矩阵快速幂
矩阵快速幂可以用来优化递推问题,如状态机DP,需要一丢丢线性代数里面矩阵的概念,只需要知道简单的矩阵乘法,结合我们普通的二分快速幂就能很快的掌握矩阵快速幂。
问题引入
三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模1000000007。
对于这种递推入门题目,相信只要对于编程有着一定了解的人都能够很快的解决掉。
假如我们用传统递推
f
(
0
)
=
1
,
f
(
1
)
=
1
,
f
(
2
)
=
2
f
(
n
)
=
f
(
n
−
1
)
+
f
(
n
−
2
)
+
f
(
n
−
3
)
\begin{array}{c} f(0) = 1 , f(1) = 1 , f(2) = 2\\ f(n) = f(n-1) + f(n - 2) + f(n - 3) \end{array}
f(0)=1,f(1)=1,f(2)=2f(n)=f(n−1)+f(n−2)+f(n−3)
const int MOD = 1e9 + 7;
int dp[1000001];
int waysToStep(int n) {
memset(dp , 0 , sizeof(dp));
dp[0] = 1, dp[1] = 1 , dp[2] = 2;
for(int i = 3 ; i <= n ; i++)
dp[i] = ((long long)dp[i - 3] + dp[i - 2] + dp[i - 1]) % MOD;
return dp[n];
}
时间复杂度:O(N) 空间复杂度:O(N)
因为每次状态都由前三个状态转移过来,如果用滚动数组优化
const int MOD = 1e9 + 7;
int waysToStep(int n) {
int dp0 = 1, dp1 = 1 , dp2 = 2;
if(n <= 1) return 1;
if(n == 2) return 2;
for(int i = 3 ; i <= n ; i++)
{
int newdp = ((long long)dp0 + dp1 + dp2) % MOD;
dp0 = dp1 , dp1 = dp2 , dp2 = newdp;
}
return dp2;
}
空间复杂度优化到了O(1),时间复杂度仍为O(N)
到滚动数组优化这一步对于大多数初学者来说已经很不错了,如果我们想更进一步呢?
我们重新分析递推公式
f
(
0
)
=
1
,
f
(
1
)
=
1
,
f
(
2
)
=
2
f
(
n
)
=
f
(
n
−
1
)
+
f
(
n
−
2
)
+
f
(
n
−
3
)
\begin{array}{c} f(0) = 1 , f(1) = 1 , f(2) = 2\\ f(n) = f(n-1) + f(n - 2) + f(n - 3) \end{array}
f(0)=1,f(1)=1,f(2)=2f(n)=f(n−1)+f(n−2)+f(n−3)
递推公式到向量计算
第一步
我们尝试把递推公式写成矩阵乘上一个列向量的形式,如下:
( f ( n ) ? ? ) = ( 1 1 1 ? ? ? ? ? ? ) ( f ( n − 1 ) f ( n − 2 ) f ( n − 3 ) ) \begin{pmatrix} f(n)\\ ?\\ ? \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ ? & ? & ? \\ ? & ? & ? \end{pmatrix} \begin{pmatrix} f(n - 1)\\ f(n - 2) \\ f(n - 3) \end{pmatrix} f(n)?? = 1??1??1?? f(n−1)f(n−2)f(n−3)
第二步
接着尝试填充?部分
( f ( n ) f ( n − 1 ) f ( n − 2 ) ) = ( 1 1 1 ? ? ? ? ? ? ) ( f ( n − 1 ) f ( n − 2 ) f ( n − 3 ) ) \begin{pmatrix} f(n)\\ f(n - 1)\\ f(n - 2) \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ ? & ? & ? \\ ? & ? & ? \end{pmatrix} \begin{pmatrix} f(n - 1)\\ f(n - 2) \\ f(n - 3) \end{pmatrix} f(n)f(n−1)f(n−2) = 1??1??1?? f(n−1)f(n−2)f(n−3)
第三步
补充矩阵中的部分,就得到了:
