目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十五、安装HIVE
1.配置MetaStore
利用ambari创建的MySQL作为MetaStore,创建用户hive及数据库hive
mysql -uroot -p
CREATE DATABASE hive;
CREATE USER 'hive'@'%' IDENTIFIED BY 'lnyd@LNsy115';
GRANT ALL ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
2.安装
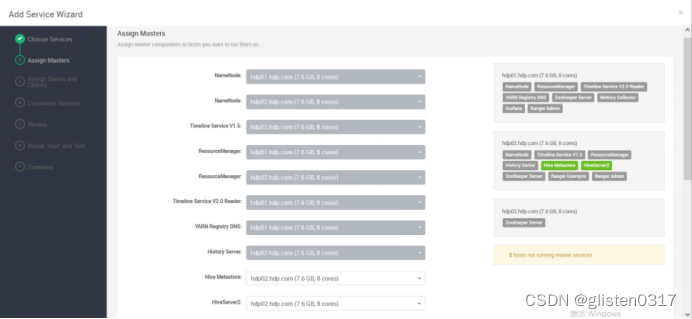
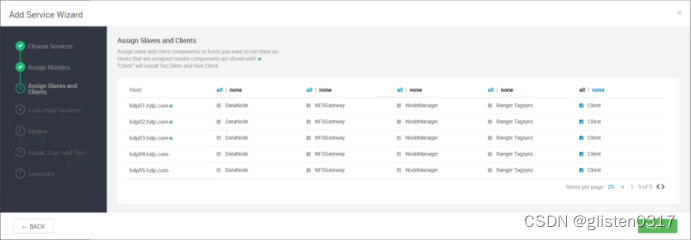
在服务中添加Hive
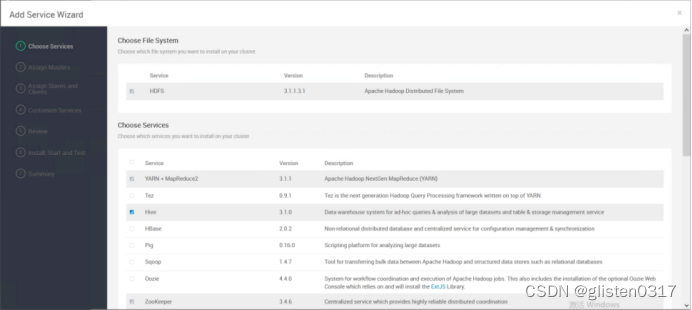
安装hive时需要同步安装Tez
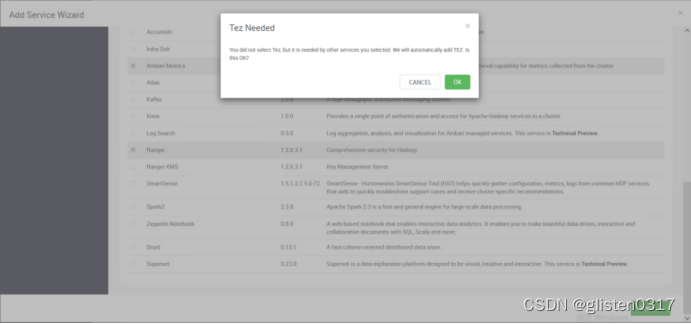
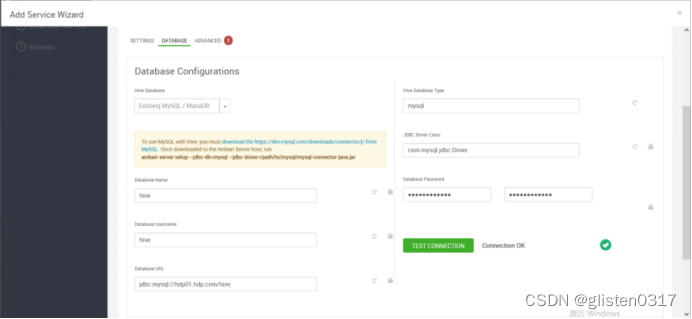
DATABASE
Hive Database:Existing MySQL / MariaDB
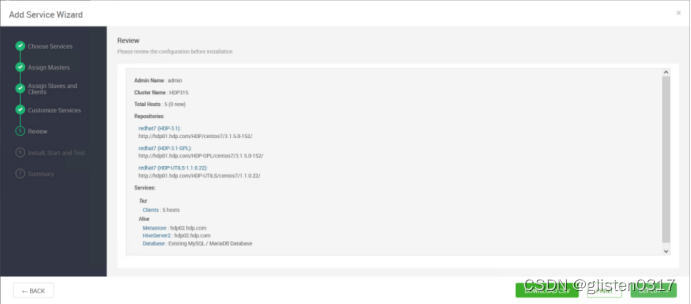
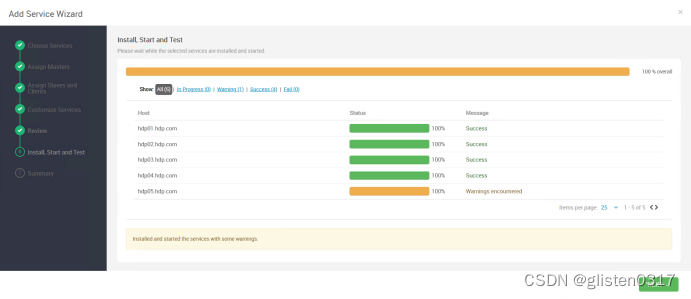

安装完成后,需要按照提示将hdfs、yarn等服务进行重启。
Ambari安装后,Hive使用了Tez作为计算引擎,也可以修改为MR或Spark,在配置文件中调整,/usr/hdp/3.1.5.0-152/hive/conf/hive-site.xml
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
3.高可用
(1)MetaSore HA
ACTIONS->Add Hive Metastore
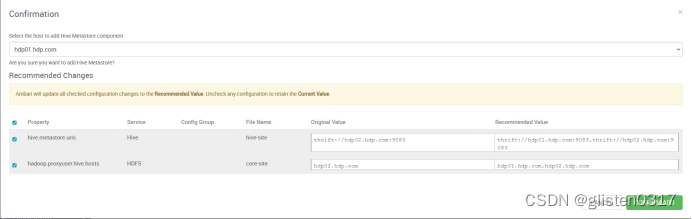
重启相关服务后完成HA启用。
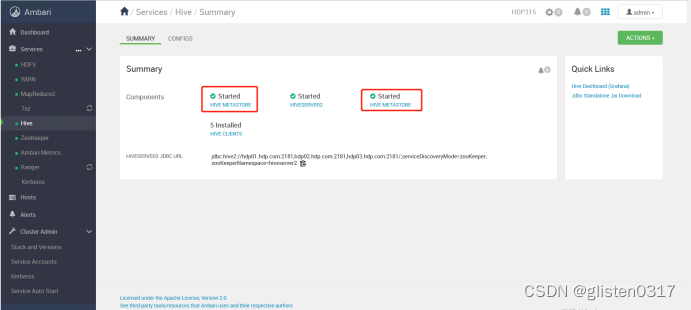
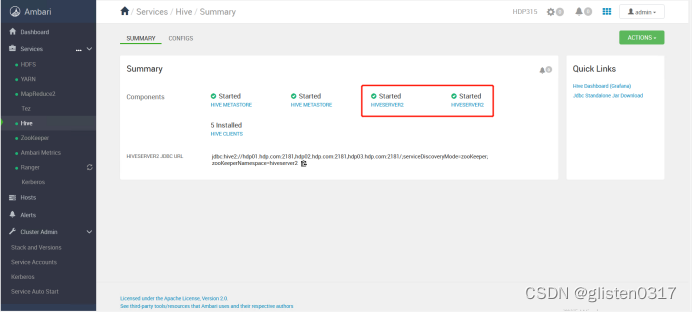
(2)HiveServer2 HA
ACTIONS->Add HiveServer2
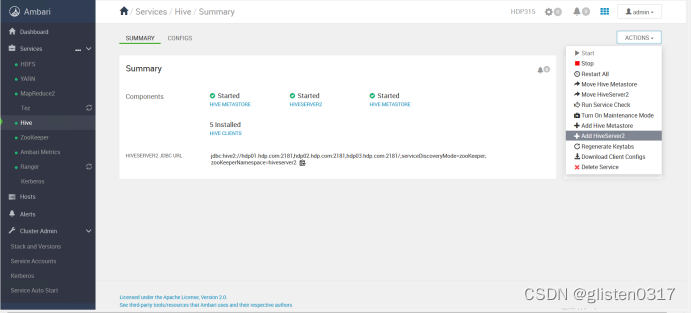
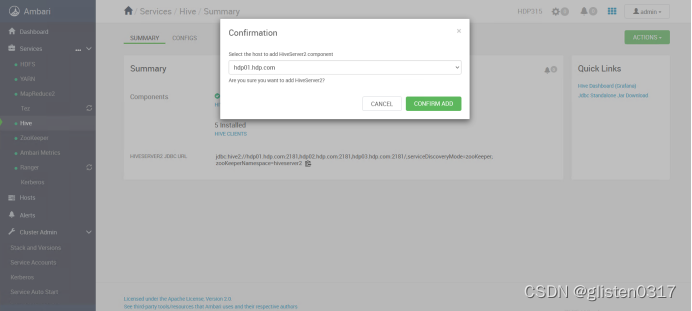
