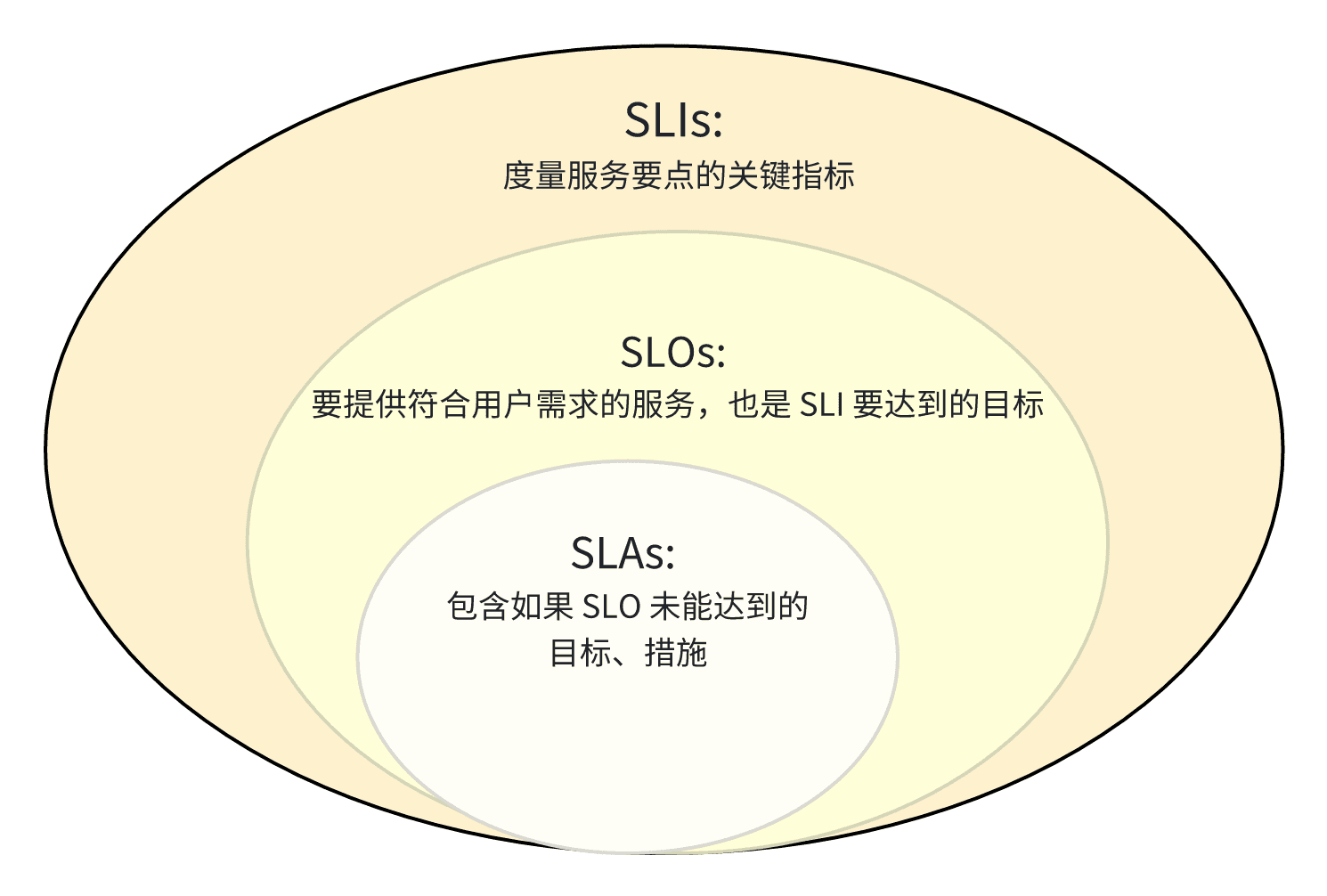
什么是 SLO?
