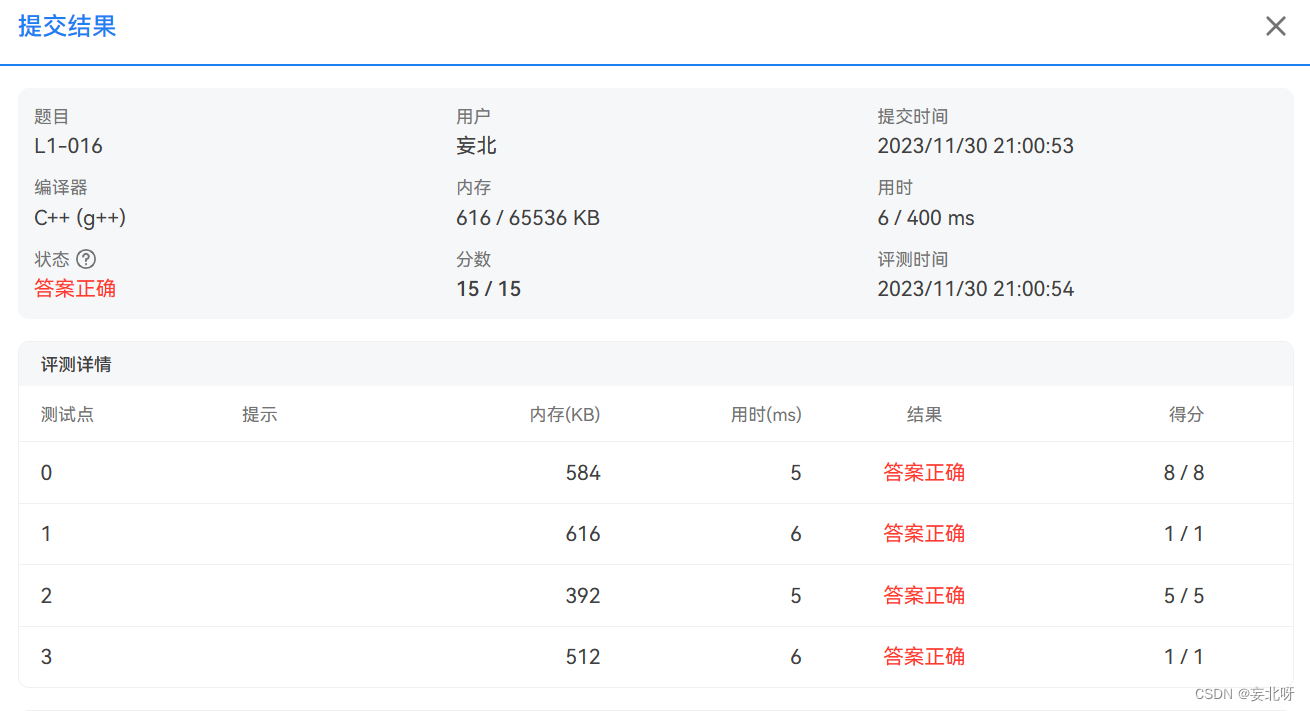
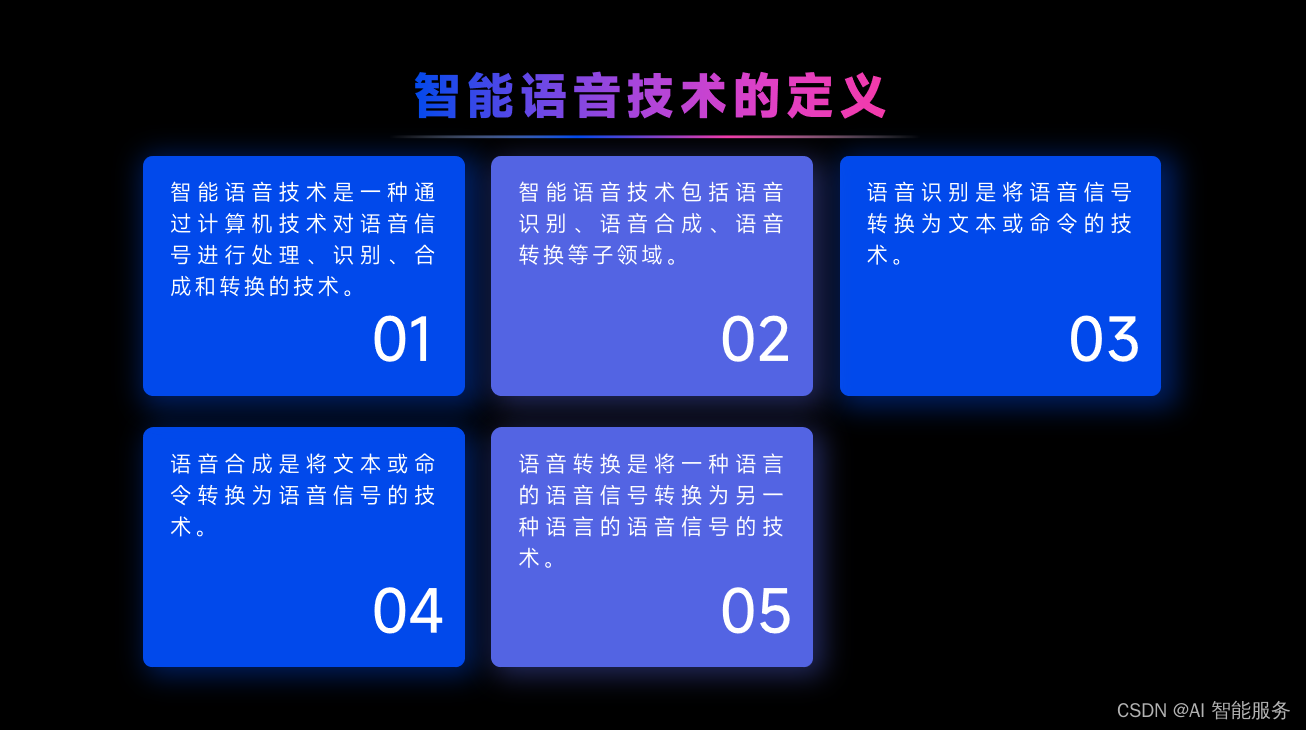
ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是一种将人类语音转换为文本的技术。ASR 系统可以处理实时音频流或已录制的音频文件,并将其转换为文本。它是一种自然语言处理技术,广泛应用于许多领域,包括电话语音助手、语音转文本、语音搜索等。
1.定义和分类
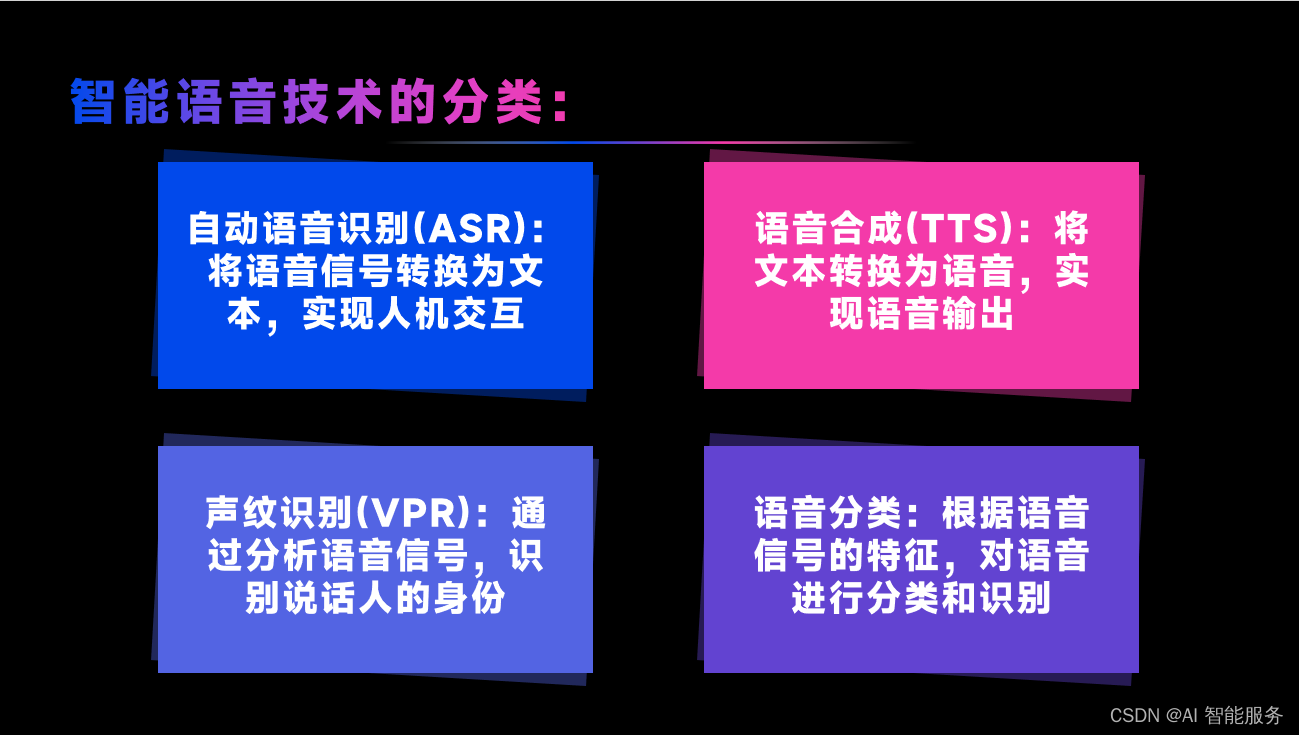
2.ASR的流程和技术框架