重启HIVE和Tez服务后完成HA启用。
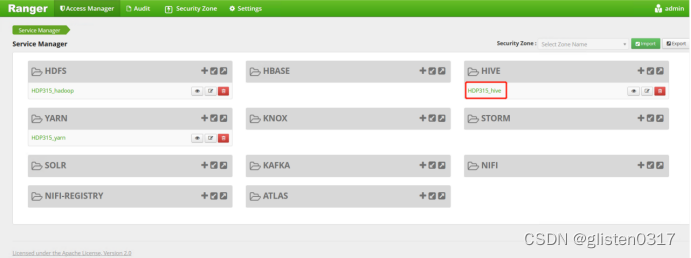
4.Ranger授权
在Ranger上新建策略完成对租户的授权

权限策略可以精细到列
5.常用指令
(1)CLI连接
类似于mysql的命令行工具,但是只能操作本地的Hive服务,无法通过JDBC连接远程服务,且sql执行结果没有格式化,看起来不是很直观。
先用keytab登录,使用hive客户端进入
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
hive

可以设置一些基本参数,让hive使用起来更便捷:
让提示符显示当前库
set hive.cli.print.current.db=true;
显示查询结果时显示字段名称
set hive.cli.print.header=true;
设置只对当前会话有效,重启hive会话后就失效。
创建测试数据库test_hive_db
create database test_hive_db;

查看数据库的信息
desc database test_hive_db;
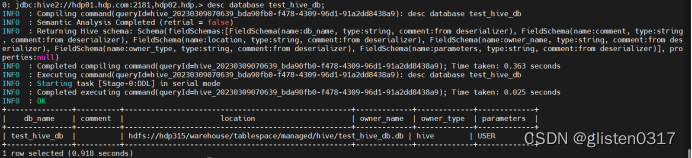
从输出结果看,测试数据库test_hive_db存储在hdfs上,位置为hdfs://hdp315/warehouse/tablespace/managed/hive/test_hive_db.db
(2)Beeline连接
HiveServer2支持一个新的命令行Shell,称为:Beeline,后续将会使用Beeline替代Hive CLI。Beeline基于SQLLine CLI的JDBC客户端。Hive CLI和Beeline都属于命令行操作模式,主要区别是Hive CLI只能操作本地的Hive服务,而Beeline可以通过JDBC连接远程服务。
开启了kerberos认证的hadoop集群,hive默认使用kerberos认证。先以hive/hdp01.hdp.com@HDP315.COM身份登录,创建数据库hive_db_tenant1和tenant2、表hive_table_tenant1和hive_table_tenant2,在ranger上分别将两个租户赋权到对应的数据库上,然后以tenant1身份连接,分别尝试连接两个数据库,看是否有权限访问
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
create database hive_db_tenant1;
