经过漫长的思考,我依然无法为昨天的第二个问题找到合适的解决方法。然后今天依然对整体的放着进行思考,找出规律再去写代码。考虑SNN网络:
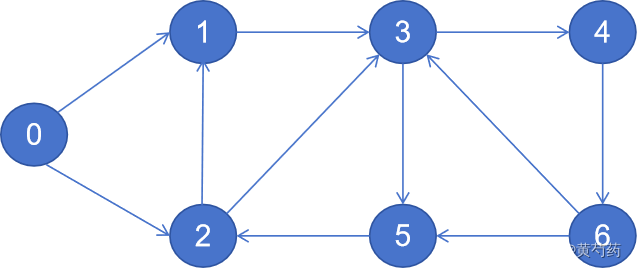
那么他的邻接表gabal_adj:
| 0 | 1 | 2 |
| 1 | 3 | |
| 2 | 1 | 3 |
| 3 | 4 | 5 |
| 4 | 6 | |
| 5 | 2 | |
| 6 | 5 | 3 |
假设有两个进程模拟,第a个进程上的SNN拓扑:
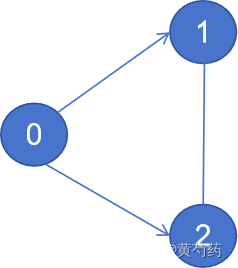
则他的邻接adj1表应该为
| 0 | 1 | 2 |
| 1 | ||
| 2 | 1 | |
| 3 | ||
| 4 | ||
| 5 | 2 | |
| 6 |
标红意味着他不在此进程。第b个进程上的拓扑
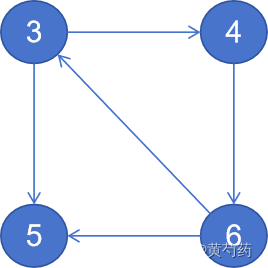
则他的邻接表的表示adj2为
| 0 | ||
| 1 | 3 | |
| 2 | 3 | |
| 3 | 4 | 5 |
| 4 | 6 | |
| 5 | ||
| 6 | 5 | 3 |
将这些数据放在一起有:

从以上的三张表中很容易得到神经元需要传递给的后突触和神经元,也可以识别是否传递给其它进程,但是需要一直维持一个全局的邻接表,感觉代价有点大。但换一种思考,只存储每个神经元的后神经元的个数,即

根据一定adj1[i].size()<=global_adj[i]. 很容易可以看出
当一个神经元i是本地神经元时,且adj1[i].size()<global_adj[i].size()。那么这个脉冲就一定是要发送给其他进程的。
当一个神经元i是本地神经元时,且adj1[i].size()=global_adj[i].size(),那么一定是本地脉冲
当一个神经元i不是本地神经元,adj1[i].size()=global_adj[i].size(),远程脉冲
当一个神经元i不是本地神经元,adj1[i].size()<global_adj[i].size(),远程脉冲。
由此我们就可以解决之前提出的问题。







![【redis】[windows]redis安装以及配置等相关](https://img-blog.csdnimg.cn/direct/a984911a0f374ead851a24a2d4395ae5.png)