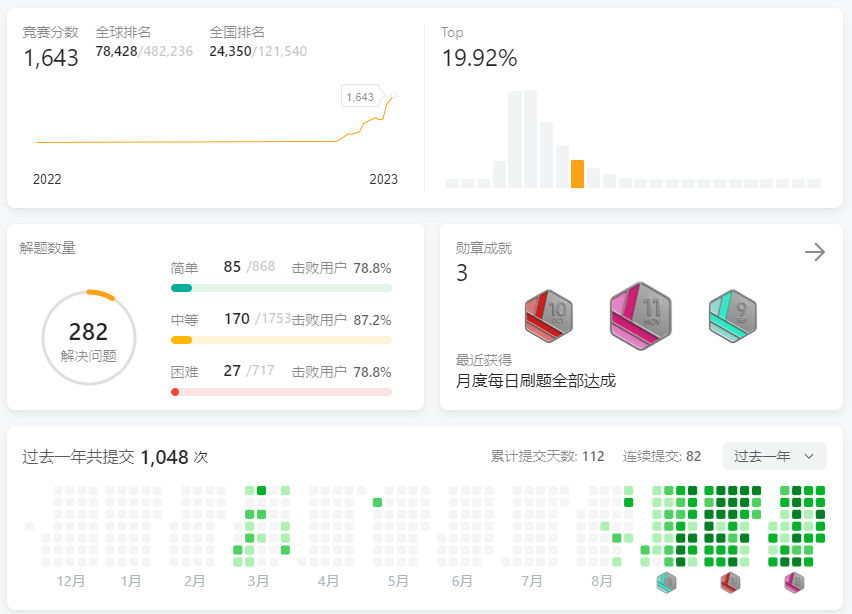
Spring三级缓存
Spring三级缓存是什么?
一级缓存:单例池。存放的是完整的Bean对象。经过完整的生命周期。二级缓存:存放需要提前暴露的Bean对象。也就不完整的Bean对象。需要提前暴露就是指,可能会被循环依赖。(这里可能需要用代理对象,替换原始对象。),保存出现循环依赖的Bean,需要提前暴露给其他Bean去依赖且还没有经过完整的生命周期的Bean 。三级缓存:存放提前暴露的ObjectFactory。这里其实是把提前暴露的对象又封装了一层。()

解决了什么?
三级缓存的目的是为了解决
循环依赖的问题。并解决了代理对象(AOP)循环依赖的问题
源码执行过程
准备配置文件
有两个Service对象,并且相互依赖着对方。
<bean name="serviceA" class="com.mfyuan.service.ServiceA">
<property name="serviceB" ref="serviceB"/>
</bean>
<bean name="serviceB" class="com.mfyuan.service.ServiceB" >
<property name="serviceA" ref="serviceA"/>
</bean>
执行过程
-
通过
beanDefinitionNames来对所有bean的定义具体化。(把BeanDefinition转换成Bean对象)。 -
AbstractBeanFactory#getBean("serviceA")在容器中获取ServiceA。 -
AbstractBeanFactory#doGetBean("serviceA")实例获取ServiceA的方法。 -
