作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
考虑到Stream API在实际开发中使用的频率越来越高,而且在可读性、简洁性和实用性上都十分出色,特别新增一个练习章节,以便帮助大家更好地掌握它。
预先准备实验数据:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("iron", 17, "宁波", 888.8));
}
public static void main(String[] args) {
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}
}练习map()
获取所有的Person的名字
public static void main(String[] args) {
List<String> personNames = list.stream().map(Person::getName).collect(Collectors.toList());
System.out.println(personNames);
}获取一个List,每个元素的内容为:{name}来自{address}
public static void main(String[] args) {
// 这里就没法用方法引用了(没有现成可用的方法),只能用Lambda表达式
List<String> personNames = list.stream()
.map(person -> person.getName() + "来自" + person.address)
.collect(Collectors.toList());
System.out.println(personNames);
}练习filter()
过滤出年龄大于等于18的Person
public static void main(String[] args) {
List<Person> personList = list.stream()
.filter(person -> person.getAge() >= 18)
.collect(Collectors.toList());
System.out.println(personList);
}过滤出年龄大于等于18 并且 月薪大于等于888.8 并且 来自杭州的Person
// 一般写法(这个filter,完全就是强迫别人花时间从头到尾阅读你代码里的细节,而且毫无提示!)
public static void main(String[] args) {
List<Person> personList = list.stream()
.filter(person -> (person.getAge() >= 18 && person.getSalary() > 888.8 && "杭州".equals(person.getAddres()))
.collect(Collectors.toList());
System.out.println(personList);
}
// 较好的写法:当我们需要给filter()、map()等函数式接口传递Lambda参数时,逻辑如果很复杂,最好抽取成方法,优先保证可读性
public static void main(String[] args) {
List<Person> personList = list.stream()
.filter(StreamTest::isRichAdultInHangZhou) // 改为方法引用,见名知意,隐藏琐碎的细节
.collect(Collectors.toList());
System.out.println(personList);
}
/**
* 是否杭州有钱人
*
* @param person
* @return
*/
private static boolean isRichAdultInHangZhou(Person person) {
return person.getAge() >= 18
&& person.getSalary() > 888.8
&& "杭州".equals(person.getAddres());
}统计
获取年龄的min、max、sum、average、count。
很多人看到这个问题,会条件反射地想到先用map()把Person降到Age纬度,然后看看有没有类似min()、max()等方法,思路很合理。
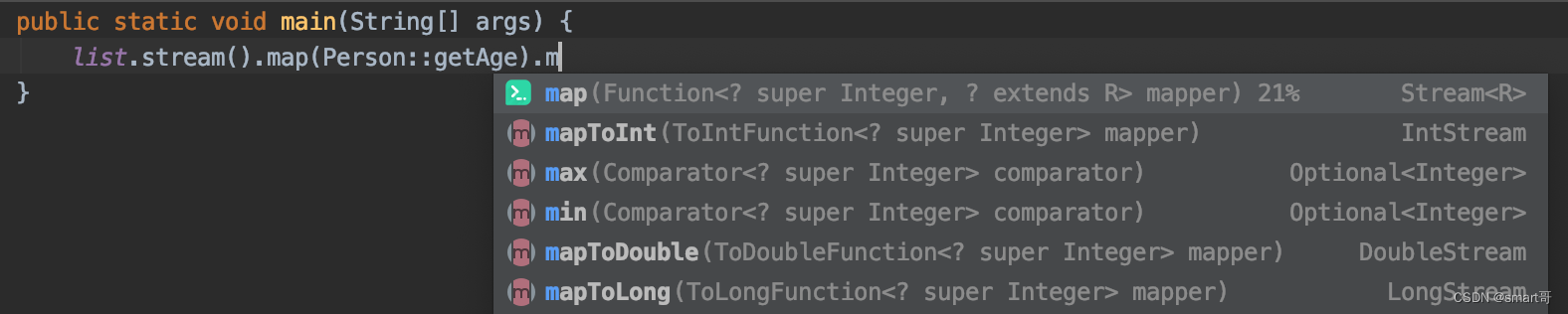
然后会发现:map()后只提供了max()、min()和count()三个方法(且max、min需要传递Comparator对象),没有average()和sum()。
为什么会设计得这么“麻烦”且看起来这么不合理呢?
