来实现的~
合适的数据结构:
二叉搜索树
我们能最先想到的数据结构就是二叉搜索树。
二叉搜索树的特殊结构,让数据在树中的排序是有序的,这样要查找指定数据,就很快很方便。
例如:我们要查询 12,根节点与 12 相比,12 大就进入右子树。
与 15 相比,12 小就进入左子树,最后找到 12 这个元素所在的位置。
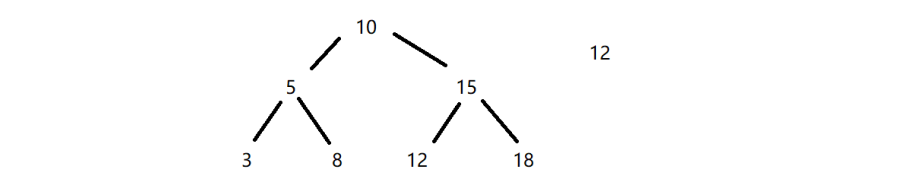
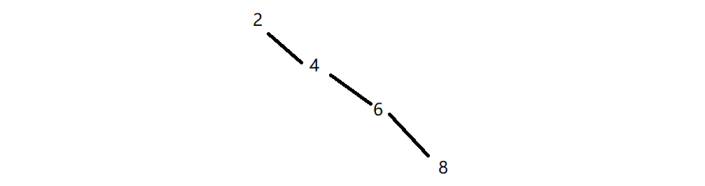
但这二叉搜索树的时间复杂度是 O(N)。因为,在最坏的情况下,二叉搜索树可能是一个单枝树。
AVL 树
为了进一步改进二叉搜索树,便引入了 AVL 树。
AVL 树本质上也是一个二叉平衡搜索树,为了防止出现单枝树,会有一个限定条件:| 左子树的高度 - 右子树的高度 | <= 1。从而保证了查找的效率~
但是!如果这样设定,意味着随着插入 / 删除元素的操作,这个 AVL 树的规则就可能被破坏掉,需要随时的检测和调整树的结构,保证整个树始终符合 AVL 树的规则。
调整操作很频繁,此时该树的插入删除操作就导致低效了。插入查找删除的时间复杂度为 O(logN).
红黑树
为了进一步改进 AVL 树,让插入删除查找能比较均衡,不至于插入删除太拉跨。
又引入了红黑树~
红黑树本质上是一个放松了规则的 AVL 树~也是要求让二叉搜索树平衡,但是没要求那么严格。
规则更加宽松,从而保证触发调整整个树的情况没有那么频繁~
虽然查找可能比 AVL 树逊色一筹,但是差异不大,还能保证插入和删除的效率更高。时间复杂度为 O(logN)。
哈希表
还有一个比较厉害的结构,哈希表~
能够做到插入查找删除的时间复杂度都是 O(1).
主要是借助了数组取下标的 “随机访问” 能力,把要保存的 key 转化为数组下标,保存到对应的数组位置上。
可是,哈希表有哈希冲突问题~
以上数据结构的问题:
以上的数据结构,做成索引来使用,是否可行?
哈希表可行又不太行,确实能大大提高查找的速度,但是还是有很大的局限性。
哈希表想要查询,有一个很关键的事情,就是必须要比较 “相等”。哈希查询的时候,只能查某个 key == 的具体值,SQL 中存在的其它查询 < <= > >= 操作不了。
那么红黑树 / AVL 树呢?
也不太行。
红黑树和 AVL 树查找效率直接由树的高度决定了,由于两个数都是 “二叉的”,当元素增加很多之后,高度也会随之增加不少。
N 叉搜索树
其实,MySQL 的索引中最常用的数据结构,就是一个 N 叉搜索树!
