目录
- 一、早期方法:滑动窗口和特征提取
- 滑动窗口机制
- 工作原理
- 特征提取方法
- HOG(Histogram of Oriented Gradients)
- SIFT(Scale-Invariant Feature Transform)
- 二、深度学习的兴起:CNN在目标检测中的应用
- CNN的基本概念
- 卷积层
- R-CNN及其变种
- R-CNN(Regions with CNN features)
- Fast R-CNN
- Faster R-CNN
- 三、现代方法:YOLO系列
- YOLO的设计哲学
- YOLO的基本原理
- YOLO的创新点
- YOLO系列的发展
- YOLOv1
- YOLOv2 和 YOLOv3
- YOLOv4 和 YOLOv5
- 四、Transformer在目标检测中的应用
- Transformer的基础知识
- 自注意力机制
- Transformer的架构
- Transformer在目标检测中的应用
- DETR(Detection Transformer)
- Transformer与CNN的结合
- 前沿研究和趋势
- 总结
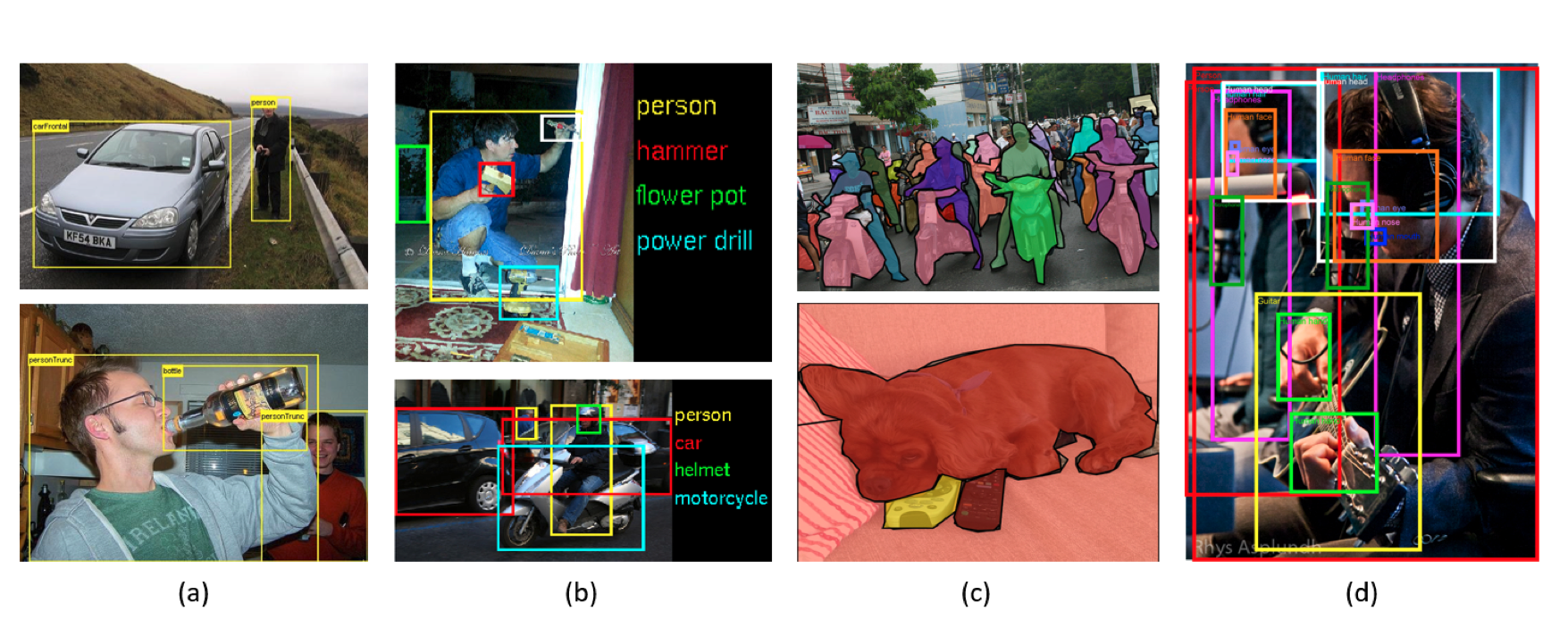
本文全面回顾了目标检测技术的演进历程,从早期的滑动窗口和特征提取方法到深度学习的兴起,再到YOLO系列和Transformer的创新应用。通过对各阶段技术的深入分析,展现了计算机视觉领域的发展趋势和未来潜力。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
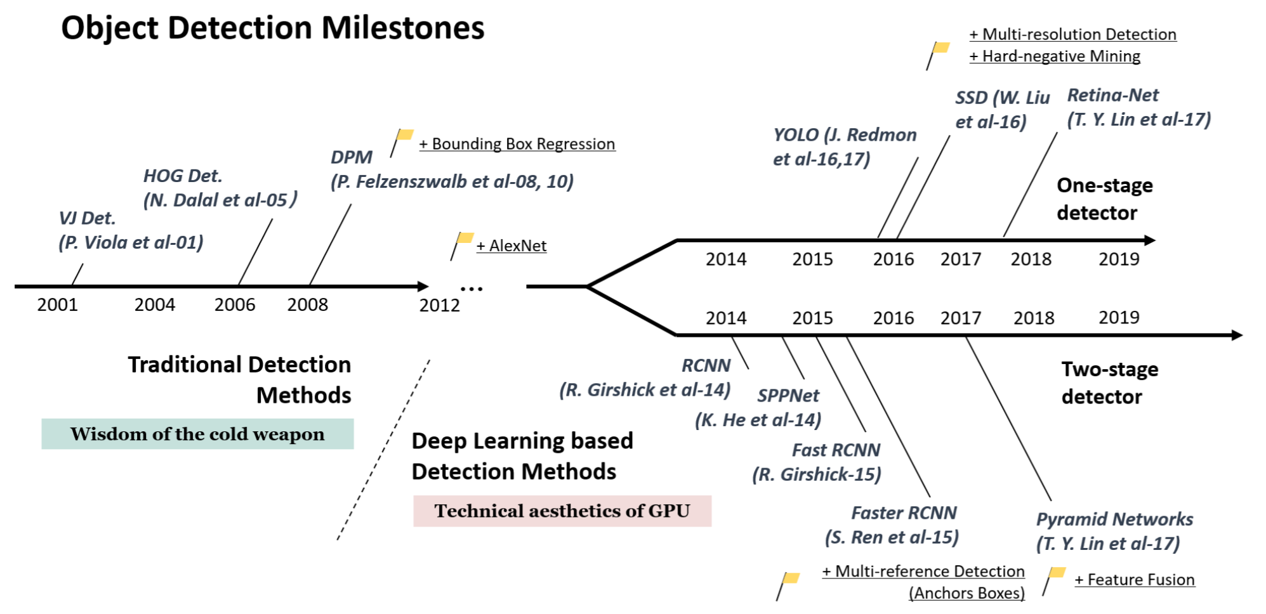
一、早期方法:滑动窗口和特征提取
在深度学习方法主导目标检测之前,滑动窗口和特征提取技术在这一领域中发挥了关键作用。通过理解这些技术的基本原理和实现方式,我们可以更好地把握目标检测技术的演进脉络。
滑动窗口机制
工作原理
- 基本概念: 滑动窗口是一种在整个图像区域内移动的固定大小的窗口。它逐步扫描图像,提取窗口内的像素信息用于目标检测。
- 代码示例: 展示如何在Python中实现基础的滑动窗口机制。
import cv2
import numpy as np
def sliding_window(image, stepSize, windowSize):
# 遍历图像中的每个窗口
for y in range(0, image.shape[0], stepSize):
for x in range(0, image.shape[1], stepSize):
# 提取当前窗口
yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
# 示例:在一张图像上应用滑动窗口
image = cv2.imread('example.jpg')
winW, winH = 64, 64
for (x, y, window) in sliding_window(image, stepSize=8, windowSize=(winW, winH)):