Stream作为接口,首要任务是保证方法通用性。由于Stream需要处理的元素是不确定的,这次是Integer,下次可能是String,甚至是自定义的Person,所以要使用Stream计算min、max时,必须告诉它“怎样才是最大”、“怎样才是最小”,具体到代码里就是策略模式,需要我们传入比较规则,也就是Comparator对象。
这其实是很合理的,比如当我们把两个人进行比较时,其实都是基于某一个/某一组评判标准的,比如外貌方面,我比吴彦祖帅,或者从身高来看,我比姚明高。所有的比较结果,必须在某一个比较规则之下才成立、才有意义。
至于sum()和average(),Stream干脆没定义...这又是为什么?你想想,如果map()后得到的是name,对于字符类型来说sum()和average()是没有意义的,因为你也说不出一串名字的平均值代表着什么。也就是说sum()和average()不是通用的,不应该定义在Stream接口中。
一句话,Stream接口只提供了通用的max()、min()、count(),而且要自己指定Comparator(策略模式)。
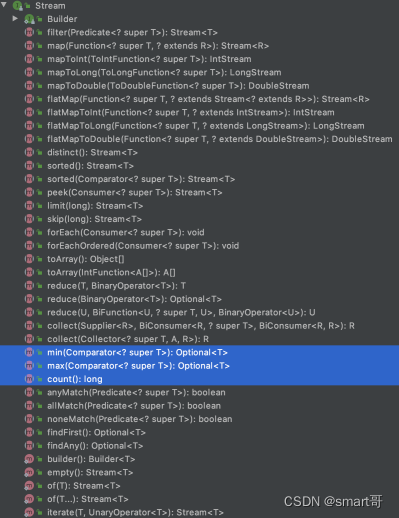
但是,如果你能确定元素的类型,比如int、long啥的,那么可以选择对应的mapToInt()、mapToLong()等方法得到具体类型的Stream:
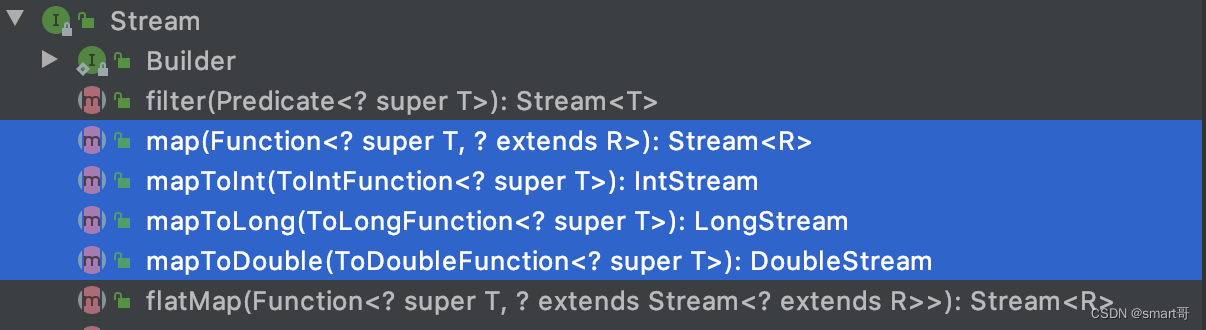
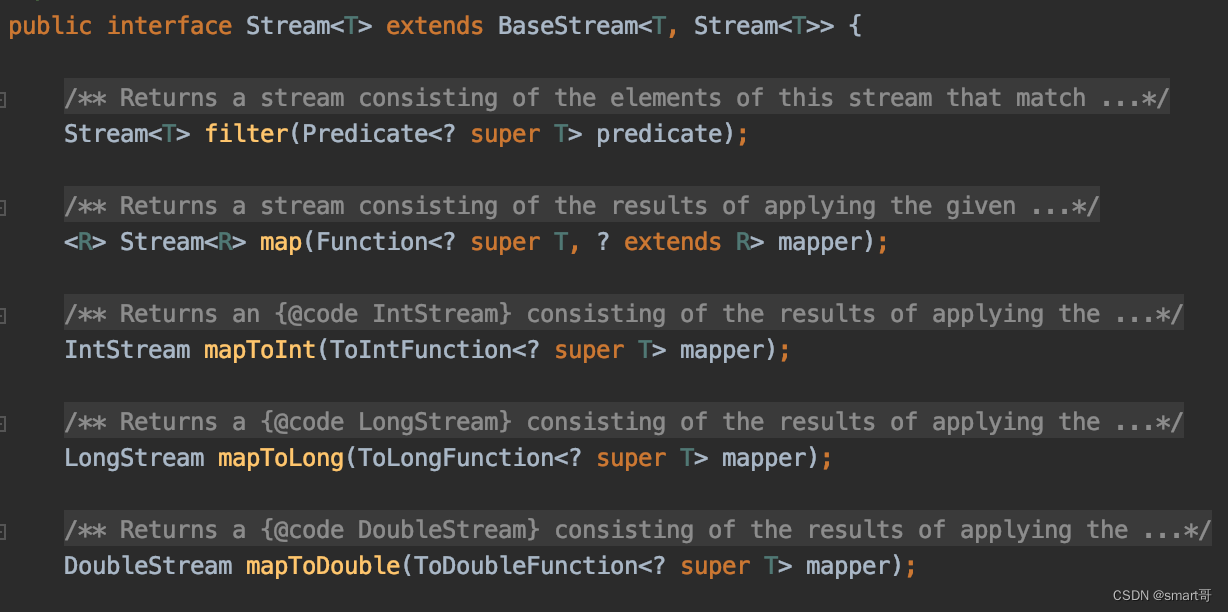
比如得到IntStream后,多了几个方法:
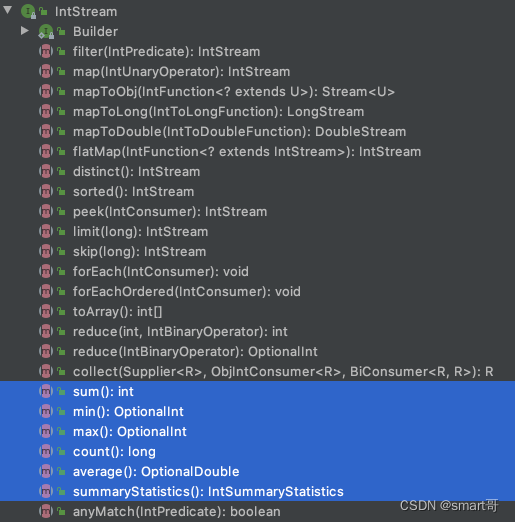
转为具体类型的Stream有以下好处:
- 不用传递Comparator,你都mapToInt()了,那么元素的类型也就确定了,比较的规则自然也确定了(自然数比较)
- 额外新增sum()、average(),因为对于数字类型来说,求和、求平均是有意义的
也就是说,如果你要操作的数据刚好是int、long、double,那么不妨转为IntStream、LongStream、DoubleStream,api会得到相应的增强!
