参考文档
yolov5-github
yolov5-github-训练文档
csdn训练博客
一、配置环境
1.1 安装依赖包
前往清华源官方地址 选择适合自己的版本替换自己的源
# 备份源文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list_bak
# 修改源文件
# 更新
sudo apt update && sudo apt upgrade -y
安装必要的环境依赖包
sudo apt-get install -y build-essential ubuntu-drivers-common net-tools python3 python python3-pip
# 修改pip源为清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
1.2 安装docker
具体安装步骤参考ubuntu安装docker官方文档
-
卸载所有冲突包
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done -
设置 Docker 的
apt存储库# Add Docker's official GPG key: sudo apt-get update sudo apt-get install -y ca-certificates curl gnupg sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg sudo chmod a+r /etc/apt/keyrings/docker.gpg # Add the repository to Apt sources: echo \ "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update -
安装最新的docker包
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
1.3 拉取pytorch docker镜像
前往pytorch 官方docker镜像寻找自己合适版本,yolov5要求1.8以上版本,我拉取1.13版本,执行命令:
sudo docker pull pytorch/pytorch:1.13.1-cuda11.6-cudnn8-runtime
1.4 安装nvidia驱动
桌面版参考链接
服务器版参考链接
我们使用pytorch-docker环境无需安装cuda,NVIDIA驱动简单安装如下
-
禁用nouveau驱动
编辑 /etc/modprobe.d/blacklist-nouveau.conf 文件,添加以下内容:
blacklist nouveau blacklist lbm-nouveau options nouveau modeset=0 alias nouveau off alias lbm-nouveau off -
关闭nouveau
echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf -
重新生成内核并重启
sudo update-initramfs -u sudo reboot -
重启后验证
重启后,执行:lsmod | grep nouveau。如果没有屏幕输出,说明禁用nouveau成功 -
查找推荐驱动
ubuntu-drivers devices # 输出如下 # modalias : pci:v000010DEd00001EB8sv000010DEsd000012A2bc03sc02i00 # vendor : NVIDIA Corporation # model : TU104GL [Tesla T4] # driver : nvidia-driver-450-server - distro non-free # driver : nvidia-driver-525-server - distro non-free # driver : nvidia-driver-535-server - distro non-free # driver : nvidia-driver-418-server - distro non-free # driver : nvidia-driver-525 - distro non-free # driver : nvidia-driver-470 - distro non-free # driver : nvidia-driver-470-server - distro non-free # driver : nvidia-driver-535 - distro non-free recommended # driver : xserver-xorg-video-nouveau - distro free builtin -
安装推荐的驱动程序
根据自己系统选择安装,安装完成后重启
sudo apt install nvidia-driver-535-server -
重启后验证
nvidia-smi命令能够输出显卡信息则验证成功
1.5 安装nvidia docker gpus工具
为了让docker支持nvidia显卡,英伟达公司开发了nvidia-docker,该软件是对docker的包装,使得容器能够看到并使用宿主机的nvidia显卡。
根据网上的资料,从docker 19版本之后,nvidia-docker成为了过去式。不需要单独去下nvidia-docker这个独立的docker应用程序,也就是说gpu docker所需要的Runtime被集成进docker中,使用的时候用–gpus参数来控制。以下是工具安装步骤:
# step1 添加包存储库,在终端依次输入以下命令:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# step2 下载安装nvidia-container-toolkit包
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
# step3 重启docker服务
sudo systemctl restart docker
二、训练数据集
2.1 下载yolov5代码
前往github下载代码,或者准备自己的yolov5训练代码,如果是拷贝他人代码,将**.git目录删除**,否则后续训练时检查git信息会报错。
git clone git@github.com:ultralytics/yolov5.git
