LLM似乎正在接管世界,但许多人仍然不真正理解他们是如何运作的。 我从事机器学习工作已有几年,并且对自然语言处理和最近的进展非常着迷。
尽管我阅读了大部分随附的论文,但训练这些模型对我来说仍然是一个谜,这就是为什么我决定继续自己训练一个模型,以真正了解它是如何工作的。 我将其与训练问答模型结合起来,但这里仅详细介绍 DistilBERT 模型。
为了让你的生活更轻松,我决定对其工作原理进行简短回顾。 请查看这篇文章中的 distilbert.ipynb文件来查找相关代码。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
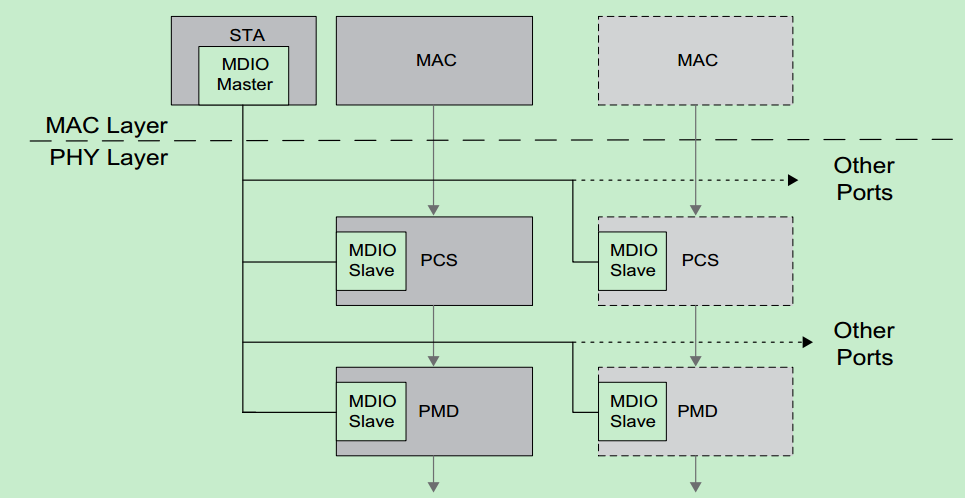
1、为什么选择 DistilBERT
要回答的第一个问题是为什么我选择 DistilBERT 而不是 BERT、ALBERT 和该模型的所有其他变体。 不幸的是,我没有无限的云计算访问权限,只有内存有限的本地 GPU,因此我必须针对模型大小和训练时间而不是性能进行优化。
也就是说,与 BERT 相比,官方的 DistilBERT 性能仅下降了3%,这似乎是一个合理的权衡。 BERT 基础有1.1亿个参数,训练时间为12天,而 DistilBERT 有6600 万个参数,训练时间只有3.5天左右。 原始论文中指出模型减小了 40%,保留了97% 的语言理解能力,速度提高 60%。
我查看了这篇文章中对 BERT、RoBERTA、DistilBERT 和 XLNet 的简短总结和比较,文章在评论中提供了一个很棒的表格,比较了所有模型。
2、数据
我使用 HuggingFace 的 OpenWebText 数据集来训练模型。 它是 OpenAI 的 WebText 数据集的开源版本。 它包含从 Reddit 采样的 8013769 个段落。
HuggingFace 为许多数据集和模型提供了一个令人惊叹的(!!!)界面,我在整个项目中都使用了它。 只需使用以下命令即可下载整个数据集。
from datasets import load_dataset
ds = load_dataset("openwebtext")然后我继续将数据集以 10 000 个为单位存储在本地,因为这需要一些时间,而且我不想每次都等待。
3、分词(tokenization)
接下来,我们需要为模型训练一个分词器(因为我们无法将自然语言输入到模型中)。 我们可以使用 HuggingFace 的 BertWordPieceTokenizer。 我们只需传递文件的路径,它就会自动完成所有操作。 此外,我们还需要添加特殊标记 PAD(填充)、UNK(未知)、CLS(分类)、SEP(分隔符)和 MSK(掩码)标记。 有关这些标记的解释,请参阅基本 BERT 模型教程。
from tokenizers import BertWordPieceTokenizer
paths = [str(x) for x in Path('data/original').glob('**/*.txt')]
tokenizer = BertWordPieceTokenizer(
clean_text=True,
handle_chinese_chars=False,
strip_accents=False,
lowercase=True
)
tokenizer.train(files=paths[:10], vocab_size=30_000, min_frequency=2,
limit_alphabet=1000, wordpieces_prefix='##',
special_tokens=['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]'])当我们测试它时,我们得到以下标记并再次解码它们,结果表明标记生成器在每个输入的开头添加了一个 CLS 标记,并在句子后面添加了分隔符标记。 此外,我们还看到标记化输入包含输入 id(每个单词的 id)和注意掩码(告诉模型哪些标记很重要,即如果我们将序列填充到给定长度,它们将为 0)。
tokens = tokenizer('Hello, how are you?')
