文章目录
- 论文简介
- 摘要
- 存在的问题
- 论文贡献
- 1. 整体架构
- 2. nPrint
- 3. nPrintML
- 4. 任务
- 总结
- 论文内容
- 工具
- 数据集
- 可读的引用文献
- 笔记参考文献
论文简介
原文题目:New Directions in Automated Traffic Analysis
中文题目:自动流量分析的新方向
发表会议:CCS '21: 2021 ACM SIGSAC Conference on Computer and Communications Security
发表年份:2021-11-12
作者:Jordan Holland
latex引用:
@inproceedings{holland2021new,
title={New directions in automated traffic analysis},
author={Holland, Jordan and Schmitt, Paul and Feamster, Nick and Mittal, Prateek},
booktitle={Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security},
pages={3366--3383},
year={2021}
}
摘要
机器学习被用于安全领域的许多网络流量分析任务,从应用识别到入侵检测。然而,最终决定模型性能的机器学习管道的各个方面——特征选择和表示、模型选择和参数调优——仍然是手工和艰苦的。本文提出了一种自动化流量分析许多方面的方法,使机器学习技术更容易应用于更广泛的流量分析任务。
我们介绍了nPrint,一个生成统一的数据包表示的工具,适用于表示学习和模型训练。我们将nPrint与自动机器学习(AutoML)集成在一起,形成了nPrintML,这是一个公共系统,在很大程度上消除了各种流量分析任务的特征提取和模型调优。我们已经在8个独立的流量分析任务上对nPrintML进行了评估,并发布了nPrint和nPrintML,以使未来的工作能够扩展这些方法。
存在的问题
- 特征工程和模型选择是一个艰苦的过程,通常需要大量的专业领域知识来设计特征
- 即使有专家领域的知识,特征探索和工程在很大程度上仍然是一个脆弱和不完美的过程,因为特征的选择和如何表示它们会极大地影响模型的准确性。这样的人工提取可能会忽略那些不是很明显或涉及复杂关系的特征(例如,特征之间的非线性关系)
- 流量模式和条件总是在变化,模型和手工制作的特征会过时
- 每一个新的网络检测或分类任务都需要重新设计系统:设计新的特征,选择合适的模型,手动调整新的参数
论文贡献
- 设计了一个标准的数据包表示,nPrint,它以固有的规范化二进制表示对每个数据包进行编码,同时保留每个数据包的底层语义。nPrint使机器学习模型能够自动发现不同分类任务提供的数据包的重要特征集合,无需手动提取。
- nPrint与AutoML(一个我们称为nPrintML的系统)的集成可以实现自动模型选择和超参数调优,从而可以使用nPrint创建完整的流量分析管道——通常不需要编写代码
论文解决上述问题的方法:
提出了nPrint来自动化提取特征,解决了问题1,问题2,问题3
提出了nPrintML实现自动模型选择和超参数调优,解决了问题4
论文的任务:
自动化流量分类
1. 整体架构
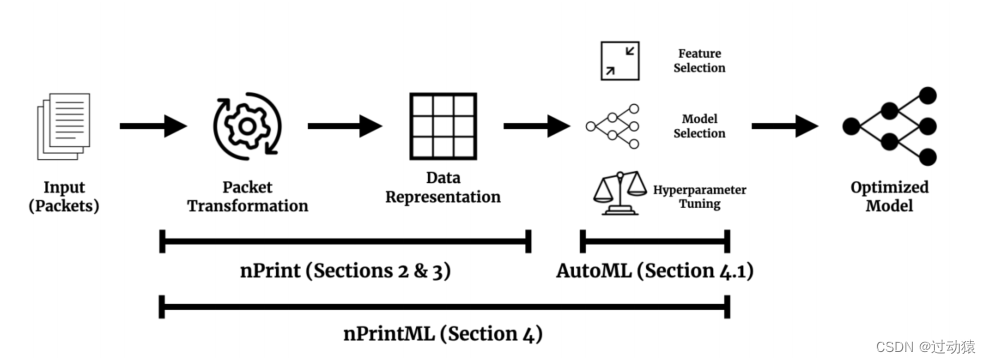
2. nPrint
-
设计要求:
- 完整性:设计一个representation,包括包头的每一个bit
这样设计的原因:避免这样一个领域知识:某个包报头字段(或字段组合)比其他字段更重要的问题。作者的直觉是,模型通常可以在没有人类指导的情况下,在给定完整的表示的情况下,自己确定哪些特征对给定问题是重要的。
- 固定尺度:每种representation都必须是固定大小的——即使单个数据包或数据包头的大小不同
这样设计的原因:这种知识避免了在存储的数据包跟踪上进行多次传递的需要,并且在数据流上下文中是必不可少的。
- 规范化:当特征被归一化时,机器学习模型通常表现得比没做归一化时更好
这样设计的原因:归一化减少了训练时间并提高了模型稳定性
- 对齐:representation中的每个位置应该对应于所有包的包头的相同部分
这样设计的原因:对齐允许模型基于特定特征(即数据包头)总是位于数据包中相同的偏移量这一事实来学习特征表示。虽然人类驱动的特征工程通过将每个数据包中的信息提取到格式良好的结构中来获得一致的特征,但在考虑二进制形式的数据包时需要此需求,因为协议和数据包的长度不同。任何不对齐的特征都会在学习过程中注入噪声,从而降低训练模型的准确性。
-
构建标准数据表示
nPrint支持三种表示网络流量的方法:- 语义(semantic)
- 未对齐二进制(unaligned binary)
- 混合(hybrid)
-
语义表示(semantic representation)