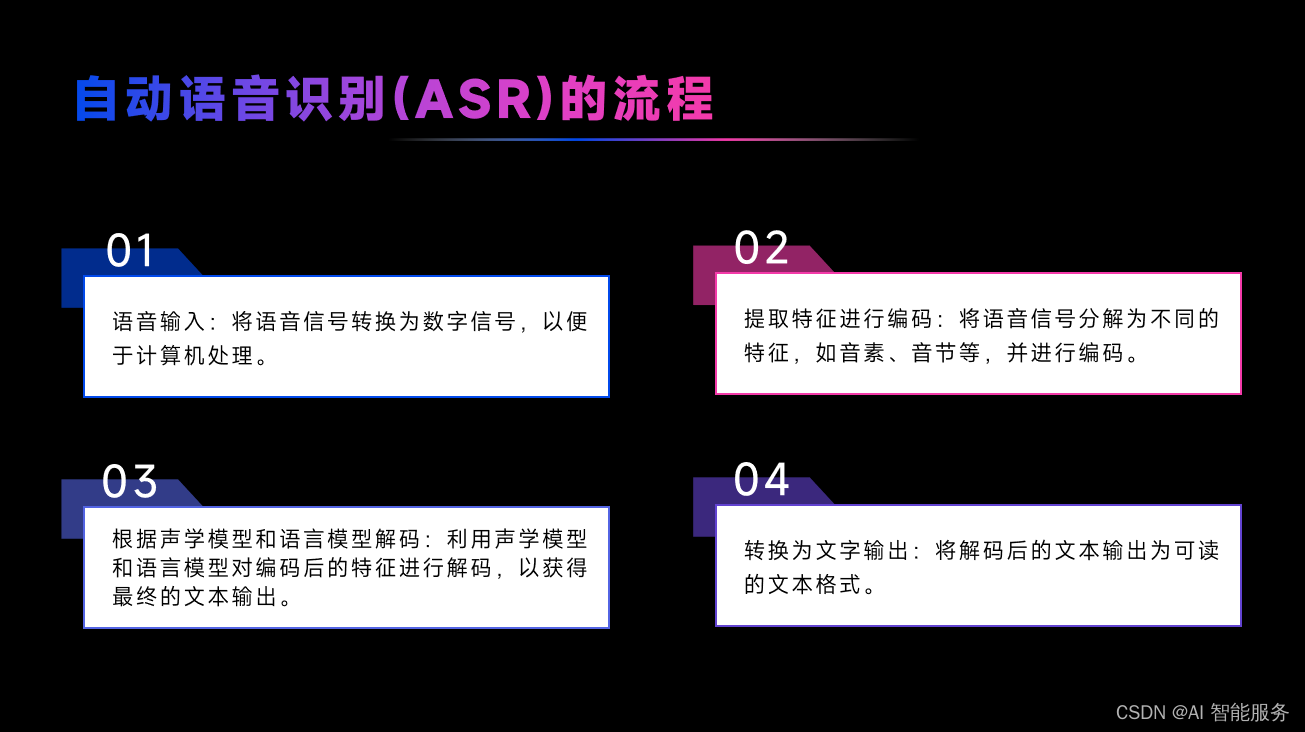
ASR 的工作原理包括以下步骤:
- 预处理:对输入的音频信号进行预处理,包括去除噪声、标准化音频信号等操作。
- 特征提取:从预处理的音频信号中提取特征向量,这些特征向量可以反映语音的韵律、音调、音色等特征。
- 声学建模:利用声学模型对特征向量进行建模,将特征向量映射到音素级别,进而映射到单词级别。
- 语言模型:利用语言模型对语音转换成的文本进行语言约束,使输出的文本更加符合语言习惯。
- 识别:将经过声学建模和语言模型处理的特征向量与预先训练好的词库进行比对,输出最匹配的文本。