SLO(Service Level Objective)是服务质量目标的短语缩写。它通常指的是维护系统的最高级别的目标,或服务等级协议(SLA)中的服务质量目标。它能够定义客户和用户在使用软件系统时所期望的服务质量水平,并提供一个标准作为开发和运维团队的参考和评估。
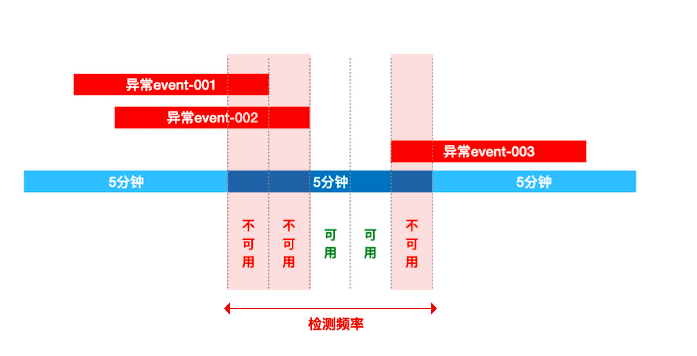
对于观测云来说,SLO 是进行 SLA 评分处理的最小单元,是一个时间窗口内 SLI 累积成功数的目标。而我们又经常把 SLO 转化为错误预算,用于计算可容忍的错误数,在每一个检测周期内出现异常事件的时间将在可容错时长中扣除。如下图:假设 SLO 检测周期为 5 分钟,根据叠加后,异常事件覆盖时间为 3 分钟,扣除额度 3 分钟。
许多组织会借助 SLO 来评估产品可靠性。SLO 为定义应用程序性能的明确目标提供了一个框架,帮助团队提供一致的客户体验,平衡功能开发与平台稳定性,并改善与内部和外部用户的沟通。SLO 还有助于分离业务关注点,明确边界,合理化不同团队的期望。尽管 SLO 是确保可靠性的工具,但仅靠简单设置 SLO 目标不能达到这样的效果。基于组织当前能力制定符合实际的 SLO 会更有助于实现组织目标,设定超出能力的 SLO 可能适得其反。