# 在此处可以进行目标检测处理
pass
特征提取方法
HOG(Histogram of Oriented Gradients)
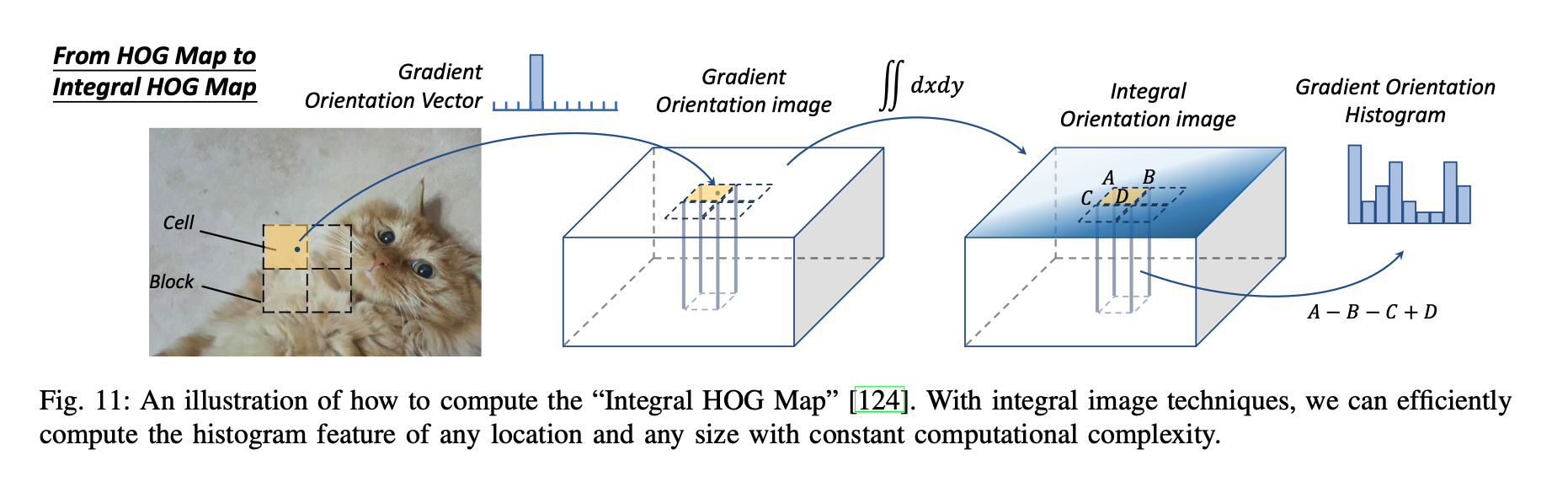
- 原理概述: HOG特征描述器通过计算图像局部区域内梯度的方向和大小来提取特征,这些特征对于描述对象的形状非常有效。
- 代码实现: 展示如何使用Python和OpenCV库提取HOG特征。
from skimage.feature import hog
from skimage import data, exposure
# 读取图像
image = data.astronaut()
# 计算HOG特征和HOG图像
fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True, channel_axis=-1)
# 显示HOG图像
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
cv2.imshow('HOG Image', hog_image_rescaled)
cv2.waitKey(0)
SIFT(Scale-Invariant Feature Transform)
- 工作原理: SIFT通过检测和描述图像中的关键点来实现对图像特征的尺度不变描述,使得它在物体识别和图像匹配中非常有效。
- 代码示例: 展示如何使用Python和OpenCV实现SIFT特征检测和描述。
import cv2
# 读取图像
image = cv2.imread('example.jpg')
# 初始化SIFT检测器
sift = cv2.SIFT_create()
# 检测SIFT特征
keypoints, descriptors = sift.detectAndCompute(image, None)
# 在图像上绘制关键点
sift_image = cv2.drawKeypoints(image, keypoints, None)
# 显示结果
cv2.imshow('SIFT Features', sift_image)
cv2.waitKey(0)
通过这些代码示例,我们不仅可以理解滑动窗口和特征提取技术的理论基础,还可以直观地看到它们在实际应用中的表现。这些早期方法虽然在当今深度学习的背景下显得简单,但它们在目标检测技术的发展历程中扮演了不可或缺的角色。
二、深度学习的兴起:CNN在目标检测中的应用
深度学习,尤其是卷积神经网络(CNN)在目标检测领域的应用,标志着这一领域的一次革命。CNN的引入不仅显著提高了检测的准确率,而且在处理速度和效率上也取得了质的飞跃。
CNN的基本概念
卷积层
- 原理概述: 卷积层通过学习滤波器(或称卷积核)来提取图像的局部特征。这些特征对于理解图像的内容至关重要。
- 代码示例: 使用Python和PyTorch实现基础的卷积层。
import torch
import torch.nn as nn
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