总结:
如果你想要做通用的数据处理,直接使用map()等方法即可,此时返回的是Stream,提供的都是通用的操作。但如果要统计的数据类型恰好是int、long、double,那么使用mapToXxx()方法转为具体的Stream类型后,方法更多更强大,处理起来更为方便!
看到这,大家应该知道这道题这么解了,就不贴代码了。特别注意下最后那个summaryStatistics():五合一。
其实,关于统计的方法,Stream共提供了3大类API,后面会总结。有时选择太多也是一种罪过,难怪有些人会感到混乱。
查找
查找其实分为两大类操作:
- 查找并返回目标值,以findFirst()为代表
- 告诉我有没有即可,无需返回目标值,以anyMatch()为代表
public static void main(String[] args) {
Optional<Person> personMatch = list.stream()
.filter(person -> "宁波".equals(person.getAddress())) // 经过一些筛选,看看有没有符合条件的元素
.findFirst();
personMatch.ifPresent(System.out::println); // 不了解Optional的同学,可以去看后面关于Optional的章节
}public static void main(String[] args) {
// 但有时候你并不关心符合条件的是哪个或哪些元素,只想知道有没有,此时anyMatch()更合适,代码会精炼很多
boolean exists = list.stream().anyMatch(person -> "宁波".equals(person.getAddress()));
}其他3个方法:findAny()、noneMatch()、allMatch()就不介绍了。
练习collect()
最牛逼的一个方法,当你想要实现某种操作却一时找不到具体方法时,一般都是在collect()里,因为它玩法实在太多了!

List转List:Collectors.toList()
所谓List转List,一般指的是原List经过filter()、sorted()、map()、limit()等一顿操作后,最终还是以List的形式返回。
public static void main(String[] args) {
List<String> top2Adult = list.stream()
.filter(person -> person.getAge() >= 18) // 过滤得到年龄大于等于18岁的人
.sorted(Comparator.comparingInt(Person::getAge)) // 按年龄排序
.map(Person::getName) // 得到姓名
.limit(2) // 取前两个数据
.collect(Collectors.toList()); // 得到List<String> names
System.out.println(top2Adult);
}问一个问题:Collectors.toList()默认返回的是ArrayList,如何指定返回LinkedList或其他类型呢?答案见下方练习题。
List转Map:Collectors.toMap()
list转map,一般来说关注两个点:
- 转化后,你要以什么作为key,以什么作为value
- 出现key冲突时怎么解决(保留旧的值还是覆盖旧的值)
public static void main(String[] args) {
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName, // 以name作为key
person -> person, // person->person表示保留整个person作为value
(pre, next) -> pre // (pre, next) -> pre)表示key冲突时保留旧值
));
System.out.println(personMap);
}
// 如果你只需要person的部分数据作为value,比如address
public static void main(String[] args) {
Map<String, String> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Person::getAddress,
(pre, next) -> pre
));
System.out.println(personMap);
}有时你会见到同事这样写:
public static void main(String[] args) {
// Function.identity() 本质上等于 person->person
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Function.identity()
));
System.out.println(personMap);
}
// Function接口定义的方法
static <T> Function<T, T> identity() {
return t -> t;
}Function.identity()只是person->person的另类写法,易读性并不好,而且并没有指定key冲突策略:

所以,即使使用Function.identity(),仍需要手动指定key冲突策略:
public static void main(String[] args) {
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName,
Function.identity(), // 看起来很酷,其实就是v->v,甚至不如v->v直观
(pre, next) -> pre
));
System.out.println(personMap);
}List转Set:Collectors.toSet()
主要目的是利用Set的特性去重。以最常用的HashSet为例,你是否清楚为什么用HashSet存储自定义对象时,要求重写hashCode()和equals()?
