SparkStreaming读取Kafka数据源:使用Direct方式
一、前提工作
-
安装了zookeeper
-
安装了Kafka
-
实验环境:kafka + zookeeper + spark
-
实验流程
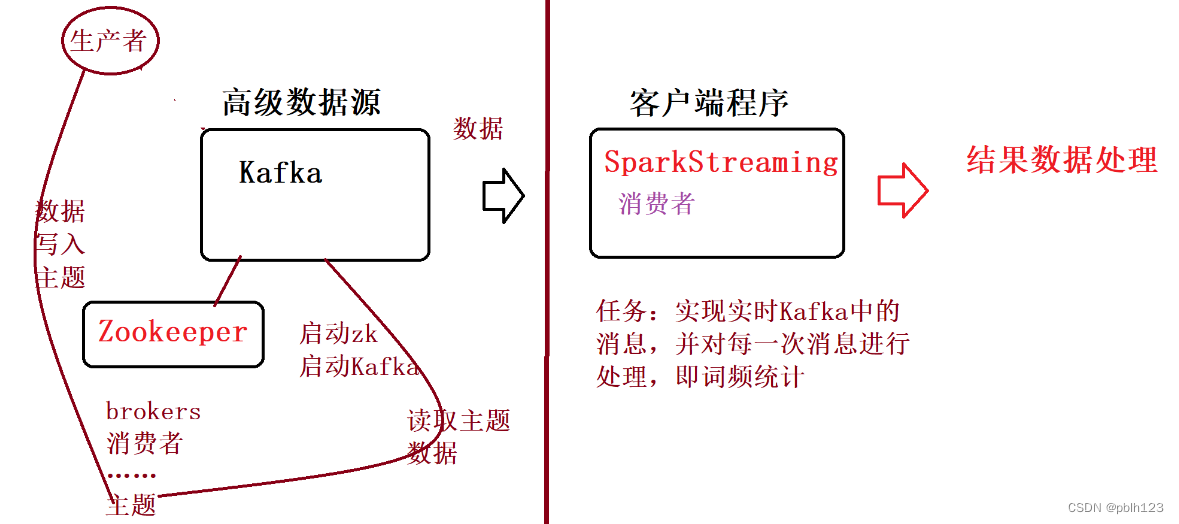
二、实验内容
实验要求:实现的从kafka读取实现wordcount程序
启动zookeeper
zk.sh start
# zk.sh脚本 参考教程 https://blog.csdn.net/pblh123/article/details/134730738?spm=1001.2014.3001.5502
启动Kafka
kf.sh start
# kf.sh 参照教程 https://blog.csdn.net/pblh123/article/details/134730738?spm=1001.2014.3001.5502

(测试用,实验不做)创建Kafka主题,如test,可参考:Kafka的安装与基本操作
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
--bootstrap-server 连接的Kafka Broker主机名称和端口号
--create 创建主题
--describe 查看主题详细描述
# 创建kafka主题测试
/opt/module/kafka_2.12-3.0.0/bin/kafka-topics.sh --create --bootstrap-server hd1:9092 --replication-factor 3 --partitions 1 --topic gnutest2
# 再次查看first主题的详情
/opt/module/kafka_2.12-3.0.0/bin/kafka-topics.sh --bootstrap-server hd1:9092 --describe --topic gnutest2

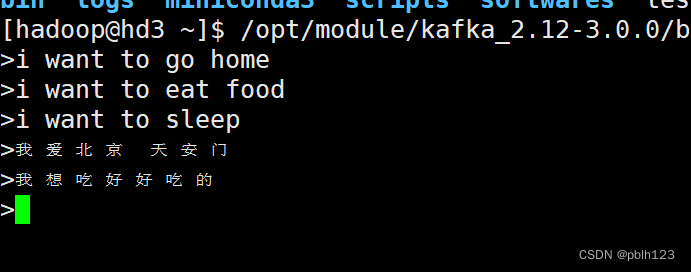
启动Kafka控制台生产者,可参考:Kafka的安装与基本操作
# 创建kafka生产者
/opt/module/kafka_2.12-3.0.0/bin/kafka-console-producer.sh --bootstrap-server hd1:9092 --topic gnutest2
