文章信息
论文题目:HeteroTiC: A robust network flow watermarking based on heterogeneous time channels
期刊(会议):Computer Networks
时间:2022
级别:CCF B
文章链接:https://doi.org/10.1016/j.comnet.2022.109424
概述
为了进一步抵抗非合作网络环境中的各种干扰,本文提出了一种基于异质时间通道的鲁棒网络流水印方法(命名为HeteroTiC),旨在克服单个数据包特征和静态配置水印方法的缺陷。对于HeteroTiC,数据包顺序、数据包定时和数据包大小是三个时间通道,用于携带水印,并深度集成以建立具有特征融合的异质时间通道。该论文的主要贡献如下:
- 基于异质时间通道(HeteroTiC)设计并提出了鲁棒的NFW方法。通过协同调制数据包顺序和数据包定时,提高了NFW对严重网络噪声对数据包定时的鲁棒性。
- 使用数据包顺序序列的反序数解决了水印同步问题。对于特定时间窗口,如果数据包的乱序程度超过阈值,则立即检测到水印的存在,而无需特定的乱序序列,从而支持对水印存在的快速检测能力。
- 嵌入比特的时间窗口长度是动态配置的,用于抵御数据包丢失和避免其他人分析NFW的参数。每个时间窗口可以通过少数数据包进行自同步,最终的时间窗口可以通过反序的数据包顺序确定。
- 原始水印信息序列通过模2加法与数据包大小转换为动态二进制序列,从而克服了数据包定时和水印的二进制信息之间的静态映射,提高了网络水印的隐蔽性。
相关工作
如图2所示,根据数据包特征的水印载体,当前方法可以从稳健性和隐蔽性两个方面进行分类。
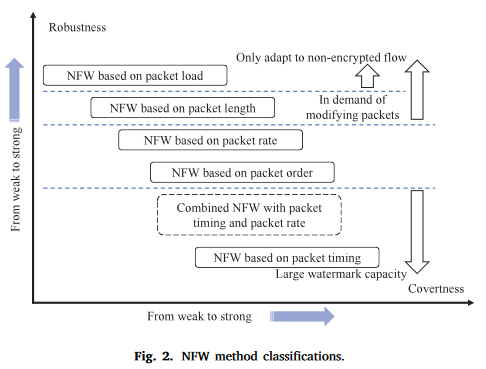
表1列出了所有具有代表性的经典NFW方法,每个方法都基于单个分组特征,以增强鲁棒性和隐蔽性。为了使水印能够适应具有噪声的复杂现实网络环境,并保持水印的隐秘性,我们尝试结合分组顺序、分组时序和分组大小,在异构时间信道上建立融合特征来提高水印性能。它不同于ICBSSW和IBSSW,后者是基于完全不同的分组特征而不是仅基于分组时序模式设计的。分组顺序是一个鲁棒的特征,它可以在严重的时延抖动情况下生存。分组定时是一种自适应特性,即使通过复杂的垫脚石传输流,也可以保持该特性。因此,如果两个或多个特征可以协同使用,则可以克服时间窗口的偏差、长识别信息传输和不确定的时延抖动。同时,融合特征可以消除单个特征的弱点,这促使我们分析并提出了基于融合特征的NFW方法:HeteroTiC。
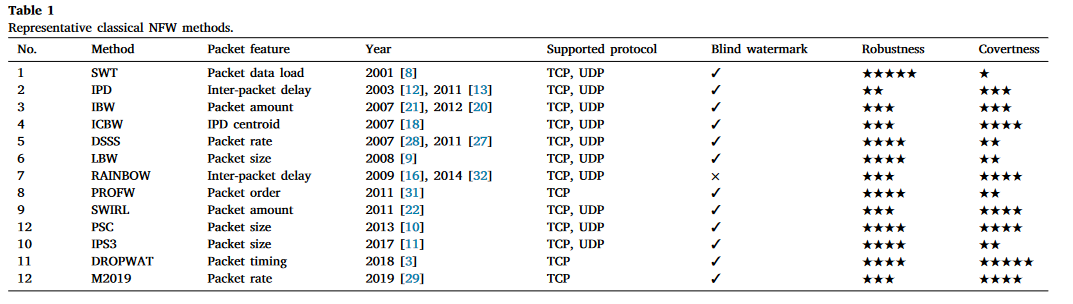
场景
为了对水印交互进行建模,考虑了非合作网络环境。水印嵌入和检测部署在整个会话流的中间节点。如图3所示,S和T是通信对节点,A是水印嵌入节点,B是水印检测节点,M是跳板,W是网络管理员节点。在信息交互时,网络噪声可能通过丢包和时间抖动来干扰水印。W可以从网络防御的角度修改分组特征。在网络流水印中,A和B是抵抗噪声和主动干扰的关键,保证了水印的鲁棒性和隐蔽性。