return x
# 示例:初始化模型并应用于一个随机图像
model = SimpleCNN()
input_image = torch.rand(1, 3, 32, 32) # 随机生成一个图像
output = model(input_image)
R-CNN及其变种
R-CNN(Regions with CNN features)
- 架构解析: R-CNN通过从图像中提取一系列候选区域(通常使用选择性搜索算法),然后独立地对每个区域运行CNN来提取特征,最后对这些特征使用分类器(如SVM)进行分类。
- 代码示例: 展示R-CNN的基本思路。
import torchvision.models as models
import torchvision.transforms as transforms
# 加载预训练的CNN模型
cnn_model = models.vgg16(pretrained=True).features
# 假设region_proposals是一个函数,它返回图像中的候选区域
for region in region_proposals(input_image):
# 将每个区域转换为CNN模型需要的尺寸和类型
region_transformed = transforms.functional.resize(region, (224, 224))
region_transformed = transforms.functional.to_tensor(region_transformed)
# 提取特征
feature_vector = cnn_model(region_transformed.unsqueeze(0))
# 在这里可以使用一个分类器来处理特征向量
Fast R-CNN
- 改进点: Fast R-CNN通过引入ROI(Region of Interest)Pooling层来提高效率,该层允许网络在单个传递中对整个图像进行操作,同时还能处理不同大小的候选区域。
- 代码实现: 展示如何使用PyTorch实现Fast R-CNN。
import torch
from torchvision.ops import RoIPool
# 假设cnn_features是CNN对整个图像提取的特征
cnn_features = cnn_model(input_image)
# 假设rois是一个张量,其中包含候选区域的坐标
rois = torch.tensor([[0, x1, y1, x2, y2], ...]) # 第一个元素是图像索引,后四个是坐标
# 创建一个ROI池化层
roi_pool = RoIPool(output_size=(7, 7), spatial_scale=1.0)
# 应用ROI池化
pooled_features = roi_pool(cnn_features, rois)
Faster R-CNN
- 创新之处: Faster R-CNN在Fast R-CNN的基础上进一步创新,通过引入区域提案网络(RPN),使得候选区域的生成过程也能通过学习得到优化。
- **代码概