SLO 可帮助确定问题的严重程度。如果可用性低于设定的 SLO,应通知工程师尽快响应。此外,SLO 可帮助明确划分服务的清晰边界,从而团队能确定需要维护哪些基础设施以及通知哪个团队解决问题。最后,基于满足 SLO 的情况,SLO 可辅助指导制定业务优先事项。
如何确定 SLO 目标?
在制定服务水平目标(SLO)时,要明确组织中的利益相关者会有不同的优先事项,由此产生不同的目标。从技术角度来看,Dev&Ops 需确保 SLO 可衡量且可行。如果任何 SLO 之间存在冲突或达到某个 SLO 会带来高成本,需及时提供预警。业务部门可与 Dev&Ops 合作,从而更好了解做出业务目标的取舍,并确定这些取舍如何有益于组织。例如,完成一款功能的设计后,可以决定设置较低的 SLO 以加快开发和发布功能的速度。
需要注意的是,各利益相关者的核心事项通常存在重叠,而非相互排斥。业务和技术团队之间的有效协作和一致性非常重要,这样才能充分发挥 SLO 的潜力。例如,CSM 了解客户的期望并确定他们最关心的事项,而工程师则可制定实现期望的最具实际性路径。
SLO 与 SLI
SLI(Service Level Indicator),也就是测量指标,即选择用于衡量系统稳定性的指标。SLO 为 SLI 设定了精确的目标。在观测云,我们基于监控器(《智能监控,高效观测 IT 系统瓶颈》)设定一个或多个测量指标。在观测云管理 SLO,以监控器的正常运行时间作为唯一衡量指标,我们就可以无缝访问监控数据。此时,我们可以把 SLI 理解为服务表现良好(即监控器未检测到异常事件)的时间比例。
例如,如果我们想确保用户请求得到快速响应,可以使用来自 APM 的服务中位数延迟作为 SLI。然后,在 SLO 中设置每分钟计算的所有用户请求的中位数延迟在任何时间段内 99% 的时间内都小于 250 毫秒。此时,为了准确追踪实际性能与我们设定的目标的比较情况,我们不仅需要监控实时性能(例如,每 60 秒计算一次中位数延迟并与250毫秒阈值进行比较),还要衡量该阈值在更长时间跨度上被超过的频率(以确保在每个时间段内都满足 99% 的目标)。观测云会跟踪我们的 SLI 并将其状态与我们设定的 SLO 进行可视化,因此我们可以立即看到实际性能与给定时间段内的目标的比较情况。
基于监控的 SLO 用例
