文章目录
- 前言
- 一、EF Core 模糊查询
- 二、MySql 日期模糊查询分析和优化
- 2.1 测试环境准备
- 2.1.1 创建数据库
- 2.1.2 查看测试数据
- 2.2 查询日期的运行效率对比
- 2.3 运行效率优化
- 三、EF Core 模糊查询优化
- 3.1 字符串转日期
- 3.2 使用日期格式查询
- 四、优化建议
- 总结
前言
在处理数据库查询时,特别是在涉及到模糊查询和日期字段时,我们常常面临一个挑战:如何在确保查询效率的同时,实现精确和灵活的数据检索?众所周知,直接转换数据库字段类型进行匹配往往会导致查询效率下降,甚至引发全表搜索的问题,这在处理大量数据时尤为明显。因此,找到一种既能保持数据库性能又能满足查询需求的方法显得尤为重要。
一、EF Core 模糊查询
在使用Entity Framework Core(EF Core)进行数据库操作时,模糊查询是一个常用而又复杂的功能。在EF Core中,进行模糊查询通常涉及到Contains方法的使用。然而,如果直接对非字符串字段应用ToString()然后进行比较,EF Core会将其解析为字符串匹配。这种做法虽然在某些场景下有效,但可能导致效率问题。以下是一个典型的例子:
expression = expression.And(p =>
// ... 其他条件
p.CreateTime.ToString().Contains(strlike)) ||
// ... 其他条件
p.PayStatus.Contains(strlike));
这段代码试图在多个字段上应用模糊匹配,包括将日期时间转换为字符串进行匹配。这种操作会在SQL级别产生如下查询:

WHERE (`e`.`id` = `e7`.`sale_order_id`) AND ((@__strLike_1 LIKE '') OR (LOCATE(@__strLike_1, CAST(`e8`.`create_time` AS char) COLLATE utf8mb4_bin) > 0)))
这样做是非常不可取的做法,需要接受严厉的批评!
二、MySql 日期模糊查询分析和优化
2.1 测试环境准备
我用到的是MySql数据库,Mysql Workbench可视化桌面软件。
2.1.1 创建数据库
-- 检查并删除已存在的数据库
DROP DATABASE IF EXISTS `date_time_test`;
-- 创建数据库
CREATE DATABASE `date_time_test`;
-- 使用新创建的数据库
USE `date_time_test`;
-- 检查并删除已存在的表
DROP TABLE IF EXISTS sales_orders;
-- 创建表
CREATE TABLE sales_orders (
id INT AUTO_INCREMENT PRIMARY KEY,
create_time DATETIME,
order_no VARCHAR(50)
);
-- 定义分隔符
DELIMITER $$
-- 创建插入数据的存储过程
CREATE PROCEDURE InsertTestData()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION; -- 开始事务
WHILE i <= 1000000 DO
INSERT INTO sales_orders (create_time, order_no)
VALUES (NOW() - INTERVAL FLOOR(RAND() * 365) DAY, CONCAT('Order_', LPAD(i, 8, '0')));
IF i % 10000 = 0 THEN -- 每10000条数据提交一次事务
COMMIT;
START TRANSACTION;
END IF;
SET i = i + 1;
END WHILE;
COMMIT; -- 最后提交剩余的事务
END$$
-- 恢复默认分隔符
DELIMITER ;
-- 调用存储过程以生成数据
CALL InsertTestData();
2.1.2 查看测试数据
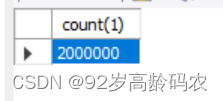