2.2 启动进入pytorch-docker
# 映射宿主机地址到docker内部,根据显卡实际情况指定显存容量
sudo docker run -v /home/zmj/lishi:/workspace --gpus all --shm-size 18g -p 6006:6006 -it pytorch/pytorch:1.13.1-cuda11.6-cudnn8-runtime /bin/bash
后续都将在docker中执行;
2.3 安装依赖项
在docker下进入yolov5代码目录下将request.txt的opencv注释掉然后执行依赖项安装
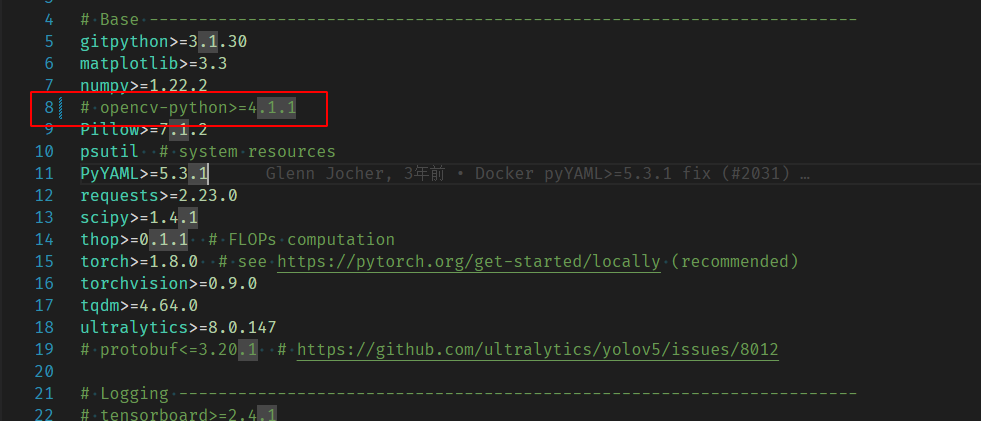
pip3 install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
继续安装opencv-python-headless版本opencv;
pip3 install opencv-python-headless
2.4 创建文件
将标准好的图像文件夹命名为images,标签文件夹命名为Annotations都放到源码目录的data文件夹下(注意: images内为数据集原始图片,Annotations内为标注的xml文件,对这两个文件夹做好备份);
在yolov5根目录下创建make_txt.py文件,内容如下:
import os
import random
# 函数:确保文件夹存在,如果不存在则创建
def ensure_folder_exists(folder):
if not os.path.exists(folder):
os.makedirs(folder)
print(f"Created folder: {folder}")
# 检查并创建所需文件夹
folders = ["data/ImageSets", "data/JPEGImages", "data/labels"]
for folder in folders:
ensure_folder_exists(folder)
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
file_paths = []
file_paths.append(os.path.join(txtsavepath, 'trainval.txt'))
file_paths.append(os.path.join(txtsavepath, 'test.txt'))
file_paths.append(os.path.join(txtsavepath, 'train.txt'))
file_paths.append(os.path.join(txtsavepath, 'val.txt'))
for file_path in file_paths:
with open(file_path, 'w') as file:
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
if file_path.endswith('trainval.txt'):
file.write(name)
if i in train:
if file_path.endswith('test.txt'):
file.write(name)
else:
if file_path.endswith('val.txt'):
file.write(name)
else:
if file_path.endswith('train.txt'):
file.write(name)
file.close()
os.chmod(file_path, 0o666) # 设置文件权限
print("Finished!")
创建voc_label.py内容如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 函数:确保文件夹存在,如果不存在则创建
def ensure_folder_exists(folder):
if not os.path.exists(folder):
os.makedirs(folder)
print(f"Created folder: {folder}")
# 检查并创建所需文件夹
folders = ["data/ImageSets", "data/JPEGImages", "data/labels"]
for folder in folders:
ensure_folder_exists(folder)
sets = ['train', 'test','val']
#此处修改为实际标注内容
classes = ['fall']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
file_path = 'data/labels/%s.txt' % (image_id)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
if(w==0 or h==0):
in_file.close()
print(image_id,"w ", w, "h ", h, "0 error")
image_file = 'data/images/%s.jpg' % (image_id)
xml_file = 'data/Annotations/%s.xml' % (image_id)
os.remove(image_file)
os.remove(xml_file)
return
out_file = open('data/labels/%s.txt' % (image_id), 'w')
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
os.chmod(file_path, 0o666) # 设置文件权限
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
file_path = 'data/%s.txt' % (image_set)
with open(file_path, 'w') as list_file:
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
os.chmod(file_path, 0o666) # 设置文件权限
print("Finished!")