create database hive_db_tenant2;
create table hive_db_tenant1.hive_table_tenant1 (id int,name string,address string,phone string);
create table hive_db_tenant2.hive_table_tenant2 (id int,name string,address string,phone string);
kdestroy
kinit -kt /root/keytab/tenant1.keytab tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
describe hive_db_tenant1.hive_table_tenant1;
describe hive_db_tenant2.hive_table_tenant2;
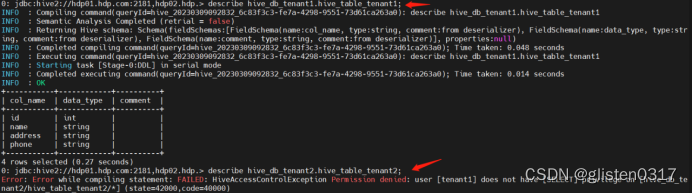
从结果看,无法访问hive_table_tenant2的表。
(3)导入数据等测试
生成6GB大小的文件
#!/bin/bash
cat /dev/null > /root/bigFile.txt
for((i=1;i<=100000000;i++));
do
echo "$i,testname$i,testaddress$i,testphonenumber$i" >> /root/bigFile.txt;
done
本次测试使用tenant1
kinit -kt /root/keytab/tenant1.keytab tenant1
hdfs dfs -put /root/bigFile.txt /testhdfs/tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
set tez.queue.name=tenant1;
① 导入测试
测试一次性导入和切分导入的性能
新建表,用于一次性导入
CREATE TABLE `test_tenant1_one`(
`id` int,
`name` string,
`address` string,
`phone` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_one.db';
执行导入
LOAD DATA INPATH 'hdfs://hdp315/testhdfs/tenant1/bigFile.txt' INTO TABLE hive_db_tenant1.test_tenant1_one;