我这里运行了两次存储过程,因此生成了2百万的随机数据。
select count(1) from sales_orders
2.2 查询日期的运行效率对比
我们对比一下我能想到的几个写法:
SELECT count(1) FROM sales_orders
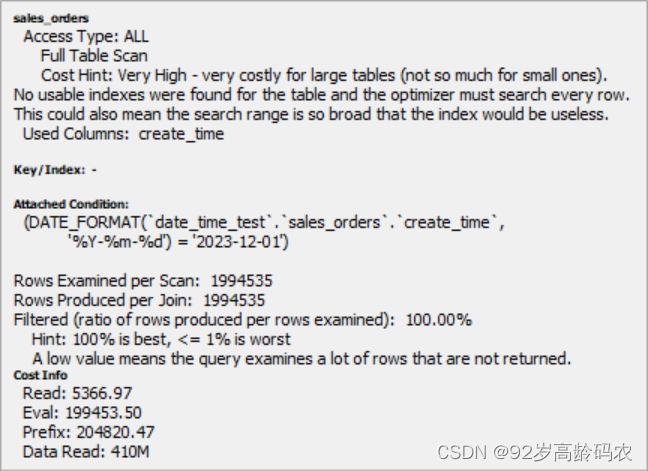
WHERE DATE_FORMAT(sales_orders.create_time, '%Y-%m-%d') = '2023-12-01';
SELECT count(1) FROM sales_orders
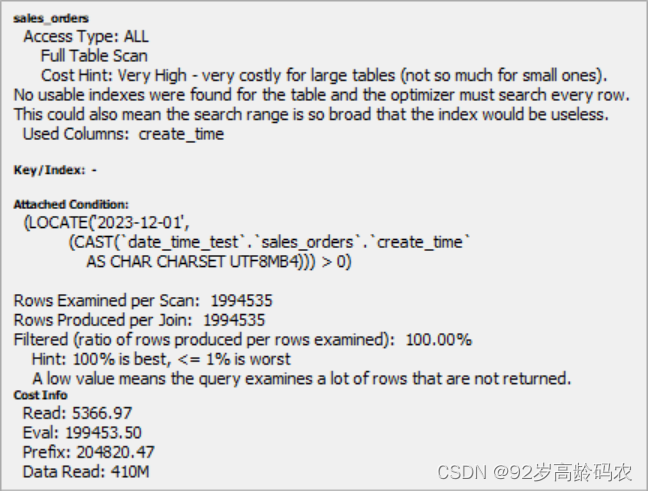
WHERE LOCATE('2023-12-01', CAST(sales_orders.create_time AS char) COLLATE utf8mb4_bin) > 0;
select count(1) from sales_orders
WHERE sales_orders.create_time >= '2023-12-01 00:00:00' and sales_orders.create_time < '2023-12-02 00:00:00';
-- 错误写法 这个只能查询到'2023-12-01 00:00:00'这个时间点的结果
select count(1) from sales_orders
WHERE sales_orders.create_time = '2023-12-01';

SELECT count(1) FROM sales_orders
WHERE DATE_FORMAT(sales_orders.create_time, '%Y-%m-%d') = '2023-12-01';
SELECT count(1) FROM sales_orders
WHERE LOCATE('2023-12-01', CAST(sales_orders.create_time AS char) COLLATE utf8mb4_bin) > 0;
select count(1) from sales_orders
WHERE sales_orders.create_time >= '2023-12-01 00:00:00' and sales_orders.create_time < '2023-12-02 00:00:00';
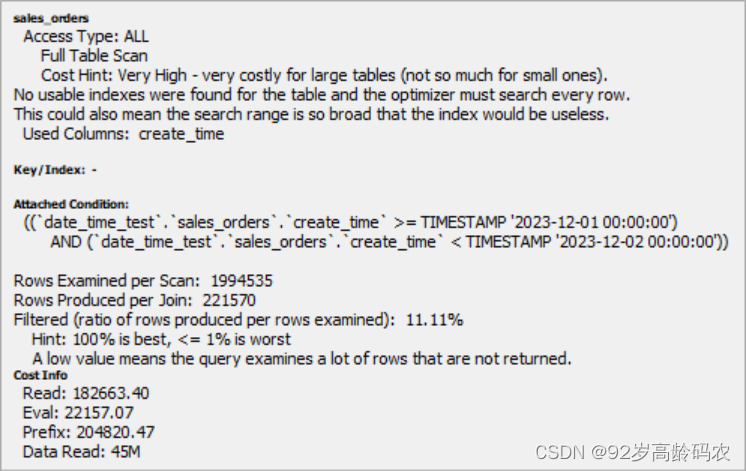
select count(1) from sales_orders
WHERE sales_orders.create_time = '2023-12-01';
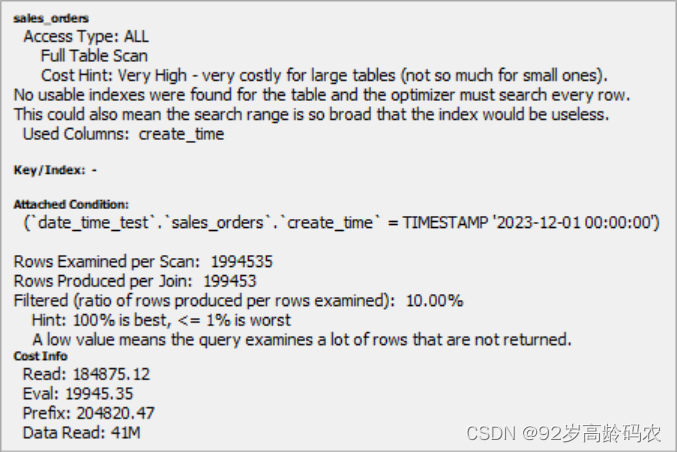
上面的截图是 MySQL 查询的 EXPLAIN 输出,用于显示 MySQL 如何执行特定的查询。我将解释输出中的一些关键部分:
Access Type: ALL
- 这意味着 MySQL 正在进行全表扫描,即它查看表中的每一行来找到匹配的行。这通常是最慢的访问类型,尤其是在处理大型表时。
Cost Hint: Very High
- 这表明查询的成本非常高。在 MySQL 中,成本是一个相对的度量,用于表示执行查询所需的工作量。
No usable indexes were found for the table
- MySQL 没有找到可用的索引来优化这个查询。如果没有索引,数据库就必须执行全表扫描,这是非常低效的。
Filtered: 100.00%
- 这个值表示查询条件过滤掉的数据百分比。在这种情况下,100% 表示没有行被过滤掉,或者说每一行都被检查了,这通常是因为查询条件没有排除任何行。这个值通常是指在表的全行中,有多少百分比的行是与查询条件相匹配的。在理想情况下(即查询非常有效地限制了结果集),这个百分比应该是较低的。
Rows Examined per Scan: 1994535
- 这表示每次扫描时检查了多少行。在这个查询中,几乎检查了两百万行,这是因为进行了全表扫描。
Hint: 100% is best, < 1% is worst
- 这个提示是关于
