Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序
Kafka 官网:Apache Kafka
关于ZooKeeper的弃用
根据 Kafka官网信息,随着Apache Kafka 3.5版本的发布,Zookeeper现已被标记为已弃用。未来计划在Apache Kafka(4.0版)的下一个主要版本中删除ZooKeeper,该版本最快将于2024年4月发布。在弃用阶段,ZooKeeper仍然支持用于Kafka集群元数据的管理,但不建议用于新的部署。新的部署方式使用 KRaft 模式,KRaft 模式部署可以看笔者的文章《kafka 集群 KRaft 模式搭建》,考虑到一些公司仍然在使用老版本的 Kafka,故笔者写这篇文章记录 Kafka 集群Zookeeper 模式搭建
官网信息截图

笔者使用3台服务器,它们的 ip 分别是 192.168.3.232、192.168.2.90、192.168.2.11
目录
1、官网下载 Kafka
2、配置 Kafka
3、启动 Kafka 集群
4、关闭 Kafka 集群
5、使用Kafka 可视化工具查看
6、测试Kafka集群
1、官网下载 Kafka
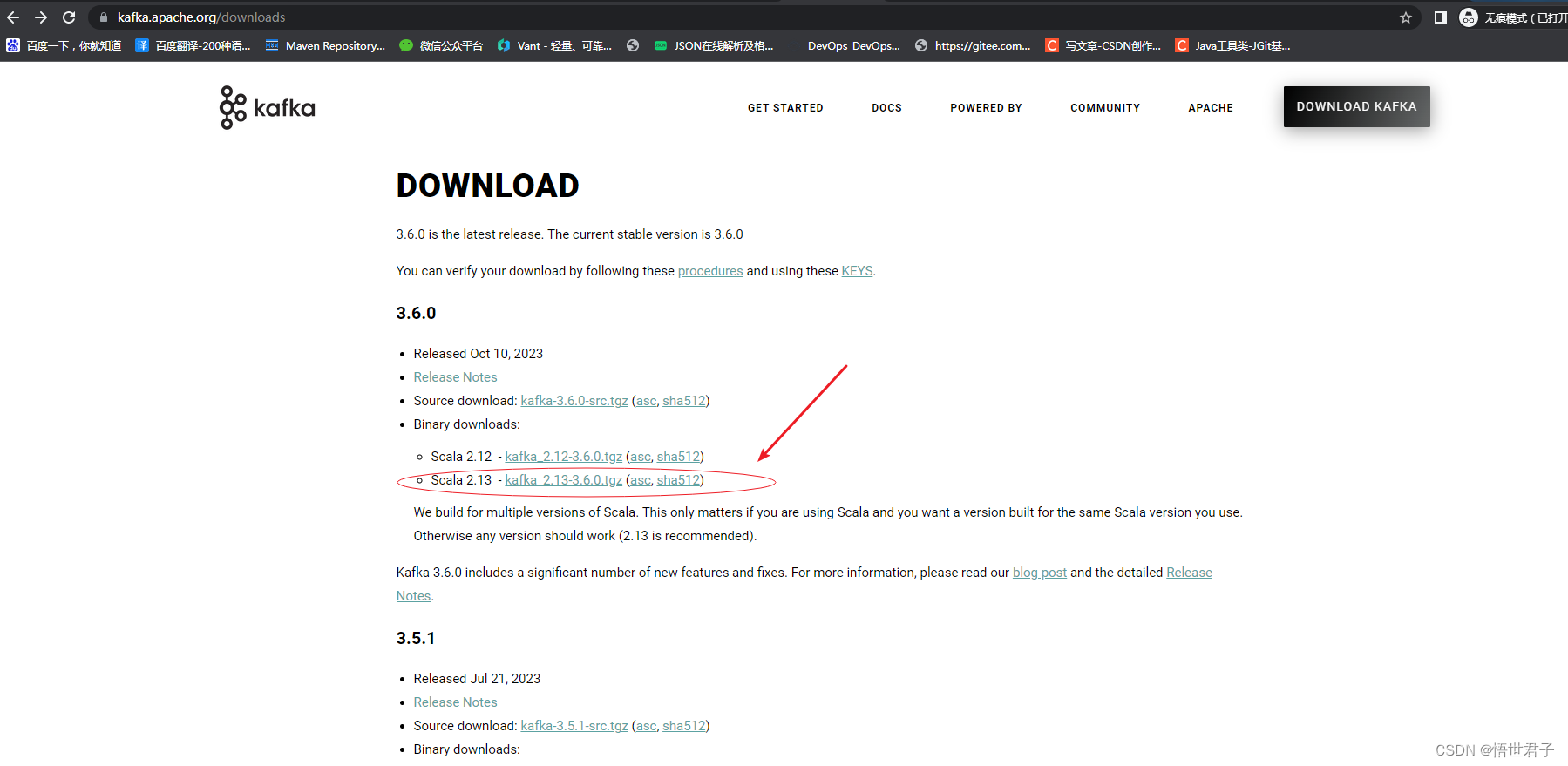
这里笔者下载最新版3.6.0
3.6.0 版本需要至少 java8 及以上版本,笔者使用的是 java8 版本
关于 linux 安装 java,没安装过的朋友可以参考《linux 系统安装 jdk》
下载完成
将 kafka分别上传到3台linux

在3台服务器上分别创建 kafka 安装目录
mkdir /usr/local/kafka在3台服务器上分别将 kafka 安装包解压到新创建的 kafka 目录
tar -xzf kafka_2.13-3.6.0.tgz -C /usr/local/kafka2、配置 Kafka
进入配置目录
cd /usr/local/kafka/kafka_2.13-3.6.0/config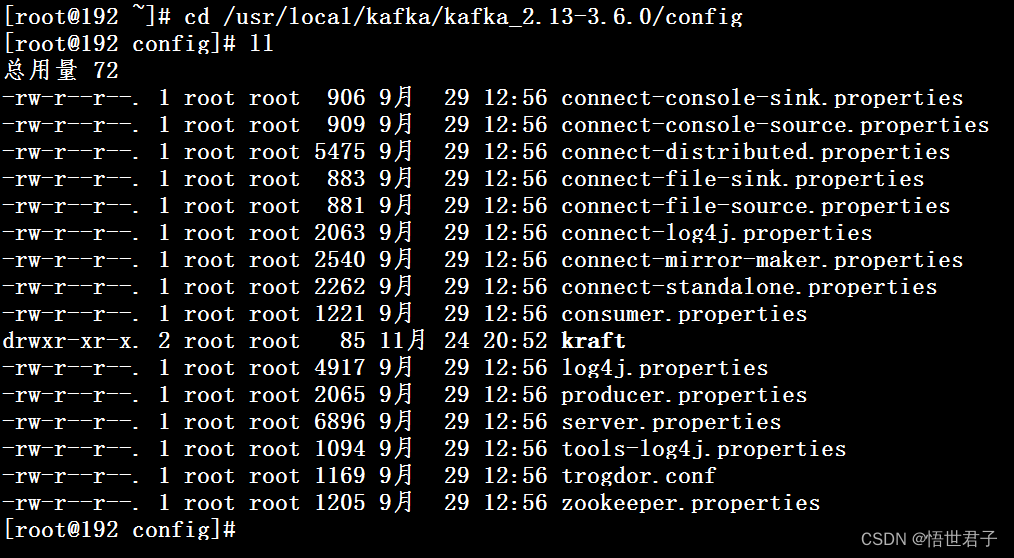
编辑配置文件 server.properties
vi server.properties配置 broker.id,advertised.listeners,zookeeper.connect