创建maven项目
添加kafka依赖
<!--- 添加streaming依赖 --->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.13</artifactId>
<version>${spark.version}</version>
</dependency>
<!--- 添加streaming kafka依赖 --->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.13</artifactId>
<version>3.4.1</version>
</dependency>编写程序,如下所示:
package exams
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import java.lang
/**
* @projectName SparkLearning2023
* @package exams
* @className exams.SparkStreamingReadKafka
* @description ${description}
* @author pblh123
* @date 2023/12/1 15:19
* @version 1.0
*
*/
object SparkStreamingReadKafka {
def main(args: Array[String]): Unit = {
// 1. 创建spark,sc对象
if (args.length != 2) {
println("您需要输入一个参数")
System.exit(5)
}
val musrl: String = args(0)
val spark: SparkSession = new SparkSession.Builder()
.appName(s"${this.getClass.getSimpleName}")
.master(musrl)
.getOrCreate()
val sc: SparkContext = spark.sparkContext
// 生成streamingContext对象
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5))
// 2. 代码主体
val bststrapServers = args(1)
val kafkaParms: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> bststrapServers, //kafka列表
"key.deserializer" -> classOf[StringDeserializer], k和v 的序列化类型
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream", //消费者组
"auto.offset.reset" -> "latest", //如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读
"enable.auto.commit" -> (true: java.lang.Boolean) // 消费者不自动提交偏移量
)
val topics = Array("gnutest2", "t100")
// createDirectStream: 主动拉取数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParms)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
//kafka 是一个key value 格式的, 默认key 为null ,一般用不上
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
// 打印
resultRDD.print()
// 3. 关闭sc,spark对象
ssc.start()
ssc.awaitTermination()
ssc.stop()
sc.stop()
spark.stop()
}
}
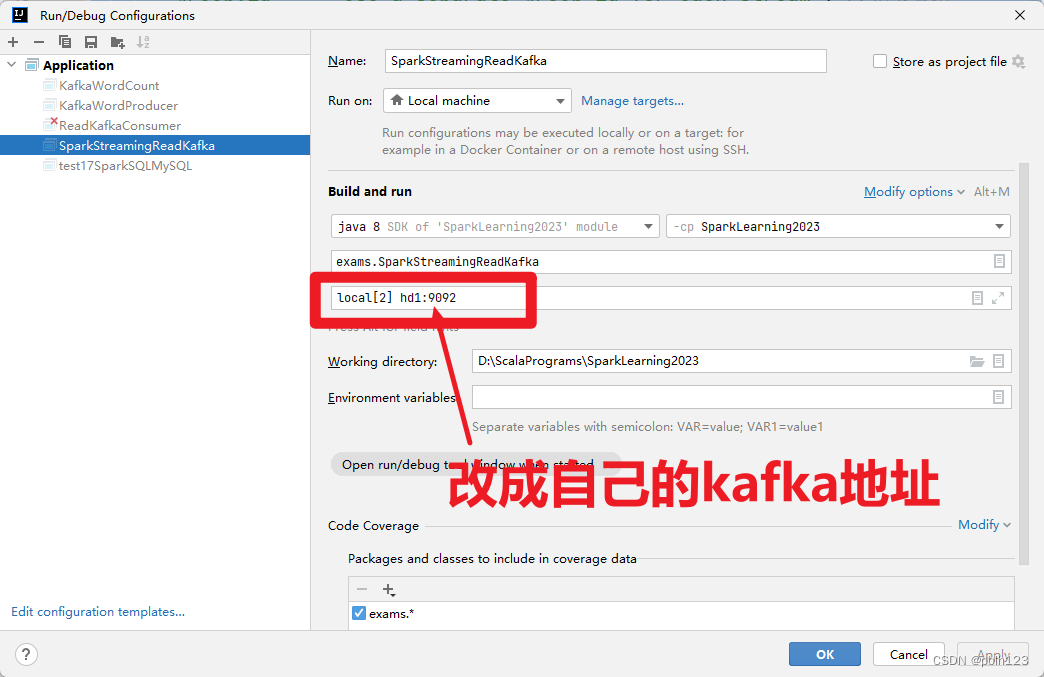
配置输入参数
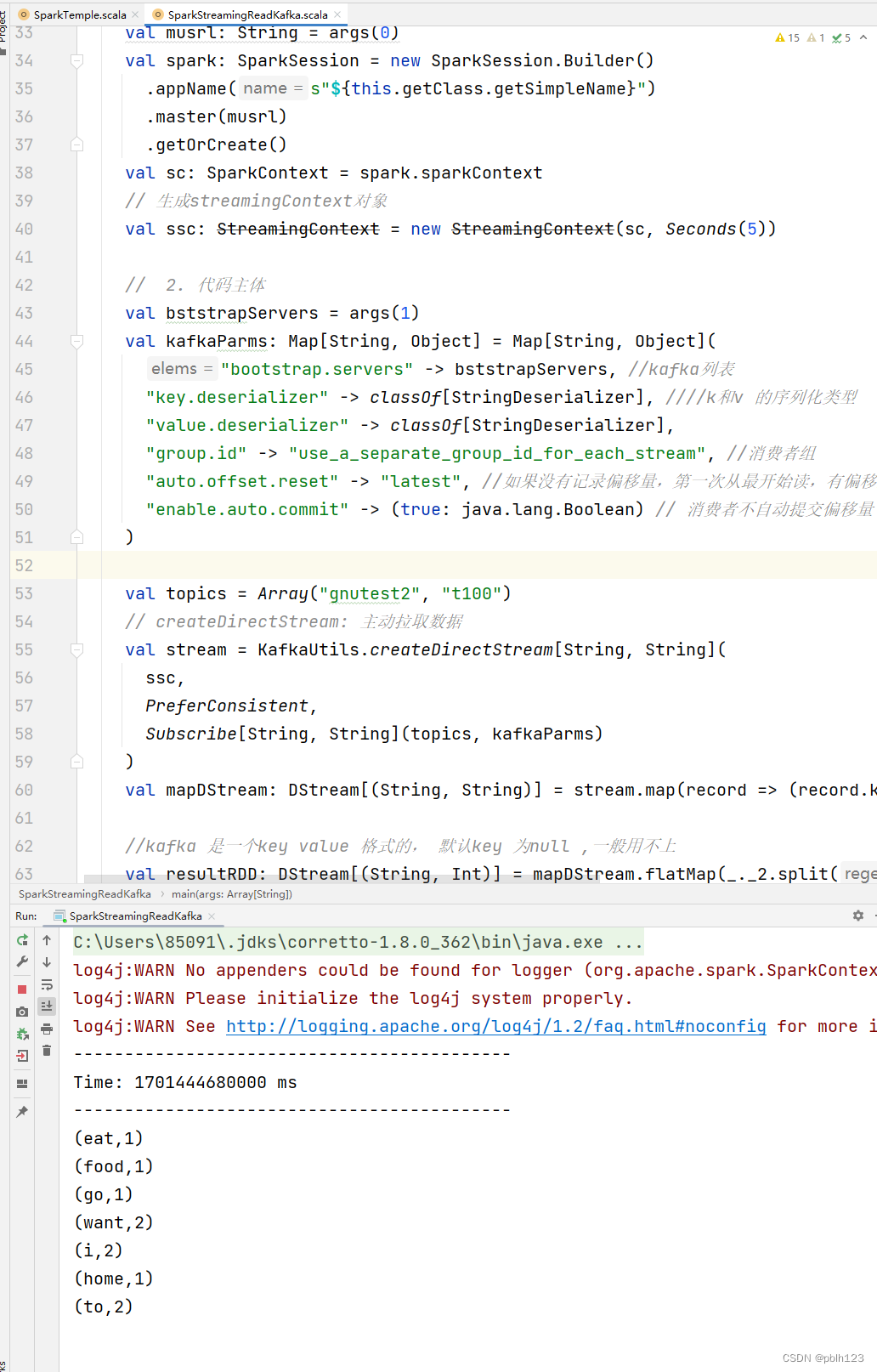
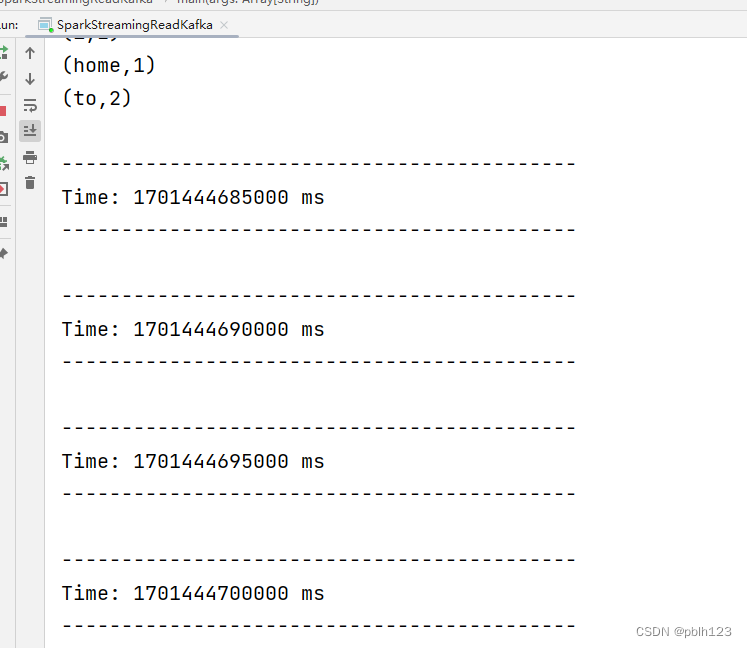
生产者追加数据