新建表,用于分桶导入,分桶的实质就是对分桶的字段做了hash,然后存放到对应文件中,所以说如果原有数据没有按key hash,需要在插入分桶的时候hash,也就是说向分桶表中插入数据的时候必然要执行一次MAPREDUCE,这也就是分桶表的数据基本只能通过从结果集查询插入的方式进行导入
CREATE TABLE `test_tenant1_bucket`(
`id` int,
`name` string,
`address` string,
`phone` string
)
CLUSTERED BY(id) INTO 16 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_bucket.db';
执行导入
INSERT OVERWRITE TABLE test_tenant1_bucket SELECT * FROM test_tenant1_one;
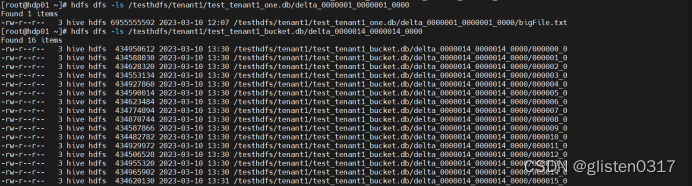
此时,分桶后的文件会分成16个分片
② 查询测试
对测试的数据库进行查询操作
SELECT SUM(id) FROM hive_db_tenant1.test_tenant1_bucket;
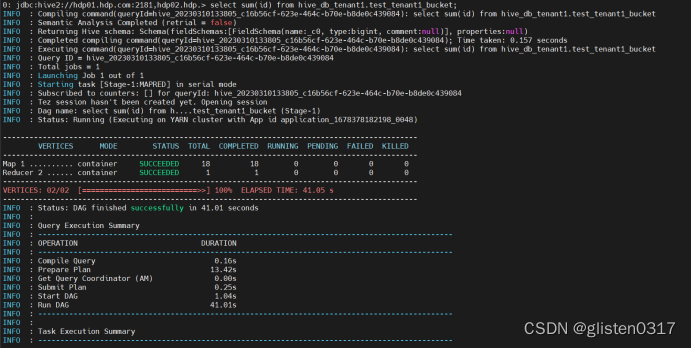
6.常见报错
(1)提示没有权限调用default队列
Select查询不报错,但count、insert、load等操作需要调用tez引擎时会报错
报错信息:
ERROR : Job Submission failed with exception 'java.io.IOException(org.apache.hadoop.yarn.exceptions.YarnException: org.apache.hadoop.security.AccessControlException: User hive does not have permission to submit application_1678378182198_0002 to queue default
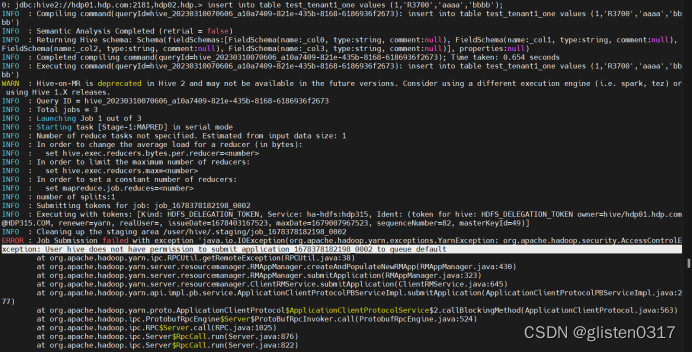
默认调用的是default队列,需要手工指定使用的队列
mr指定队列:
set mapreduce.job.queuename=tenant1;
tez指定队列:
set tez.queue.name=tenant1;