根据攻击者位置的不同,实现场景可以分为两种:
- S是攻击者:用于识别攻击源和分析攻击行为
- T是攻击者:用于识别被攻击者宝贵数据泄露
本文方案
HeteroTiC采用特征融合来支持更鲁棒的水印。同时,为了适应具有快速检测性能的大规模网络流量检测,设计了多层HeteroTiC。如图4所示,水印方案由三层组成:水印存在性检查(WEC)层、水印识别(WI)层和水印扩展信息(WEI)层。

水印嵌入
水印的嵌入为流IP分组设计了多层结构,将水印分为水印存在性标签和水印识别信息。水印存在性标签不包含用于识别源节点的任何水印比特,但是是从混合网络流中检测快速水印流的关键。对于HeteroTiC,将包顺序、包定时和包大小深度集成为携带水印的核心特征,建立了抗网络噪声的异构时间信道。利用包顺序来标记整个水印和每个水印比特的起始位置,消除了由包丢失和时间抖动引起的水印起始位置偏差。包定时用于基于包间延迟的分布来携带水印识别信息,确保传输期间的定时模式可靠。利用包大小动态地建立包定时与水印识别信息之间的映射关系,避免了水印在隐蔽性上的参数泄漏。
WEC层的嵌入
当网络流到达嵌入节点时,流的前
T
s
T_{s}
Ts长度内将被用于嵌入水印的存在性信息和水印识别信息的起始位置。为了抵抗丢包影响,水印存在性标签将嵌入r个冗余。对于每个冗余,分组被分为具有不同时间窗口的两个部分:
T
o
i
T_{o}^{i}
Toi和
T
a
i
T_{a}^{i}
Tai,最后再附加一个额外的
T
o
i
+
1
T_{o}^{i+1}
Toi+1,如图5所示。
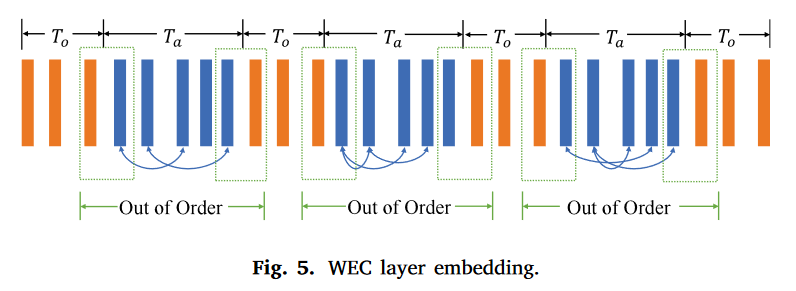
T o i T_{o}^{i} Toi中的数据包用于分离每个 T a i T_{a}^{i} Tai,避免数据包在不同 T a T_{a} Ta的顺序上的混淆。 T a i T_{a}^{i} Tai中的数据包用于携带标签,以确保存在水印。在不同的时间窗口中,为了方便地控制数据包顺序上的逆序数, T a i T_{a}^{i} Tai中包的数量应该相等。 T o i T_{o}^{i} Toi和 T a i T_{a}^{i} Tai中的数据包数量分别配置为定值 C o C_{o} Co和 C a C_{a} Ca,并且为了控制 T o i T_{o}^{i} Toi和 T a i T_{a}^{i} Tai的比率, C o C_{o} Co和 C a C_{a} Ca应满足 C o ≤ 1 γ C a , γ ≥ 2 C_{o}\le \frac{1}{\gamma} C_{a},\gamma \ge 2 Co≤γ1Ca,γ≥2。