述:** 展示Faster R-CNN中RPN的基本工作原理。
class RPN(nn.Module):
def __init__(self, anchor_generator, head):
super(RPN, self).__init__()
self.anchor_generator = anchor_generator
self.head = head
def forward(self, features, image_shapes):
# 生成锚点
anchors = self.anchor_generator(features, image_shapes)
# 对每个锚点应用头网络,得到区域提案
objectness, pred_bbox_deltas = self.head(features)
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
return proposals
通过这一部分的内容,我们不仅能够深入理解深度学习在目标检测中的应用,特别是CNN及其衍生模型的设计理念和实现方式,而且可以通过代码示例直观地看到这些技术在实践中的应用。这些知识对于理解目标检测技术的现代发展至关重要。
三、现代方法:YOLO系列
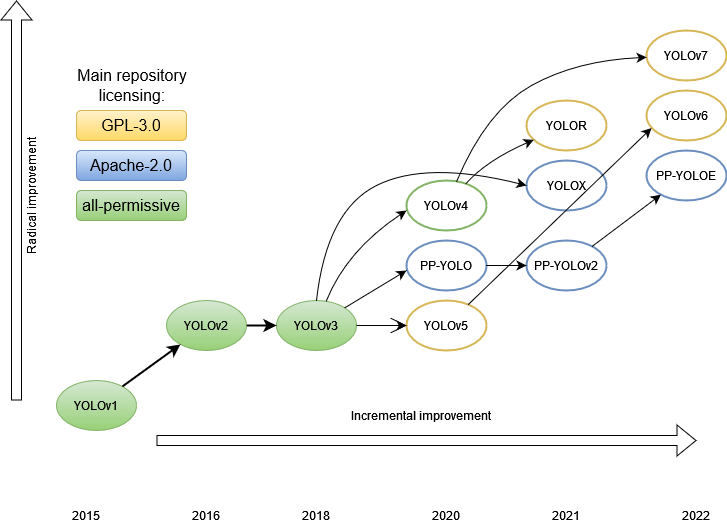
随着目标检测技术的不断进步,YOLO(You Only Look Once)系列作为现代目标检测方法的代表,凭借其独特的设计理念和优越的性能,在实时目标检测领域中取得了显著的成就。
YOLO的设计哲学
YOLO的基本原理
- 核心思想: YOLO将目标检测任务视为一个单一的回归问题,直接从图像像素到边界框坐标和类别概率的映射。这种设计使得YOLO能够在单次模型运行中完成整个检测流程,大大提高了处理速度。
- 架构简介: YOLO使用单个卷积神经网络同时预测多个边界框和类别概率,将整个检测流程简化为一个步骤。
YOLO的创新点
- 统一化框架: YOLO创新性地将多个检测任务合并为一个统一的框架,显著提高了速度和效率。
- 实时性能: 由于其独特的设计,YOLO可以在保持高精度的同时实现接近实时的检测速度,特别适合需要快速响应的应用场景。
YOLO系列的发展
YOLOv1
- 架构特点: YOLOv1通过将图像划分为网格,并在每个网格中预测多个边界框和置信度,从而实现快速且有效的检测。
- 代码概览: 展示YOLOv1模型的基本架构。
import torch.nn as nn
class YOLOv1(nn.Module):
def __init__(self, grid_size=7, num_boxes=2, num_classes=20):
super(YOLOv1, self).__init__()
# 网络层定义
# ...
def forward(self, x):
# 网络前向传播
# ...
return x
# 实例化模型
model = YOLOv1()
YOLOv2 和 YOLOv3
- 改进点: YOLOv2和YOLOv3进一步优化了模型架构,引入了锚点机制和多尺度检测,提高了模型对不同大小目标的检测能力。