因为HashSet本质还是HashMap,只不过HashSet的value是空,只利用了key(HashSet是单列集合,而HashMap是双列集合)。

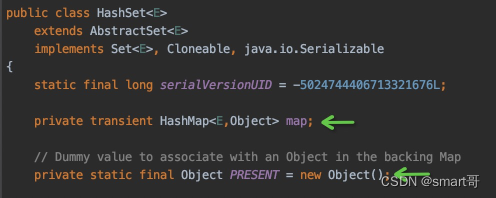
原理挺唬人,使用却很简单:
public static void main(String[] args) {
// String、Integer这些类本身重写了hashCode()和equals(),可以直接toSet()
Set<String> names = list.stream().map(Person::getName).collect(Collectors.toSet());
System.out.println(names);
// 如果你要对自定义的对象去重,比如Person,那么你必须重写hashCode()和equals()
Set<Person> persons = list.stream().collect(Collectors.toSet());
System.out.println(persons);
// 一般来说,用到Collectors.toSet()之前,也是filter()等一顿操作,最后希望去重。像上面那样单纯地想得到Set,可以简单点
Set<Person> anotherPersons = new HashSet<>(list);
System.out.println(anotherPersons);
}
@Getter
@Setter
// 利用Lombok的注解,如果有条件建议手写。Lombok默认把所有字段加入计算,但实际上你可能只需要计算id和name就能确定唯一性
@EqualsAndHashCode
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}去重
和Collectors.toSet()一样,但凡要去重,最关键的就是“怎么判断两个对象是否相同”,于是必须明确“怎样才算相同”。在Java中通常有两种做法:
- 重写hashCode()和equals()
- 指定Comparator(比较器)
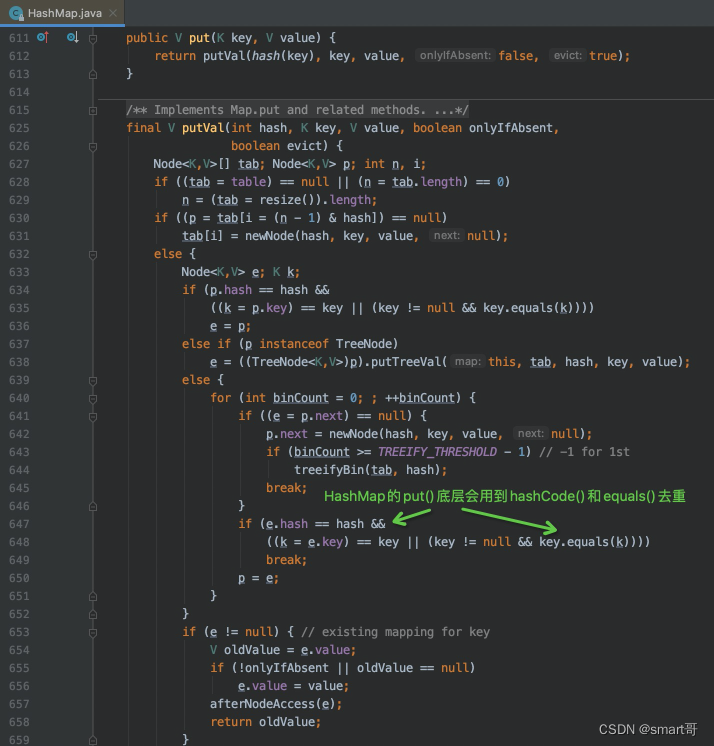
Java8以后Stream API专门提供了distinct()方法用来去重,底层就是根据元素hashCode()和equals方法判断是否相同,然后再去重。
public static void main(String[] args) {
// 如果不重写Person的hashCode()和equals(),去重无效!!!
List<Person> persons = list.stream().distinct().collect(Collectors.toList());
System.out.println(persons);
}你可能感到诧异:不对啊,我平时工作就是这么去重的。其实你平时的写法是这样的:
public static void main(String[] args) {
// Integer、String这些基础包装类已经重写了hashCode()和equals()
List<String> personNameList = list.stream().map(Person::getName).distinct().collect(Collectors.toList());
System.out.println(personNameList);
}有时我们的判断标准是,只要某些字段相同就去重(比如name),该怎么做呢?(注意,我希望的是按name去重,但最终得到的还是PersonList,而不是PersonNameList,所以上面的方法行不通)
第一种办法,仍然重写hashCode()和equals(),但只选择需要的字段(比如你只根据name作为判断标准)。
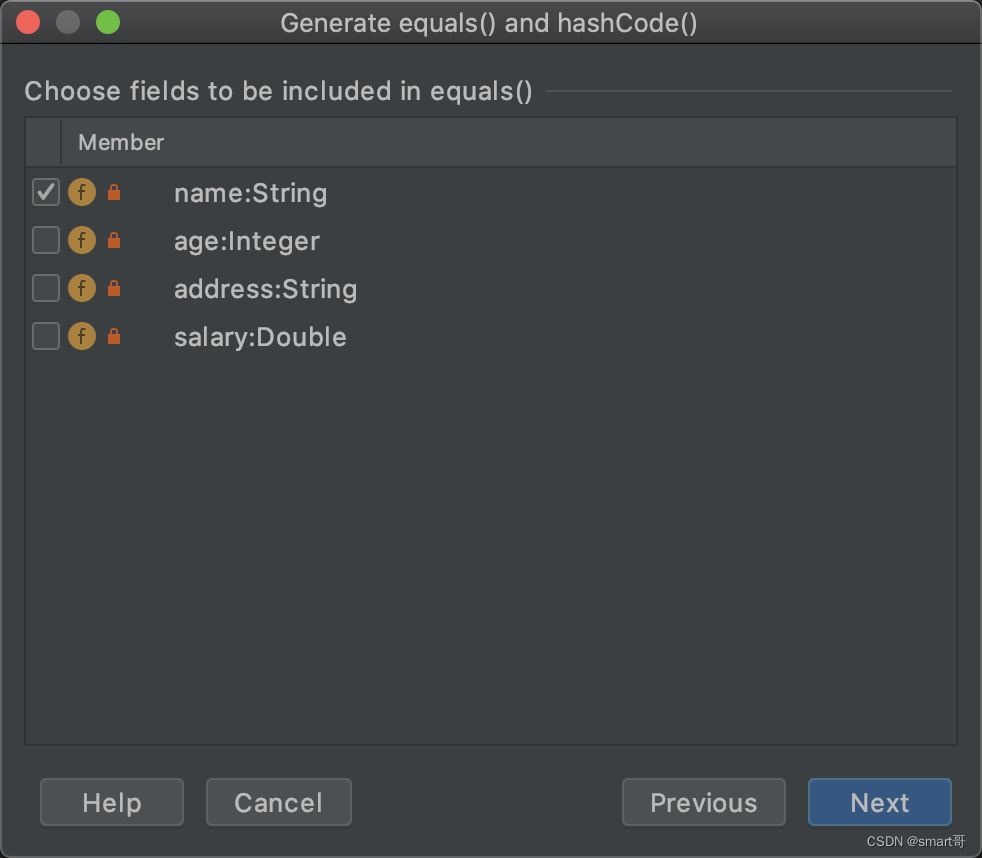
public static void main(String[] args) {
List<Person> persons = list.stream().distinct().collect(Collectors.toList());
System.out.println(persons);
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
// IDEA自动生成的
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return name.equals(person.name);
}
// IDEA自动生成的
@Override
public int hashCode() {
return Objects.hash(name);
}
// 不用理会,只是方便打印观察
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}但这个方法有个缺点,如果这个Pojo不止你一个人用,直接重写hashCode()和equals()可能会影响到别人。
另外hashSet、hashMap这种底层是hash结构的容器,在去重时也会依赖hashCode()和equals()。比如你希望根据name去重,而name是String类型,本身是重写了hashCode()和equals()的,那么可以根据name先去重。比如我们可以利用HashMap完成去重(HashSet同理):