DefaultSingletonBeanRegistry#getSingleton("serviceA")。记住这个方法后面经常用到。他是先从一级缓存-》二级缓存-》三级缓存依次已经判断。因为这个时候我们缓存中不存在ServiceA这个Bean,所以这里是获取不到的。所以继续往下走。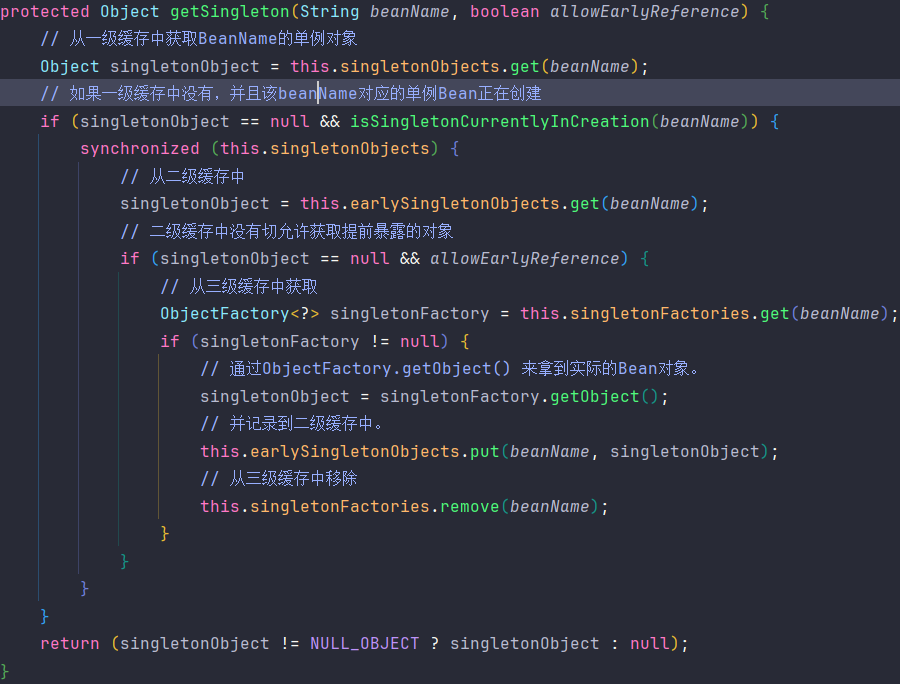
-
DefaultSingletonBeanRegistry#getSingleton("serviceA",new ObjectFactory())。很眼熟,没错它是跟上面同样的方法名,只不过是重载方法。关键的是第二个参数ObjectFactory对象工厂。他是一个匿名内部类在高版本中也可以是lambda表达式。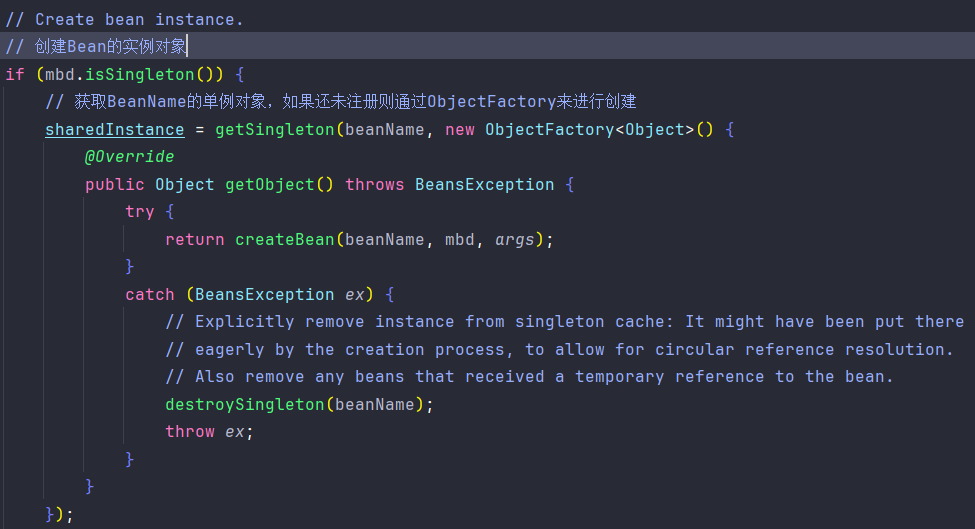
-
首先从
一级缓存中获取ServiceA,这里显然也是获取不到的。所以通过ObjectFactory来创建对象。而我们的ObjectFactory中只有一个方法就是createBean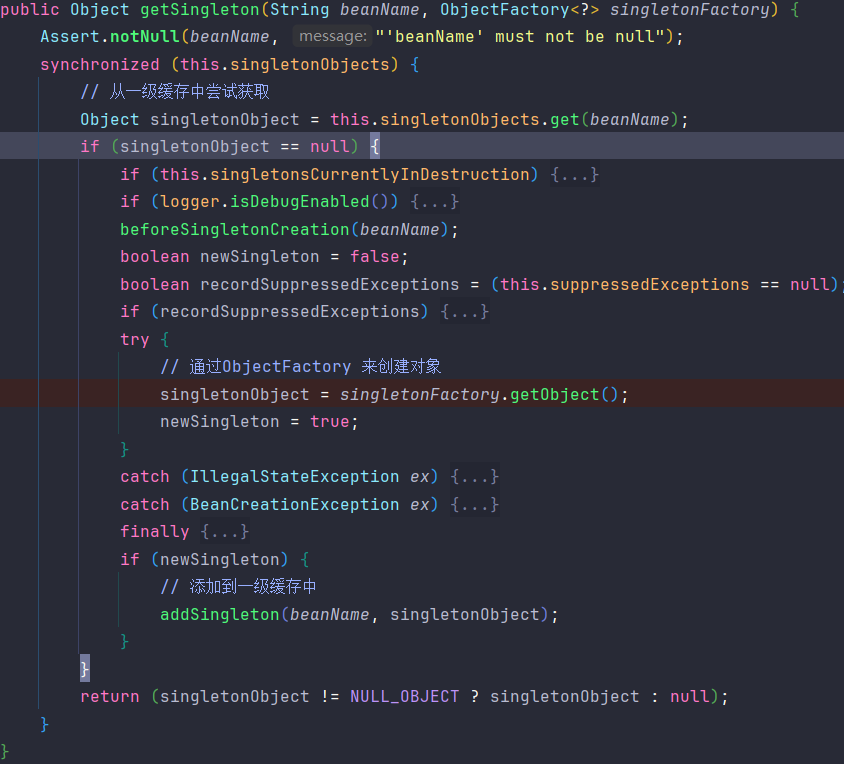
-
AbstractAutowireCapableBeanFactory#doCreateBean("serviceA")实际创建Bean的方法。 -
AbstractAutowireCapableBeanFactory#createBeanInstance("serviceA")。这个时候已经把ServiceA这个Bean实例化好了,但是未初始化,且没有放入到容器中。 -
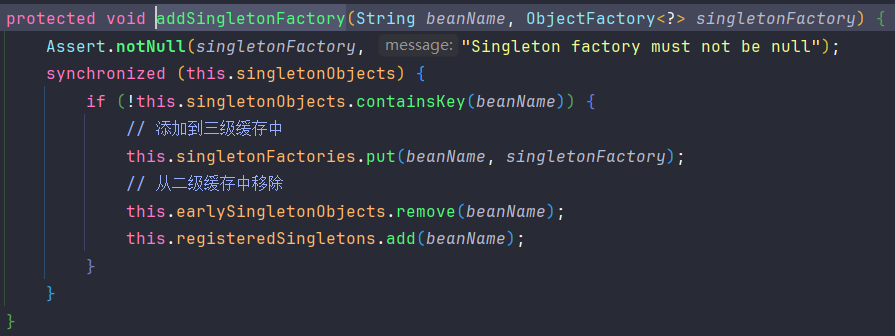
判断这个Bean是否需要提前暴露,如果需要。则将原始对象包装成