broker.id 每个节点的id
advertised.listeners 本机的外网访问地址
zookeeper.connect zookeeper 地址
192.168.3.232 节点配置
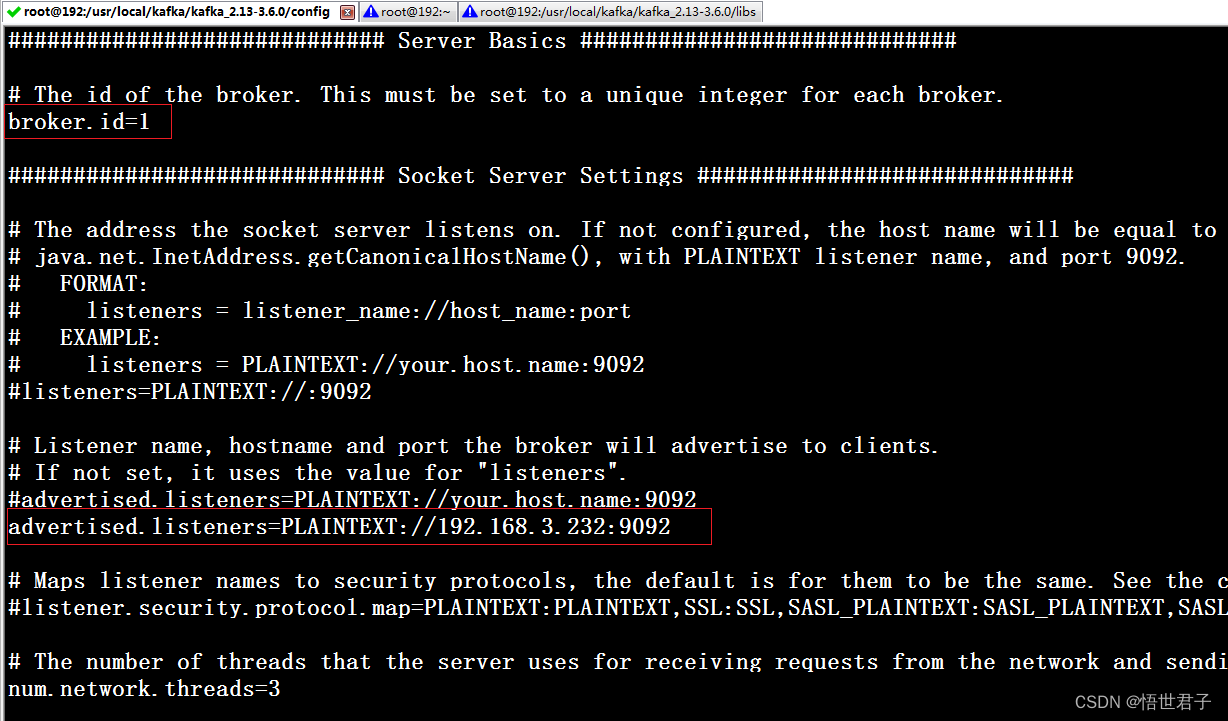
advertised.listeners 笔者配置为本机地址
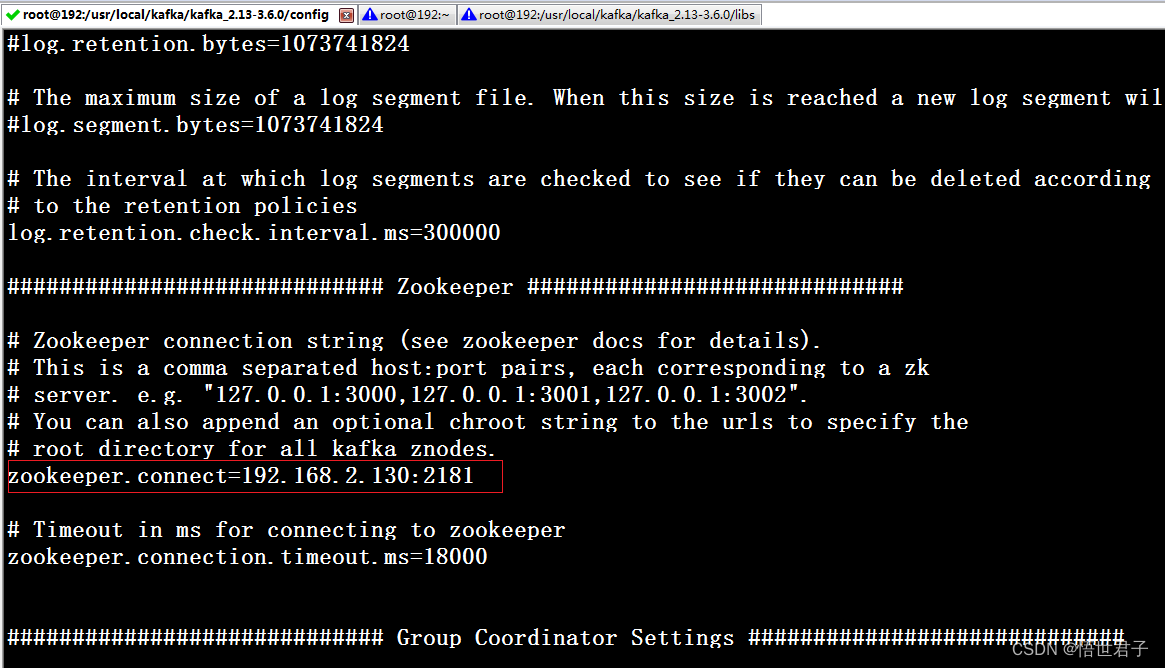
192.168.2.90 节点
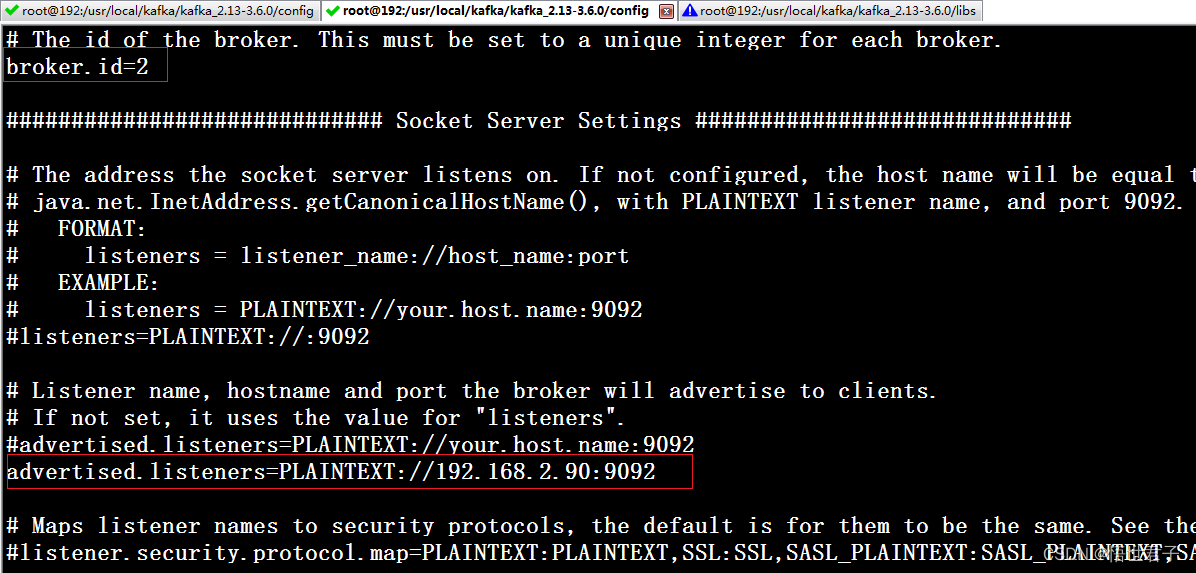
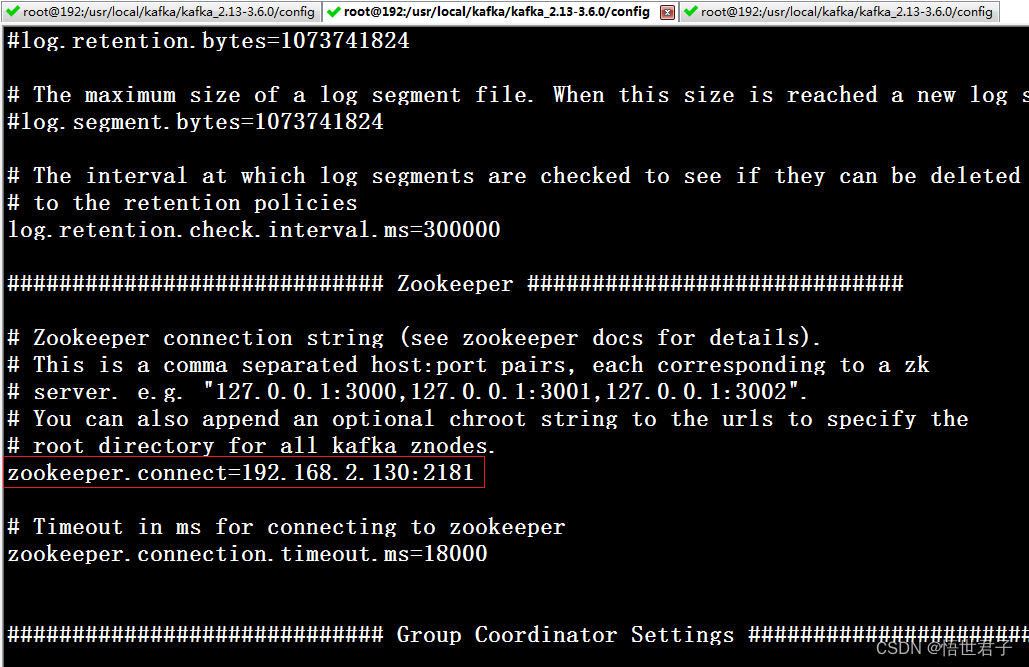
192.168.2.11 节点
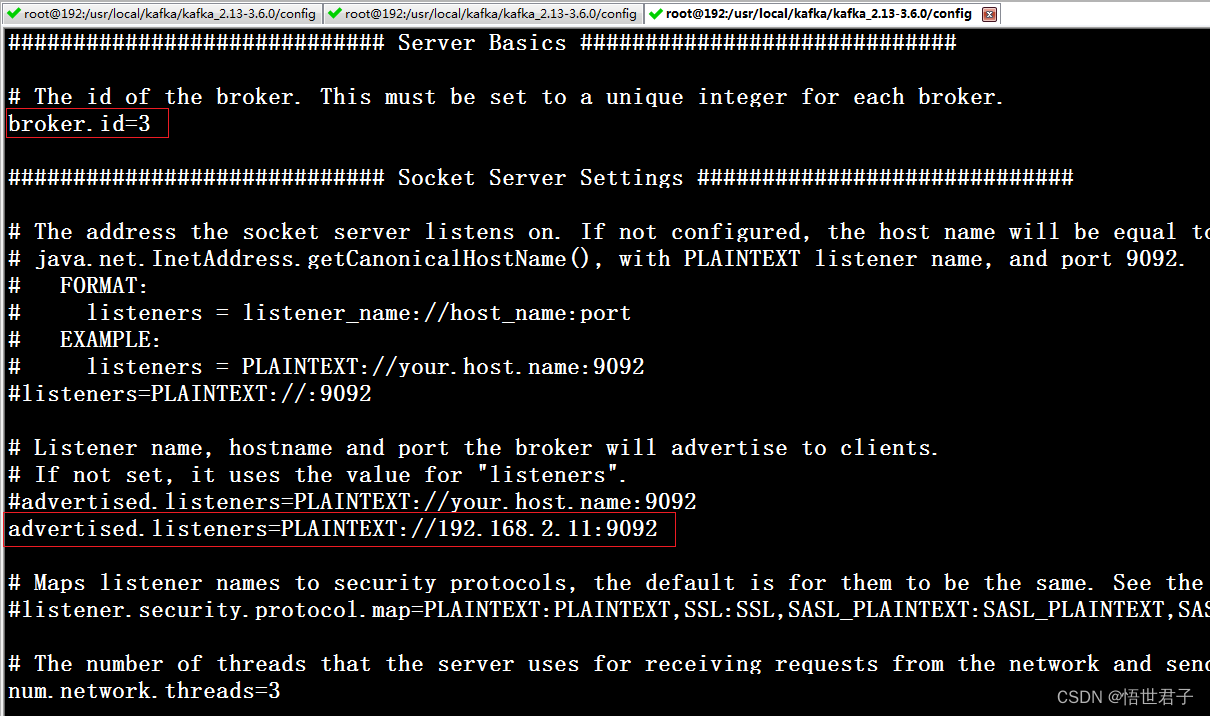
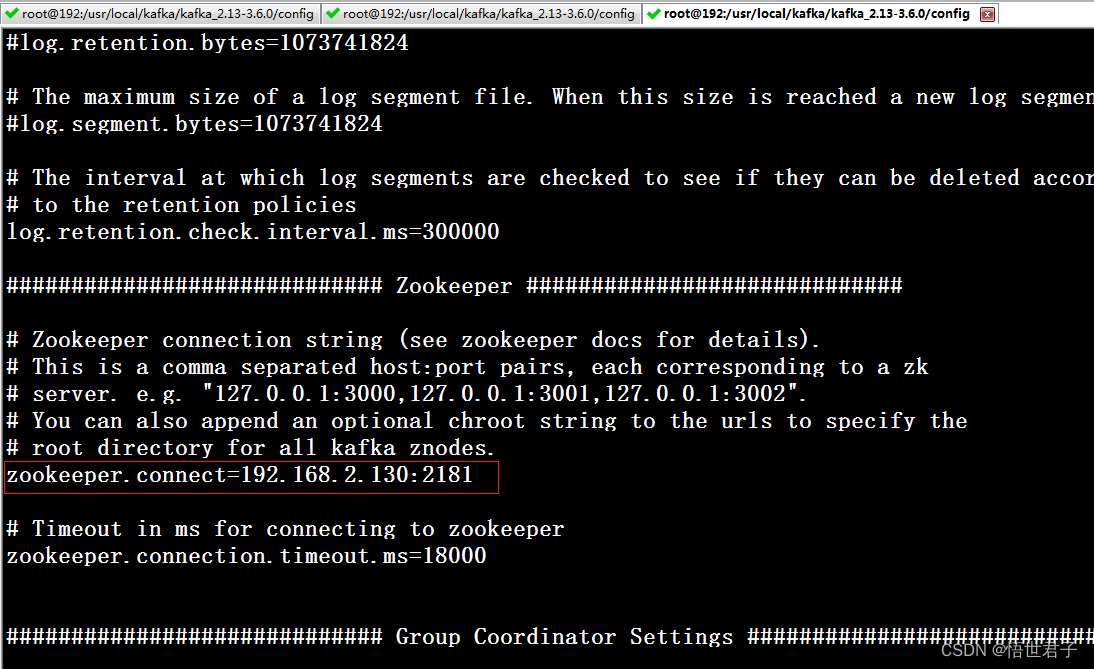
笔者zookeeper 地址是 192.168.2.130:2181
zookeeper 版本是3.8.3
