我们从最常用的 Python 包入手,去解答上述这个问题。最初,我列出过去一年在 PyPI 上下载次数最多的 Python 包。接下来,深入研究其用途、它们之间的关系和它们备受欢迎的原因。
1、Urllib3
下载次数:8.93 亿
Urllib3是一个 Python 的 HTTP 客户端,它拥有 Python 标准库中缺少的许多功能:
线程安全
连接池
客户端 SSL/TLS 验证
使用分段编码上传文件
用来重试请求和处理 HTTP 重定向的助手
支持 gzip 和 deflate 编码
HTTP 和 SOCKS 的代理支持不要被名字所误导,Urllib3并不是urllib2的后继者,而后者是 Python 核心的一部分。如果你想使用尽可能多的 Python 核心功能,或者你能安装什么东西是受限,那么请查看 urlllib.request。
对最终用户来说,我强烈建议使用 requests 包。这个包之所以会排名第一,是因为有差不多 1200 个包依赖 urllib3,其中许多包在这个列表中的排名也很高。
2、Six
下载次数:7.32 亿
six 是一个是 Python 2 和 3 的兼容性库。这个项目旨在支持可同时运行在 Python 2 和 3 上的代码库。
它提供了许多可简化 Python 2 和 3 之间语法差异的函数。一个容易理解的例子是six.print_()。在 Python 3 中,打印是通过print()函数完成的,而在 Python 2 中,print后面没有括号。因此,有了six.print_()后,你就可以使用一个语句来同时支持两种语言。
一些事实:
它的名字叫six,是因为二乘以三等于六。
同类库还可以看看future包。
如果你要将代码转换为 Python3(并停止支持 2),请查看 2to3。虽然我理解它为什么这么受欢迎,但我希望人们能完全放弃 Python 2,因为要知道从 2020 年 1 月 1 日起 Python 2 的官方支持就已停止。
3、botocore、boto3、s3transfer、awscli
这里,我把相关的几个项目列在一起:
botocore(#3,6.6 亿次下载)
s3transfer(#7,5.84 亿次下载)
awscli(#17,3.94 亿次下载)
boto3(#22,3.29 亿次下载)
Botocore是 AWS 的底层接口。Botocore是 Boto3 库(#22)的基础,后者让你可以使用 Amazon S3 和 Amazon EC2 一类的服务。Botocore 还是 AWS-CLI 的基础,后者为 AWS 提供统一的命令行界面。
S3transfer(#7)是用于管理 Amazon S3 传输的 Python 库。它正在积极开发中,其介绍页面不推荐人们现在使用,或者至少等版本固定下来再用,因为其 API 可能发生变化,在次要版本之间都可能更改。Boto3、AWS-CLI和其他许多项目都依赖s3transfer。
令人惊讶的是,这些针对 AWS 库的排名竟如此之高——这充分说明了 AWS 有多厉害。
4、Pip
下载次数:6.27 亿
我想,你们大多数人都知道并且很喜欢 pip,它是 Python 的包安装器。你可以用 pip 轻松地从 Python 包索引和其他索引(例如本地镜像或带有私有软件的自定义索引)来安装软件包。
有关 pip 的一些有趣事实:
pip是“Pip Installs Packages”的首字母递归缩写。
pip很容易使用。要安装一个包只需pip install 即可,而删除包只需pip uninstall 即可。
最大优点之一是它可以获取包列表,通常以requirements.txt文件的形式获取。该文件能选择包含所需版本的详细规范。大多数 Python 项目都包含这样的文件。
如果结合使用pip与virtualenv(列表中的 #57),就可以创建可预测的隔离环境,同时不会干扰底层系统,反之亦然。
5、Python-dateutil
下载次数:6.17 亿
python-dateutil模块提供了对标准datetime模块的强大扩展。我的经验是,常规的Python datetime缺少哪些功能,python-dateutil就能补足那一块。
你可以用这个库做很多很棒的事情。其中,我发现的一个特别有用的功能就是:模糊解析日志文件中的日期,例如:
from dateutil.parser import parselogline = ‘INFO 2020-01-01T00:00:01 Happy ew year, human.’timestamp = parse(log_line, fuzzy=True)print(timestamp)# 2020-01-01 00:00:01
6、Requests
下载次数:6.11 亿
Requests建立在我们的 #1 库——urllib3基础上。它让 Web 请求变得非常简单。相比urllib3来说,很多人更喜欢这个包。而且使用它的最终用户可能也比urllib3更多。后者更偏底层,并且考虑到它对内部的控制级别,它一般是作为其他项目的依赖项。
下面这个例子说明 requests 用起来有多简单:
import requests
r = requests.get(‘https://api.github.com/user’, auth=(‘user’, ‘pass’))
r.status_code
200
r.headers[‘content-type’]
‘application/json; charset=utf8’
r.encoding
‘utf-8′
r.text
u’{“type”:”User”…’
r.json()
{u’disk_usage’: 368627, u’private_gists’: 484, …}
最后
分享一份Python的学习资料,但由于篇幅有限,完整文档可以扫码免费领取!!!