()->getEarlyBeanReference("serviceA", mbd, bean)放入三级缓存中。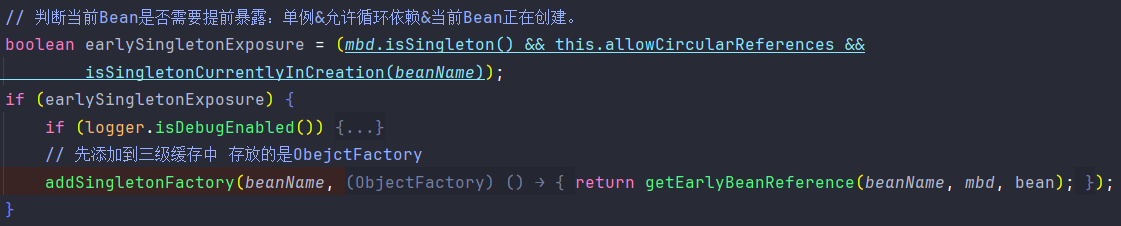
-
AbstractAutowireCapableBeanFactory#populateBean("serviceA"),对serviceA进行属性赋值,也就是初始化。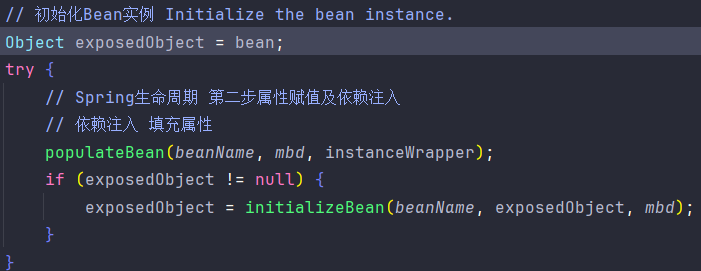
-
AbstractAutowireCapableBeanFactory#applyPropertyValues("serviceA", mbd, bw, pvs)。判断ServiceA是否依赖其他Bean,这里因为依赖ServiceB,所以会进入以下步骤。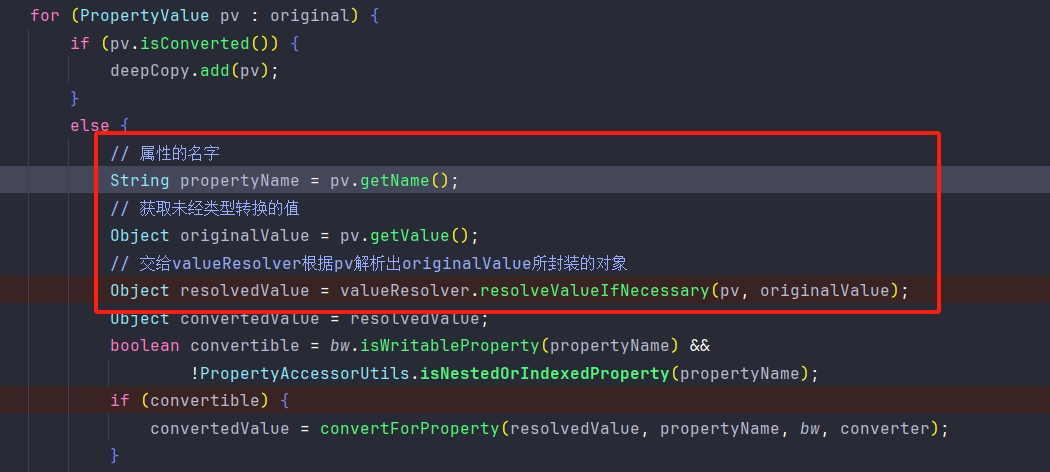
12.主要是BeanDefinitionValueResolver#resolveValueIfNecessary("serviceB", originalValue);。这里的pv就是我们的serviceB了。然后去判断ServiceB是否还依赖其他Bean。

-
BeanDefinitionValueResolver#resolveReference("serviceB")。这里又看到一个很熟悉的方法getBean("serviceB")也就是我们的步骤2;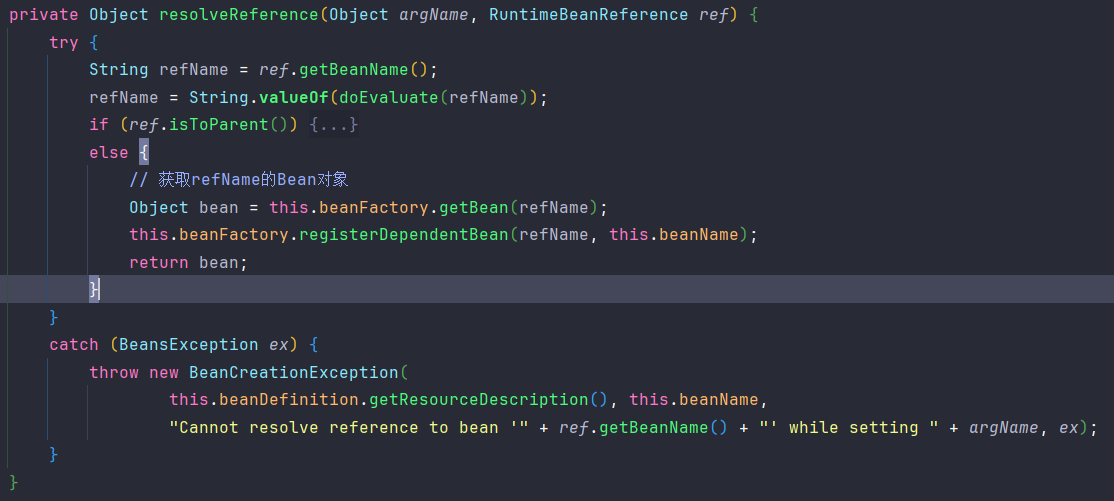
-
serviceB与serviceA一样的步骤这里就省略详细过程。