每个报头都有语义字段,如IP TTL、TCP端口号和UDP长度字段。网络流量的标准语义表示将所有这些语义字段收集到一个表示中。这种语义表示是完整且大小恒定的,满足设计要求中的完整性,固定尺度以及对齐。缺点:
- 语义表示不保留选项字段的顺序,而选项字段长期以来一直用于区分指纹识别中的设备类别
- 需要领域专业知识来解析每个协议的语义结构,即使有了这些知识,确定每个特征的正确表示通常也是一项重要的工作。例如,领域知识可能表明TCP源端口是一个重要的字段,但可能需要进一步(通常是手动)评估,以确定是否应该将其表示为连续值,还是使用one-hot编码,以及是否需要在训练前对特征进行规范化。必须对以语义方式提取的每个字段做出这些决定,从IP地址到每个唯一的TCP选项,再到ICMP地址掩码。即难以脱离人工操作来满足规范化的要求。
-
未对齐二进制表示(unaligned binary representation)
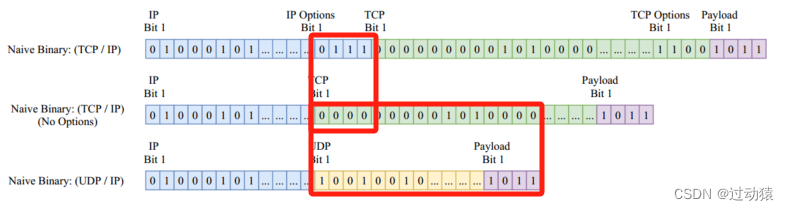
使用原始的位图表示来保持顺序并减少对手动特征工程的依赖。这种选择导致了固定尺度、预规范化的表示,类似于每个数据包的“图像”。满足设计要求中的完整性,固定尺度,规范化。缺点:
- 将每个数据包转换为其位图表示忽略了许多复杂的细节,包括不同的大小和协议。以上图为例,包含IP选项字段的TCP数据包和不含IP选项字段的TCP数据包红框位置的bit含义不同,不含IP选项字段的TCP数据包与不含IP选项字段的UDP数据包红框位置的bit含义也不同,但机器只知道输入的是0,1位信息,无从得知各个bit的含义。
-
混合表示(hybrid nPrint representation)
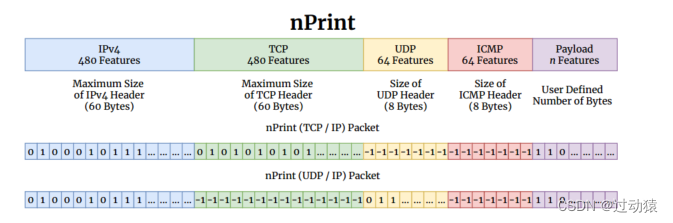
nPrint是语义和二进制数据包表示的混合,将数据包表示为原始二进制数据,但以一种识别数据包本身具有特定语义结构的方式对二进制数据进行对齐。- nPrint 完整性:任何包都可以表示而不丢失信息
- nPrint 固定尺度:每个包都用相同数量的特征来表示。对于给定的问题,我们将有效负载设置为可选的字节数。随着越来越多的网络流量被加密,有效负载无法用于许多流量分类问题。
- nPrint 规范化:通过直接使用数据包的位并用-1填充不存在的头,每个特征取三个值中的一个:-1,0或1,消除了解析和表示每个数据包中每个字段值的需要
- nPrint 对齐:使用内部填充并包括每个报头类型的空间,而不管该报头是否实际存在于给定的数据包中,确保每个数据包以相同数量的特征表示,并且每个特征具有相同的含义
- nPrint模块化:可以将其他协议(例如ICMP)添加到表示中
- nPrint可扩展性:nPrint是一个单包表示,可以用作需要一组包的分类问题的构建块(可以扩展到流分类问题上)
nPrint的优势:
- 对齐使nPrint比许多网络表示具有明显的优势,因为它在位级别上是可解释的。这允许研究人员和从业者将nPrint映射回语义领域,以更好地理解驱动给定模型性能的特征。并不是所有的模型都是可解释的,但是通过一个可解释的表示,我们可以更好地理解那些可解释的模型。
nPrint实现:https://github.com/nprint/nprint
3. nPrintML
nPrintML:https://github.com/nprint/nprintml
-
AutoML
作者使用AutoGluon-Tabular对评估的所有八个问题进行特征选择、模型搜索和超参数优化。
4. 任务
- 主动设备指纹识别(5.1)
- 被动操作系统指纹识别(5.2)
- DTLS应用识别(5.3)
- 其他任务(5.4)
总结
论文内容
-
学到的方法
写论文的方法:
创新点不一定非要设计一个新模型,提高准确率之类的,可以设计一个通用的模型,来简化之前研究,然后收集各个任务的数据集,在每个数据集上跑一下模型
-
论文优缺点
优点:
nPrintML:这种自动化为更快地迭代和部署网络机器学习算法铺平了道路,降低了实际部署的障碍。存在的问题:
- 捕获多个流量之间的时间关系,以及在更长的流量序列上运行nPrintML,仍然没有得到解决
- 当前 nPrintML 只支持两种数据集模式
- 这个工具只适合有原始 pcap 的场景。有些竞赛的数据集之类的,已经帮你把语义信息提取出来了,那么 nPrint 没有 pcap 文件也束手无策。不过这也不能叫完全的缺点,因为 nPrint 在实时分析上的作用还是比较大的
- 好像没说清是nPrint是怎么为实时流量打标签的,需要复现一下看看
工具
- nPrint:https://github.com/nprint/nprint
- nPrintML:https://github.com/nprint/nprintml
数据集
见下表:

可读的引用文献
- AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
笔记参考文献
https://zhuanlan.zhihu.com/p/448215353