用 N 叉的目的就是能够减少高度,高度低了,此时查找的时候的比较次数就少了,磁盘 IO 少了,效率就提高了。
B 树
MySQL 中的索引,其中最常用的结构,就是 B+ 树(一种特殊的 N 叉搜索树)。
想要理解 B+ 树,还需要先了解 B 树(B 树是 B+ 树的前身,B+ 树就是改进版的 B 树)。
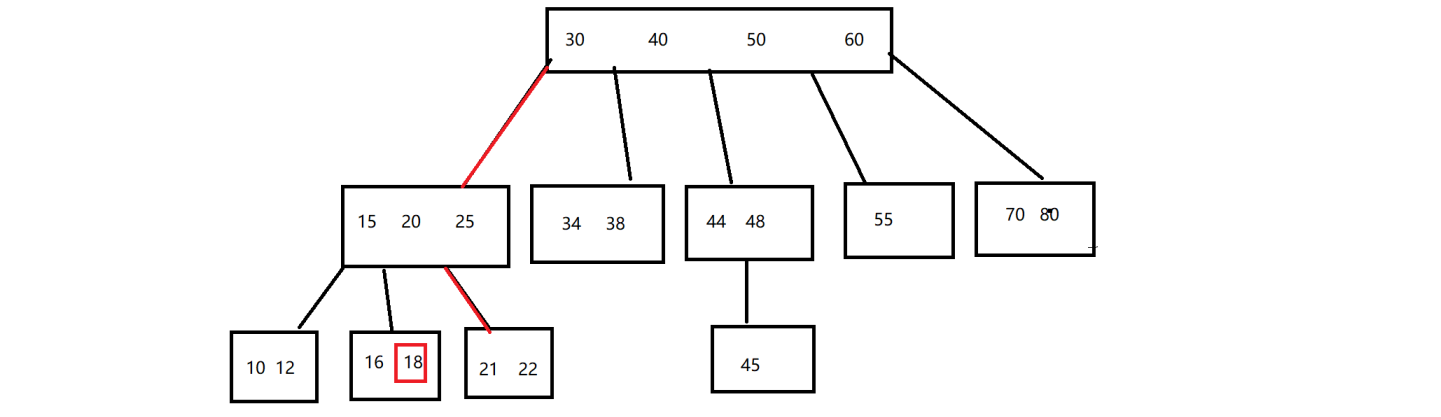
B 树的特点
- N 叉搜索树,每个节点可能包含 N 个子树。
- 每个节点上都存在多个值。
- 保证类似 “二叉搜索树” 一样的规则(左子树,小于根节点,小于右子树)。
B 树的使用
查询元素过程,例如找元素 22
- 先拿着 22 去和根节点中元素比较,发现 22 比 30 小,于是从最左侧第一个叉继续向下找。
- 再拿 22 去和 “15,20,25” 这个节点对比,此时 22 就在 20 和 25 之间,因此就从这个节点的第三个叉,继续向下走。
- 最后再拿 22 去和 “21 22” 这个节点进行比较,找到元素 22 的位置了。
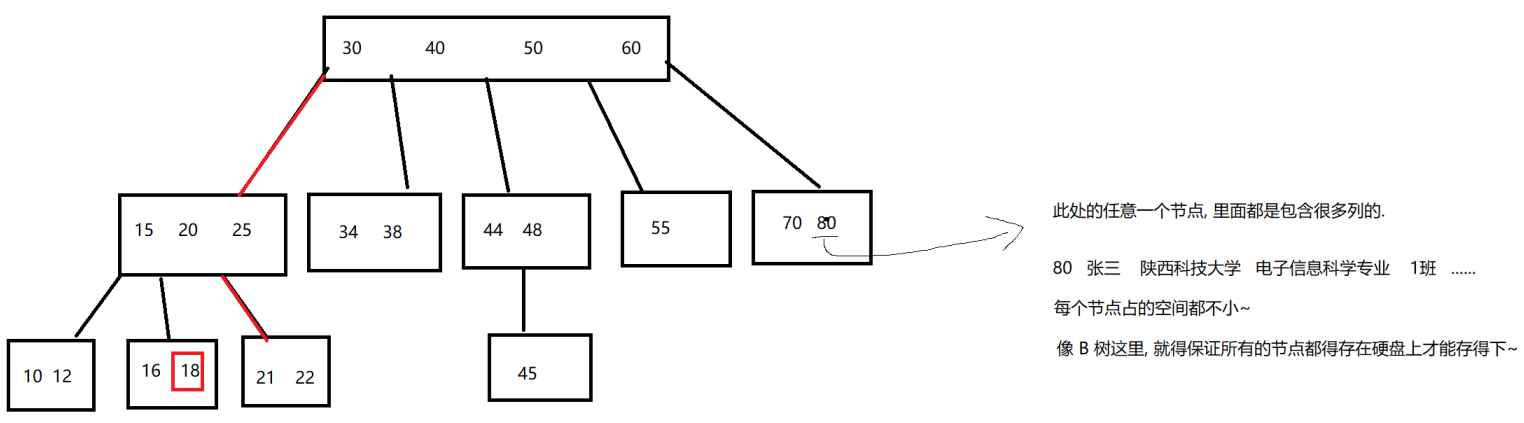
通过 B 树其实能够更好的完成查找过程了,但是还可以进一步改进~
接下来,B+ 树又进一步做出了改进~
B+ 树
B+ 树相比于 B 树,最明显的变化在于两个方面:
- 非叶子节点的值,可能会存在重复。就能保证最终的叶子节点这一层,就是完整的数据集合~(这是重复带来的好处)。
- 通过类似链表的方式,把所有叶子节点按照顺序连接了起来。
B+ 树的优势
- 非常擅长进行 “范围查找”,例如查一个 id<=11 and id>=6,拿着这两个边界值,分别去找这两个边界值的位置。
- 所有的查询最终都是落在叶子节点上,查询速度还是比较稳定的。
- 由于叶子节点是数据的全集,因此就可以把叶子节点存储在硬盘上,非叶子节点直接存储到内存中。进一步大大减低了读取硬盘的次数~~ (B+ 树的大杀器!)