getBean("serviceB")->doGetBean("serviceB")->getSingleton("serviceB")->getSingleton("serviceB",new ObjectFactory())尝试在一级缓存中获取,这里也显然拿不到serviceB->createBean("serviceB")->doCreateBean("serviceB")->createBeanInstance("serviceB")实例化完成ServiceB->addSingletonFactory(()->getEarlyBeanReference("serviceB", mbd, bean))将实例化但未初始化的ServiceB放到三级缓存中。 ->populateBean("serviceB")属性赋值 ->applyPropertyValues("serviceB")-> 因为ServiceB依赖ServiceA所以执行resolveValueIfNecessary("serviceA", originalValue)->resolveReference("serviceA")->this.beanFactory.getBean("serviceA")再次去容器中获取ServiceA又一层嵌套循环 ->doGetBean("serviceA")。
-
getSingleton("serviceA")在容器中获取ServiceA,因为serviceA已经是正在创建的了,所以是可以从三级缓存中获取到。并把ServiceA放入二级缓存。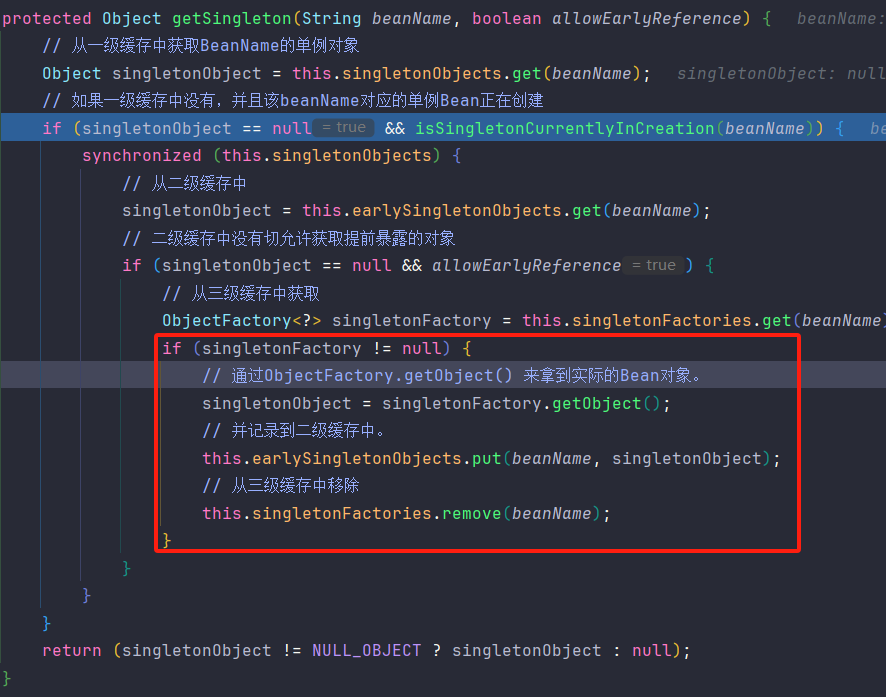
-
AbstractAutowireCapableBeanFactory#getEarlyBeanReference("serviceA")来获取最终公开的对象,因为我们的ServiceA他是不需要代理的所以直接返回原始对象即可。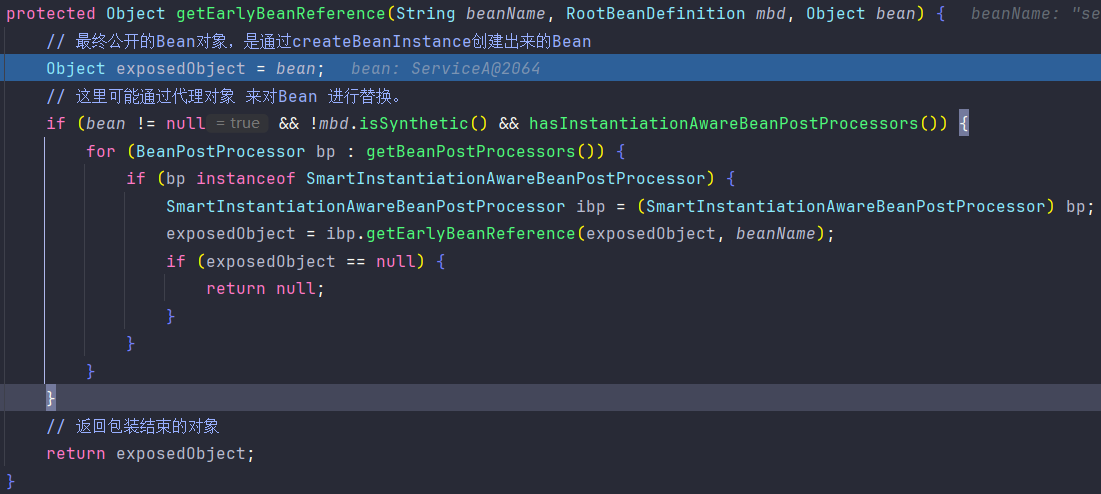