1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

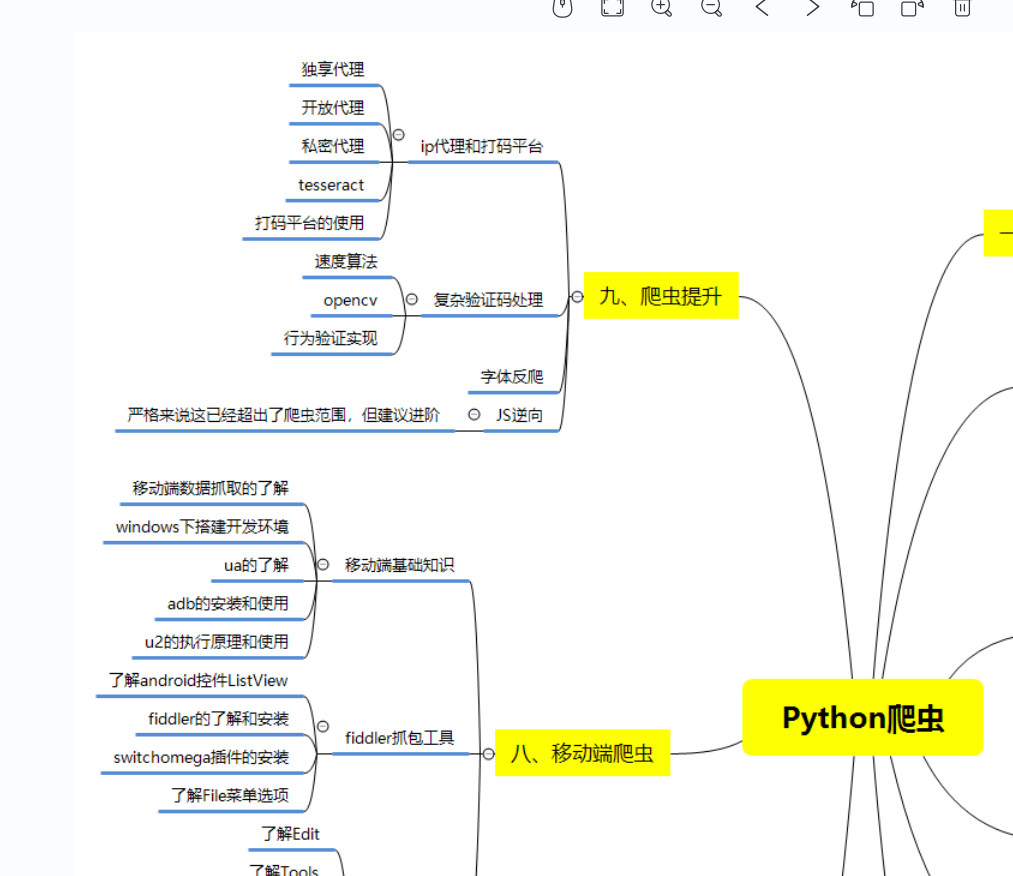
比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。