print(tokens)
# {'input_ids': [2, 21694, 16, 2287, 2009, 1991, 35, 3],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
tokenizer.decode(tokens['input_ids'])
# '[CLS] hello, how are you? [SEP]'4、数据集和数据加载器
我们可以继续使用自定义的 Dataset 类和 PyTorch 中的 DataLoader 准备要加载到模型中的数据。 数据集类可以在这里找到。 我们基本上加载文件并使用我们的分词器对输入进行编码。
我在数据集中做的另一件事是逐个加载文件。 考虑到内存限制,我必须以这种方式实现它。 它有一些缺点,即你不能以这种方式洗牌数据,因为这会把一切搞乱。 不过,这应该不是什么太大的问题,因为数据集已经根据数据集描述进行了改组。
在训练过程中,模型尝试预测被屏蔽的标记,我们需要对其进行屏蔽。 因此,我屏蔽了(分配 MSK 令牌)15% 的输入,效果非常好。 其中一些基于 DistilBERT 的 HuggingFace 实现,可以在这里找到。
dataset = Dataset(paths = [str(x) for x in Path('data/original').glob('**/*.txt')][50:70], tokenizer=tokenizer)
loader = torch.utils.data.DataLoader(dataset, batch_size=8)
test_dataset = Dataset(paths = [str(x) for x in Path('data/original').glob('**/*.txt')][10:12], tokenizer=tokenizer)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4)5、模型
接下来我们必须定义我们的模型,是的,你猜对了,我们在这里也使用 HuggingFace。 它提供了一个令人惊叹的界面,使训练变得非常容易。
from transformers import DistilBertForMaskedLM, DistilBertConfig
config = DistilBertConfig(
vocab_size=30000,
max_position_embeddings=514
)
model = DistilBertForMaskedLM(config)我们使用学习率为 1e-4 的 AdamW 作为优化器并训练 10 个 epoch(这已经花费了很多时间)。 在下面,你可以找到我的训练过程,这是非常基础的代码。
epochs = 10
for epoch in range(epochs):
loop = tqdm(loader, leave=True)
# set model to training mode
model.train()
losses = []
# iterate over dataset
for batch in loop:
optim.zero_grad()
# copy input to device
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# predict
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
# update weights
loss = outputs.loss
loss.backward()
optim.step()
# output current loss
loop.set_description(f'Epoch {epoch}')
loop.set_postfix(loss=loss.item())
losses.append(loss.item())
print("Mean Training Loss", np.mean(losses))
losses = []
loop = tqdm(test_loader, leave=True)
# set model to evaluation mode
model.eval()
# iterate over dataset
for batch in loop:
# copy input to device
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# predict
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
# update weights
loss = outputs.loss
# output current loss
loop.set_description(f'Epoch {epoch}')
loop.set_postfix(loss=loss.item())
losses.append(loss.item())
print("Mean Test Loss", np.mean(losses))6、测试
之后,我们可以运行一些健全性测试来查看模型对某些屏蔽标记的预测。 我们可以再次使用 HuggingFace 创建一个管道,它将为我们处理预测。 我们使用 fill.tokenizer.mask_token 将 MSK 令牌添加到输入中。
from transformers import pipeline
fill = pipeline("fill-mask", model='distilbert', config=config, tokenizer='distilbert_tokenizer')
fill(f'It seems important to tackle the climate {fill.tokenizer.mask_token}.')此外,我们得到了以下带有置信水平的预测,这些预测似乎都是这句话中合理的下一个标记。
- change: 0.19
- crisis: 0.12
- issues: 0.05
- issue: 0.04
7、结束语
总而言之,考虑到基础设施的限制,结果相当不错。 显然,我们没有达到与原始模型相当的性能,但如果确实想在应用程序中使用它,你可以使用预训练模型(请参考这里)。
原文链接:DistilBERT模型训练实战 - BimAnt