-
将
ServiceA这个不完整的对象放入到二级缓存中。 -
这里因为可以拿到
ServiceA了,并通过setPropertyValues来对ServiceB的serviceA进行赋值。
-
initializeBean("serviceB")赋值完成后,对ServiceB进行剩下的初始化操作。 -
addSingleton("serviceB", singletonObject)将ServiceB放入一级缓存中。
-
这里也就是能到到完成的
ServiceB对象了,进行执行步骤10-11中的后续步骤,也就是对ServiceA的serviceB属性进行赋值。 -
initializeBean("serviceA")赋值完成后,对ServiceA进行剩下的初始化操作。 -
addSingleton("serviceA", singletonObject)将ServiceA放入一级缓存中。 -
注意这里其实并没有结束,因为我们一个是通过步骤1中的循环才进入到这个过程的。因为
ServiceB还没有循环到所有会继续用ServiceB来进行循环。但是因为一级缓存中都存在这些信息了所以很快就结束了。
大致的过程就是这样的。可能有些绕,结合源码啃下来还是有些收货的。
思考问题
为什么不将lambda表达式放入二级缓存呢?
如果有一个
Bean同时与另外两个Bean所循环依赖呢。那是不是得从二级缓存里取两次,然后创建两次呢?这样显然是不对的。
为什么不直接将代理对象放入到二级缓存中,而是通过lambda表达式的方式存入三级缓存。
Bean被创建的时候,其实并不知道,自己是否被其他Bean所依赖(也就是不知道自己是否产生了循环依赖)。什么时候知道自己被依赖的呢? 是当其他Bean初始化的时候扫描到依赖里的时候,才能知道。
