文章目录
- 散列函数的构造方法
- 直接定址法
- ==除留余数法==
- 散列表的查找
- 1.开放地址法
- 线性探测法
- 二次探测法
- 伪随机探测法
- 2.链地址法(拉链法)
- 散列表的查找效率
散列函数的构造方法
散列存储
选取某个函数,依该函数按关键字计算元素的存储位置。
Loc(i)= H(keyi)
冲突:不同的关键码映射到同一个散列地址
key1不等于k2,但是H(key1)= H(key2)
使用散列表要解决的两个问题:
1)构造好的散列函数
(a)所选函数尽可能的简单,以便提高转换速度。
(b)所选函数对关键码计算出的地址,应在散列地址集中致均匀分布,以减少空间的浪费。
2)制定好一个好的解决冲突的方法
查找时,如果从散列表计算出的地址中查不到关键码,则应当依据解决冲突的规则,有规律的查询其他相关单元。
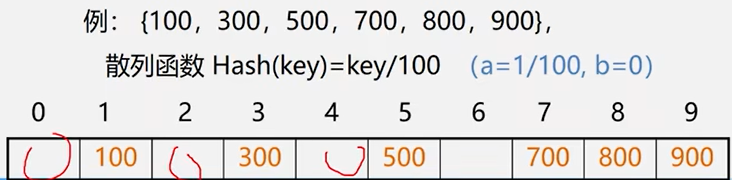
直接定址法

优点:以关键码key的某个线性函数值为散列地址,不会产生冲突。
缺点:要占用连续的空间,空间效率低。
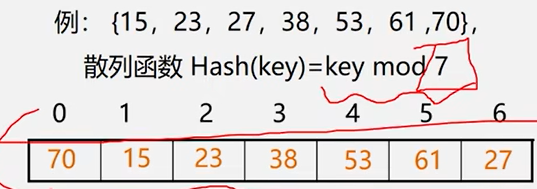
除留余数法

如何选择合适的p?
设表长为m,取p<=m为质数
散列表的查找
处理冲突的方法:
1.开放地址法
基本思想:有冲突就去寻找下一个空的散列地址,只要散列表足够大,空的散列表地址总能找到,并将数据存入。


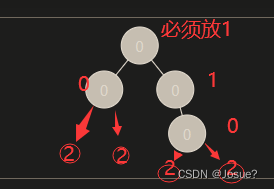
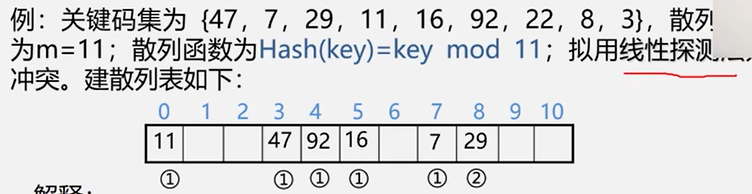
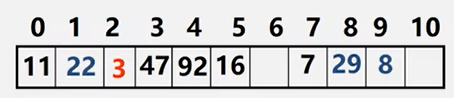
线性探测法
一旦冲突,就找下一个地址,直到找到空地址存入。
二次探测法

伪随机探测法
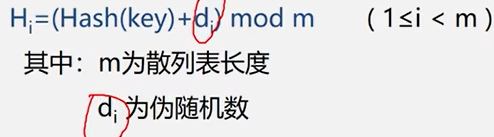
2.链地址法(拉链法)
相同的散列地址的记录链成一个单链表
m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构。
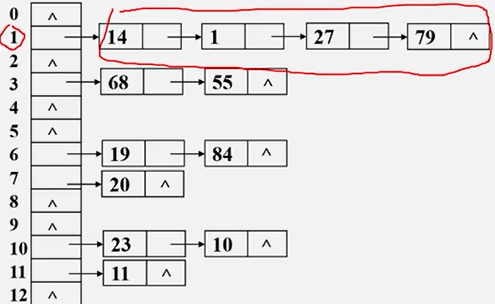
这里就是将余数相同的都存在一个链表中。
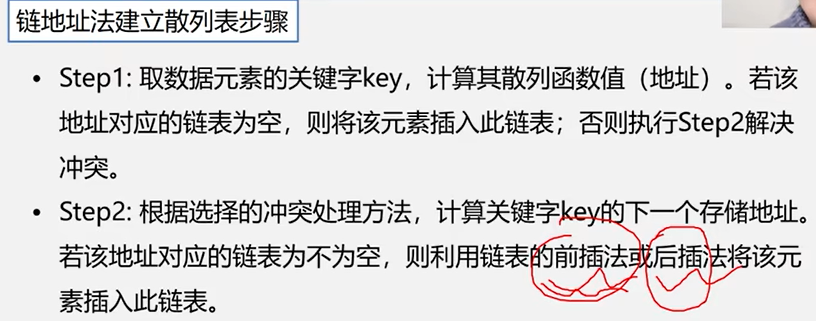
优点:非同义词不会冲突,无“聚集”现象。
链表上的结点空间动态申请,更适合表长不确定的情况下。
3.再散列法(双散列函数法)
4.建立一个公共溢出区
散列表的查找效率