依次执行上述两个脚本,如果执行voc_labels.py提示有w 0 h 0 errror字样,说明标注的宽高有0异常,会删除异常标签和图片,重新执行这两个脚本
python3 make_txt.py
python3 voc_label.py
执行完成后会在data下创建ImageSets文件夹和labels文件夹大致内容如下:
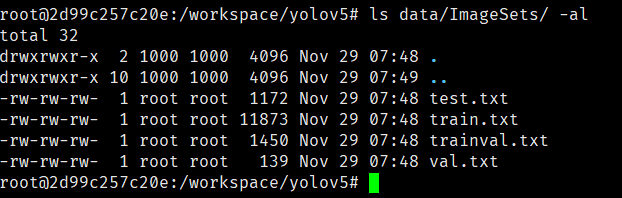

data下生成三个txt文件

2.5 修改yaml文件
复制data目录下的coco.yaml,我这里命名为fall.yaml,参照参考文档主要修改三个地方:
-
修改train,val,test的路径为自己刚刚生成的路径;
-
nc 里的数字代表数据集的类别,我这里只有跌倒一类,所以修改为1;
-
names 里为自己数据集标注的类名称,我这里是
fall;内容如下
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license # COCO 2017 dataset http://cocodataset.org by Microsoft # Example usage: python train.py --data coco.yaml # parent # ├── yolov5 # └── datasets # └── coco ← downloads here (20.1 GB) # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] # path: ../datasets/coco # dataset root dir # train: train2017.txt # train images (relative to 'path') 118287 images # val: val2017.txt # val images (relative to 'path') 5000 images test: data/test.txt # dataset root dir train: data/train.txt # train images (relative to 'path') 128 images val: data/val.txt # val images (relative to 'path') 128 