对于每个冗余, T o i T_{o}^{i} Toi中的数据包按包顺序保持原始。重新分配 T a i T_{a}^{i} Tai中数据包的顺序,使逆序数 τ i \tau _{i} τi超过预先配置的阈值 δ o \delta _{o} δo,这使得 T a i T_{a}^{i} Tai中的数据包处于混沌状态,以标记水印的存在。每个 T a i T_{a}^{i} Tai中包的顺序随机产生,但要保证具有相同的逆序数,因为逆序数要指明WI层的开始位置,并且逆序数 τ i \tau _{i} τi的大小由 T a i T_{a}^{i} Tai中包的数量控制。逆序数指明WI层开始的位置,指的是WI层和WEC层之间间隔 n k = τ i ˉ n_{k} =\bar{\tau_{i} } nk=τiˉ个数据包。
WI层的嵌入
WI层的嵌入用于处理WEC层后的后续数据包。当进入第二层嵌入时,需要较大的时间窗口 T l T_{l} Tl,这意味着需要更多的数据包来完成水印识别信息的嵌入。
如图6所示,对于WI层的数据包,其被具有固定分组量的特定时间窗口
T
t
T_{t}
Tt分割(t是WI层中时间窗口的索引)。如果水印比特的量为
N
w
N_{w}
Nw,则时间窗口
T
t
T_{t}
Tt的数量也为
N
w
N_{w}
Nw。对于每个
T
t
T_{t}
Tt,数据包被划分为具有数据包数量
n
f
n_{f}
nf和
n
l
n_{l}
nl的两个子窗口。前
n
f
n_{f}
nf个数据包被重新排序以标记每个时间窗口
T
t
T_{t}
Tt的开始。后
n
l
n_{l}
nl个数据包在包定时上调制以携带水印比特信息。通常,在每个
T
t
T_{t}
Tt准确标记起始位置的条件下,让
n
f
n_{f}
nf足够小,以提高分组嵌入效率。因此,应同时满足
n
f
≪
C
a
n_{f}\ll C_{a}
nf≪Ca和
n
f
≪
n
l
n_{f}\ll n_{l}
nf≪nl。

如图6所示,从按照某种算法产生的相同逆序数的顺序序列中随机选择一个顺序序列 ξ \xi ξ,用于改变除最终时间窗口 T N w T_{N_{w}} TNw之外的每个 T t T_{t} Tt的前 n f n_{f} nf个数据包的顺序,即上图中的41532;逆序序列 ξ ′ \xi ' ξ′仅用于协调最终时间窗口 T N w T_{N_{w}} TNw的数据包顺序用于标记水印的结束,即上图中的23514。
对于每个时间窗口
T
t
T_{t}
Tt中的后
n
l
n_{l}
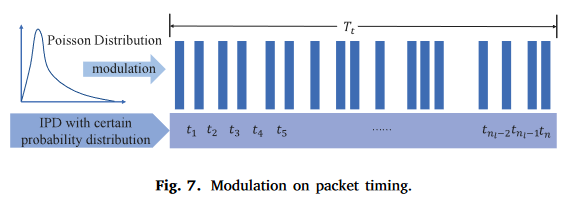
nl个包,采用包间延迟来设计嵌入水印识别信息。如图7所示,对
n
l
n_{l}
nl分组的包间延迟进行调制,以满足参数
λ
t
\lambda_{t}
λt的泊松分布。基于
P
(
λ
t
)
P(\lambda_{t})
P(λt),使用该分布随机生成IPD序列以调制包间延迟。
假设
T
t
T_{t}
Tt中水印比特的二进制值为
w
t
w_{t}
wt,
λ
t
\lambda_{t}
λt根据
w
t
w_{t}
wt配置。当
w
t
w_{t}
wt为1时,
λ
t
=
λ
1
\lambda_{t}=\lambda_{1}