在使用 SLO 的实践过程中,如下图所示,输入 SLO 任务名称后,首先需设定两个目标,即目标和最低目标。
- 目标:当 SLO 百分比 < 目标百分比,且 >= 最低目标百分比时,被认定为不健康 SLA;
- 最低目标:当 SLO 百分比 < 最低目标百分比时,被认定为不达标 SLA。
其次,选择一个最符合当下所需场景的 SLI。有一句话十分重要:所有 SLIs 都是衡量指标,但不是所有衡量指标都是好的 SLIs。因此,面对我们工作空间内的诸多衡量指标,我们应首先选择最能捕捉当下场景体验的指标。
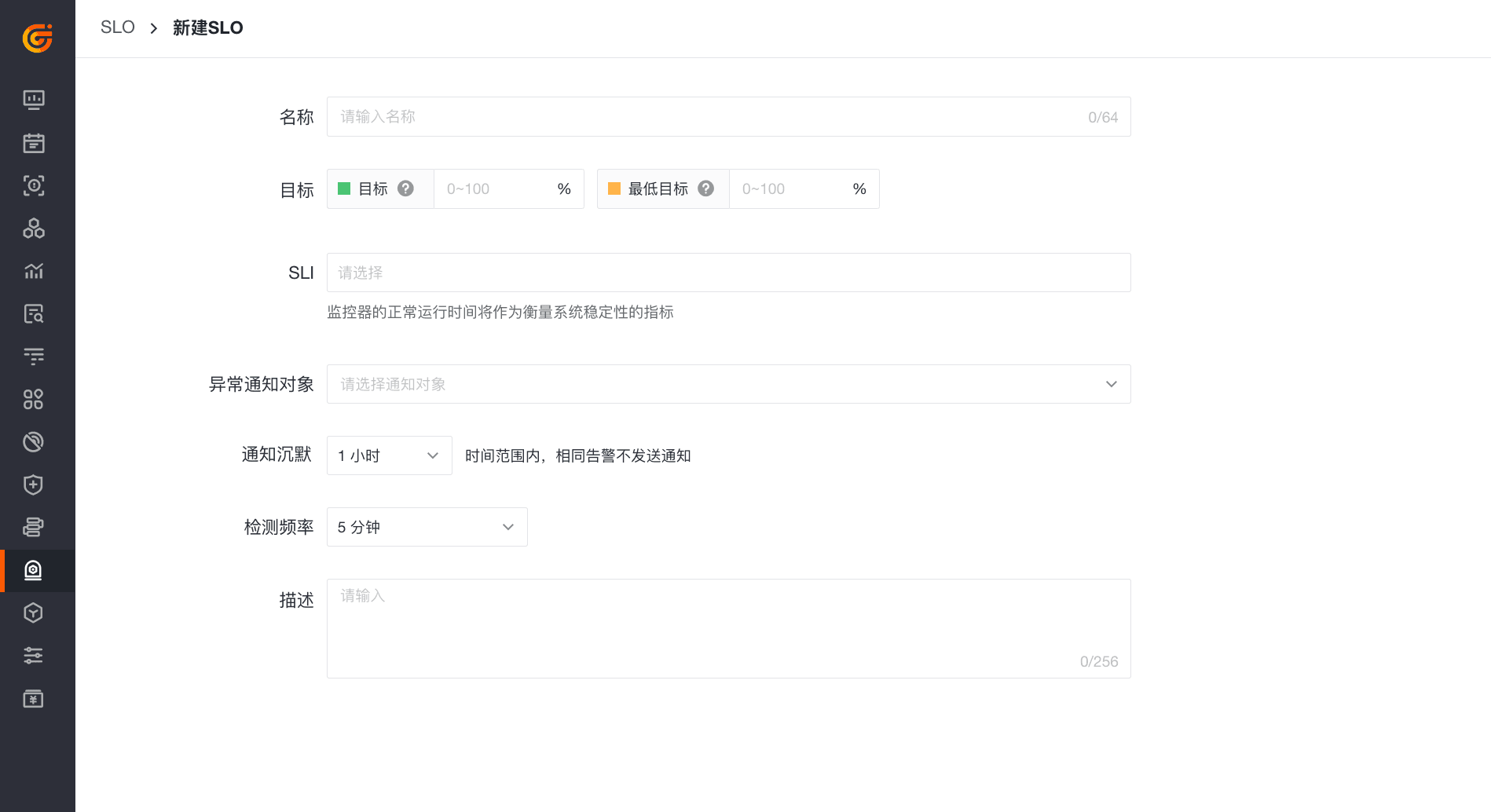
另外,选择需要发送异常通知的对象(包含空间成员、邮件组、企业微信机器人、钉钉机器人、飞书机器人、短信等);设置重复告警通知,从而减少告警通知频率,避免受到异常通知的不必要干扰;设定好检测频率(目前支持 5分钟、10分钟两种),从而以一定时间范围为周期,监测 SLO 任务中监控器是否出现异常事件。
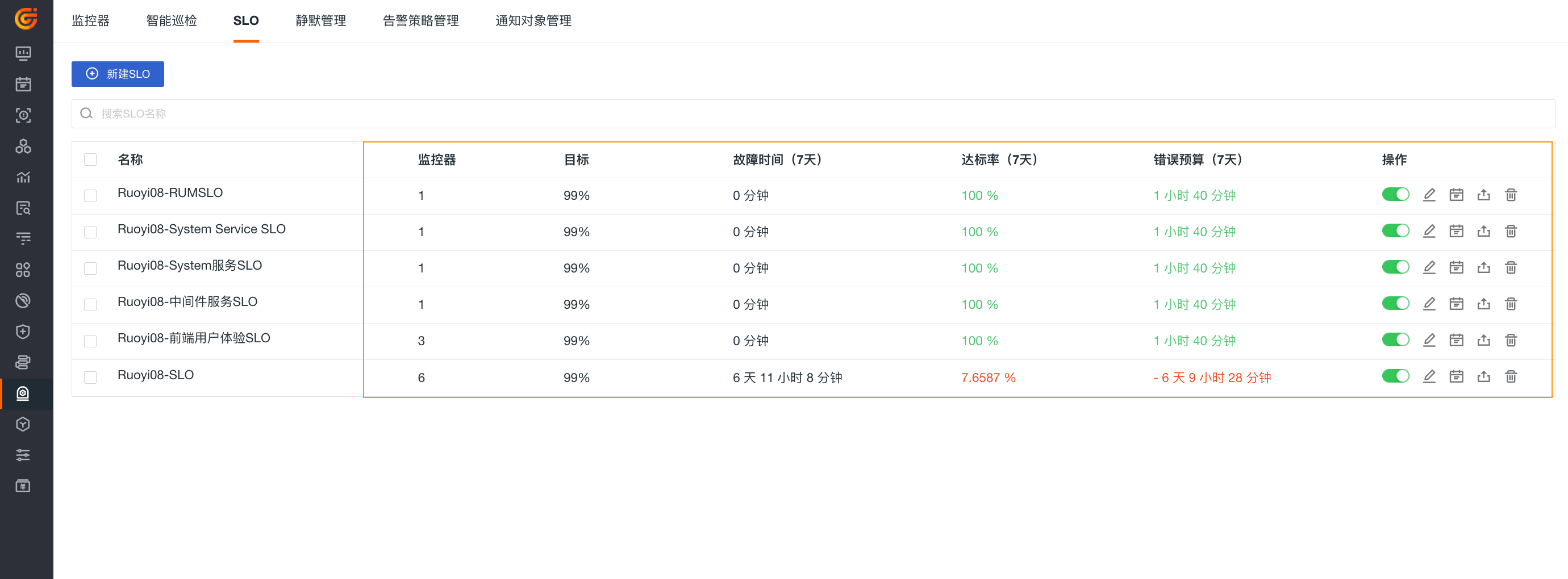
新建完任务后,在 SLO 列表进一步分析 SLO 任务达标率、目标服务水平等之前离不开以下概念:
| 字段 | 说明 |
|---|---|
| 监控器 | SLI 关联的监控器数量,即测量服务性能的指标。 |
| 达标率 | 在给定考核周期内满足系统无异常时间占总时长的百分比(达标率=系统无异常时间/考核周期 * 100%):
|
| 故障时间 | 即监控器异常的时间/已用额度。 |
| 剩余额度 | 当前 SLO 还剩余的可容错时长(假设目标 SLO 设定为 95%,即存在 5% 的容错率,默认最近 7 天为周期,即默认剩余额度=7天 *5% = 21分钟),显示为:
|
| 目标 | 创建 SLO 任务时设定的,服务可用性的目标百分比。 |
点击单条 SLO 任务进入其详情页,我们就可以观测到当前 SLO 的达标率、剩余额度及 SLI 异常记录:
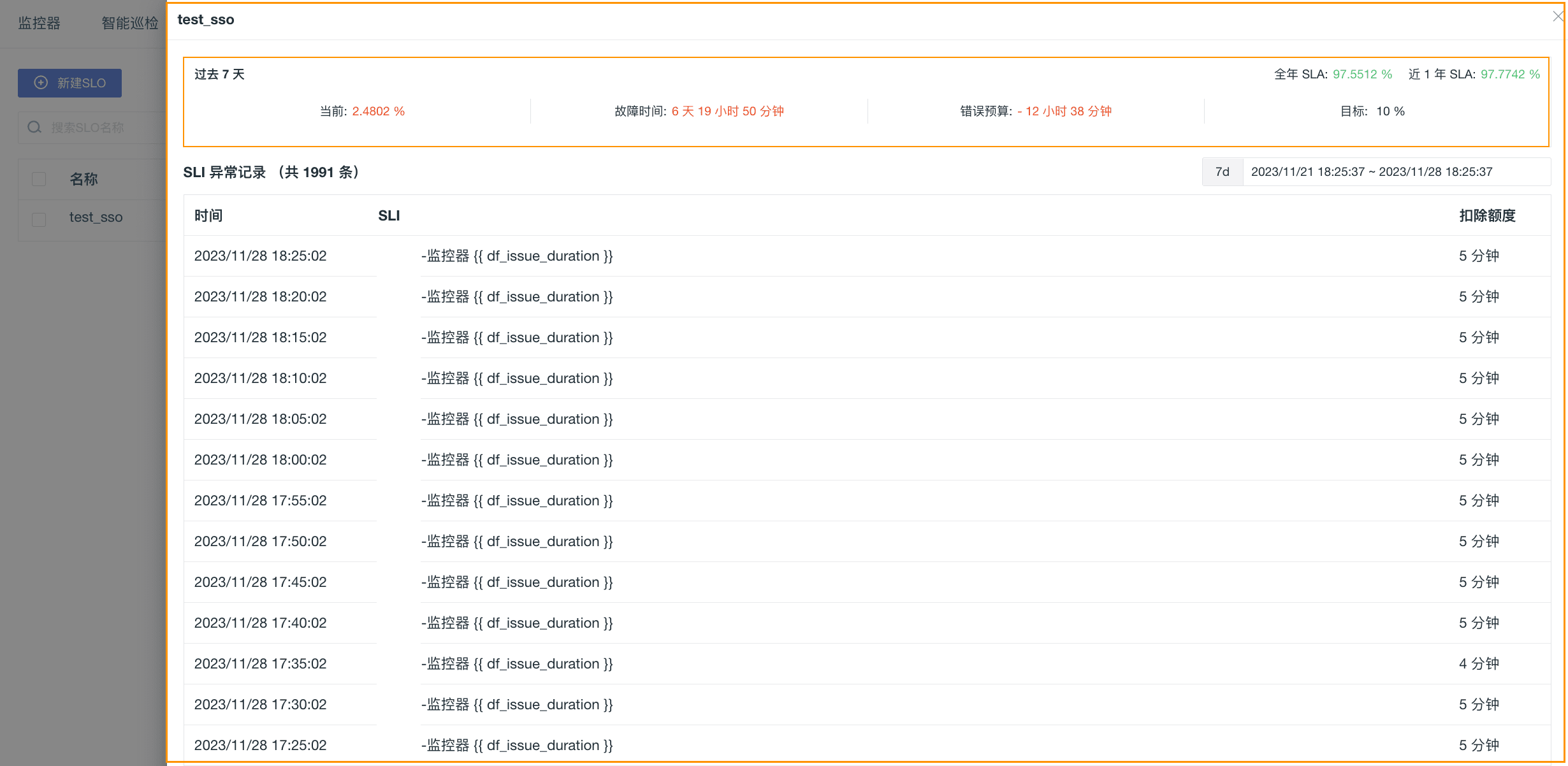
| 字段 | 说明 |
|---|---|
| 过去 7 天 SLA | 根据当前访问的时间获取近 7 天的达标率。 |
| 全年 SLA | 根据当前访问的时间获取今年(自然年)的达标率。 |
| 近一年 SLA | 根据当前访问的时间获取最近 1 年(自然年)的达标率。 |