( f ( n ) f ( n − 1 ) f ( n − 2 ) ) = ( 1 1 1 1 0 0 0 1 0 ) ( f ( n − 1 ) f ( n − 2 ) f ( n − 3 ) ) \begin{pmatrix} f(n)\\ f(n - 1)\\ f(n - 2) \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} f(n - 1)\\ f(n - 2) \\ f(n - 3) \end{pmatrix} f(n)f(n−1)f(n−2) = 110101100 f(n−1)f(n−2)f(n−3)
第四步
你以为到这里就结束了?我们在该式子的基础上带入n - 1作为变量,则有:
( f ( n − 1 ) f ( n − 2 ) f ( n − 3 ) ) = ( 1 1 1 1 0 0 0 1 0 ) ( f ( n − 2 ) f ( n − 3 ) f ( n − 4 ) ) \begin{pmatrix} f(n - 1)\\ f(n - 2)\\ f(n - 3) \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} f(n - 2)\\ f(n - 3) \\ f(n - 4) \end{pmatrix} f(n−1)f(n−2)f(n−3) = 110101100 f(n−2)f(n−3)f(n−4)
第五步
我们把第四步中的式子带入到第三步中,就会得到
( f ( n ) f ( n − 1 ) f ( n − 2 ) ) = ( 1 1 1 1 0 0 0 1 0 ) ( 1 1 1 1 0 0 0 1 0 ) ( f ( n − 2 ) f ( n − 3 ) f ( n − 4 ) ) \begin{pmatrix} f(n)\\ f(n - 1)\\ f(n - 2) \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} f(n - 2)\\ f(n - 3) \\ f(n - 4) \end{pmatrix} f(n)f(n−1)f(n−2) = 110101100 110101100 f(n−2)f(n−3)f(n−4)
第六步
我们不断地迭代下去就会有这样一个式子:
(
f
(
n
)
f
(
n
−
1
)
f
(
n
−
2
)
)
=
(
1
1
1
1
0
0
0
1
0
)
n
−
2
(
f
(
2
)
f
(
1
)
f
(
0
)
)
\begin{pmatrix} f(n)\\ f(n - 1)\\ f(n - 2) \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix}^{n-2} \begin{pmatrix} f(2)\\ f(1) \\ f(0) \end{pmatrix}
f(n)f(n−1)f(n−2)
=
110101100
n−2
f(2)f(1)f(0)
我们发现f(n)的计算还可以通过计算出一个已知矩阵的n - 2次幂与一个列向量的乘积来获取。那么这样的计算方式可以令我们算法的执行效率得到提高吗?
对于两个M阶矩阵做乘积,其时间复杂度为O(M^3),进行n - 2次,那么时间复杂度就是O(M^3 * n),似乎与我们的传统递归相比还要慢上常数阶,于是这就引出了我们今天的主题矩阵快速幂
普通二分快速幂
关于二分快速幂的介绍在笔者的另一篇博客有详细介绍及证明二分快速幂和快读快写模板【C++】-CSDN博客
对于我们快速求a ^ b % p,我们可以不断地二分为(a ^ 2) ^ (b / 2) % p…
如果出现b为奇数,就使得我们最终的返回值ans(ans初始为1)乘上a,当指数为0的时候循环执行完毕,此时ans就是我们的答案。
同样的思想也可以用于矩阵的幂运算中。
代码如下
inline long long quickPower(int a, int b, int p)
{
long long ans = 1;
while (b)
{
if (b & 1)
{
ans = ans * a % p;
}
a = a * a % p;
b /= 2;
}
return ans;
}
矩阵二分快速幂
由普通二分快速幂对矩阵做推广,可有如下递归式
A
n
=
{
I
n
=
0
(
A
n
−
1
2
)
2
×
A
n
为奇数
(
A
n
2
)
2
×
A
n
为非零偶数
A^{n} = \left\{\begin{matrix} I\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ n=0 \\ (A^{\frac{n-1}{2}})^2\times A \ \ \ \ \ \ \ n为奇数 \\ (A^{\frac{n}{2}})^2\times A \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ n为非零偶数 \\ \end{matrix}\right.