- 后处理:对输出的文本进行语法校正、标点符号处理等后处理操作,使其更加符合人类语言的表达习惯。

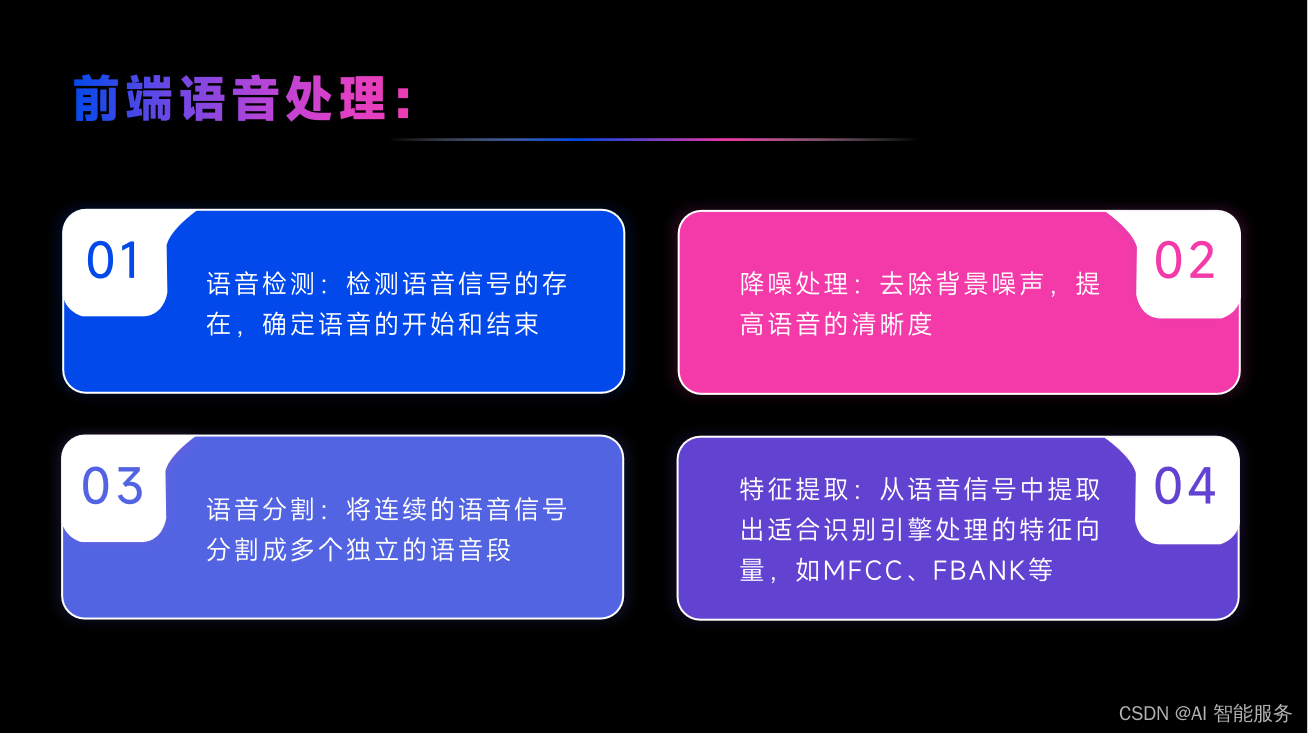
3.ASR模型组成和前端语音处理
ASR 技术需要大量的数据进行训练,以不断提高准确度和鲁棒性。近年来,随着深度学习技术的不断发展,ASR 系统也在逐步采用深度神经网络等方法进行优化和改进。

4.效果评测与提升方法
ASR系统的性能可以通过多种指标进行评估,其中最常用的指标包括词错误率(WER)、字符错误率(CER)、句子错误率(SER)和识别时间等。
