做毕业论文需要收集数据集,我的数据集就是文本的格式,而且是静态页面的形式,所以只是一个简单的入门。动态页面的爬虫提取这些比较进阶的内容,我暂时没有这样的需求,所以有这类问题的朋友们请移步。
如果只是简单的静态页面的信息爬取,我这篇文章的结构尽量做的清晰,并且把注释给打好,相信有点语法基础的都是能看懂的。
目录
- URL管理器
- Beautiful Soup4语法速成
- 创建Beautiful Soup4对象
- 搜索结点
- 访问结点信息
- 超简单爬虫案例
- 进阶——爬取所有博客页面
- 知识点掌握
- 实战
- 实践——爬取豆瓣电影Top250榜单
URL管理器
我们可能会爬取大量的URL,并且还可能对URL进行筛选,同时我们需要避免重复和循环爬取,所以对URL进行管理是重要的,具体的管理方式是这样的:
1、建立两个set数组,一个是new_urls存储未爬取的URL,一个是old_urls存储已爬取的URL;
2、如果一个网站是新的网站,那就存在new_urls中;
3、如果new_urls里的网站被爬取过了,那就在new_urls中删除这个网站,并且添加到old_urls中,利用new_urls与old_urls一起判断一个网站是否是一个新的网站。
在工程下面新建一个utils的包,并且将工具类直接封装在这个包下,代码如下:
# -- coding: utf-8 --
class UrlManager():
"""URL管理器"""
def __init__(self): # 初始化函数
# old_urls的来源就是new_urls,爬取完就把URL从new_urls中删除并添加到old_urls中
self.new_urls = set() # 定义未爬取的URL的集合
self.old_urls = set() # 定义已经爬取了的URL的集合
def add_new_url(self, url): # 增加新的URL
if url is None or len(url) == 0: # 判断URL是否合格
return
if url in self.new_urls or url in self.old_urls: # 判断是否出现过,不管是否是已经爬取了的,都不应该重复添加一个URL
return
self.new_urls.add(url) # 如果是新的URL,就增加到未爬取的set数组中去
def add_new_urls(self, urls): # 增加批量的URL
if urls is None or len(urls) == 0: # 同理,批量的URL不合法就return
return
for url in urls:
self.add_new_url(url)
def get_url(self): # 取出URL
if self.has_new_url(): # 若有未爬取的URL
url = self.new_urls.pop() # 将new_urls移除一个元素并且返回
self.old_urls.add(url) # 爬取就把这个URL放到old_urls中
return url
else:
return None
def has_new_url(self): # 判断是否有还未爬取的URL
return len(self.new_urls) > 0
if __name__ == "__main__": # 测试类
url_manager = UrlManager()
url_manager.add_new_url("url1")
url_manager.add_new_urls(["url1", "url2"])
print(url_manager.new_urls, url_manager.old_urls)
print("#" * 30)
new_url = url_manager.get_url()
print(url_manager.new_urls, url_manager.old_urls)
print("#" * 30)
new_url = url_manager.get_url()
