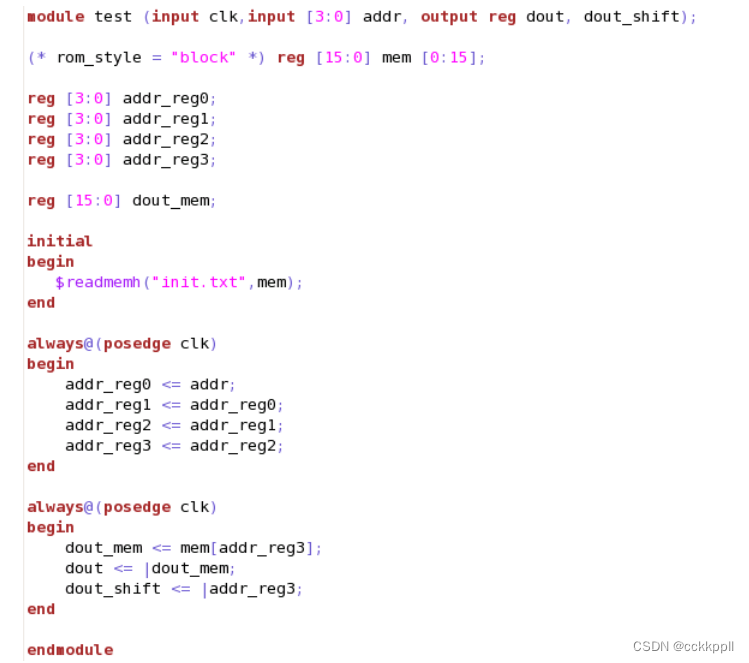
1、最优化
RAMB
输入逻辑以允许输出寄存器推断
以下
RTL
代码片段可从块
RAM
(
实际上为
ROM
)
生成关键路径
,
其中包含多个止于触发器
(FF)
的逻辑层次。
RAMB单元已在无可选输出寄存器 (DOA-0)
的情况下完成推断
,
这给
RAMB
输出路径增加了超过
1 ns
的额外延迟惩罚。
工具显示的对应以上
RTL
代码的关键路径如下图所示。

最好在综合后以及每个实现步骤后复查关键路径以识别需改进哪些逻辑组。如有任何路径过长
,
或者未能以最优方式利用 FPGA
硬件功能
,
请返回
RTL
描述
,
尝试了解已综合的逻辑未实现最优化的原因
,
并修改代码以帮助综合工具改进网表。
Vivado
具有强大的嵌入式调试机制
,
可供您用于开始使用细化视图。细化视图有助于识别问题可能的来源
,
而无需手动搜索整个 RTL
代码。请参阅下图中所示对应上述
RTL
代码片段的细化视图。

细化视图提供了有关给定测试案例结构效率低下的有效提示。在此例中
,
问题来自地址寄存器扇出
(addr_reg3_reg)
,它用于驱动存储器地址和部分胶合逻辑(
蓝色高亮
)
。
由综合工具执行的
RAMB
推断要求
RTL
代码中存在专用地址寄存器
,
这与当前地址寄存器扇出不兼容。由此导致综合工具对输出寄存器进行重定时以允许执行 RAMB
推断
,
而不是使用它来启用
RAMB
可选输出寄存器。
通过复制
RTL
代码中的地址寄存器
,
使用独立寄存器来驱动存储器地址和互连逻辑或
FPGA
逻辑
,
即可在启用输出寄存器的情况下推断 RAMB
。
手动复制后的
RTL
代码和细化视图如下图所示
:


已修改的
RTL
代码的关键路径如下图所示。请注意
:
•
addr_reg2_reg
寄存器已连接到块
RAM
的地址管脚。
•
addr_reg3_reg
寄存器在块
RAM
中已被吸收。
•
RAMB
输出寄存器已启用
,
由此显著降低了
RAMB
输出上的数据路径延迟。
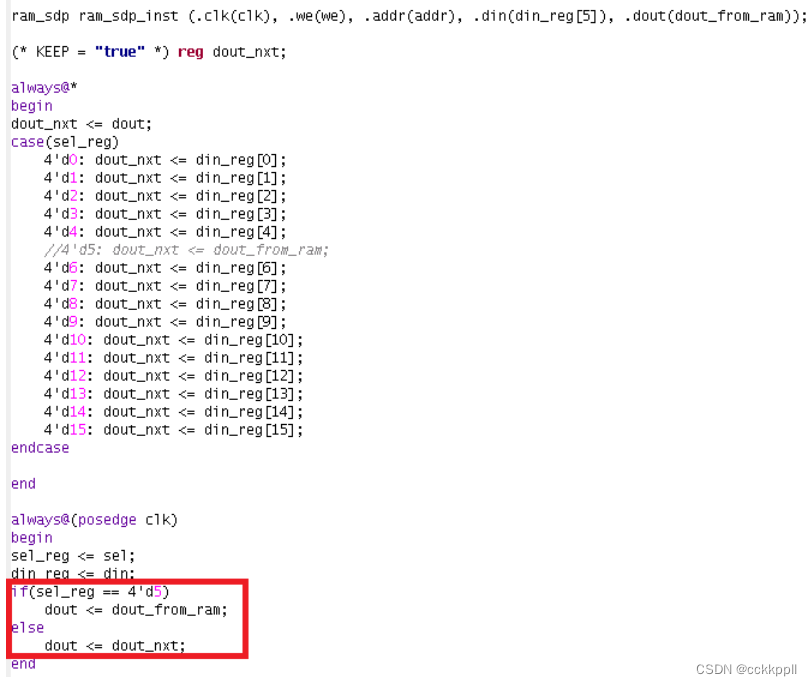
2、改进
RAMB
输出上的关键逻辑
以下测试用例以将宏
(
块
RAM
)
推送至距离目标寄存器更近的位置为例
,
重点提供了有关通过重构来对关键路径进行改进的信息。
下图显示了
1
个
16x1
多路复用器
,
其中仅含
1
个从块
RAM
到多路复用器的输入
,
其余输入由寄存器馈送。
关键路径
:
块
RAM-> 2
个逻辑层次
-> FF
。

下图显示的关键路径中
,
以红色高亮显示块
RAM
到
FF
的路径。块
RAM->FF
和
FF->FF
都存在
2
个逻辑层次。由于块 RAM CLK->Q
延迟对于块
RAM
更高
,
因此
RAM->FF
为关键路径。

下一步
,
请注意下图中所示
RTL
代码
,
查看是否能够重构逻辑。

重构逻辑的最佳方法是将
16x1
多路复用器拆分为
2
个多路复用器来重写上述代码片段。您可将选择值
4'd5
的条件豁免,
将其用作为
2x1
多路复用器的启用条件
(
如下图所示
),
创建此级联多路复用器结构可生成含
3
个逻辑层次的 FF->FF;
但块
RAM->FF
减少至
1
个逻辑层次。这样即可改进块
RAM->FF
路径
,
从而帮助下游工具实现更好的布局
,因为 RAMB
布局比
LUT
和
FF
布局难度更高。总之
,
对于任意给定设计
,
减少宏原语
(
如
RAMB
、
URAM
和
DSP
)
周围的长路径即可改进 QoR
结果。