public static void main(String[] args) {
// 先通过Map去重,只保留key不同的对象。
Map<String, Person> personMap = list.stream().collect(Collectors.toMap(
Person::getName, // 用person.name做key,由于key不能重复,即根据name去重
p -> p, // map的value就是person对象本身
(pre, next) -> pre // key冲突策略:key冲突时保留前者(根据实际需求调整)
));
// 然后收集value即可(特别注意,hash去重后得到的person不保证原来的顺序)
List<Person> peoples = new ArrayList<>(personMap.values());
System.out.println(peoples);
}可能还有其他方法,但顶多形式看起来不一样,个人认为底层思路都是一样的:hashCode()和equals()。
介绍完hashCode()和equals()这个派系以后,我们再来说说Comparator,尤其是对于TreeSet这样的容器:
public static void main(String[] args) {
// 先把元素赶到TreeSet中(根据Comparator去重),然后再倒腾回ArrayList
List<Person> list = list.stream().collect(
Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))),
ArrayList::new
)
);
}上面介绍的几种方式,去重后顺序会打乱。关于去重后如何保持元素顺序,网上有很多方法
要做到去重并保持顺序,光靠Stream似乎有点无能为力,也显得比较啰嗦。还记得之前封装的ConvertUtil吗?不妨往里面再加一个方法:
/**
* 去重(保持顺序)
*
* @param originList 原数据
* @param distinctKeyExtractor 去重规则
* @param <T>
* @param <K>
* @return
*/
public static <T, K> List<T> removeDuplication(List<T> originList, Function<T, K> distinctKeyExtractor) {
LinkedHashMap<K, T> resultMap = new LinkedHashMap<>(originList.size());
for (T item : originList) {
K distinctKey = distinctKeyExtractor.apply(item);
if (resultMap.containsKey(distinctKey)) {
continue;
}
resultMap.put(distinctKey, item);
}
return new ArrayList<>(resultMap.values());
}总的来说,去重通常有两类做法:要么通过重写hashCode和equals,要么传入Comparator(Comparable接口也行)。
分组
Stream的分组有两类操作:
- 字段分组
- 条件分组

先看字段分组。所谓的groupingBy(),和MySQL的GROUP BY很类似,比如:
public static void main(String[] args) throws JsonProcessingException {
// 简单版
Map<String, List<Person>> result = list.stream().collect(Collectors.groupingBy(Person::getAddress));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}得到的结果类似于:
{
"温州": [
{
"name": "am",
"age": 19,
"address": "温州",
"salary": 777.7
}
],
"宁波": [
{
"name": "iron",
"age": 17,
"address": "宁波",
"salary": 888.8
}
],
"杭州": [
{
"name": "i",
"age": 18,
"address": "杭州",
"salary": 999.9
},
{
"name": "iron",
"age": 21,
"address": "杭州",
"salary": 888.8
}
]
}总的来说,groupingBy()的最终结果是Map,key是分组的字段,value是属于该分组的所有元素集合,默认是List。
为什么我说默认是List呢?因为我们还可以自行指定将分组元素收集成到什么容器中,比如Set:
public static void main(String[] args) throws JsonProcessingException {
// groupingBy()还可以传入第二个参数,指定如何收集元素
