yolox-pytorch:nets/yolo.py
- yolox网络结构
- yolox-pytorch目录
- 今天解析注释nets/yolo.py
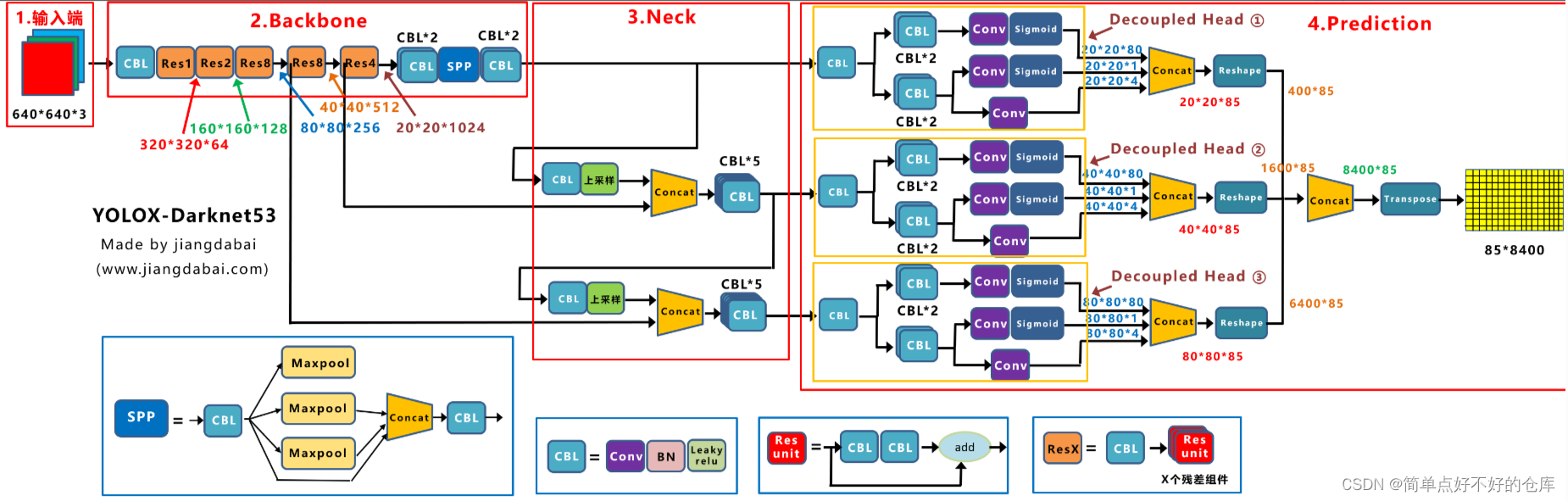
yolox网络结构
yolox-pytorch目录
nets目录
今天解析注释nets/yolo.py
import torch
import torch.nn as nn
from .darknet import BaseConv, CSPDarknet, CSPLayer, DWConv
###################################################################################
class YOLOXHead(nn.Module):
def __init__(self, num_classes, width = 1.0, in_channels = [256, 512, 1024], act = "silu", depthwise = False,):
super().__init__() # 调用父类的初始化方法
# 根据depthwise的值选择卷积类型,如果是深度可分离卷积,则使用DWConv,否则使用BaseConv
Conv = DWConv if depthwise else BaseConv
# 初始化存储不同部分预测结果的列表
self.cls_convs = nn.ModuleList() # 分类卷积层
self.reg_convs = nn.ModuleList() # 回归卷积层
self.cls_preds = nn.ModuleList() # 分类预测层
self.reg_preds = nn.ModuleList() # 回归预测层
self.obj_preds = nn.ModuleList() # 目标存在性预测层
self.stems = nn.ModuleList() # stem卷积层,用于调整输入通道数
# 遍历每一个输入通道数
for i in range(len(in_channels)):
# stem卷积层,用于将输入通道数调整为指定的输出通道数
self.stems.append(BaseConv(in_channels = int(in_channels[i] * width), out_channels = int(256 * width), ksize = 1, stride = 1, act = act))
# 分类卷积层,包括两个卷积操作
self.cls_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
]))
# 分类预测层,输出通道数为num_classes,表示每个像素位置可能的类别数量
self.cls_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = num_classes, kernel_size = 1, stride = 1, padding = 0)
)
# 回归卷积层,包括两个卷积操作
self.reg_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), ksize = 3, stride = 1, act = act)
]))
# 回归预测层,输出通道数为4,表示每个目标的边框位置信息(x, y, w, h)
self.reg_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = 4, kernel_size = 1, stride = 1, padding = 0)
)
# 目标存在性预测层,输出通道数为1,表示每个像素位置是否有目标存在
self.obj_preds.append(
nn.Conv2d(in_channels = int(256 * width), out_channels = 1, kernel_size = 1, stride = 1, padding = 0)
)
def forward(self, inputs):
#---------------------------------------------------#
# inputs输入
# P3_out 80, 80, 256
# P4_out 40, 40, 512
# P5_out 20, 20, 1024
#---------------------------------------------------#
outputs = []
for k, x in enumerate(inputs):
#---------------------------------------------------#
# 利用1x1卷积进行通道整合
#---------------------------------------------------#
x = self.stems[k](x)
#---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
#---------------------------------------------------#
cls_feat = self.cls_convs[k](x)
#---------------------------------------------------#
# 判断特征点所属的种类
# 80, 80, num_classes
# 40, 40, num_classes
# 20, 20, num_classes
#---------------------------------------------------#
cls_output = self.cls_preds[k](cls_feat)
#---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
#---------------------------------------------------#
reg_feat = self.reg_convs[k](x)
#---------------------------------------------------#
# 特征点的回归系数
# reg_pred 80, 80, 4
# reg_pred 40, 40, 4
# reg_pred 20, 20, 4
#---------------------------------------------------#