正常流程,
AOP其实是在后置处理器的去帮我们创建代理对象的。(实例化后,设置属性之后。)所有说我们不能一开始就把所有需要代理的对象,都给代理出来,只有产生循环依赖的时候才能把他代理出来,也就是需要把
AOP操作提前。二级缓存的结构是
Map<String,Object>,如果从二级缓存中取出的对象,你还得判断一下它是否需要被代理(也就是每个对象都要判断一下)。那可能就麻烦了。新增一个
Map,并且使用lambda表达式的方法,就可以很好的解决,只有在被调用且满足条件(循环依赖&&需要被代理)的时候的时候才去创建代理对象。
总结
当
Spring遇到循坏依赖时,它通过使用三级缓存以及提前暴露不完整的对象来解决问题。举例:在
A实例化完成后,Spring会将他放入到三级缓存中。A此时并没有进行初始化,当A进行属性赋值的时候,如果扫描到A对象依赖B对象的话,则又会去实例化B对象,然后再把B对象放入到三级缓存中,当B进行属性赋值的时候,发现需要依赖A对象,那么这个时候就出现了循环依赖的问题了。然后从三级缓存中取出A对象,这里的A对象被包装成了一个ObjectFactroy的一个lambda表达式,这个表达式执行后会决定是否使用代理对象还是原始对象,因为属性注入的时候肯定是需要把代理后的属性给设置进去。那么当我们拿到了处理后的A对象,会将他放入到二级缓存中,此时A并没有走完所有的生命周期,并且从三级缓存中将A对象移除。到这里B的属性就注入完成了,执行剩下的生命周期后会被放入到一级缓存中,也就是单例池。然后A的属性也可以从一级缓存中取到了,然后整个循环依赖就结束了。这三个缓存存在的目的就是为了,在容器的创建过程中,可以将某些对象提前暴露出来,从而起到打破循环的目的。