改造
修改python3中的http.server.SimpleHTTPRequestHandler,实现简单的文件上传下载服务
simple_http_file_server.py:
# !/usr/bin/env python3
import datetime
import email
import html
import http.server
import io
import mimetypes
import os
import posixpath
import re
import shutil
import sys
import urllib.error
import urllib.parse
import urllib.request
import socket
from http import HTTPStatus
import threading
import contextlib
__version__ = "0.1"
__all__ = ["MySimpleHTTPRequestHandler"]
class MySimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):
server_version = "SimpleHTTP/" + __version__
extensions_map = _encodings_map_default = {
'.gz': 'application/gzip',
'.Z': 'application/octet-stream',
'.bz2': 'application/x-bzip2',
'.xz': 'application/x-xz',
}
def __init__(self, *args, directory=None, **kwargs):
if directory is None:
directory = os.getcwd()
self.directory = os.fspath(directory)
super().__init__(*args, **kwargs)
def do_GET(self):
f = self.send_head()
if f:
try:
self.copyfile(f, self.wfile)
finally:
f.close()
def do_HEAD(self):
f = self.send_head()
if f:
f.close()
def send_head(self):
path = self.translate_path(self.path)
f = None
if os.path.isdir(path):
parts = urllib.parse.urlsplit(self.path)
if not parts.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(HTTPStatus.MOVED_PERMANENTLY)
new_parts = (parts[0], parts[1], parts[2] + '/',
parts[3], parts[4])
new_url = urllib.parse.urlunsplit(new_parts)
self.send_header("Location", new_url)
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
ctype = self.guess_type(path)
if path.endswith("/"):
self.send_error(HTTPStatus.NOT_FOUND, "File not found")
return None
try:
f = open(path, 'rb')
except OSError:
self.send_error(HTTPStatus.NOT_FOUND, "File not found")
return None
try:
fs = os.fstat(f.fileno())
# Use browser cache if possible
if ("If-Modified-Since" in self.headers
and "If-None-Match" not in self.headers):
# compare If-Modified-Since and time of last file modification
try:
ims = email.utils.parsedate_to_datetime(self.headers["If-Modified-Since"])
except (TypeError, IndexError, OverflowError, ValueError):
# ignore ill-formed values
pass
else:
if ims.tzinfo is None:
# obsolete format with no timezone, cf.
# https://tools.ietf.org/html/rfc7231#section-7.1.1.1
ims = ims.replace(tzinfo=datetime.timezone.utc)
if ims.tzinfo is datetime.timezone.utc:
# compare to UTC datetime of last modification
last_modif = datetime.datetime.fromtimestamp(
fs.st_mtime, datetime.timezone.utc)
# remove microseconds, like in If-Modified-Since
last_modif = last_modif.replace(microsecond=0)
if last_modif <= ims:
self.send_response(HTTPStatus.NOT_MODIFIED)
self.end_headers()
f.close()
return None
self.send_response(HTTPStatus.OK)
self.send_header("Content-type", ctype)
self.send_header("Content-Length", str(fs[6]))
self.send_header("Last-Modified",
self.date_time_string(fs.st_mtime))
self.end_headers()
return f
except:
f.close()
raise
def list_directory(self, path):
try:
list_dir = os.listdir(path)
except OSError:
self.send_error(HTTPStatus.NOT_FOUND, "No permission to list_dir directory")
return None
list_dir.sort(key=lambda a: a.lower())
r = []
try:
display_path = urllib.parse.unquote(self.path, errors='surrogatepass')
except UnicodeDecodeError:
display_path = urllib.parse.unquote(path)
display_path = html.escape(display_path, quote=False)
enc = sys.getfilesystemencoding()
form = """
<h1>文件上传</h1>\n
<form ENCTYPE="multipart/form-data" method="post">\n
<input name="file" type="file"/>\n
<input type="submit" value="upload"/>\n
</form>\n"""
title = 'Directory listing for %s' % display_path
r.append('<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" '
'"http://www.w3.org/TR/html4/strict.dtd">')
r.append('<html>\n<head>')
r.append('<meta http-equiv="Content-Type" '
'content="text/html; charset=%s">' % enc)
r.append('<title>%s</title>\n</head>' % title)
r.append('<body>%s\n<h1>%s</h1>' % (form, title))
r.append('<hr>\n<ul>')
for name in list_dir:
fullname = os.path.join(path, name)
displayname = linkname = name
# Append / for directories or @ for symbolic links
if os.path.isdir(fullname):