λt=λ1;当
w
t
w_{t}
wt为0时,
λ
t
=
λ
0
\lambda_{t}=\lambda_{0}
λt=λ0,这建立了分组特征和水印比特之间的映射关系。为了防止
λ
t
\lambda_{t}
λt的值从一个偏移到另一个,
λ
1
\lambda_{1}
λ1
和
λ
0
\lambda_{0}
λ0之间的距离应满足
∣
λ
1
−
λ
0
∣
>
1
0
⌊
log
10
λ
0
⌋
\left | \lambda_{1}-\lambda_{0} \right | >10^{\left \lfloor \log_{10}{\lambda_{0}} \right \rfloor }
∣λ1−λ0∣>10⌊log10λ0⌋。
虽然在分组定时和水印比特之间建立直接映射是可行的,但它在面对多流分析时很容易受到攻击,导致隐蔽性降低。在良好通信下分组大小是一个可靠特征,并且对于不同数据流中的分组是不同的。因此,HeteroTiC使用数据包大小通过改变静态映射关系来增强水印的隐蔽性。
如图8所示,每个
T
t
T_{t}
Tt被分为两个子窗口:
T
t
1
T_{t}^{1}
Tt1和
T
t
2
T_{t}^{2}
Tt2,这独立于分组定时上的
n
f
n_{f}
nf和
n
l
n_{l}
nl子窗口。
T
t
1
T_{t}^{1}
Tt1和
T
t
2
T_{t}^{2}
Tt2两个子窗口的长度相等。对于
T
t
1
T_{t}^{1}
Tt1和
T
t
2
T_{t}^{2}
Tt2,平均包大小值分别为
l
ˉ
t
(
1
)
\bar{l}_{t}^{(1)}
lˉt(1)和
l
ˉ
t
(
2
)
\bar{l}_{t}^{(2)}
lˉt(2)。就特定数据流的数据包大小而言,可以按照
v
t
=
⌊
(
1
+
s
i
g
n
(
l
ˉ
t
(
2
)
−
l
ˉ
t
(
1
)
)
)
/
2
⌋
v_{t}=\left \lfloor (1+sign(\bar{l}_{t}^{(2)}-\bar{l}_{t}^{(1)}))/2 \right \rfloor
vt=⌊(1+sign(lˉt(2)−lˉt(1)))/2⌋来获得数据包大小的比特信息,其中sign为符号函数。整个式子的意思就是当
l
ˉ
t
(
2
)
>
l
ˉ
t
(
1
)
\bar{l}_{t}^{(2)}>\bar{l}_{t}^{(1)}
lˉt(2)>lˉt(1)时,
v
t
v_{t}
vt会被设置为1;否则为0。

假设
λ
t
′
\lambda_{t}'
λt′是
T
t
T_{t}
Tt内IPD分布的最终控制参数,则:
λ
t
′
=
{
λ
1
,
t
=
1
λ
w
t
⊕
v
t
−
1
,
t
>
1
\lambda_{t}'=\left\{\begin{matrix} \lambda_{1}&,t=1 \\ \lambda_{w_{t}\oplus v_{t-1}}&,t> 1 \end{matrix}\right.