- 代码概览: 展示YOLOv2或YOLOv3模型的锚点机制。
# YOLOv2和YOLOv3使用预定义的锚点来改进边界框的预测
anchors = [[116, 90], [156, 198], [373, 326]] # 示例锚点尺寸
YOLOv4 和 YOLOv5
- 最新进展: YOLOv4和YOLOv5在保持YOLO系列高速度的特点基础上,进一步提高了检测精度和鲁棒性。YOLOv5特别注重于易用性和训练效率的提升。
- 代码概览: 介绍YOLOv5的模型加载和使用。
import torch
# 加载预训练的YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 应用模型进行目标检测
imgs = ['path/to/image.jpg'] # 图像路径
results = model(imgs)
YOLO系列的发展不仅展示了目标检测技术的前沿动态,也为实时视频分析、无人驾驶汽车等多个应用领域提供了强大的技术支持。通过对YOLO系列的深入理解,可以更全面地掌握现代目标检测技术的发展趋势和应用场景。
四、Transformer在目标检测中的应用
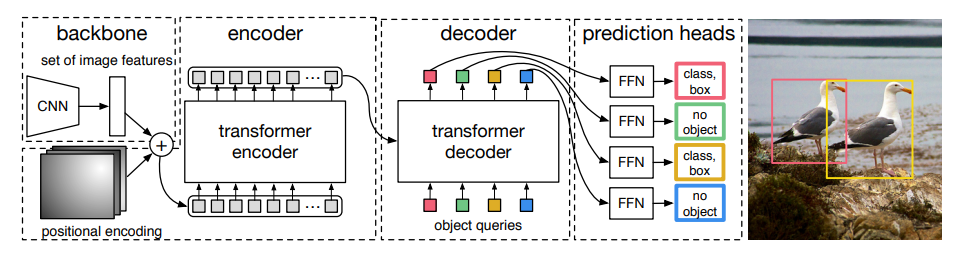
近年来,Transformer模型原本设计用于自然语言处理任务,但其独特的结构和工作机制也被证明在计算机视觉领域,特别是目标检测中,具有巨大的潜力。Transformer在目标检测中的应用开启了一个新的研究方向,为这一领域带来了新的视角和方法。
Transformer的基础知识
自注意力机制
- 核心原理: Transformer的核心是自注意力机制,它允许模型在处理一个元素时,同时考虑到输入序列中的所有其他元素,从而捕捉全局依赖关系。
- 在视觉任务中的应用: 在目标检测中,这意味着模型可以同时考虑图像中所有区域的信息,有助于更好地理解场景和对象之间的关系。
Transformer的架构
- 编码器和解码器: 标准的Transformer模型包含编码器和解码器,每个部分都由多个相同的层组成,每层包含自注意力机制和前馈神经网络。
Transformer在目标检测中的应用
DETR(Detection Transformer)
- 模型介绍: DETR是将Transformer应用于目标检测的先驱之作。它使用一个标准的Transformer编码器-解码器架构,并在输出端引入了特定数量的学习对象查询,以直接预测目标的类别和边界框。
- 代码概览: 展示如何使用DETR进行目标检测。
import torch
from models.detr import DETR
# 初始化DETR模型
model = DETR(num_classes=91, num_queries=100)
model.eval()
# 假设input_image是预处理过的图像张量
with torch.no_grad():
outputs = model(input_image)
# outputs包含预测的类别和边界框
Transformer与CNN的结合
