A题论文分享 链接:
https://pan.baidu.com/s/1cltswCuiPG30HhuysrEVuA
提取码:sxjm
欢迎大家批评指正,
为了方便大家摘抄,所有内容均为中文。但是!!该比赛是英文论文竞赛,大家需要全部自行翻译为英文。为了方便起见,图表的相关指标已经全部改为英文。!!!必读!!!
为了防伪,目前论文中所有图片均有水印,3日将公布无水印版本
使用须知:该论文为直接可以提交的论文,会进行展示。很多人都会这一版本成品论文,直接提交一定会查重不过关。成品论文是按着半成品论文以及之前的解题思路写出的,如果不对外展示,在普通建模竞赛是可以直接提交100%获奖的文章,保二冲一的水平。进行展示的目的,及为了让辅助大家写论文,也让大家知道获奖的话应该要比展示的这篇成品论文要更好一些。
组委会要求重要格式规范如下所示,大家可以根据要求,以及1资料中提供的优秀论文资料进行修改。
使用、借鉴、抄写该论文是否违规:只要不超过查重率的20%,就不能算作违规。该论文属于公开发表的网上资料,进行借鉴、参考不能算作违规,切记不要抄的太过分,查重率一定要低于20%就可以。下图为最新的数模竞赛规定

51页正文 1万七千字
14页word文档可视化图片
全部过程数据
不禁言QQ群
每一问题可实现,直接可以调用代码
作品 特色:
1、售后群 不禁言,这是对作品最大的自信,欢迎大家进行批评指正
2、全国最快、最多、最便宜
3、全部图片具有实现代码,所有过程据可以代码实现,代码完全公开透明
基于预测模型的太阳黑子研究
摘要
由于太阳黑子与其他类型的太阳活动相关,太阳黑子可以用来帮助预测空间天气、电离层的状态,以及与短波无线电传播或卫星通信相关的条件。因此,本文将收集太阳黑子相关数据进行建立预测模型进行研究分析。
首先,为了找到相关的数据,利用python数据爬虫以及自行寻找等方式,利用SILSO、NASA和ESA等收集太阳黑子的历史数据。首先识别和处理数据中的缺失值和异常值,运用3σ原则和箱型图来识别和处理异常值,将异常值进行剔除处理。采用牛顿插值的线性插值方法进行填补缺失值。
对于问题一,预测当前和下一个太阳周期的开始和结束。收集到每个太阳周期的时长,使用该指标作为自变量构建预测模型进行预测。使用ARIMA(自回归积分滑动平均)模型来处理时间序列数据。首先利用自相关图以及偏自相关图、单位根检验判定稳定性。在引入巴雷特检验判定随机性,从而建立ARIMA模型,以更准确地识别和预测太阳周期的变化。
对于问题二,预测下一个太阳周期的太阳最大值的开始时间和持续时间。以太阳最大值为自变量,使用灰色预测模型进行单变量预测。对于持续时间,利用每次最大值开始与结束的时间计算时间长度,以时间长度作为自变量,使用灰色预测模型进行单变量预测。
对于问题三,预测当前和下一个太阳周期中太阳黑子的数量和面积。我们引入LSTM预测模型,结合ARIMA、灰色和LSTM(长短期记忆)网络模型,建立一个加权平均预测模型。以误差最小为目标函数,权重系数和为1为约束条件,构建优化模型,引入粒子群算法进行算法优化。利用历史数据分析数量和面积之间的关系,引入相关性分析进行判断。最后使用matlab拟合工具箱构造非线性拟合关系式。利用预测得到的数量以及非线性函数关系式对面积进行求解计算。最后引入MAPE、MAE等评价指标对预测结果进行评价,并进行交叉检验验证模型稳定性。
最终,基于ARIMA、灰色和LSTM预测模型实现对当前和下一个太阳周期各种指标的相关变换。不仅可以更准确地预测太阳黑子的活动,还可以深入理解太阳活动与地球环境之间的复杂相互作用。这种方法结合了传统统计学和现代数据科学的优势,为解决复杂的天文预测问题提供了坚实的基础。
关键词:关联模型、数据预处理、预测模型、优化模型、
目录
基于预测模型的太阳黑子研究
摘要
一、 问题重述
1.1 问题背景
1.2 问题回顾
二、 问题分析
1.1 数据分析
1.2 问题一分析
1.3 问题二分析
1.4 问题三分析
三、 模型假设
四、 符号说明
五、 模型的建立与求解
5.1 数据预处理
5.1.1 数据收集
5.1.2 异常值处理
5.1.3 缺失值处理
5.2 问题一预测模型的建立与求解
5.2.1 变量的选择
一、数据的检验与处理
二、建立模型
5.3问题二预测模型的建立与求解
5.3.1 相关性分析
5.3.2 极大值持续时间非线性拟合
5.3.4 极大值非线性拟合
5.3.5 极小值预测
6.3.3季节性ARIMA序列模型的建立
5.3.6 极大值预测
5.4问题三预测模型的建立与求解
5.4.1 LSTM预测模型的构建
5.4.2 SVM预测模型
5.4.3 随机森林
5.4.4 加权优化预测
5.4.6 评价指标
评价指标结果如下所示
5.4.6 关系判定
六、 模型总结
6.1 模型优点
6.2模型缺点
6.3模型推广
七、 参考文献
八、 附录
5.1 数据预处理
5.1.1 数据收集
为了找到相关的数据,利用python数据爬虫以及自行寻找等方式,利用SILSO、NASA和ESA等收集太阳黑子的历史数据。这里展示利用SILSO收集到的数据过程,
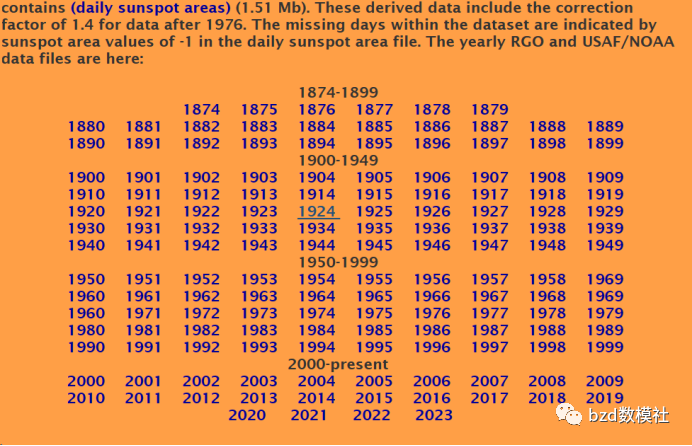
对于该网站的数据下载后是txt文件且数据合并在一起,因此,我们使用python进行文件类型转变以及数据与指标的复合,伪代码如下所示
表1:伪代码
| 导入 pandas 库作为 pd |
| # 读取文本文件 |
| 设置 file_path 为 '/mnt/data/g1874.txt' |
| # 使用 pandas 读取文件到 DataFrame |
| # 使用 'read_fwf' 方法读取固定宽度格式的数据 |
| df = 读取固定宽度格式文件(file_path, 列规格=[(0, 4), (4, 6), ..., (69, 74)], 表头=无) |





![捷诚管理信息系统CWSFinanceCommon.asmx SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/direct/bd3f84bdb06e497c896e7ce836fabeee.png)