λt′={λ1λwt⊕vt−1,t=1,t>1
其中
w
t
w_{t}
wt是水印比特,
v
t
−
1
v_{t-1}
vt−1是前一个基于包大小的比特信息。例如上图中对于第一个分组,控制参数应该为
λ
1
\lambda_{1}
λ1;对于第二个分组,水印比特为0,前一个分组的包大小比特信息为0,异或后得到0,所以控制参数应该为
λ
0
\lambda_{0}
λ0。
WEI层的嵌入
在第二层嵌入后,如果通信良好且流足够长,则可以在隐蔽时间信道中传输更多的比特,这可以扩展网络水印的功能,并与隐蔽通信无缝融合。HeteroTiC为足够长的比特嵌入保留了一个接口,该接口仅受网络流的数据包量的限制。嵌入机制类似于WI层嵌入。每个比特嵌入在时间窗口 T t T_{t} Tt内,该时间窗口 T t T_{t} Tt还包括两个部分:
- 用特定的逆序数对前 n f n_{f} nf分组重新排序
- 调制分组定时,以使IPD服从 λ t ′ \lambda_{t}' λt′的泊松分布。
对于第一部分,要调制的顺序序列不同于WI层嵌入的顺序序列,用于避免WEI层和WI层之间的混淆。对于第二部分, λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1的参数可以灵活配置,可以设置不同于WI层的参数,以增强隐蔽性。对于HeteroTiC,WEI层的设计是为了提高其可扩展性,而WEI层不是水印的必要组成部分。
完整嵌入方案
当网络流到达嵌入节点时,利用先验知识选择目标流。先验知识是可以识别已知攻击源的恶意节点或其他威胁的列表。针对选定的网络流量数据,设计了一个具有攻击源识别能力的水印序列。例如,可以对攻击源节点进行编号,并且可以将该编号作为其水印嵌入。或者可以将攻击源节点的IP地址直接嵌入水印。嵌入时,将流分割为不同的时间窗口。如图9所示,时间窗口长度主要由包数量控制。
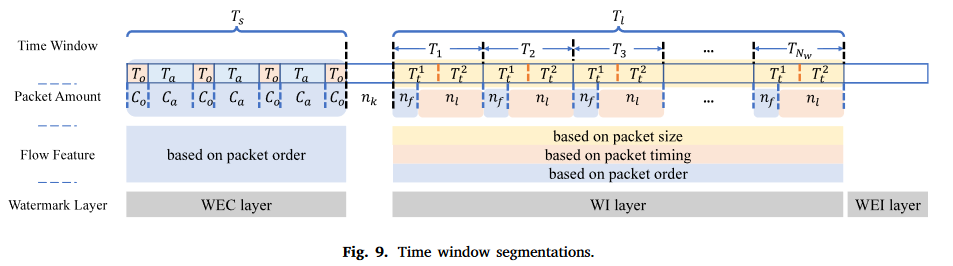
对于不同的层,时间窗口的分割模式是不同的。对于WEC层,利用分组顺序,时间窗口 T a T_{a} Ta是水印存在的主要载体。在WI层,将分组大小、分组时序和分组顺序深度集成,表示水印识别信息。对于时间窗口 T t T_{t} Tt,存在两种分割模式:{ T t 1 T_{t}^{1} Tt1, T t 2 T_{t}^{2} Tt2}和{ n f n_{f} nf, n l n_{l} nl},它们分别用于嵌入分组大小和其他特征。对于WEI层,它在时间窗口分割上与WI层相同。
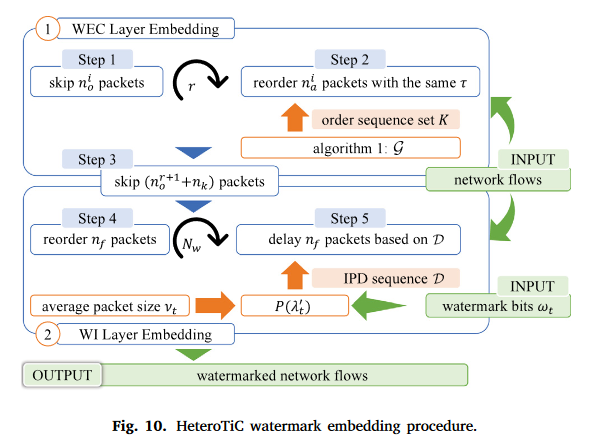
图10示出了HeteroTiC的完整嵌入流程,其中不包括类似于WI层的WEI层嵌入。执行多层嵌入有5个步骤,包顺序和包定时交替调制,使得HeteroTiC不依赖于单个分组特征。当数据包定时或数据包顺序由于噪声或中断而无效时,水印仍然可以工作。
水印检测
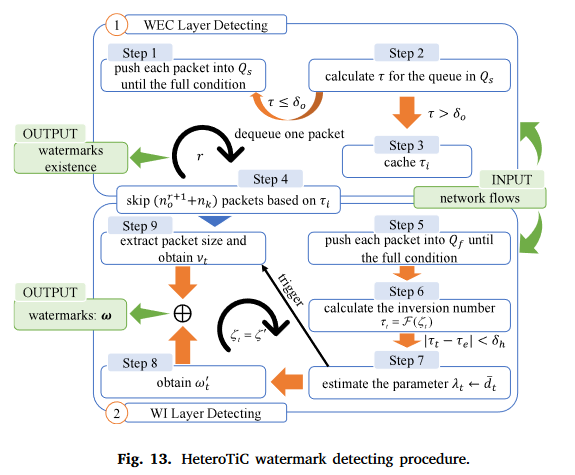