displayname = name + "/"
linkname = name + "/"
if os.path.islink(fullname):
displayname = name + "@"
# Note: a link to a directory displays with @ and links with /
r.append('<li><a href="%s">%s</a></li>' % (urllib.parse.quote(linkname, errors='surrogatepass'),
html.escape(displayname, quote=False)))
r.append('</ul>\n<hr>\n</body>\n</html>\n')
encoded = '\n'.join(r).encode(enc, 'surrogate escape')
f = io.BytesIO()
f.write(encoded)
f.seek(0)
self.send_response(HTTPStatus.OK)
self.send_header("Content-type", "text/html; charset=%s" % enc)
self.send_header("Content-Length", str(len(encoded)))
self.end_headers()
return f
def translate_path(self, path):
# abandon query parameters
path = path.split('?', 1)[0]
path = path.split('#', 1)[0]
# Don't forget explicit trailing slash when normalizing. Issue17324
trailing_slash = path.rstrip().endswith('/')
try:
path = urllib.parse.unquote(path, errors='surrogatepass')
except UnicodeDecodeError:
path = urllib.parse.unquote(path)
path = posixpath.normpath(path)
words = path.split('/')
words = filter(None, words)
path = self.directory
for word in words:
if os.path.dirname(word) or word in (os.curdir, os.pardir):
# Ignore components that are not a simple file/directory name
continue
path = os.path.join(path, word)
if trailing_slash:
path += '/'
return path
def copyfile(self, source, outputfile):
shutil.copyfileobj(source, outputfile)
def guess_type(self, path):
base, ext = posixpath.splitext(path)
if ext in self.extensions_map:
return self.extensions_map[ext]
ext = ext.lower()
if ext in self.extensions_map:
return self.extensions_map[ext]
guess, _ = mimetypes.guess_type(path)
if guess:
return guess
return 'application/octet-stream'
def do_POST(self):
r, info = self.deal_post_data()
self.log_message('%s, %s => %s' % (r, info, self.client_address))
enc = sys.getfilesystemencoding()
res = [
'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" '
'"http://www.w3.org/TR/html4/strict.dtd">',
'<html>\n<head>',
'<meta http-equiv="Content-Type" content="text/html; charset=%s">' % enc,
'<title>%s</title>\n</head>' % "Upload Result Page",
'<body><h1>%s</h1>\n' % "Upload Result"
]
if r:
res.append('<p>SUCCESS: %s</p>\n' % info)
else:
res.append('<p>FAILURE: %s</p>' % info)
res.append('<a href=\"%s\">back</a>' % self.headers['referer'])
res.append('</body></html>')
encoded = '\n'.join(res).encode(enc, 'surrogate escape')
f = io.BytesIO()
f.write(encoded)
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
if f:
self.copyfile(f, self.wfile)
f.close()
def deal_post_data(self):
content_type = self.headers['content-type']
if not content_type:
return False, "Content-Type header doesn't contain boundary"
boundary = content_type.split("=")[1].encode()
remain_bytes = int(self.headers['content-length'])
line = self.rfile.readline()
remain_bytes -= len(line)
if boundary not in line:
return False, "Content NOT begin with boundary"
line = self.rfile.readline()
remain_bytes -= len(line)
fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())
if not fn:
return False, "Can't find out file name..."
path = self.translate_path(self.path)
fn = os.path.join(path, fn[0])
line = self.rfile.readline()
remain_bytes -= len(line)
line = self.rfile.readline()
remain_bytes -= len(line)
try:
out = open(fn, 'wb')
except IOError:
return False, "Can't create file to write, do you have permission to write?"
preline = self.rfile.readline()
remain_bytes -= len(preline)
while remain_bytes > 0:
line = self.rfile.readline()
remain_bytes -= len(line)
if boundary in line:
preline = preline[0:-1]
if preline.endswith(b'\r'):
preline = preline[0:-1]
out.write(preline)
out.close()
return True, "File '%s' upload success!" % fn
else:
out.write(preline)
preline = line
return False, "Unexpect Ends of data."
def _get_best_family(*address):
infos = socket.getaddrinfo(
*address,
type=socket.SOCK_STREAM,
flags=socket.AI_PASSIVE,
)
family, type, proto, canonname, sockaddr = next(iter(infos))
return family, sockaddr
def serve_forever(port=8000, bind=None, directory="."):
"""
This runs an HTTP server on port 8000 (or the port argument).