reg_output = self.reg_preds[k](reg_feat)
#---------------------------------------------------#
# 判断特征点是否有对应的物体
# obj_pred 80, 80, 1
# obj_pred 40, 40, 1
# obj_pred 20, 20, 1
#---------------------------------------------------#
obj_output = self.obj_preds[k](reg_feat)
# 将回归、目标存在性和分类的输出在第二个维度上进行拼接
output = torch.cat([reg_output, obj_output, cls_output], 1)
# 将拼接后的输出添加到outputs列表中
outputs.append(output)
# 返回包含所有尺度或所有层预测结果的outputs列表
return outputs
###################################################################################
# 导入PyTorch的nn模块
class YOLOPAFPN(nn.Module):
def __init__(self, depth = 1.0, width = 1.0, in_features = ("dark3", "dark4", "dark5"), in_channels = [256, 512, 1024], depthwise = False, act = "silu"):
super().__init__() # 调用父类nn.Module的初始化方法
# 根据depthwise的值选择卷积方式,如果是True则使用DWConv,否则使用BaseConv
Conv = DWConv if depthwise else BaseConv
# 创建CSPDarknet作为backbone网络,其参数由外部传入
self.backbone = CSPDarknet(depth, width, depthwise = depthwise, act = act)
# 存储输入特征层的名称
self.in_features = in_features
# 定义上采样层,用于将特征图放大一倍
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
# 以下部分是定义不同的卷积层和CSPLayer,用于特征提取和融合
# 注释中的数字表示特征图的尺寸和通道数,例如20, 20, 1024表示宽高为20,通道数为1024的特征图
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
self.reduce_conv1 = BaseConv(int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
# 这里是一个卷积操作,但代码被注释掉了,所以没有实际执行任何操作
# 定义一个卷积层,输入和输出的通道数都是in_channels[0] * width,卷积核大小为3,步长为2,激活函数为act
self.bu_conv2 = Conv(int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act)
# 注释说明:该卷积层将特征图的尺寸从40x40变为20x20,通道数从256变为512
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
# 定义一个CSPLayer,输入通道数为2 * in_channels[0] * width,输出通道数为in_channels[1] * width,其他参数由外部传入
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
# 定义另一个卷积层,输入和输出的通道数都是in_channels[1] * width,卷积核大小为3,步长为2,激活函数为act
self.bu_conv1 = Conv(int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act)
# 注释说明:该卷积层将特征图的尺寸从40x40变为20x20,通道数从512变为1024
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
# 定义另一个CSPLayer,输入通道数为2 * in_channels[1] * width,输出通道数为in_channels[2] * width,其他参数由外部传入
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act,
)
def forward(self, input):
out_features = self.backbone.forward(input)
[feat1, feat2, feat3] = [out_features[f] for f in self.in_features]
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 512
#-------------------------------------------#
P5 = self.lateral_conv0(feat3)
#-------------------------------------------#
# 20, 20, 512 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.upsample(P5)
#-------------------------------------------#
# 40, 40, 512 + 40, 40, 512 -> 40, 40, 1024
#-------------------------------------------#
P5_upsample = torch.cat([P5_upsample, feat2], 1)
#-------------------------------------------#
# 40, 40, 1024 -> 40, 40, 512
#-------------------------------------------#
P5_upsample = self.C3_p4(P5_upsample)
#-------------------------------------------#