对于会话流,连续监视分组以提取分组顺序特征。当逆序数统计量超过控制阈值 δ o \delta _{o} δo时,验证了水印的存在性。将存在性检查过程设计为在线分析,减少了面对大规模流量数据处理时的耗时。随后,基于WEC层检测的结果确定WI层的起始位置。信息的提取和转换依赖于包顺序、包时序和包大小,这些都是基于特征融合的。包顺序检测是确定水印的每个时间窗口 T t T_{t} Tt的开始和最后比特 w N w w_{N_{w}} wNw,IPD检测是获得嵌入的水印序列,包大小检测是恢复IPD和水印比特之间的映射关系。水印识别信息的提取设计为离线分析,避免了复杂的处理占用更多的时间。如果水印后的数据包仍然是无序的,则验证WEI层的存在性,并根据WI层检测中的处理提取其扩展信息。
WEC层的检测
如图11所示,具有容量
n
a
i
n_{a}^{i}
nai的队列
Q
s
Q_{s}
Qs被用来缓存数据包。

当
Q
s
Q_{s}
Qs满时,计算
Q
s
Q_{s}
Qs中所有数据包的逆序数,并与阈值
δ
o
\delta _{o}
δo进行比较。如果
τ
i
\tau _{i}
τi超过
δ
o
\delta _{o}
δo,则该逆序数被记录下来。否则,
Q
s
Q_{s}
Qs移动一个分组来搜索与阈值
δ
o
\delta _{o}
δo规则匹配的分组序列。当确定
τ
i
\tau _{i}
τi时,
Q
s
Q_{s}
Qs将被清除并填充后续的数据包,以根据嵌入规则进行检查。水印嵌入存在r个冗余,因此需要连续获得所有超过
δ
o
\delta _{o}
δo的r个分组序列。当
δ
o
\delta _{o}
δo以外的
τ
i
\tau _{i}
τi持续r个时间窗口时,验证了水印的存在性。
τ
i
\tau _{i}
τi的统计对于确定水印识别信息的起始位置至关重要。如果发生丢包,
τ
i
\tau _{i}
τi可能在不确定的范围内波动,这会导致嵌入设计的预配置值发生偏差。因此,为了准确性,使用平均值或众数值来估计起始位置:当
众数的个数
≥
⌊
r
2
⌋
众数的个数\ge \left \lfloor \frac{r}{2} \right \rfloor
众数的个数≥⌊2r⌋,
n
k
=
众数
(
也就是
τ
i
中出现最多的那个数
)
n_{k}=众数(也就是\tau_{i}中出现最多的那个数)
nk=众数(也就是τi中出现最多的那个数);否则,
n
k
=
τ
i
的平均数
n_{k}=\tau_{i}的平均数
nk=τi的平均数。
一旦确定
n
k
n_{k}
nk,将跳过
n
k
n_{k}
nk个数据包来定位WI层上的第一个时间窗口。
WI层的检测
当起始位置被准确定位时,提取每个时间窗口 T t T_{t} Tt的头部来分析分组的顺序序列,这是区分当前分组所属时间窗口的边界。队列 Q f Q_{f} Qf用于缓存数据包并计算逆序数。
τ t \tau _{t} τt是嵌入时时间窗口 T t T_{t} Tt的逆序数, τ t ′ \tau _{t}' τt′是检测时时间窗口 T t T_{t} Tt的逆序数, δ h \delta _{h} δh是确定分组是否携带 T t T_{t} Tt的头部标签的控制阈值。在数据包丢失和内部数据包无序的情况下,采用 δ h \delta _{h} δh来克服 τ t \tau _{t} τt上的偏差,以准确标记每个 T t T_{t} Tt的开始位置。 