print(url_manager.new_urls, url_manager.old_urls)
print("#" * 30)
print(url_manager.has_new_url())
Beautiful Soup4语法速成
Beautiful Soup4是比较便捷的,比起一堆乱七八糟的正则表达式,这里只需要掌握一下语法就能随便做爬虫了,大家可以看官方的帮助文档:
Beautiful Soup4帮助文档
我这边就总结一些常用的:
创建Beautiful Soup4对象
from bs4 import BeautifulSoup
# 根据HTML网页字符串创建BeautifulSoup对象
soup = BeautifulSoup(
html_doc, # HTML文档字符串
'html.parser', # HTML解析器,平时就用这个就行
from_encoding='utf8'# HTML文档的编码
)
搜索结点
# 查找所有标签为a的结点
soup.find_all('a')
# 查找所有标签为a,链接符合/view/123.html形式的结点
soup.find_add('a', href='view/123.html')
# 查找所有标签为div,class为abc,文字为python的结点
soup.find_all('div', class_='abc', string='Python') # 还可以根据id等信息查找对应标签,注意class后面有下划线,因为class是关键字
访问结点信息
# 假设得到了结点<a href='1.html'>Python</a>
# 标签名称
node.name
# a结点的href属性
node['href']
# a结点的链接文字
node.get_text()
超简单爬虫案例
网页代码右键+检查就能看了,学过web能看懂HTML代码就行。
流程很容易:
1、利用request获取网页内容
2、利用BeautifulSoup来解析内容
接下来我们利用爬虫来爬取静态的博客网站,这里就拿一些非主流网站,那些个主流网站应该都会拦截的,我没学那么复杂。
代码如下:
# -- coding: utf-8 --
import requests
from bs4 import BeautifulSoup
# 指定url为我的博客主页网址
url = "http://www.crazyant.net"
r = requests.get(url) # 利用requests获取url信息
if r.status_code != 200: # 状态值不为200则返回异常
raise Exception()
# 获取url文本内容
html_doc = r.text
# 创建Beautiful Soup4对象
soup = BeautifulSoup(html_doc, "html.parser")
# 找到所有的h2标签,所有的文章链接跳转都放在了h2下面,这一点自行打开网页源代码就能看见了
h2_nodes = soup.find_all("h2", class_="entry-title")
for h2_node in h2_nodes:
link = h2_node.find("a") # 查找标签名为a的所有标签
print(link["href"], link.get_text()) # 打印链接和标签名
运行结果:
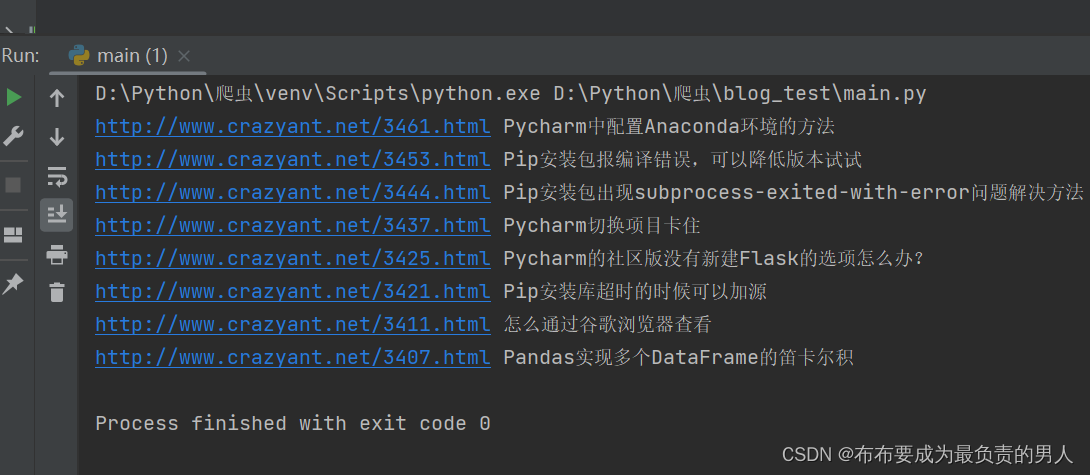
进阶——爬取所有博客页面
感觉这个学会了基本就学会了如何爬取一个静态页面了。
还是上个例子的网址:
根域名:http://www.crazyant.net
文章页URL形式:http://www.crazyant.net/2261.html
知识点掌握
首先掌握一些知识点:
1、requests请求时附带cookie字典
import requests
cookies = {...}
r = requests.get(
"http://url",
cookies=cookies
)
2、正则表达式实现模糊匹配:
import re # 正则表达式的包
