哈希表的迭代器:
迭代器模板介绍:
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>K:关键词类型
T:存储的数据类型
Ref:T& (operator*() 解引用函数的返回类型)
Ptr:T* (operator->() 使用指针去操作成员)
KeyOfT:是外面哈希map (哈希map中存的是键值对 键值对的第一个数据就是key 第二个数据就是value 存储的数据) 和哈希set (哈希set中存的是value )
外部会提供调函数去调用关键词key
Hash:是哈希函数将K关键词转化为hashi哈希桶的位置进行存储 将key转化为整数的函数 为了确定哈希桶的位置
哈希迭代器的成员介绍:
Node* _node;
const HashTable<K, T, KeyOfT, Hash>* _pht;
size_t _hashi;迭代器中_node 是实现 operator*(),operator->(),operator!=().
_hashi:每一次桶的位置 operator++()会运用到进行节点的遍历 记录每次桶的位置方便遍历
_pht:哈希表获取哈希桶的数据参数,获取哈希表的成员数据,成员函数等,我个人认为这个成员很方便也很重要
哈希表的默认构造:
__HTIterator(Node* node, HashTable<K, T, KeyOfT, Hash>* pht, size_t hashi)
:_node(node)
,_pht(pht)
,_hashi(hashi)
{}
__HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht, size_t hashi)
:_node(node)
, _pht(pht)
, _hashi(hashi)
{}利用初始化列表进行初始化,根据外面传的参数类型选择对应的默认构造函数,进行初始化构造。
哈希表迭代器中的操作符重载:
* -> !=
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}!=利用迭代器中存储的_node进行判断 判断是否为同一个指针。
* 对节点数据进行引用
-> 对节点数据地址进行返回 但是Ptr=T* (*和-> 相遇会抵消 所以也是数据)
++
Self& operator++()
{
if (_node->_next)
{
// 当前桶还有节点,走到下一个节点
_node = _node->_next;
}
else
{
// 当前桶已经走完了,找下一个桶开始
//KeyOfT kot;
//Hash hf;
//size_t hashi = hf(kot(_node->_data)) % _pht._tables.size();
++_hashi;
while (_hashi < _pht->_tables.size())
{
if (_pht->_tables[_hashi])
{
_node = _pht->_tables[_hashi];
break;
}
++_hashi;
}
if (_hashi == _pht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}这里重点解释一下_node->_next为空之后的操作

1,第一个++hashi 为什么?
因为哈希表中的bigin() 会进行哈希桶的遍历 返回第一个不为空的哈希桶 (用该位置的节点,哈希表指针,哈希桶位置进行迭代器的赋值)但是begin()只会提供第一个不为空的哈希桶位置 不会将哈希桶进行向后遍历 如果该桶的单链表遍历完毕 到末尾nullptr 就应该找下一个通的位置 如果下一个桶的位置也为空 再向后找
第一个++hashi 就是单链表遍历完毕遇到空进行下一个哈希桶的查找
第二个++hashi 是该哈希桶位置本身为空 进行向后的查找
2.找到不为空的哈希表位置之后 再进单链表的迭代遍历
返回的就是迭代器*this
哈希表模板的介绍:
template<class K, class T, class KeyOfT, class Hash>K:关键词类型
T:存储数据类型
KeyOfT:外部提取key所配的专用函数
Hash: 将key转化为整数的函数 为了确定哈希桶的位置
哈希表中的友元:
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
friend struct __HTIterator;由于哈希表迭代器成员中存在哈希表指针,二哈希表指针会访问哈希表成员,所以将哈希表迭代器设置为哈希表的友元。
哈希表中类型的typedef
typedef __HTIterator<K, T, T&, T*, KeyOfT, Hash> iterator;
typedef __HTIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;根据外部的调用进行对应的调用。const迭代器就调用const对应的迭代器。
哈希表的节点:
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};由于哈希桶是单链表构成的所以类节点的成员为该节点类型的指针 和数据 ,将节点初始化为空。
哈希表的查找:
iterator Find(const K& key)
{
Hash hf;
KeyOfT kot;
size_t hashi = hf(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this, hashi);
}
cur = cur->_next;
}
return end();
}这里就是简单的单链表遍历查找,利用哈希函数和KeyOfT外部函数进行关键词的查找,存在返回迭代器,不存在返回end().
哈希表的插入:
pair<iterator, bool> Insert(const T& data)
{
Hash hf;
KeyOfT kot;
iterator it = Find(kot(data));
if (it != end())
return make_pair(it, false);
// 负载因子最大到1
if (_n == _tables.size())
{
vector<Node*> newTables;
newTables.resize(_tables.size() * 2, nullptr);
// 遍历旧表
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while(cur)
{
Node* next = cur->_next;
// 挪动到映射的新表
size_t hashi = hf(kot(cur->_data)) % newTables.size();
cur->_next = newTables[i];
newTables[i] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = hf(kot(data)) % _tables.size();
Node* newnode = new Node(data);
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this, hashi), true);
}首先判断该关键词是存在,如果存在就返回存在数据位置的迭代器和false;
这里面的扩容是插入元素与哈希桶的数量相同就扩容,这里不是固定的,你可以判断每个哈希桶的大小最大不超过多少,再去扩容,这里方法很自由,没有固定的。
对于新表元素的插入,新表元素的插入方法与旧表类似,所以就可以直接赋用旧表的插入方法,这里很容易被看作递归,但不是递归,是代码赋用。
将新表插入完毕之后 再将旧表数据与新表数据进行交换,这里新表出了作用域就调用其对应的析构函数进行析构。大大的方便。
插入成功返回新节点位置的迭代器迭代器进行赋值(存在时的赋值在find函数中有涉及),和true.