| SLI 异常记录 | 基于当前 SLO 任务下的监控器所触发的异常事件。 |
SLO 与仪表板的完美联合
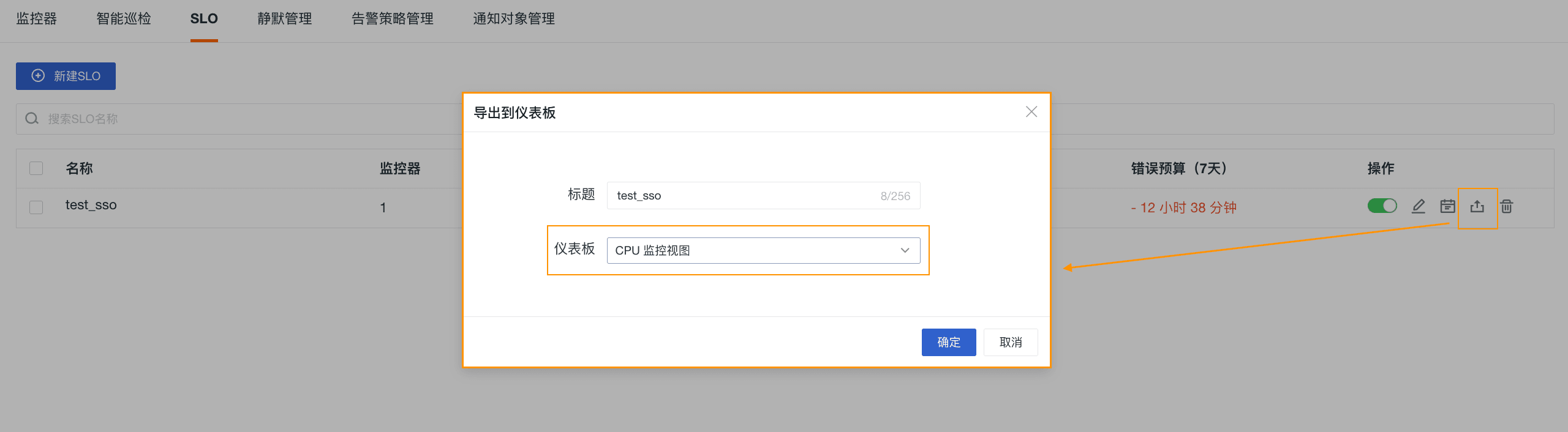
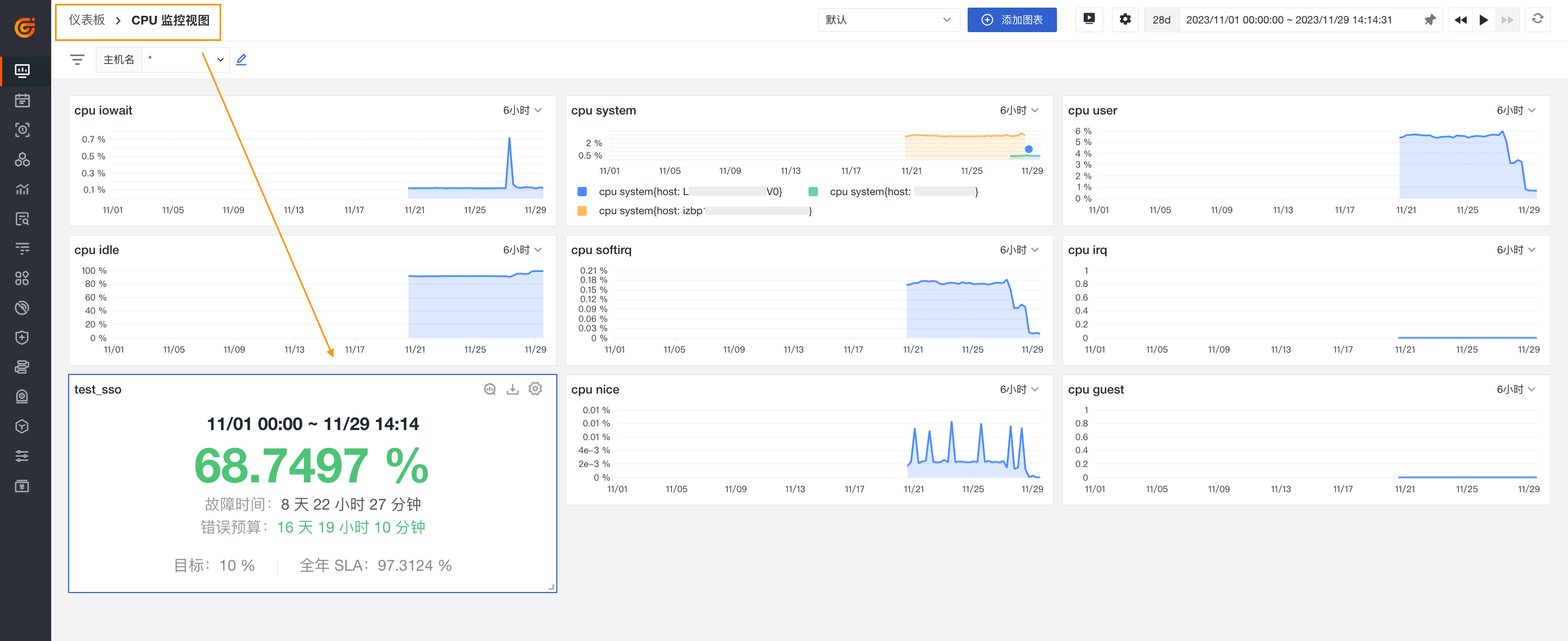
当组织内多个团队实施不同的 SLO 任务,那么将 SLO 的任务状态可视化能进一步帮助各团队设置任务优先级、解决问题。借助应用到仪表板的可视化办法,我们可以以一种更加全方位的方式与任何利益相关者共享这些 SLO 的实时状态。如下图,我们将该条 SLO 任务直接导出到仪表板。在仪表板内,我们可以看到 SLO 的状态、故障时间、错误预算、全年 SLA 等关键信息。
结语
协作和沟通对于成功实施服务水平目标至关重要。开发和运营团队需要评估他们的工作对于已建立的服务可靠性目标的影响,以改善最终用户的体验。观测云通过使组织借助统一入口方跟踪、管理和监控其所有 SLO 的状态和错误预算,简化了跨团队协作的繁琐流程。团队可以在仪表板上将其SLO 与相关服务和基础架构组件可视化,并与依赖于它们的任何利益相关者共享这些 SLO 的实时状态。