url1 = "http://www.crazyant.net/123.html"
url2 = "http://www.crazyant.net/123.html#comments"
url3 = "http://www.baidu.com"
# 解析一下这个表达式
# 1、"^...$,那么结尾就必须得是.html的形式"
# 2、“\d”表示是数字,“\d+”表示是多个数字
pattern = r'^http://www.crazyant.net/\d+.html$'
print(re.match(pattern, url1)) # OK
print(re.match(pattern, url2)) # None
print(re.match(pattern, url3)) # None
实战
接下来进行实战
# -- coding: utf-8 --
import re
from utils import url_manager
import requests
from bs4 import BeautifulSoup
root_url = "http://www.crazyant.net"
urls = url_manager.UrlManager()
urls.add_new_url(root_url)
# 初始化文件对象,用于把结果写入文件中去,开启写入模式
fout = open("craw_all_pages.txt", "w", encoding="utf-8")
# 我们把跟URL添加以后,我们就可以进行爬取,并把新网址加入到new_urls中
while urls.has_new_url(): # 有未爬取的URL时为真
curr_url = urls.get_url()
# 获取网页内容,可能有很多网页,所以设置3秒反应时间
r = requests.get(curr_url, timeout=3)
if r.status_code != 200:
print("error, return status_code is not 200", curr_url)
continue
soup = BeautifulSoup(r.text, "html.parser") # 创建BeautifulSoup对象
title = soup.title.string # 获得title的值
fout.write("%s\t%s\n" % (curr_url, title)) # 将网址和title写入文件
fout.flush() # 将内存数据刷到磁盘里,这样能很快看到数据
print("success: %s, %s, %d" % (curr_url, title, len(urls.new_urls)))
links = soup.find_all("a") # 找到所有标签a内容
for link in links:
# 提取网址,并且与正则表达式进行匹配
href = link.get("href") # link["href"]有可能会错,因为有些超链接不标准,没有href
if href is None:
continue
pattern = r'^http://www.crazyant.net/\d+.html$'
if re.match(pattern, href):
urls.add_new_url(href) # 匹配那就写入
fout.close()
运行结果正常:
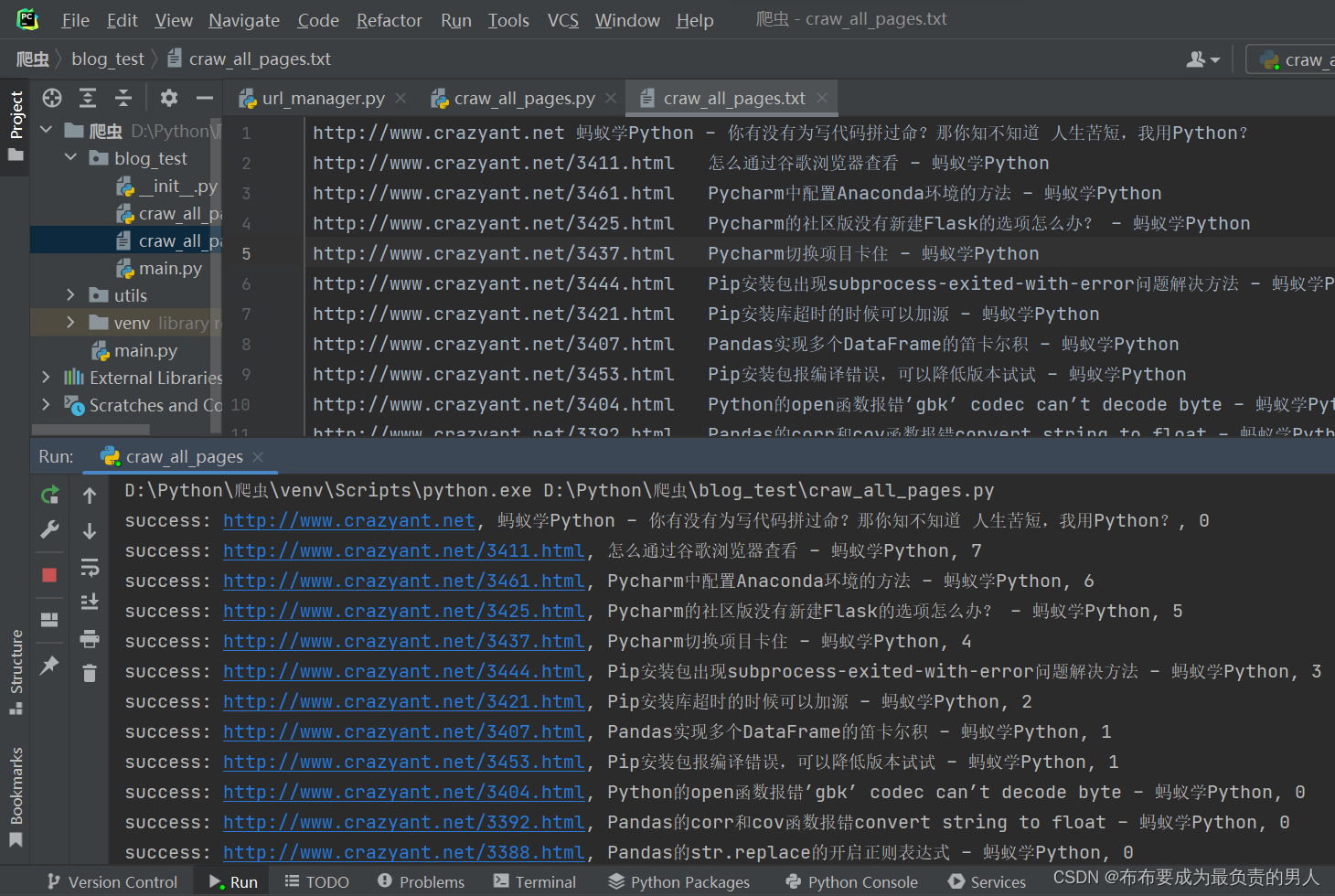
实践——爬取豆瓣电影Top250榜单
观察网站,10页,每页25个电影,我们要爬取10个页面的内容。
自行看一下网站的内容是怎样的,敲代码还是挺容易的。
# -- coding: utf-8 --
# 1、使用requests爬取网页
# 2、使用BeautifulSoup实现数据解析
# 3、借助pandas将数据写出到Excel
import requests
from bs4 import BeautifulSoup
import pprint
import pandas as pd
import json