词错误率(WER)是衡量ASR系统性能最重要的指标之一,它指的是ASR系统在识别过程中产生的单词错误数量与参考文本中单词总数量的比例。WER越低,说明ASR系统的性能越好。
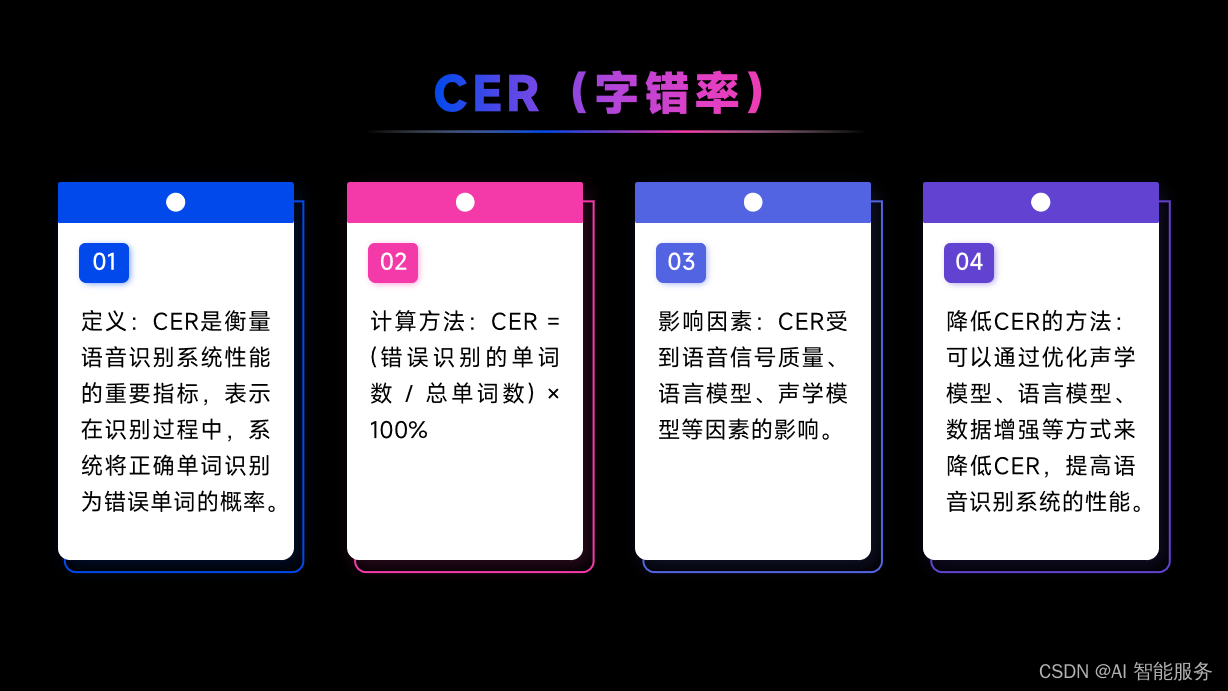
字符错误率(CER)是指ASR系统在识别过程中产生的字符错误数量与参考文本中字符总数的比例。CER越低,说明ASR系统在识别过程中产生的单个字符错误越少。
句子错误率(SER)是指ASR系统在识别一句话时产生的错误数量与参考文本中句子总数的比例。SER越低,说明ASR系统在识别整个句子时的错误越少。
识别时间是指ASR系统对一段语音进行识别所需的时间。识别时间越短,说明ASR系统的实时性越好。