Map<String, Set<Person>> result = list.stream().collect(Collectors.groupingBy(Person::getAddress, Collectors.toSet()));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}如果你期望得到的是各个城市的年龄构成呢?比如:
{
"温州": [
19
],
"宁波": [
17
],
"杭州": [
18,
21
]
}做法是,可以把Collectors.toSet()替换成Collectors.mapping(),然后进行嵌套:
public static void main(String[] args) throws JsonProcessingException {
// 进阶版版
Map<String, List<Integer>> result = list.stream().collect(Collectors.groupingBy(
Person::getAddress, // 以Address分组
Collectors.mapping(Person::getAge, Collectors.toList())) // mapping()的做法是先映射再收集
);
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}其他过于复杂的api就不再介绍了,太多了反而会乱。实际开发时,如果遇到某个场景,可以自行百度,一般都能解决问题。总之要记住,collect()里面经常可以通过“套娃”操作完成复杂的需求。
有了这么好用的groupingBy(),为啥还需要partitioningBy()呢?因为groupingBy()也是有局限性的,它不能自定义“分组条件”。比如,如果你的分组条件是:
- 年龄大于18岁 && 来自杭州 的分为一组
- 其他的分为另一组
那么groupingBy()就无能为力了。
此时,支持自定义分组条件的partitioningBy()就派上用场:
public static void main(String[] args) throws JsonProcessingException {
// 简单版
Map<Boolean, List<Person>> result = list.stream().collect(Collectors.partitioningBy(StreamTest::condition));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
// 年龄大于18,且来自杭州
private static boolean condition(Person person) {
return person.getAge() > 18
&& "杭州".equals(person.getAddress());
}{
"false": [
{
"name": "i",
"age": 18,
"address": "杭州",
"salary": 999.9
},
{
"name": "am",
"age": 19,
"address": "温州",
"salary": 777.7
},
{
"name": "iron",
"age": 17,
"address": "宁波",
"salary": 888.8
}
],
"true": [
{
"name": "iron",
"age": 21,
"address": "杭州",
"salary": 888.8
}
]
}partitioningBy()也返回Map,但key是true/false,因为条件分组的依据要么true、要么false。partitioningBy()也支持各种嵌套,大家自己尝试即可。
排序
说到排序,大家最先想到的是Stream API中的sorted(),共有两个方法,其中一个支持传入Comparator:

排序的前提是比较,而只要涉及到比较,就必须明确比较的标准是什么。
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}大家猜猜上面代码的运行结果是什么?
答案是:报错。

在学习Java基础时,我们了解到,如果希望进行对象间的比较:
- 要么对象实现Comparable接口(对象自身可比较)
- 要么传入Comparator进行比较(引入中介,帮对象们进行比较)
就好比你和朋友进行100米比赛,要么你们自己计时,要么请个裁判。而上面sorted()既然没有传入Comparator,那么Person要实现Comparable接口:
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}
@Getter
@Setter
@EqualsAndHashCode
@AllArgsConstructor
static class Person implements Comparable<Person> {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
// 定义比较规则
@Override
public int compareTo(Person anotherPerson) {
return anotherPerson.getAge() - this.getAge();
}
}这样就可以了。
但是,同样是sorted(),为什么下面的代码不会报错呢?