# 下载共10个页面的HTML
page_indexs = range(0, 250, 25) # 每个页面都是25个电影,因此间隔25
# print(list(page_indexs)): [0, 25, 50,...,200, 225]
def download_all_htmls():
"""下载所有页面的HTML,用于后续分析"""
htmls = []
for idx in page_indexs:
url = f"https://movie.douban.com/top250?start={idx}&filter="
print("craw html:", url)
# 定义headers,绕开反爬机制
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
r = requests.get(url, headers=headers)
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
return htmls
# 执行爬取
htmls = download_all_htmls()
# 解析HTML得到数据
def parse_single_html(html):
"""解析单个HTML,得到数据,@return list({"link", "title", [label]})"""
soup = BeautifulSoup(html, 'html.parser') # 初始化对象
article_items = (
# 这里就自行观察一下网页的结构,就能定位到电影的位置
soup.find("div", class_="article")
.find("ol", class_="grid_view")
.find_all("div", class_="item") # 有多个,要find_all
)
datas = []
for article_item in article_items:
rank = article_item.find("div", class_="pic").find("em").get_text()
info = article_item.find("div", class_="info")
title = info.find("div", class_="hd").find("span", class_="title").get_text()
stars = (
info.find("div", class_="bd")
.find("div", class_="star")
.find_all("span") # 有多个,要find_all
)
rating_star = stars[0]["class"][0]
rating_num = stars[1].get_text()
comments = stars[3].get_text()
datas.append({
"rank": rank,
"title": title,
"rating_star": rating_star.replace("rating", "").replace("-t", ""),
"comments": comments.replace("人评价", "")
})
return datas
pprint.pprint(parse_single_html(htmls[0]))
# 执行所有的HTML页面的解析
all_datas = []
for html in htmls:
all_datas.extend(parse_single_html(html))
# print(all_datas)
# 将结果存入Excel
df = pd.DataFrame(all_datas)
df.to_excel("豆瓣电影TOP250.xlsx")
运行结果:
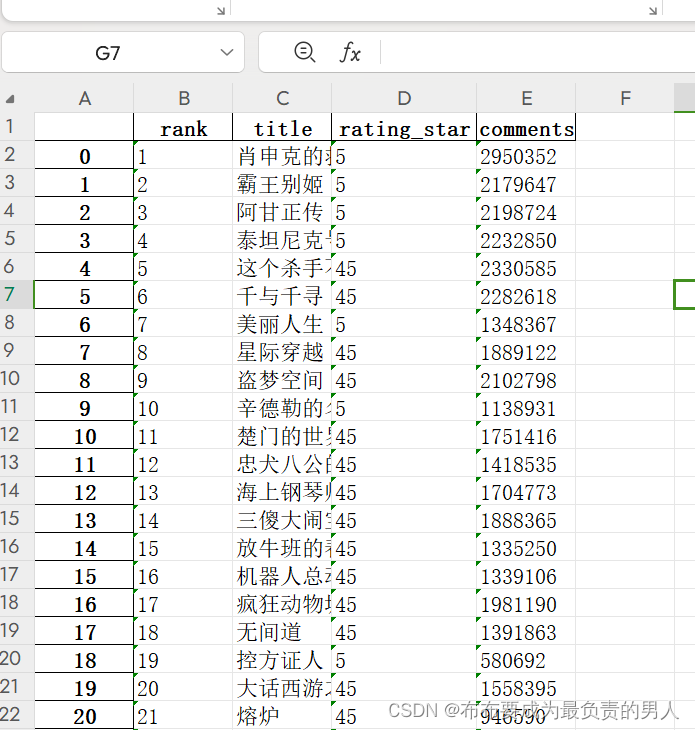
如果我们想要查询电影榜单中每个电影的一些信息,我们可以爬取到网址以后直接爬取每个电影的网址,然后再提取相关的一些信息,掌握上面的一些内容,剩下都是基本功了。