除了以上指标外,ASR系统的性能还可以通过识别率、鲁棒性、可扩展性和训练效率等。这些指标可以用来评估ASR系统在不同方面的性能表现。
4.1语音识别评测指标


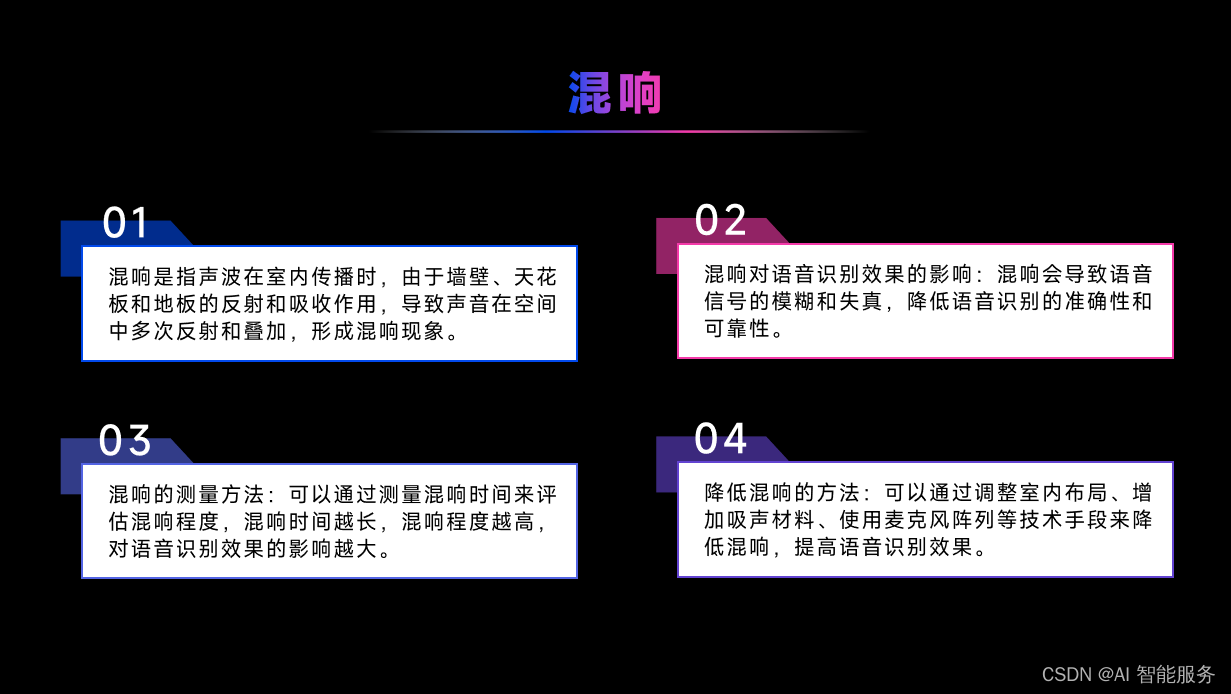
4.2语音识别效果影响因素


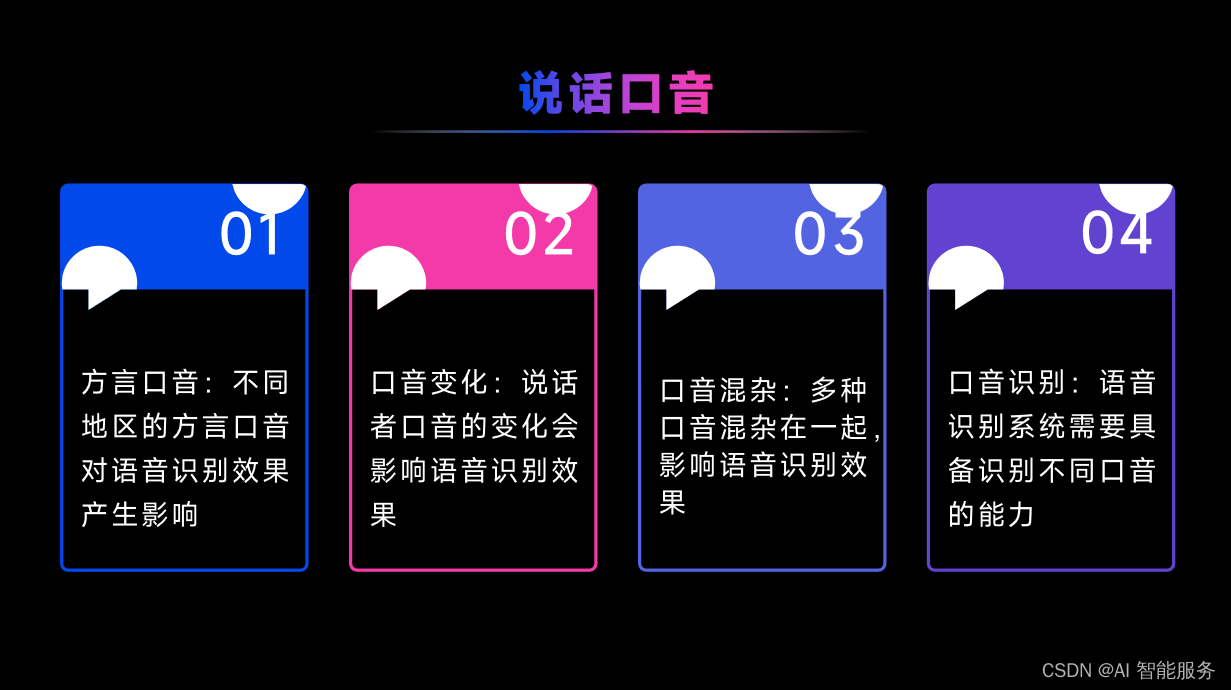
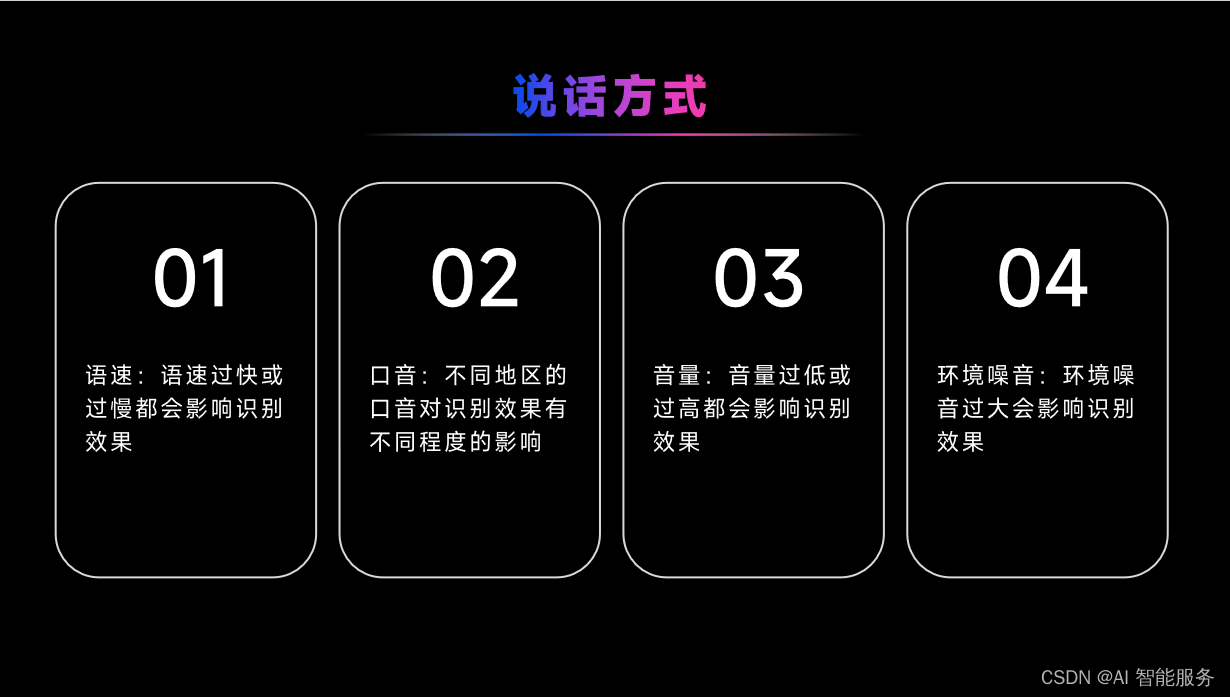
4.3语音识别效果提升方法

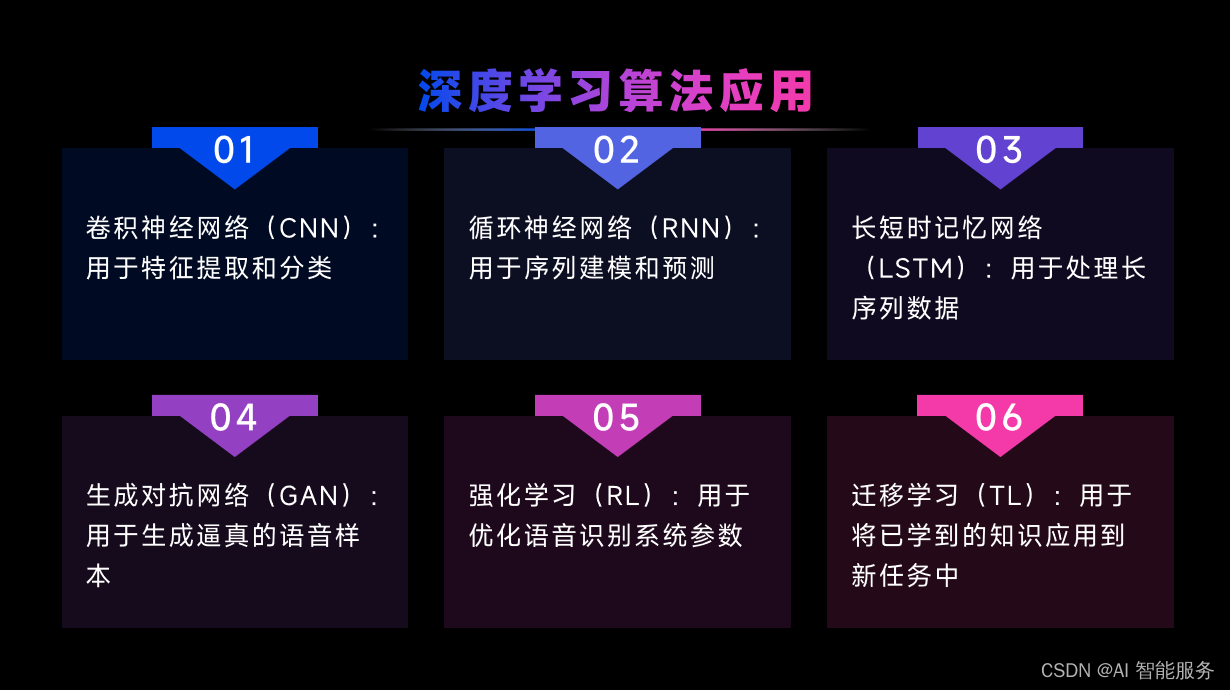

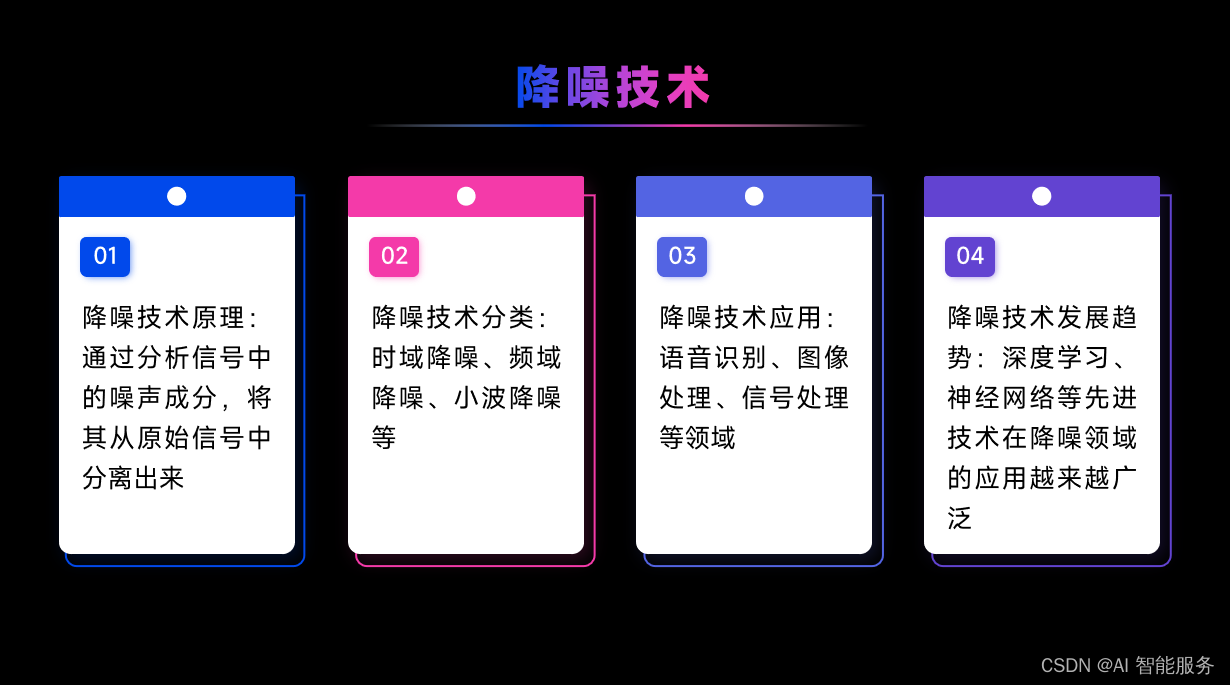