# 40, 40, 512 -> 40, 40, 256
#-------------------------------------------#
P4 = self.reduce_conv1(P5_upsample)
#-------------------------------------------#
# 40, 40, 256 -> 80, 80, 256
#-------------------------------------------#
P4_upsample = self.upsample(P4)
#-------------------------------------------#
# 80, 80, 256 + 80, 80, 256 -> 80, 80, 512
#-------------------------------------------#
P4_upsample = torch.cat([P4_upsample, feat1], 1)
#-------------------------------------------#
# 80, 80, 512 -> 80, 80, 256
#-------------------------------------------#
P3_out = self.C3_p3(P4_upsample)
#-------------------------------------------#
# 80, 80, 256 -> 40, 40, 256
#-------------------------------------------#
P3_downsample = self.bu_conv2(P3_out)
#-------------------------------------------#
# 40, 40, 256 + 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P3_downsample = torch.cat([P3_downsample, P4], 1)
#-------------------------------------------#
# 40, 40, 256 -> 40, 40, 512
#-------------------------------------------#
P4_out = self.C3_n3(P3_downsample)
#-------------------------------------------#
# 40, 40, 512 -> 20, 20, 512
#-------------------------------------------#
P4_downsample = self.bu_conv1(P4_out)
#-------------------------------------------#
# 20, 20, 512 + 20, 20, 512 -> 20, 20, 1024
#-------------------------------------------#
P4_downsample = torch.cat([P4_downsample, P5], 1)
#-------------------------------------------#
# 20, 20, 1024 -> 20, 20, 1024
#-------------------------------------------#
P5_out = self.C3_n4(P4_downsample)
return (P3_out, P4_out, P5_out)
###################################################################################
# 定义了一个名为YoloBody的类,它继承了nn.Module,是PyTorch中的一个神经网络模型。
class YoloBody(nn.Module):
# 初始化函数,当创建YoloBody类的实例时会被调用。
def __init__(self, num_classes, phi):
# 调用父类nn.Module的初始化函数。
super().__init__()
# 定义了两个字典,分别存储了不同phi值对应的深度和宽度系数。
depth_dict = {'nano': 0.33, 'tiny': 0.33, 's' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,}
width_dict = {'nano': 0.25, 'tiny': 0.375, 's' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,}
# 根据输入的phi值,从字典中获取对应的深度和宽度系数。
depth, width = depth_dict[phi], width_dict[phi]
# 判断phi值是否为'nano',如果是,则depthwise为True,否则为False。
depthwise = True if phi == 'nano' else False
# 创建YOLOPAFPN的实例作为backbone,参数包括depth、width和depthwise。
self.backbone = YOLOPAFPN(depth, width, depthwise=depthwise)
# 创建YOLOXHead的实例作为head,参数包括num_classes、width和depthwise。
self.head = YOLOXHead(num_classes, width, depthwise=depthwise)
# 定义前向传播函数。
def forward(self, x):
# 将输入x传递给backbone,得到fpn_outs。
fpn_outs = self.backbone.forward(x)
# 将fpn_outs传递给head,得到outputs。
outputs = self.head.forward(fpn_outs)
# 返回outputs。
return outputs
###################################################################################
###################################################################################