Filtered百分比。这个提示可能是指行的选择性。在这种特定情况下,因为查询没有过滤任何行(可能是由于查询条件的设计),所以解释器提示:实际上并没有行被排除在外。成本细节
Read: 读取数据的成本。Eval: 计算 WHERE 条件的成本。Prefix: 到达当前查询点的总成本。Data_Read: 每次连接操作读取的数据量。
2.3 运行效率优化
我们已经知道将搜索字符串转换目标数据类型,会提高查询效率。在这种情况下,查询慢的原因很可能是由于缺乏有效的索引。在 create_time 字段上创建一个索引可能会显著提高查询的性能,因为索引可以让数据库快速定位到那些匹配特定日期时间范围的行,而不必扫描整个表。
我们可以通过以下SQL语句创建一个:
CREATE INDEX idx_create_time ON sales_orders(create_time);


经过索引化后,查询效率提升非常明显。
三、EF Core 模糊查询优化
在前文中,我们探讨了如何在C#和MySQL中实现模糊搜索,特别是在涉及日期字段时的一些常见问题。我们发现,直接将日期字段转换为字符串进行查询是一种常见但效率低下的做法。现在,我们将专注于优化这种方法,以提高查询的效率和准确性。
3.1 字符串转日期
首先,我们将模糊搜索字段尝试转换为日期类型,如果转换成功,则进行日期模糊搜索;如果转换失败,则查询时不考虑搜索日期字段。
下面是我尝试转换的静态方法,允许输入单个日期或者日期范围。
/// <summary>
/// 尝试根据输入的字符串解析日期或日期范围。
/// 支持的格式包括单个日期(年、年月、年月日)和日期范围(年~年、年月~年月、年月日~年月日)。
/// </summary>
/// <param name="input">输入的日期字符串,可以是单个日期或日期范围。</param>
/// <param name="startDate">解析成功时,返回范围的起始日期。</param>
/// <param name="endDate">解析成功时,返回范围的结束日期。</param>
/// <returns>如果输入格式正确且能成功解析,则返回true;否则返回false。</returns>
/// <remarks>
/// - 单个日期的格式可以是 "yyyy", "yyyy-MM" 或 "yyyy-MM-dd"。
/// - 日期范围由两个这样的日期组成,以~字符分隔。
/// - 方法会根据输入格式确定日期范围:
/// - 年(如 "2023")的范围是该年的1月1日到次年1月1日。
/// - 年月(如 "2023-10")的范围是该月的1日到次月1日。
/// - 年月日(如 "2023-10-12")的范围是该日的0时到次日0时。
/// - 对于日期范围,起始和结束日期根据相同规则确定。
/// - 输入字符串中的日期部分可以包含或不包含前导零(例如 "2023-1-1" 或 "2023-01-01")。
/// </remarks>
public static bool TryParseDateInput(string input, out DateTime startDate, out DateTime endDate)
{
var formats = new[] { "yyyy-MM-dd", "yyyy-MM-d","yyyy-M-dd", "yyyy-M-d",
"yyyy-MM", "yyyy-M", "yyyy" };
var parts = input.Split('~');
startDate = default;
endDate = default;
// 单个日期
if (parts.Length == 1)
{
if (!DateTime.TryParseExact(input, formats, CultureInfo.InvariantCulture, DateTimeStyles.None, out var date))
{
return false;
}
switch (input.Count(f => f == '-'))
{
case 0: // 年
startDate = new DateTime(date.Year, 1, 1);
endDate = startDate.AddYears(1);