An=⎩
⎨
⎧I n=0(A2n−1)2×A n为奇数(A2n)2×A n为非零偶数
那么我们只需要把普通二分快速幂模板中整数乘法更换成矩阵乘法即可。
矩阵类的定义
struct Matrix
{
int m[101][101];
Matrix()
{
memset(m, 0, sizeof(m));
}
};
矩阵乘法的运算符重载
Matrix operator*(const Matrix &x, const Matrix &y)
{
Matrix ret;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
for (int k = 1; k <= n; k++)
ret.m[i][j] = (ret.m[i][j] + (x.m[i][k] * y.m[k][j]) % MOD) % MOD;
return ret;
}
矩阵快速幂模板
Matrix MatrixQuickPower(const Matrix &A, int k)
{
Matrix res;
for (int i = 1; i <= n; i++)
res.m[i][i] = 1; // 单位矩阵
while (k)
{
if (k & 1)
res = res * A;
A = A * A;
k >>= 1;
}
return res;
}
矩阵快速幂就是对普通二分快速幂的基础上,将运算对象更改为了矩阵罢了。
矩阵乘法的常数级优化
我们发现矩阵乘法这里y每次访问m[k][j]寻址需要跳过一整行,对性能其实是有一定影响的,我们可以把第二层循环和第三层循环进行交换
Matrix operator*(const Matrix &x, const Matrix &y)
{
Matrix ret;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
for (int k = 1; k <= n; k++)
ret.m[i][j] = (ret.m[i][j] + (x.m[i][k] * y.m[k][j]) % MOD) % MOD;
return ret;
}
则有
Matrix operator*(const Matrix &x, const Matrix &y)
{
Matrix ret;
for (int i = 1; i <= n; i++)
for (int k = 1; k <= n; k++)
for (int j = 1; j <= n; j++)
ret.m[i][j] = (ret.m[i][j] + (x.m[i][k] * y.m[k][j]) % MOD) % MOD;
return ret;
}
这样既不影响结果,又降低了寻址消耗。
矩阵快速幂在状态机DP中的应用
如果你学习过数字逻辑电路,相信对于时序电路中的有限状态机不会陌生,没有学过也没有关系,因为学了也不会状态机DP,做算法题早晚都要面对的
其实虽然状态机DP在动态规划中算是一类难度不低的问题,但是只要多做几道题就会很快的掌握其套路,相较于背包问题,难度低了不少,因为套路更容易掌握。
下面详解一道题,留下另一道题供读者练手。
OJ题目精讲
935. 骑士拨号器
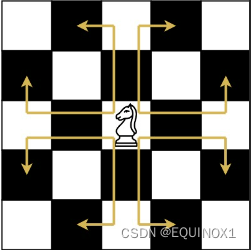
象棋骑士有一个独特的移动方式,它可以垂直移动两个方格,水平移动一个方格,或者水平移动两个方格,垂直移动一个方格(两者都形成一个 L 的形状)。
象棋骑士可能的移动方式如下图所示:
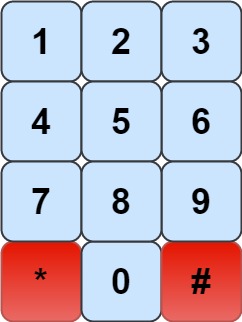
我们有一个象棋骑士和一个电话垫,如下所示,骑士只能站在一个数字单元格上(即蓝色单元格)。
给定一个整数 n,返回我们可以拨多少个长度为 n 的不同电话号码。
你可以将骑士放置在任何数字单元格上,然后你应该执行 n - 1 次移动来获得长度为 n 的号码。所有的跳跃应该是有效的骑士跳跃。
因为答案可能很大,所以输出答案模
109 + 7.
对于长度为n的电话号码,每个位置有10种情况,如果没有题目中的限制,我们通过简单的组合数学就可以解决.
但现在每个位置可以移动的方式都给出了限制,也就是说在每个位置可以抵达的下一个位置是确定且有限的.