n f n_{f} nf的最大逆序数为 n f ( n f − 1 ) / 2 n_{f}(n_{f}-1)/2 nf(nf−1)/2,最大值的四分之一配置为阈值 δ h = n f ( n f − 1 ) 8 \delta _{h} =\frac{n_{f}(n_{f}-1)}{8} δh=8nf(nf−1),以测量 τ t \tau _{t} τt上的差异。当 ∣ τ t ′ − τ t ∣ < δ h \left | \tau _{t}'-\tau_{t} \right | <\delta_{h} ∣τt′−τt∣<δh时,可以认为时间窗口定位成功。否则, Q f Q_{f} Qf移动一个分组以寻找所需的无序数据包分组序列。
根据嵌入规则的设计,
T
t
T_{t}
Tt中的IPD集合
d
t
j
d_{tj}
dtj应该服从泊松分布
P
(
λ
t
)
P(\lambda_{t})
P(λt),用IPD的均值
d
t
ˉ
\bar{d_{t}}
dtˉ来估计
λ
t
\lambda_{t}
λt。于是可以得到水印比特
w
t
′
=
{
1
,
∣
λ
t
−
λ
1
∣
∈
[
0.8
λ
1
,
1.8
λ
1
]
0
,
∣
λ
t
−
λ
0
∣
∈
[
λ
0
−
0.2
λ
1
,
λ
0
+
0.8
λ
1
]
w_{t}'=\left\{\begin{matrix} 1, &\left | \lambda_{t}-\lambda_{1} \right | \in [0.8\lambda_{1},1.8\lambda_{1}] \\ 0,&\left | \lambda_{t}-\lambda_{0} \right | \in [\lambda_{0}-0.2\lambda_{1},\lambda_{0}+0.8\lambda_{1}] \end{matrix}\right.
wt′={1,0,∣λt−λ1∣∈[0.8λ1,1.8λ1]∣λt−λ0∣∈[λ0−0.2λ1,λ0+0.8λ1]
通常,间隔
[
0.8
λ
1
,
1.8
λ
1
]
[0.8\lambda_{1},1.8\lambda_{1}]
[0.8λ1,1.8λ1]和
[
λ
0
−
0.2
λ
1
,
λ
0
+
0.8
λ
1
]
[\lambda_{0}-0.2\lambda_{1},\lambda_{0}+0.8\lambda_{1}]
[λ0−0.2λ1,λ0+0.8λ1]不会交叉。由于潜在的丢包,范围配置为原始嵌入
λ
1
=
m
i
n
(
λ
0
,
λ
1
)
\lambda_{1}=min(\lambda_{0},\lambda_{1})
λ1=min(λ0,λ1)的
[
0.8
,
1.8
]
[0.8,1.8]
[0.8,1.8]。在大多数情况下,网络中的数据包都会延迟,并且仅在少数情况下提前到达。因此,范围的右边界大于左边界。
然而,
w
t
′
w_{t}'
wt′不是最终的水印比特,还需要根据包大小提取最终的信息。如图12所示,通过分析
T
t
1
T_{t}^{1}
Tt1和
T
t
2
T_{t}^{2}
Tt2的平均包大小,最终水印识别信息可以提取为
w
t
=
{
w
t
′
,
t
=
1
w
t
′
⊕
v
t
−
1
,
t
>
1
w_{t}=\left\{\begin{matrix} w_{t}'&,t=1 \\ w_{t}'\oplus v_{t-1}&,t>1 \end{matrix}\right.