break;
case 1: // 年月
startDate = new DateTime(date.Year, date.Month, 1);
endDate = startDate.AddMonths(1);
break;
default: // 年月日
startDate = date;
endDate = startDate.AddDays(1);
break;
}
return true;
}
// 日期范围
else if (parts.Length == 2)
{
if (!DateTime.TryParseExact(parts[0], formats, CultureInfo.InvariantCulture, DateTimeStyles.None, out var start) ||
!DateTime.TryParseExact(parts[1], formats, CultureInfo.InvariantCulture, DateTimeStyles.None, out var end))
{
return false;
}
startDate = new DateTime(start.Year, start.Month, start.Day);
endDate = new DateTime(end.Year, end.Month, end.Day);
switch (parts[1].Count(f => f == '-'))
{
case 0: // 年
endDate = endDate.AddYears(1);
break;
case 1: // 年月
endDate = endDate.AddMonths(1);
break;
default: // 年月日
endDate = endDate.AddDays(1);
break;
}
return true;
}
else
{
return false;
}
}
3.2 使用日期格式查询
// 尝试解析 strLike 为日期范围
bool isDateRange = CommonFunc.TryParseDateInput(strlike, out DateTime startDate, out DateTime endDate);
expression = expression.And(p =>
// ... 其他条件
p.PayStatus.Contains(strlike) ||
(isDateRange && p.CreateTime >= startDate && p.CreateTime < endDate));

在上图中,我们可以看到一个EF Core查询示例,其中正确应用了针对日期字段的优化技巧。这种做法不仅使代码更加清晰,而且能够显著提高数据库查询的性能。通过这些技巧,我们可以有效地在C#和MySQL环境下处理复杂的模糊搜索需求,尤其是当涉及到日期字段时。
四、优化建议
-
避免不必要的类型转换:在数据库查询中,尽量避免将非字符串类型转换为字符串进行匹配。这不仅会降低查询效率,还可能使得数据库无法利用现有索引。
-
使用专门的日期函数:对于日期类型的字段,使用专门的日期比较函数而不是将日期转换为字符串。EF Core支持多种日期相关的函数,这些函数可以直接应用于日期字段,提高查询效率。
-
考虑索引的影响:确保对于频繁进行模糊匹配的字段建立合适的索引。特别是对于大型数据库,合理的索引对于维持查询性能至关重要。
-
分析生成的SQL:在开发过程中,关注EF Core生成的SQL语句。这可以帮助我们理解EF Core是如何将LINQ查询转换为SQL的,并据此做出优化。
-
减少全表扫描:尽量减少会导致全表扫描的查询模式。
总结
这篇博客中,我们探讨了在C#和MySQL环境下进行模糊查询日期的处理策略。我们从EF Core的模糊查询开始,深入分析了在MySQL中对日期进行模糊查询的效率问题,并提出了相应的优化方法。最后,我们聚焦于如何在EF Core中优化这些查询,特别是针对日期字段的处理。
通过本文的讨论,我们还学会了如何优化现有的查询方法以提高性能。这些知识对于开发高效、可靠的数据驱动应用程序至关重要,尤其是在处理大量数据和复杂查询的情况下。希望这些技巧能在未来的项目中更好地处理非字符串类型的查询。