public static void main(String[] args) {
List<Integer> result = StreamTest.list.stream()
.map(Person::getAge)
.sorted()
.collect(Collectors.toList());
System.out.println(result);
}因为String、Integer都已经实现了Comparable接口:

sorted()容易采坑而且语义不够明确,个人建议使用sort(Comparator),显式地传入比较器:
public class ComparatorTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, 170));
list.add(new Person("am", 19, 180));
list.add(new Person("am", 20, 180));
list.add(new Person("iron", 19, 181));
list.add(new Person("iron", 19, 179));
list.add(new Person("man", 17, 160));
list.add(new Person("man", 16, 160));
}
public static void main(String[] args) {
// 先按身高降序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge).reversed());
System.out.println(list);
// 先按身高升序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高降序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).reversed().thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高升序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparing(Person::getAge, Comparator.reverseOrder()));
System.out.println(list);
/**
* 大家可以理解为Comparator要实现排序可以有两种方式:
* 1、comparingInt(keyExtractor)、comparingLong(keyExtractor)... + reversed()表示倒序,默认正序
* 2、comparing(keyExtractor, Comparator.reverseOrder()),不传Comparator.reverseOrder()表示正序
*
* 第四个需求如果采用reversed(),似乎达不到效果,反正我没查到。
* 个人建议,单个简单的排序,无论正序倒序,可以使用第一种,简单一些。但如果涉及多个联合排序,建议使用第二种,语义明确不易搞错。
*
* 最后,上面是直接使用Collection的sort()方法,请大家自行改成Stream中的sorted()实现一遍。
*/
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private Integer height;
}
}截取
对于List的截取,可能大家都习惯用List.subList(),但它有个隐形的坑:对截取后的List进行元素修改,会影响原List(除非你就希望改变原List)。
究其原因,subList()并非真的从原List截取出元素,而是偏移原List的访问坐标罢了:

比如你要截取(5, 6),那么下次你get(index),我就直接返回5+index给你,看起来好像真的截取了。
另外,这个方法限制太大,用起来也麻烦,比如对于一个不确定长度的原List,如果你想做以下截取操作:list.subList(0, 5)或者list.subList(2, 5),当原List长度不满足List.size()>=5时,会抛异常。为了避免误操作,你必须先判断size:
if(list != null && list.size()>=5) {
return list.subList(2, 5);
}较为简便和安全的做法是借助Stream(Stream一个很重要的特性是,不修改原数据,而是新产生一个流):
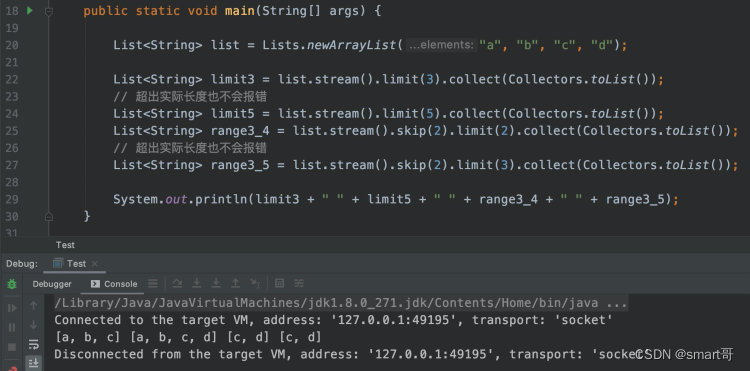
public static void main(String[] args) {
List<String> list = Lists.newArrayList("a", "b", "c", "d");
List<String> limit3 = list.stream().limit(3).collect(Collectors.toList());
// 超出实际长度也不会报错
List<String> limit5 = list.stream().limit(5).collect(Collectors.toList());
List<String> range3_4 = list.stream().skip(2).limit(2).collect(Collectors.toList());
// 超出实际长度也不会报错
List<String> range3_5 = list.stream().skip(2).limit(3).collect(Collectors.toList());
System.out.println(limit3 + " " + limit5 + " " + range3_4 + " " + range3_5);
}
多用Stream
Stream有个很重要的特性,常常被人忽略:Stream操作并不改变原数据。这个特性有什么用呢?
假设有两个List,AList和BList。AList固定10个元素,BList元素长度不固定,0~10个。
要求:
要把AList和BList合并,BList的元素在前,合并后的List不能有重复元素(过滤AList),且不改变两个List原有元素的顺序。
你可以先思考一下怎么处理。
之前介绍过List转Map然后利用Key去重的方法,但转Map后元素顺序可能会打乱,为了保证顺序,你可能会选择双层for:
for (int i = aList.size() - 1; i >= 0; i--) {
for (Item bItem : bList) {
// 注意,思考一下aItem.get(i)有没有问题
if (Objects.equals(bItem.getItemId(), aList.get(i).getItemId())) {
aList.remove(i);
}
}
}
// bList在前
bList.addAll(aList);当aList.remove(i)以后,第二层for又执行aList.get(i)就有可能造成数组越界异常,比如aList.remove(9),移除第10个元素,但第二层for在下一轮还是aList.get(9),此时aList其实只有9个元素。改进的写法可以是这样:
for (int i = aList.size() - 1; i >= 0; i--) {
// 在第一层for取出aItem,且只取一次
Item aItem = aList.get(i);
for (Item bItem : bList) {
if (Objects.equals(bItem.getItemId(), aItem.getItemId())) {
aList.remove(i);
}
}
}
// bList在前
bList.addAll(aList);但这样不够直观,而且下次再有类似需求,可能还是心惊胆战。此时使用Stream可以编写出更为安全、易读的代码:
Map<String, Item> bItemMap = ConvertUtil.listToMap(bList, Item::getItemId);
// 对aList去重(收集bList中没有的元素)
aList = aList.stream().filter(aItem -> !bItemMap.contains(aItem.getItemId())).collect(Collectors.toList());
// bList在前
bList.addAll(aList);当然,List其实也提供了取并集、差集的方法,只不过上面的做法会更通用一些,但这不是重点。这里主要是想提醒大家,对于原数组的增删改操作一不小心会带来意想不到的问题,比如数组越界、并发修改异常等,此时用Stream往往是更安全的做法。
小结
- filter()、map()如果逻辑过长,最好抽取函数
- IntStream、LongStream、DoubleStream在统计方面比Stream方法更丰富,更好用
- collect()是最强大的,但一般掌握上面6种情景问题不大
- 去重的原理是利用hashCode()和equals()来确定两者是否相同,无论是自定义对象还是String、Integer等常用内置对象,皆是如此