- 结合方式: 一些研究开始探索将Transformer与传统的CNN结合,以利用CNN在特征提取方面的优势,同时借助Transformer处理长距离依赖的能力。
- 实例介绍: 例如,一些方法在CNN提取的特征图上应用Transformer模块,以增强对图像中不同区域间相互作用的理解。
前沿研究和趋势
- 研究动态: 目前,许多研究团队正在探索如何更有效地将Transformer应用于目标检测,包括改进其在处理不同尺度对象上的能力,以及提高其训练和推理效率。
- 潜在挑战: 尽管Transformer在目标检测中显示出巨大潜力,但如何平衡其计算复杂性和性能,以及如何进一步改进其对小尺寸目标的检测能力,仍然是当前的研究热点。
通过对Transformer在目标检测中的应用的深入了解,我们不仅能够把握这一新兴领域的最新发展动态,还能从中窥见计算机视觉领域未来可能的发展方向。Transformer的这些创新应用为目标检测技术的发展提供了新的动力和灵感。
总结
本篇文章全面回顾了目标检测技术的演变历程,从早期的滑动窗口和特征提取方法,到深度学习的兴起,尤其是CNN在目标检测中的革命性应用,再到近年来YOLO系列和Transformer在这一领域的创新实践。这一旅程不仅展示了目标检测技术的发展脉络,还反映了计算机视觉领域不断进步的动力和方向。
技术领域的一个独特洞见是,目标检测的发展与计算能力的提升、数据可用性的增加、以及算法创新紧密相关。从早期依赖手工特征的方法,到今天的深度学习和Transformer,我们看到了技术演进与时代背景的深度融合。
-
计算能力的提升: 早期目标检测技术的局限性在很大程度上源于有限的计算资源。随着计算能力的增强,复杂且计算密集的模型(如深度卷积网络)变得可行,这直接推动了目标检测性能的飞跃。
-
数据的重要性: 大量高质量标注数据的可用性,尤其是公开数据集如ImageNet、COCO等,为训练更精确的模型提供了基础。数据的多样性和丰富性是深度学习方法成功的关键。
-
算法的创新: 从R-CNN到YOLO,再到Transformer,每一次重大的技术飞跃都伴随着算法上的创新。这些创新不仅提高了检测的精度和速度,还扩展了目标检测的应用范围。
-
跨领域的融合: Transformer的成功应用显示了跨领域技术融合的巨大潜力。最初为自然语言处理设计的模型,经过适当的调整和优化,竟在视觉任务中也展现出卓越的性能,这启示我们在未来的研究中应保持对跨学科方法的开放性和创新性。
总的来说,目标检测技术的发展是计算机视觉领域不断进步和创新精神的体现。随着技术的不断进步,我们期待目标检测在更多领域发挥关键作用,例如在自动驾驶、医疗影像分析、智能监控等领域。展望未来,目标检测技术的进一步发展无疑将继续受益于计算能力的提升、更大规模和多样性的数据集,以及跨领域的算法创新。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。




![[c++]—string类___深度学习string标准库成员函数与非成员函数](https://img-blog.csdnimg.cn/direct/cb57cab79c534ea08e05975a73db5beb.png)