关于zookeeper单机安装和集群安装可以参考:《Linux环境 安装 zookeeper》《windows环境 安装 zookeeper》《linux 使用 nginx 搭建 zookeeper 集群》
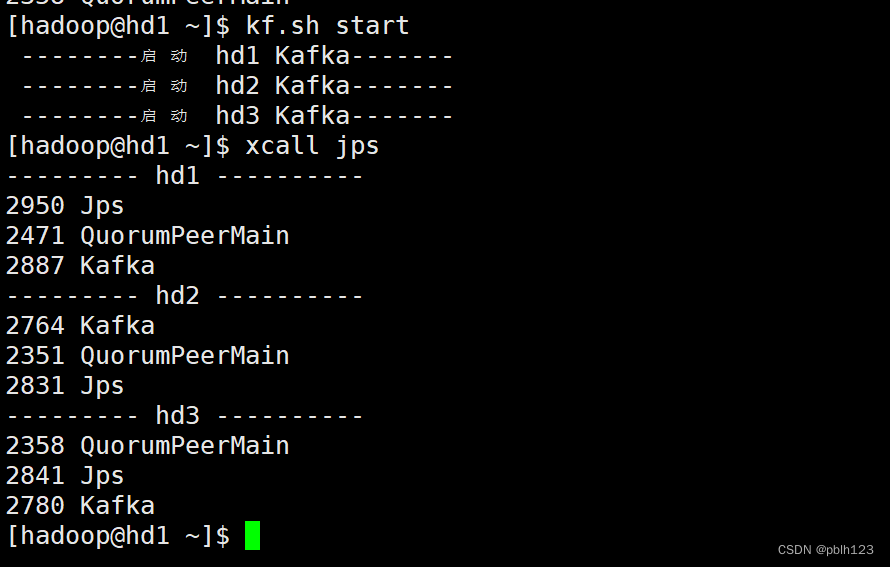
3、启动 Kafka 集群
首先启动 zookeeper
然后在3台机器上依次启动 Kafka
进入 kafka 目录
cd /usr/local/kafka/kafka_2.13-3.6.0下面2个命令皆可
bin/kafka-server-start.sh config/server.properties或
bin/kafka-server-start.sh -daemon config/server.properties
4、关闭 Kafka 集群
关闭命令
bin/kafka-server-stop.sh在 3 个节点上分别执行关闭命令
5、使用Kafka 可视化工具查看
下载地址:https://www.kafkatool.com/download.html
运行效果
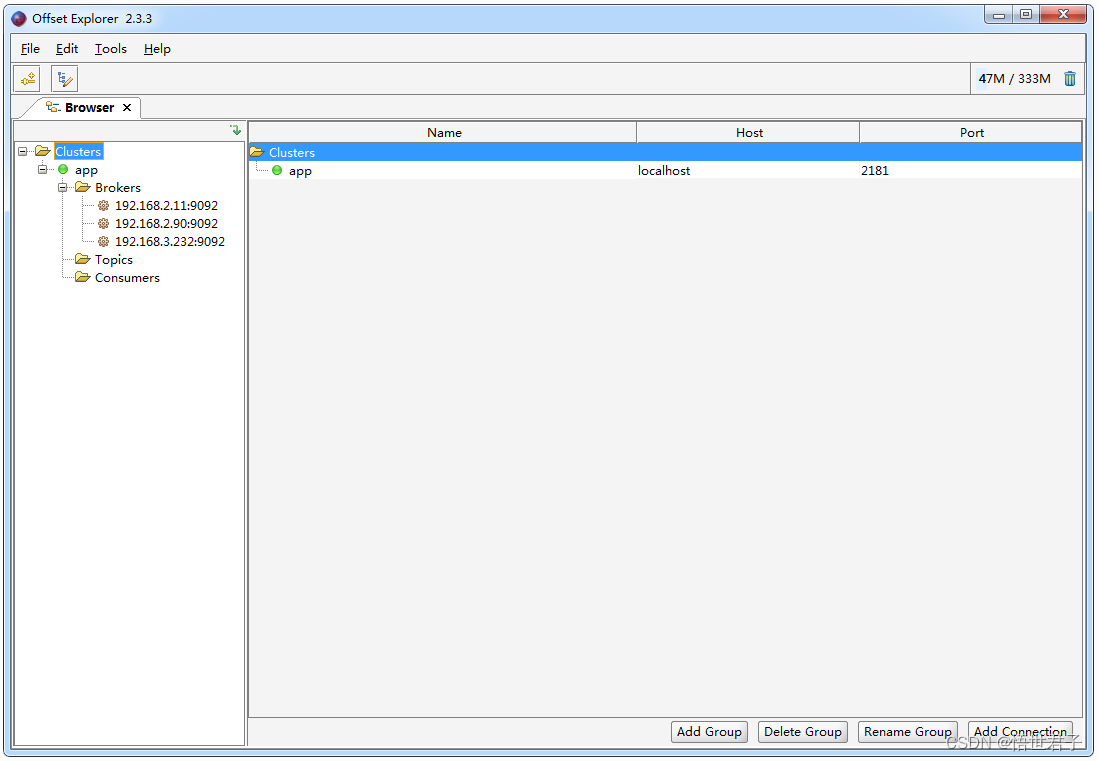
6、测试Kafka集群