哈希表的析构与构造:
HashTable()
{
_tables.resize(10);
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}哈希表的默认构造函数:对vector进行初始容量的 扩容;
哈希表的析构函数:从第一个桶位置开始进行遍历 跳过nullptr位置 将存在数据的位置进行单链表遍历删除 删除完单链表之后 再将该位置置为空。
哈希表的删除:
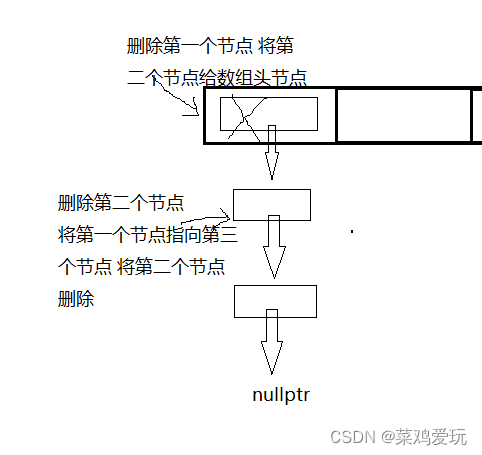
哈希表节点的删除可以分为两种情况:
第一种,删除哈希桶的头节点
第二种,删除除头结点的任意节点
通过哈希函数将key转换为关键词,再遍历哈希桶(单链表)利用KeyOfT将数据进行提取找到要删除的数据 再进行上面两种情况的判断。
bool Erase(const K& key)
{
Hash hf;
KeyOfT kot;
size_t hashi = hf(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}哈希桶长度,数量,最大长度,平均桶长的统计:
void Some()
{
size_t bucketSize = 0;
size_t maxBucketLen = 0;
size_t sum = 0;
double averageBucketLen = 0;
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
++bucketSize;
}
size_t bucketLen = 0;
while (cur)
{
++bucketLen;
cur = cur->_next;
}
sum += bucketLen;
if (bucketLen > maxBucketLen)
{
maxBucketLen = bucketLen;
}
}
averageBucketLen = (double)sum / (double)bucketSize;
printf("all bucketSize:%d\n", _tables.size());
printf("bucketSize:%d\n", bucketSize);
printf("maxBucketLen:%d\n", maxBucketLen);
printf("averageBucketLen:%lf\n\n", averageBucketLen);
}上面代码就是简单的遍历,不做过多讲解。
完整代码:
namespace hash_bucket
{
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
// 前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;
Node* _node;
const HashTable<K, T, KeyOfT, Hash>* _pht;
// vector<Node*> * _ptb;
size_t _hashi;
__HTIterator(Node* node, HashTable<K, T, KeyOfT, Hash>* pht, size_t hashi)
:_node(node)
,_pht(pht)
,_hashi(hashi)
{}
__HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht, size_t hashi)
:_node(node)
, _pht(pht)
, _hashi(hashi)
{}
Self& operator++()
{
if (_node->_next)
{
// 当前桶还有节点,走到下一个节点
_node = _node->_next;
}
else
{
// 当前桶已经走完了,找下一个桶开始
//KeyOfT kot;
//Hash hf;
//size_t hashi = hf(kot(_node->_data)) % _pht._tables.size();
++_hashi;
while (_hashi < _pht->_tables.size())
{
if (_pht->_tables[_hashi])
{
_node = _pht->_tables[_hashi];
break;
}
++_hashi;
}
if (_hashi == _pht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
// unordered_set -> Hashtable<K, K>
// unordered_map -> Hashtable<K, pair<K, V>>
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
typedef HashNode<T> Node;
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
friend struct __HTIterator;
public:
typedef __HTIterator<K, T, T&, T*, KeyOfT, Hash> iterator;
typedef __HTIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;
iterator begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return iterator(_tables[i], this, i);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this, -1);
}
const_iterator begin() const
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return const_iterator(_tables[i], this, i);
}
}
return end();
}
// this-> const HashTable<K, T, KeyOfT, Hash>*
const_iterator end() const
{
return const_iterator(nullptr, this, -1);
}
HashTable()
{
_tables.resize(10);
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
pair<iterator, bool> Insert(const T& data)
{
Hash hf;
KeyOfT kot;
iterator it = Find(kot(data));
if (it != end())
return make_pair(it, false);
// 负载因子最大到1
if (_n == _tables.size())
{
vector<Node*> newTables;
newTables.resize(_tables.size() * 2, nullptr);
// 遍历旧表
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while(cur)
{
Node* next = cur->_next;
// 挪动到映射的新表
size_t hashi = hf(kot(cur->_data)) % newTables.size();
cur->_next = newTables[i];
newTables[i] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = hf(kot(data)) % _tables.size();
Node* newnode = new Node(data);
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this, hashi), true);
}
iterator Find(const K& key)
{
Hash hf;
KeyOfT kot;
size_t hashi = hf(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this, hashi);
}
cur = cur->_next;
}
return end();
}
bool Erase(const K& key)
{
Hash hf;
KeyOfT kot;
size_t hashi = hf(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
void Some()
{
size_t bucketSize = 0;
size_t maxBucketLen = 0;
size_t sum = 0;
double averageBucketLen = 0;
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
++bucketSize;
}
size_t bucketLen = 0;
while (cur)
{
++bucketLen;
cur = cur->_next;
}
sum += bucketLen;
if (bucketLen > maxBucketLen)
{
maxBucketLen = bucketLen;
}
}
averageBucketLen = (double)sum / (double)bucketSize;
printf("all bucketSize:%d\n", _tables.size());
printf("bucketSize:%d\n", bucketSize);
printf("maxBucketLen:%d\n", maxBucketLen);
printf("averageBucketLen:%lf\n\n", averageBucketLen);
}
private:
vector<Node*> _tables;
size_t _n = 0;
};
}