- 排序的原理是,要么自身实现Comparable接口,要么传入Comparator对象,总之要明确比较的规则
- 平时可能觉得skip()、limit()用不到,但需要截取List或者内存分页时,可以尝试一下
- 尽量用Stream代替List原生操作,代码健壮性和可读性都会提升一个台阶
关于collect()还有很多玩法这里没有提及,大家可以自己没事玩一玩。
public static void main(String[] args) {
// 统计其实有三大类:stream直接统计、IntStream等具体的Stream统计、collect()中统计
// Stream直接统计:min/max/count
Optional<Person> collect1 = list.stream().min(Comparator.comparingInt(Person::getAge));
Optional<Person> collect2 = list.stream().max(Comparator.comparingInt(Person::getAge));
long count = list.stream().count();
// IntStream/LongStream/DoubleStream统计:min/max/count/average/sum/summaryStatistics
OptionalInt min = list.stream().mapToInt(Person::getAge).min();
OptionalInt max = list.stream().mapToInt(Person::getAge).max();
long count = list.stream().mapToInt(Person::getAge).count();
OptionalDouble average = list.stream().mapToInt(Person::getAge).average();
int sum = list.stream().mapToInt(Person::getAge).sum();
IntSummaryStatistics intSummaryStatistics = list.stream().mapToInt(Person::getAge).summaryStatistics();
// collect()统计,和IntStream们类似,可以被优化为上面两种写法,不常用
list.stream().collect(Collectors.minBy(Comparator.comparingInt(Person::getAge)));
list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge)));
list.stream().collect(Collectors.averagingDouble(...));
list.stream().collect(Collectors.averagingLong(...));
list.stream().collect(Collectors.averagingInt(...));
list.stream().collect(Collectors.summingDouble(...));
list.stream().collect(Collectors.summingDouble(...));
list.stream().collect(Collectors.summingInt(...));
list.stream().collect(Collectors.counting());
list.stream().collect(Collectors.summarizingDouble(...));
list.stream().collect(Collectors.summarizingInt(...));
list.stream().collect(Collectors.summarizingLong(...));
}还有个Collectors.joining()用来拼接字符串、Collectors.collectingAndThen()用来组合操作的。
练习题
先来回答上文的一个小问题:Collectors.toList()默认返回ArrayList,如何返回LinkedList?
public static void main(String[] args) {
List<String> top2Adult = list.stream()
.filter(person -> person.getAge() >= 18) // 过滤得到年龄大于等于18岁的人
.sorted(Comparator.comparingInt(Person::getAge)) // 按年龄排序
.map(Person::getName) // 得到姓名
.limit(2) // 取前两个数据
.collect(Collectors.toCollection(LinkedList::new)); // 返回LinkedList,其他同理
System.out.println(top2Adult);
}留了3道思考题给大家,分别关于flatMap()、分组统计、还有一个我自己前几天实际开发遇到的一个问题。
1、FlatMap:
public class FlatMapTest {
/**
* 需求:
* 1.要求返回所有的key,格式为 list<Long> 提示:keyset
* 2.要求最终返回所有value,格式为 List<Long> 提示:flatMap(),Function需要啥你就转成啥
*
* @param args
*/
public static void main(String[] args) {
Map<Long, List<Long>> map = new HashMap<>();
map.put(1L, new ArrayList<>(Arrays.asList(1L, 2L, 3L)));
map.put(2L, new ArrayList<>(Arrays.asList(4L, 5L, 6L)));
}
}2、分组统计:
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}1.要求分组统计出各个城市的年龄总和,返回格式为 Map<String, Integer>。
2.要求得到Map<城市, List<用户工资>>
3、实际开发遇到的问题:处理优惠券信息

某个优惠券服务返回的List如上图左边的JSON,希望处理成上图右边的格式。大家有什么好的方案吗?
public class CouponTest {
public static void main(String[] args) throws JsonProcessingException {
List<CouponResponse> coupons = getCoupons();
// TODO 对优惠券统计数量
ObjectMapper objectMapper = new ObjectMapper();
System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(getCoupons()));
}
private static List<CouponResponse> getCoupons() {
return Lists.newArrayList(
new CouponResponse(1L, "满5减4", 500L, 400L),
new CouponResponse(1L, "满5减4", 500L, 400L),
new CouponResponse(2L, "满10减9", 1000L, 900L),
new CouponResponse(3L, "满60减50", 6000L, 5000L)
);
}
@Data
@AllArgsConstructor
static class CouponResponse {
private Long id;
private String name;
private Long condition;
private Long denominations;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
static class CouponInfo {
private Long id;
private String name;
private Integer num;
private Long condition;
private Long denominations;
}
}作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬



![[黑皮系列] 计算机网络:自顶向下方法(第8版)](https://img-blog.csdnimg.cn/direct/459fe81a9f264dfd9483a468e5702892.jpeg#pic_center)