5.ASR的应用
语音识别技术的应用非常广泛,以下是其中几个具体的领域:
- 智能家居:语音识别技术可以在家庭中实现人机交互,实现家庭环境的智能化控制,包括灯光、音响、空调等家电设备的控制,提高人们的生活品质。例如,使用“嘿,小度,把客厅电视打开”可以迅速打开电视。
- 智能交通:语音识别技术可以用于智能驾驶和智能交通控制,例如语音导航、语音识别支付等。在保证驾驶安全的前提下,司机可以通过说出指令来控制车辆,而不需要分心操作屏幕或按钮。
- 智能医疗:语音识别技术可以用于医疗记录、医学诊断、医学研究和医学教育等方面。医生可以通过语音快速记录病历和诊断结果,从而更好地为病人提供诊疗服务。
- 智能客服:语音识别技术也可以用于客户服务,尤其是针对语言不同的客户。客户可以通过说出指令来解决问题,减少语言沟通的障碍,提高客户满意度。
- 语音助手:如Siri、Google Assistant等,用户可以通过语音与语音助手进行交互,进行信息查询、日程安排、拨打电话等操作,大大提高了用户的使用体验。
- 语音翻译:语音翻译是将语音转化为文字信息,并实现不同语言之间的翻译,在旅游、商务等领域具有广泛应用前景。
- 智能办公:在办公场景下,语音识别技术可以实现语音转文字、远程会议、文件传输等功能,提高办公效率。
- 娱乐应用:在娱乐领域,语音识别技术也被广泛应用于游戏、音乐播放器、智能音箱等方面,为用户带来更加智能化的娱乐体验。
随着技术的不断发展,语音识别技术的应用领域会越来越广泛,为人们的生活带来更多便利和惊喜。
基础课15——语音合成-CSDN博客文章浏览阅读160次,点赞6次,收藏4次。TTS是语音合成技术的简称,也称为文语转换或语音到文本。它是指将文本转换为语音信号,并通过语音合成器生成可听的语音。TTS技术可以用于多种应用,例如智能语音助手、语音邮件、语音新闻、有声读物等。https://blog.csdn.net/2202_75469062/article/details/134634054?spm=1001.2014.3001.5501