我们如果把每个位置都看做成是一种状态,那么我们有如下的状态转移关系:
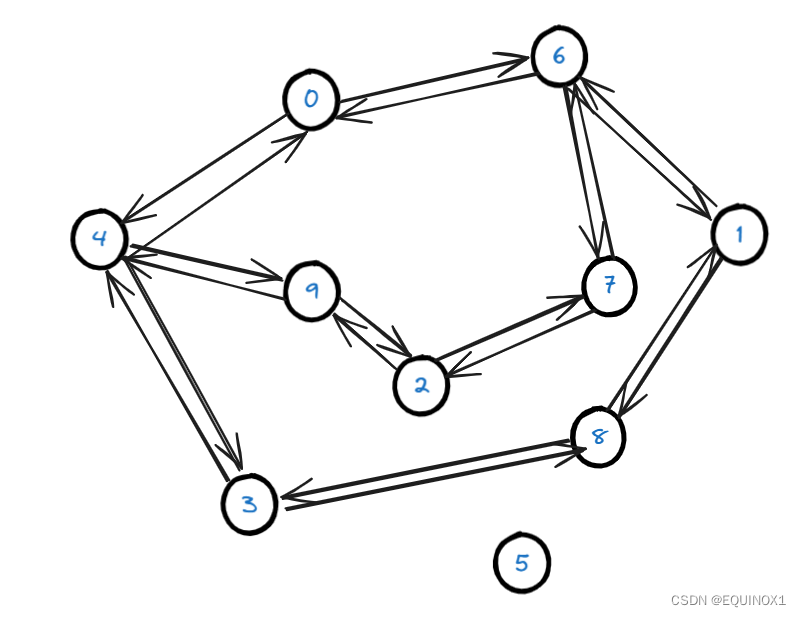
我们定义状态dp[i][j]为第i次移动后在位置j的情况数,那么我们有如下状态转移方程:
d
p
[
i
]
[
j
]
=
∑
d
p
[
i
−
1
]
[
k
]
,
其中
j
可由
k
转移
dp[i][j] = \sum dp[i-1][k],其中j可由k转移
dp[i][j]=∑dp[i−1][k],其中j可由k转移
非矩阵快速幂解法
我们打表列出每个位置的的前驱状态,然后执行状态转移方程,最后对dp[n][i]进行累加即可
class Solution {
public:
const int MOD = 1e9 + 7;
vector<vector<int>> pre{
{4 , 6} , {6 , 8} , {7 , 9} , {4 , 8} , {0 , 3 , 9} , {} , {0 , 1 , 7} , {2 , 6} , {1 , 3} , {2 , 4}
};
int knightDialer(int n) {
vector<vector<int>> dp(n + 1 , vector<int>(10));
for(int i = 0 ; i < 10 ; i++)
dp[1][i] = 1;
for(int i = 2 ; i <= n ; i++)
{
for(int j = 0 ; j < 10 ; j++)
{
for(auto x : pre[j])
dp[i][j] = (dp[i - 1][x] + dp[i][j]) % MOD;
}
}
long long ret = 0;
for(int i = 0 ; i < 10 ; i++)
ret = (ret + dp[n][i]) % MOD;
return ret;
}
};
滚动数组优化
由于每个状态只与上一次状态有关,所以我们还可以优化二维为一维,代码如下:
class Solution {
public:
const int MOD = 1e9 + 7;
vector<vector<int>> pre{
{4 , 6} , {6 , 8} , {7 , 9} , {4 , 8} , {0 , 3 , 9} , {} , {0 , 1 , 7} , {2 , 6} , {1 , 3} , {2 , 4}
};
int knightDialer(int n) {
vector<int> dp(10);
for(int i = 0 ; i < 10 ; i++)
dp[i] = 1;
for(int i = 2 ; i <= n ; i++)
{
vector<int> newdp(10);
for(int j = 0 ; j < 10 ; j++)
{
for(auto x : pre[j])
newdp[j] = (dp[x] + newdp[j]) % MOD;
}
dp = newdp;
}
long long ret = 0;
for(int i = 0 ; i < 10 ; i++)
ret = (ret + dp[i]) % MOD;
return ret;
}
};
矩阵快速幂解法
其实我们对于我们矩阵快速幂优化递推问题而言,只要提前写出矩阵A的行列式即可。对于本题我们分析
n
e
w
d
p
[
0
]
=
d
p
[
4
]
+
d
p
[
6
]
n
e
w
d
p
[
1
]
=
d
p
[
6
]
+
d
p
[
8
]
n
e
w
d
p
[
2
]
=
d
p
[
7
]
+
d
p
[
9
]
.