"""
# ensure dual-stack is not disabled; ref #38907
class DualStackServer(http.server.ThreadingHTTPServer):
def server_bind(self):
# suppress exception when protocol is IPv4
with contextlib.suppress(Exception):
self.socket.setsockopt(
socket.IPPROTO_IPV6, socket.IPV6_V6ONLY, 0)
return super().server_bind()
def finish_request(self, request, client_address):
self.RequestHandlerClass(request, client_address, self,
directory=directory)
HandlerClass=MySimpleHTTPRequestHandler
ServerClass=DualStackServer
protocol="HTTP/1.0"
ServerClass.address_family, addr = _get_best_family(bind, port)
HandlerClass.protocol_version = protocol
with ServerClass(addr, HandlerClass) as httpd:
host, port = httpd.socket.getsockname()[:2]
url_host = f'[{host}]' if ':' in host else host
print(
f"Serving HTTP on {host} port {port} "
f"(http://{url_host}:{port}/) ..."
)
try:
httpd.serve_forever()
except KeyboardInterrupt:
print("\nKeyboard interrupt received, exiting.")
sys.exit(0)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--bind', '-b', metavar='ADDRESS',
help='specify alternate bind address '
'(default: all interfaces)')
parser.add_argument('--directory', '-d', default=os.getcwd(),
help='specify alternate directory '
'(default: current directory)')
parser.add_argument('port', action='store', default=8000, type=int,
nargs='?',
help='specify alternate port (default: 8000)')
args = parser.parse_args()
# 在主线程中执行
# serve_forever(
# port=args.port,
# bind=args.bind,
# directory = args.directory
# )
# 在子线程中执行,这样主线程可以执行异步工作
thread1 = threading.Thread(name='t1',target= serve_forever,
kwargs={
"port" : args.port,
"bind" : args.bind,
"directory" : args.directory
}
)
thread1.start()
# thread1.join()
使用帮助:
>python3 simple_http_file_server.py --help
usage: simple_http_file_server.py [-h] [--cgi] [--bind ADDRESS] [--directory DIRECTORY] [port]positional arguments:
port specify alternate port (default: 8000)optional arguments:
-h, --help show this help message and exit
--cgi run as CGI server
--bind ADDRESS, -b ADDRESS
specify alternate bind address (default: all interfaces)
--directory DIRECTORY, -d DIRECTORY
specify alternate directory (default: current directory)
使用示例:
>python3 simple_http_file_server.py -d ~ 12345
Serving HTTP on :: port 12345 (http://[::]:12345/) ...
::ffff:127.0.0.1 - - [30/Nov/2023 09:35:06] "GET / HTTP/1.1" 200 -。。。
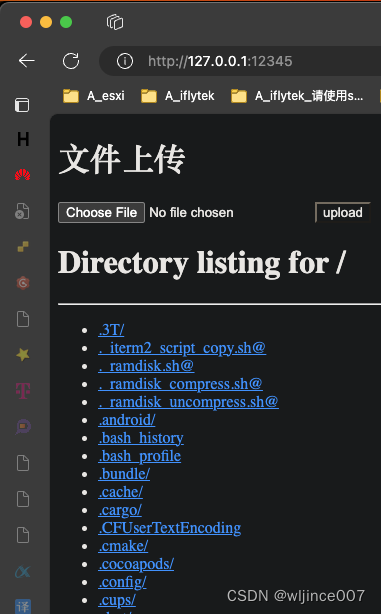
访问:
浏览器中访问:http://127.0.0.1:12345/
参考:
Python3 实现简单HTTP服务器(附带文件上传)_python3 -m http.server-CSDN博客