images # test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794 nc: 1 # number of classes names: ['fall'] # class names # Download script/URL (optional) download: | from utils.general import download, Path # Download labels segments = False # segment or box labels dir = Path(yaml['path']) # dataset root dir url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/' urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels download(urls, dir=dir.parent) # Download data urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional) download(urls, dir=dir / 'images', threads=3)
2.6 修改模型文件
models下有5个模型,smlx需要训练的时间依次增加,按照需求选择一个文件进行修改即可,我选择yolov5s.yaml,只需将nc改为实际值即可;
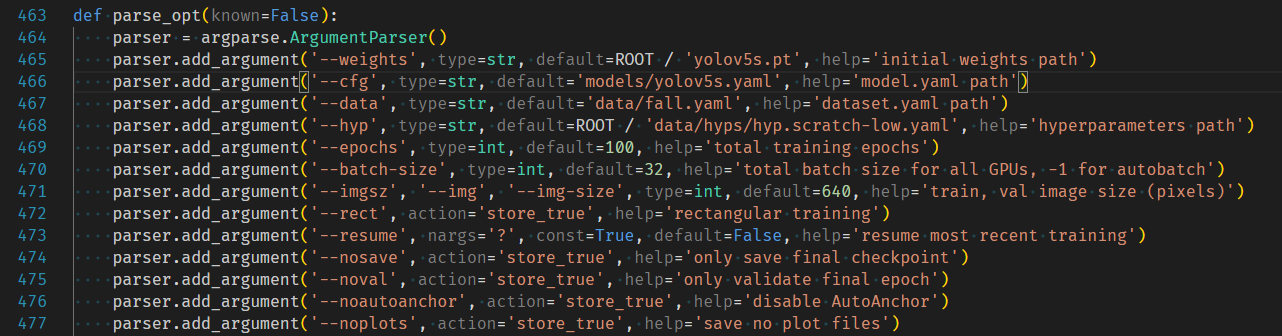
2.7修改训练tran.py
这里需要对train.py文件内的参数进行修改,weights,cfg,data按照自己所需文件的路径修改,weights如果使用参考博客的文件,将yolov5s.pt下载放到代码根目录下即可,如果使用官方则无需修改,会自行下载。具体参数含义,查看官方文档。我修改内容如下:
2.8 开始训练
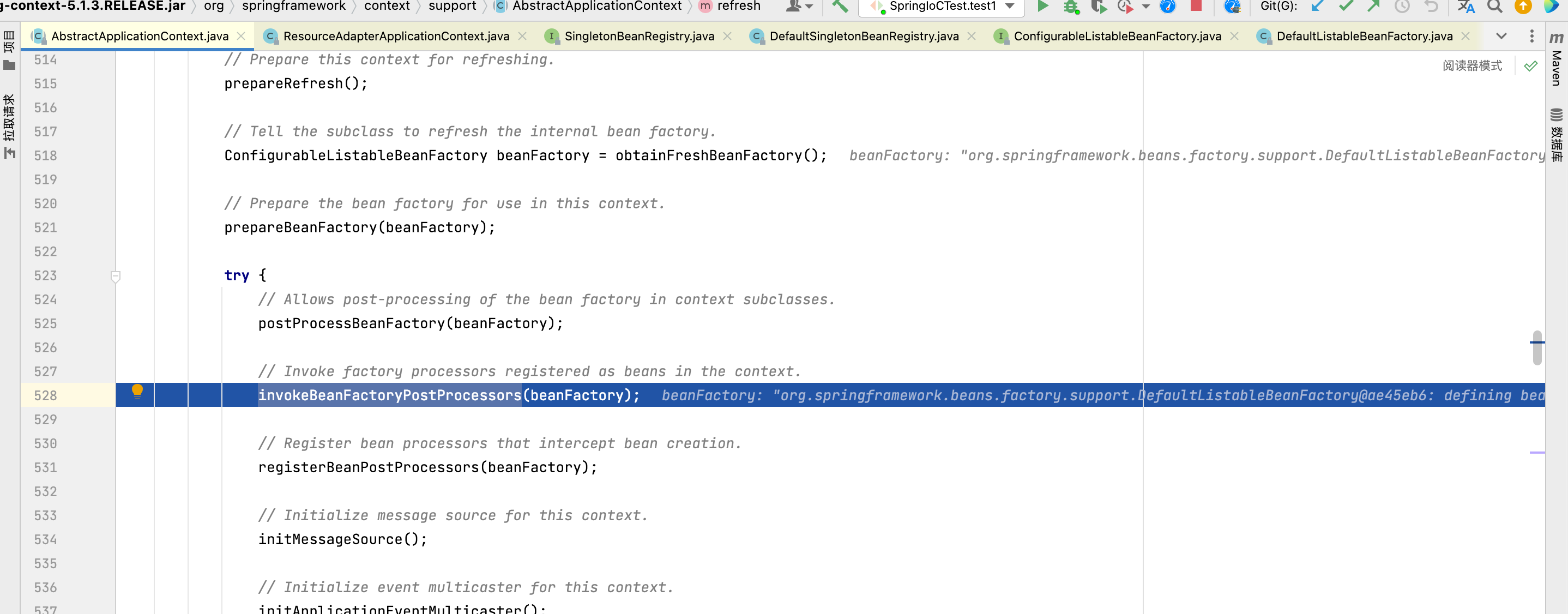
执行python train.py
可能报以下错误:
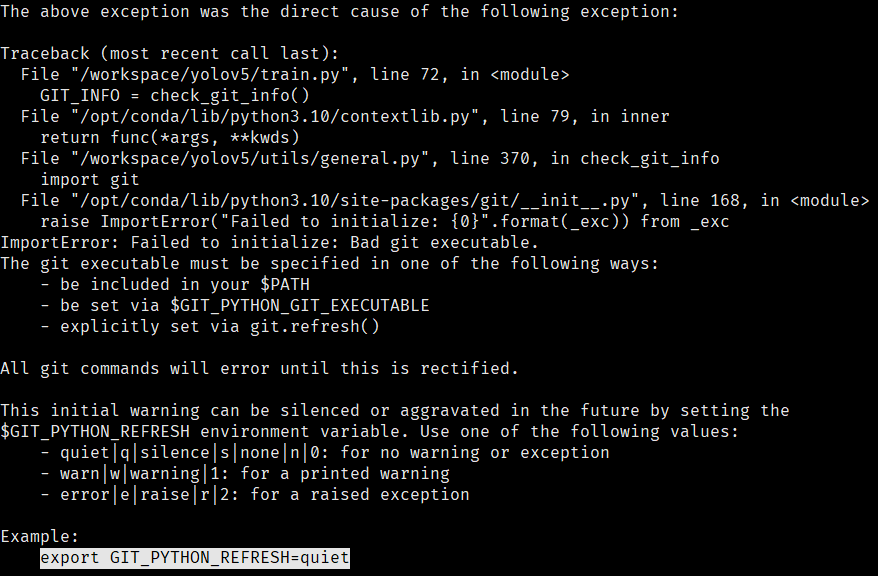
按照提示执行export GIT_PYTHON_REFRESH=quiet继续执行训练命令,就可以开始训练了。