.
.
\begin{array}{c} newdp[0] = dp[4]+dp[6]\\ newdp[1] = dp[6]+dp[8]\\ newdp[2] = dp[7]+dp[9]\\ ... \end{array}
newdp[0]=dp[4]+dp[6]newdp[1]=dp[6]+dp[8]newdp[2]=dp[7]+dp[9]...
对于我们的10x10矩阵A的行列式可以很容易的计算出,于是我们的递推公式的矩阵表示为:
$$
\begin{pmatrix}
dpn(0)\
dpn(1)\
dpn(2)\
dpn(3)\
dpn(4)\
dpn(5)\
dpn(6)\
dpn(7)\
dpn(8)\
dpn(9)
\end{pmatrix} =\begin{pmatrix}
{0, 0, 0, 0, 1, 0, 1, 0, 0, 0}\
{0, 0, 0, 0, 0, 0, 1, 0, 1, 0}\
{0, 0, 0, 0, 0, 0, 0, 1, 0, 1}\
{0, 0, 0, 0, 1, 0, 0, 0, 1, 0}\
{1, 0, 0, 1, 0, 0, 0, 0, 0, 1}\
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0}\
{1, 1, 0, 0, 0, 0, 0, 1, 0, 0}\
{0, 0, 1, 0, 0, 0, 1, 0, 0, 0}\
{0, 1, 0, 1, 0, 0, 0, 0, 0, 0}\
{0, 0, 1, 0, 1, 0, 0, 0, 0, 0}
\end{pmatrix}^{n} \begin{pmatrix}
dp(0)\
dp(1)\
dp(2)\
dp(3)\
dp(4)\
dp(5)\
dp(6)\
dp(7)\
dp(8)\
dp(9)
\end{pmatrix}
$$
我们矩阵运算时间复杂度为O(103),执行logn次,这样我们的时间复杂度就降到了**O(103 * logn)**
代码如下:
const int MOD = 1e9 + 7;
struct Matrix
{
long long m[10][10];
Matrix()
{
memset(m, 0, sizeof(m));
}
Matrix(int x) :m{
{0, 0, 0, 0, 1, 0, 1, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 1, 0, 1, 0},
{0, 0, 0, 0, 0, 0, 0, 1, 0, 1},
{0, 0, 0, 0, 1, 0, 0, 0, 1, 0},
{1, 0, 0, 1, 0, 0, 0, 0, 0, 1},
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{1, 1, 0, 0, 0, 0, 0, 1, 0, 0},
{0, 0, 1, 0, 0, 0, 1, 0, 0, 0},
{0, 1, 0, 1, 0, 0, 0, 0, 0, 0},
{0, 0, 1, 0, 1, 0, 0, 0, 0, 0}
}
{}
};
Matrix A, dp;
Matrix operator*(const Matrix& x, const Matrix& y)
{
Matrix ret;
for (int i = 0; i < 10; i++)
for (int k = 0; k < 10; k++)
for (int j = 0; j < 10; j++)
ret.m[i][j] = (ret.m[i][j] + (x.m[i][k] * y.m[k][j]) % MOD) % MOD;
return ret;
}
Matrix MatrixQuickPower(Matrix& A, int k)
{
Matrix res;
for (int i = 0; i < 10; i++)
res.m[i][i] = 1; // 单位矩阵
while (k)
{
if (k & 1)
res = res * A;
A = A * A;
k >>= 1;
}
return res;
}
int init(int n)
{
A = Matrix(1);
for (int i = 0; i < 10; i++)
dp.m[i][0] = 1;
Matrix dpn = MatrixQuickPower(A, n - 1) * dp;
int ret = 0;
for (int i = 0; i < 10; i++)
ret = (ret + dpn.m[i][0]) % MOD;
return ret;
}
class Solution {
public:
int knightDialer(int n) {
return init(n);
}
};
遥遥领先
这里省事直接套模板了,有很多拷贝是可以优化掉的。就不演示了(懒x_x)
练习题OJ链接
这道题留给大家练习
552. 学生出勤记录 II - 力扣(LeetCode)