新建 maven 项目,添加 Kafka 依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>笔者新建 maven项目 kafka-learn
kafka-learn 项目 pom 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wsjzzcbq</groupId>
<artifactId>kafka-learn</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
</project>新建生产者 ProducerDemo
package com.wsjzzcbq;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* Demo
*
* @author wsjz
* @date 2023/11/24
*/
public class ProducerDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
//配置集群节点信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");
//配置序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(properties);
//topic 名称是demo_topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_topic", "明月别枝惊鹊");
RecordMetadata recordMetadata = producer.send(producerRecord).get();
System.out.println(recordMetadata.topic());
System.out.println(recordMetadata.partition());
System.out.println(recordMetadata.offset());
}
}新建消费者 ConsumerDemo
package com.wsjzzcbq;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* ConsumerDemo
*
* @author wsjz
* @date 2023/11/24
*/
public class ConsumerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
// 配置集群节点信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");
// 消费分组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "demo_group");
// 序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 消费者订阅主题
consumer.subscribe(Arrays.asList("demo_topic"));
while (true) {
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String,String> record:records) {
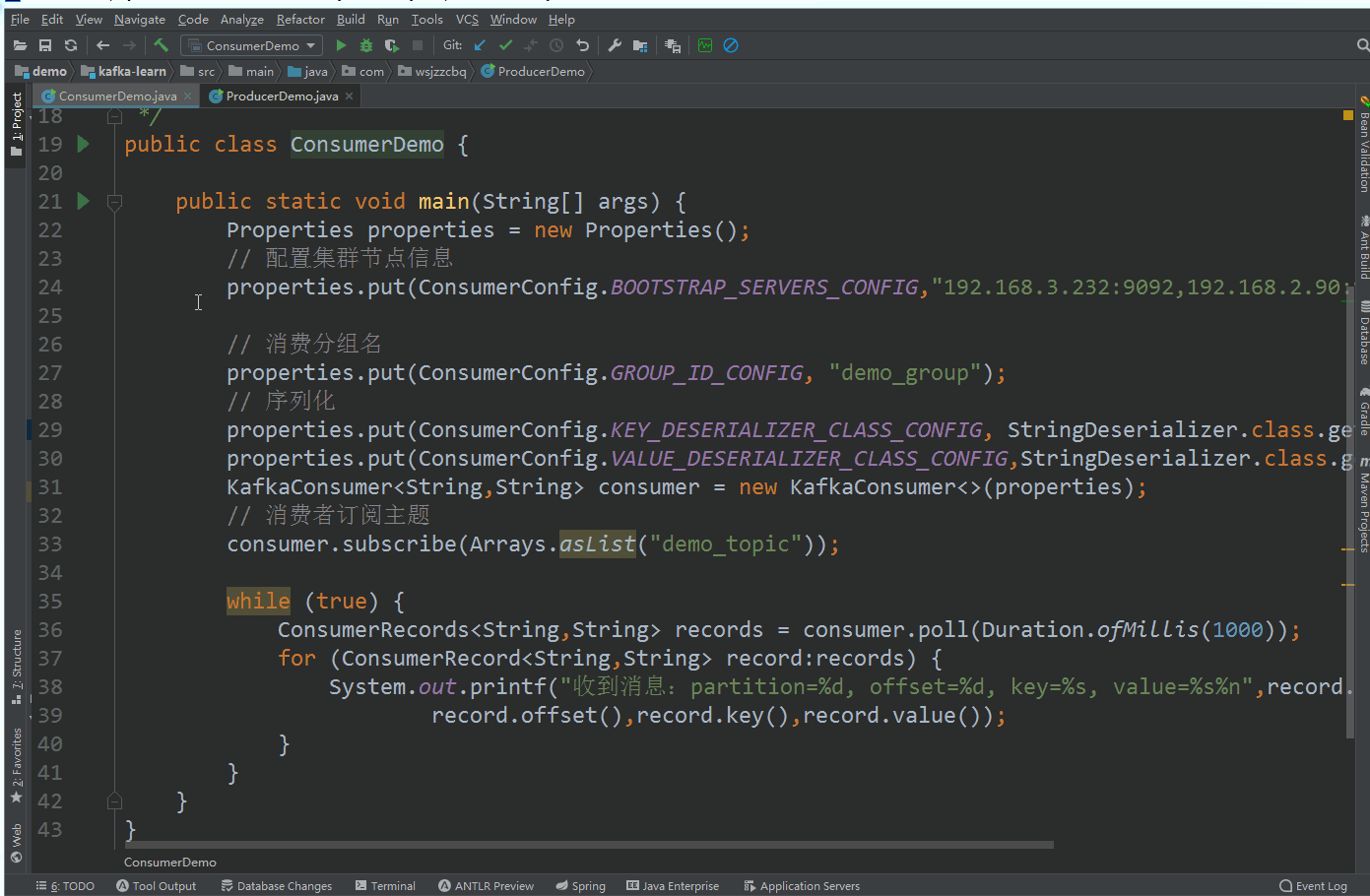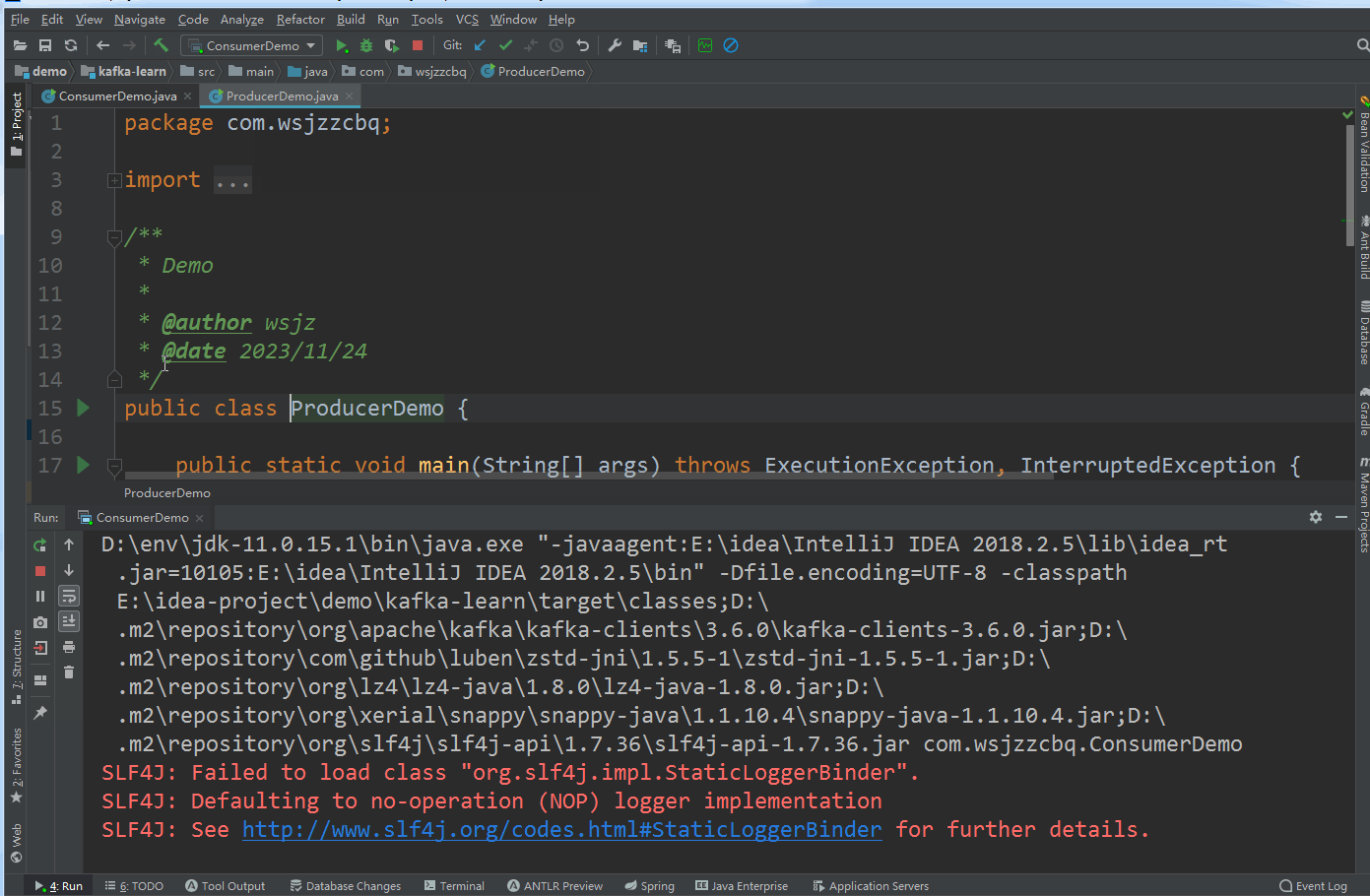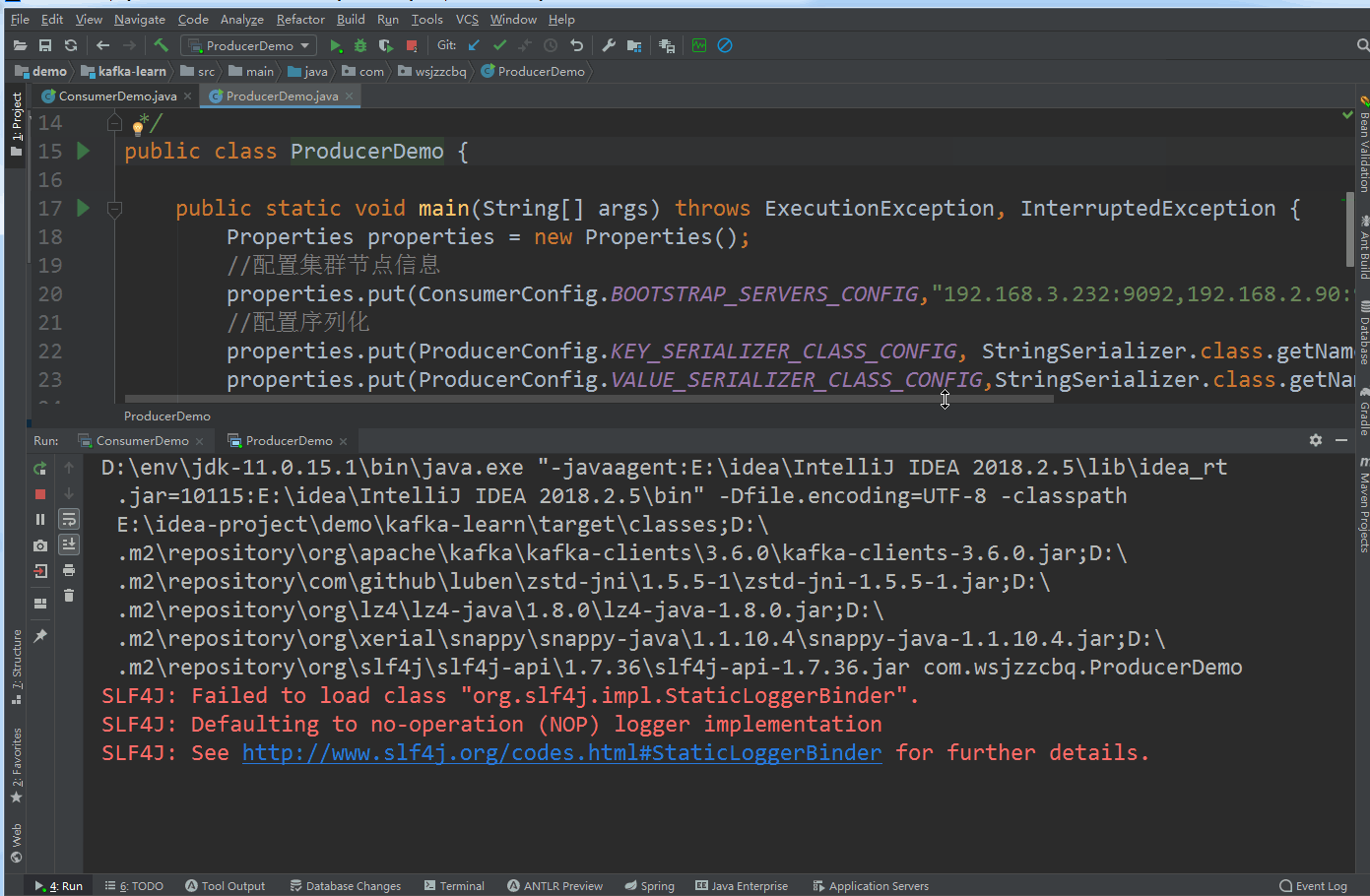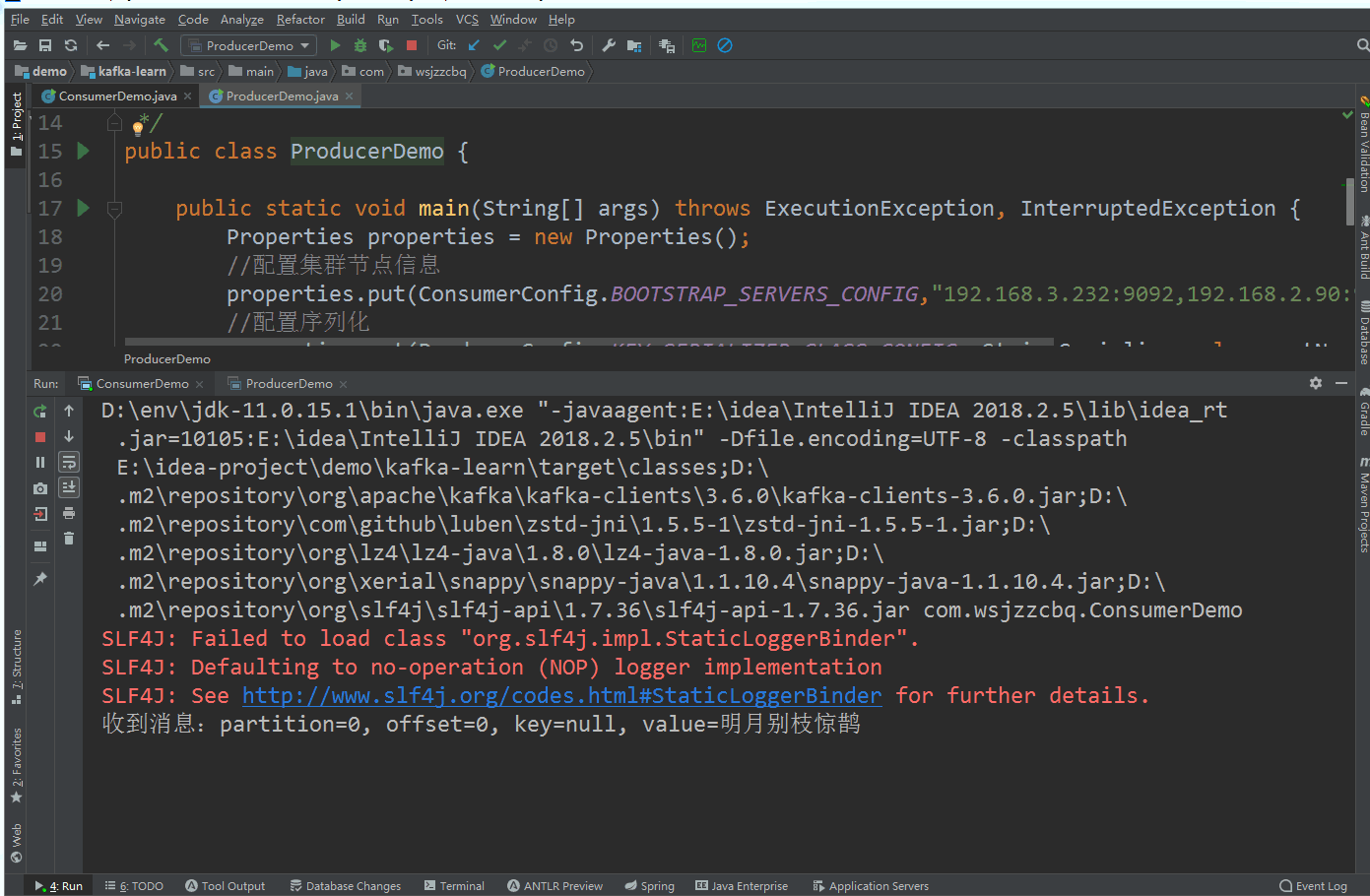
System.out.printf("收到消息:partition=%d, offset=%d, key=%s, value=%s%n",record.partition(),
record.offset(),record.key(),record.value());
}
}
}
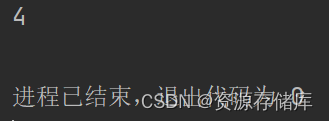
}运行测试
效果图
至此完

![读书笔记-《数据结构与算法》-摘要1[数据结构]](https://img-blog.csdnimg.cn/direct/7f63f19f694c4412869b072651e5aa79.png)





![【前缀和]LeetCode1862:向下取整数对和](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)