1.4 索引的使用场景
要考虑对数据库表的某列或某几列建立索引,需要考虑以下几点:
- 数据量比较大,而且经常对这些列进行条件查询。
- 该数据库表的插入操作,对列的修改操作频率比较低。
- 索引会额外占用磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或者经常做插入、修改操作,或者磁盘空间不足时,就不考虑创建索引了。
1.5 索引的使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
查看索引
show index from 表名;
-- 查看学生表已有的索引
show index from student;
创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引。
语法:
create index 索引名 on 表名(字段名);
-- 创建班级表中,name 字段的索引
create index idx_classes_name on classes(name);
删除索引
语法:
drop index 索引名 on 表名;
-- 删除班级表中 name 字段的索引
drop index idx_classes_name on classes;
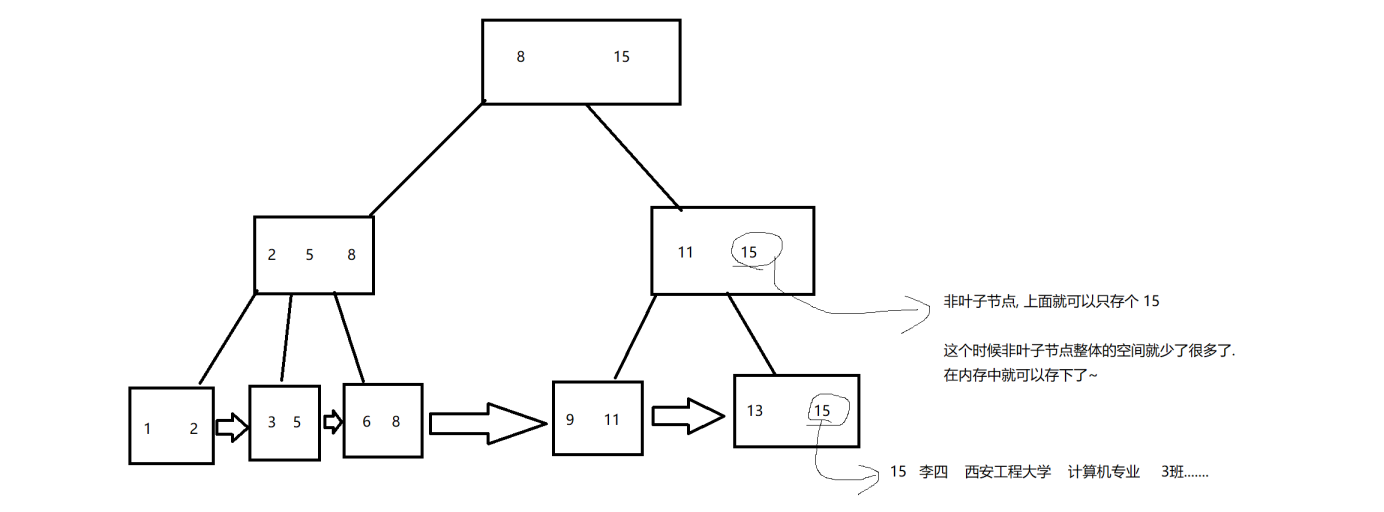
1.6 聚簇索引与非聚簇索引
聚簇索引
数据本身就是通过 B+ 树的方式来组织的。
每个叶子节点,都直接存在一条完整的记录~
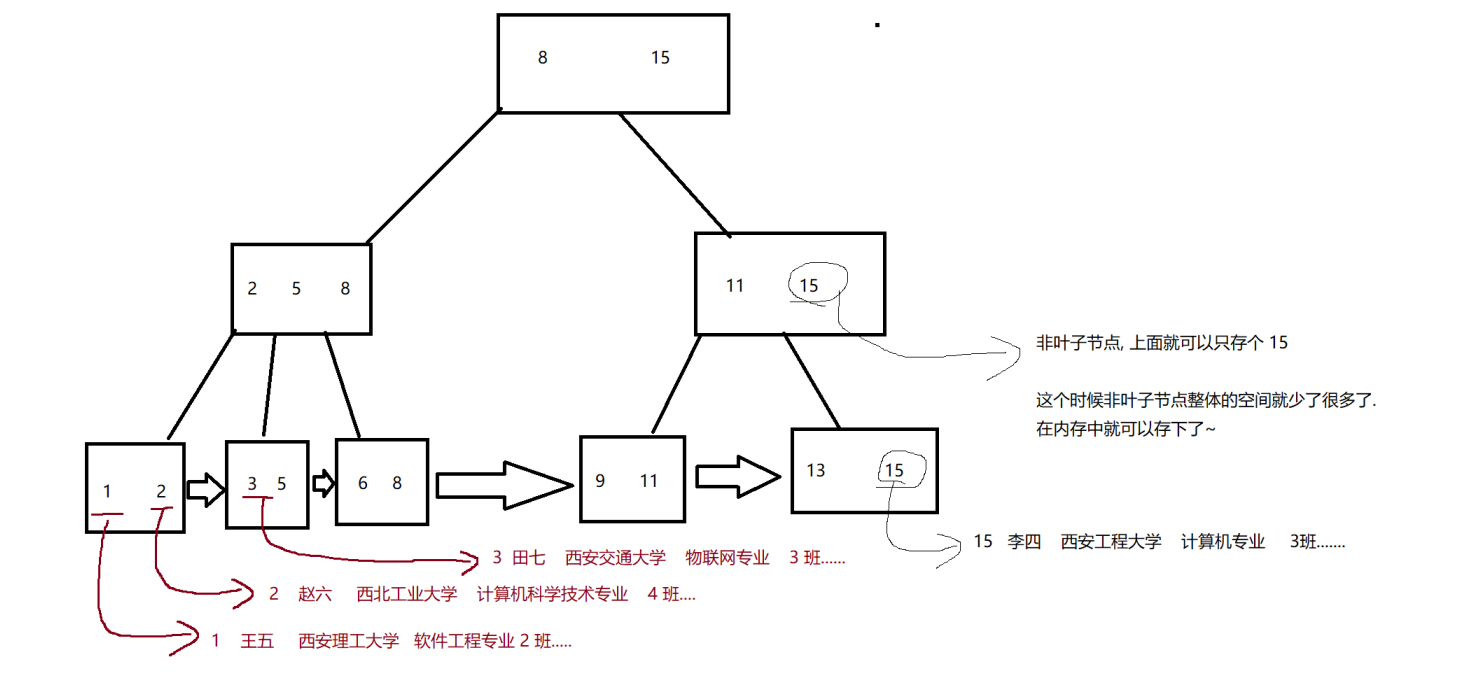
非聚簇索引
先通过一个 “表” 这样的结构,把所有数据都装进去。
再通过 “表” 的下标,和树的叶子节点一一对应。
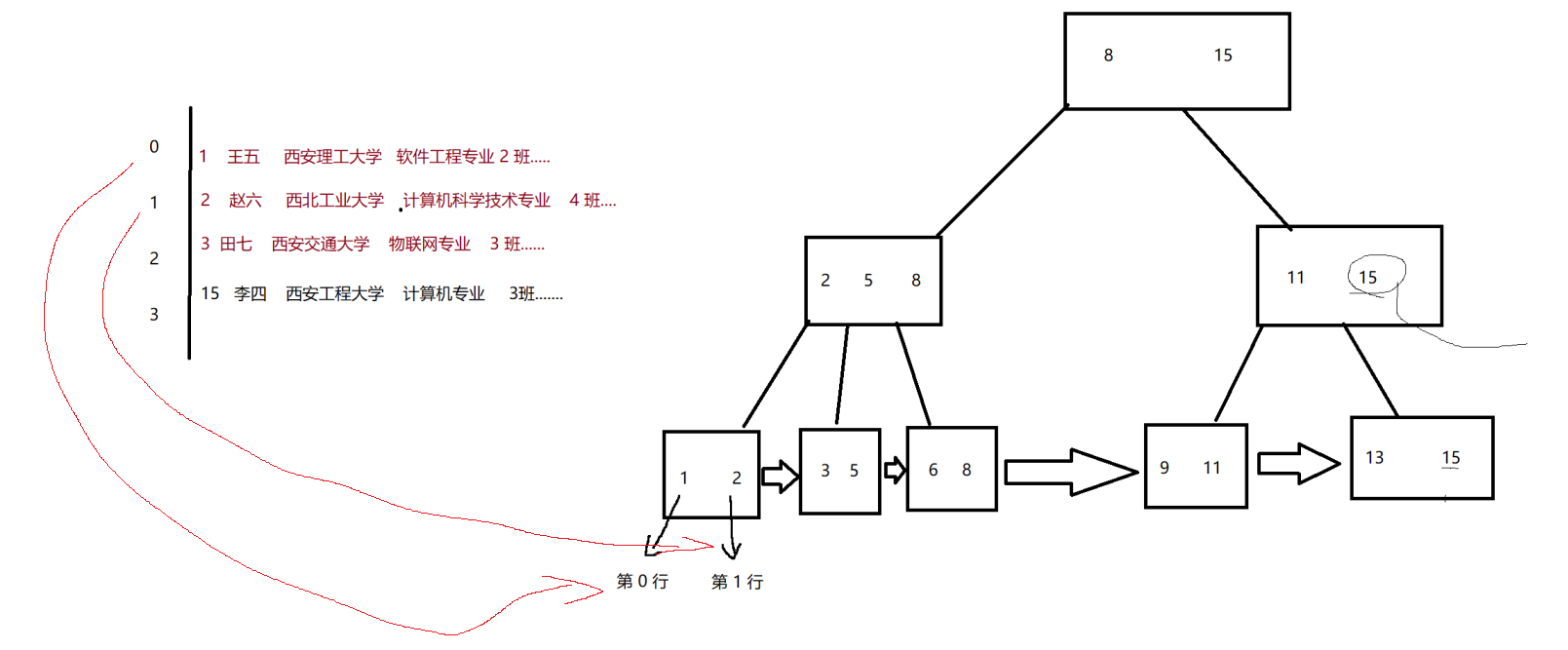
聚簇索引和非聚簇索引,也不能说谁好谁坏。
聚簇索引更高效~
非聚簇索引产生的硬盘碎片更少~
1.7 索引 - 小结
索引的结构最重要是 B+ 树,但也不是只有 B+ 树。
MySQL 支持多种不同的 “存储引擎”,不同的存储引擎,组织数据使用的数据结构都会存在差异,同时索引结构也会存在差异~
二、事务
2.1 为什么使用事务
准备测试表
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元。
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
假如在执行以上第一句 SQL 时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少 2000 ,但是四十大盗的账户上就没有了增加的金额。
解决方案:使用事务来控制,保证以上两句 SQL 要么全部执行成功,要么全部执行失败。
2.2 事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
事务最核心的特点,就是把一系列操作打包到一起~~构成一个整体。这个整体要么全部做完,要么就一个都不做。这也称为事务的原子性。
那么,事务要怎么保证原子性呢?
如果是全部做完那还好,但是做了的中间状态,事务会将此状态偷偷还原回去~(例如:转账500块钱,卡里已经扣钱了,但是钱没有到账;事务就会回滚,把卡里扣的钱再添加回去)。
2.3 事务的四个核心特性
事务除了原子性之外,还有其它特性~
称为事务的四个核心特性:
- 原子性
把一组操作打包在一起,要么全部做完,要么一件不做~ - 一致性
执行事务之前,和执行事务之后,表里的数据都是合理的状态~ - 持久性
事务操作的数据都是直接操作硬盘,硬盘的数据都是持久化存储的。 - 隔离性
多个事务,并发执行的时候,产生的相关问题可以隔离。