wt={wt′wt′⊕vt−1,t=1,t>1
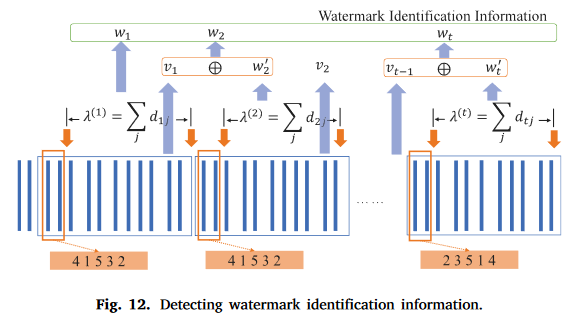
WEI层的检测
如果每个时间窗口 T t T_{t} Tt存在无序的 n f n_{f} nf数据包,则检测过程工作。每个时间窗口 T t T_{t} Tt的水印比特序列的检测机制与WI层的检测近似。
完整检测方案
当网络流到达检测节点时,可以根据会话标签(IP地址、通信端口、协议等)对流进行分类。分组被连续监控。如图13所示,提出了HeteroTiC的完整检测流程,包括WEC层和WI层的检测。WEI层检测机制类似于WI层。水印识别信息的获取分为9个步骤,即依赖队列来提取分组顺序并定位起始位置。水印比特由IPD和包大小确定,这为识别源节点奠定了基础。
实验场景
根据图3中的水印模型,建立如图14所示的实验环境。
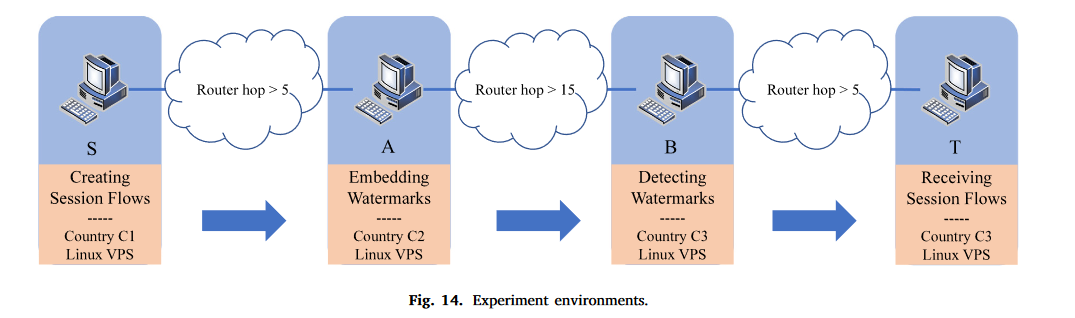
说明:
- S用于为多个会话生成不同的IP流。可以根据实验配置来协调核心数据包特征,例如包大小、包顺序和包间延迟(IPD)。
- A用于拦截来自S的所有网络流,并将流数据重定向到跳板(或直接重定向到b)。在重定向分组之前,应用HeteroTiC来改变包顺序和包间延迟,实现水印嵌入过程。
- B用于截获发送给T的所有网络流,检测带水印的流,并提取水印识别信息。处理过程包括在线分析和离线分析。在线分析用于监测和探测流的头部,以验证水印的存在,这是针对流数据的。离线分析用于离线提取水印识别信息,用于在线分析后缓存的数据包。在线分析速度快、隐蔽性强,能够满足多流量检测的要求。
- T用于接收分组以完成与S的正常通信,而S不需要对分组进行更多的额外操作。
除了这四个角色外,跳板被设计为在A和B之间转发流。在实验中,跳板只改变源和目标的IP地址、通信端口,然后重定向。S、 A和B是关键节点,它们是完成以下实验的最小集。跳板的数量是不受限制的,可以在实验中用于扩展VPS的数量。考虑到部署的需求,为了捕获发送到T的大多数流,B在同一个国家接近T。对于实验,所有节点都在分布在不同国家的虚拟专用服务器上实现。来自节点S的所有网络流在包定时和包大小上随机生成。生成的流具有顺序。为方便起见,采用UDP协议,不配置隧道。
一些参数如表2所示
实验分析
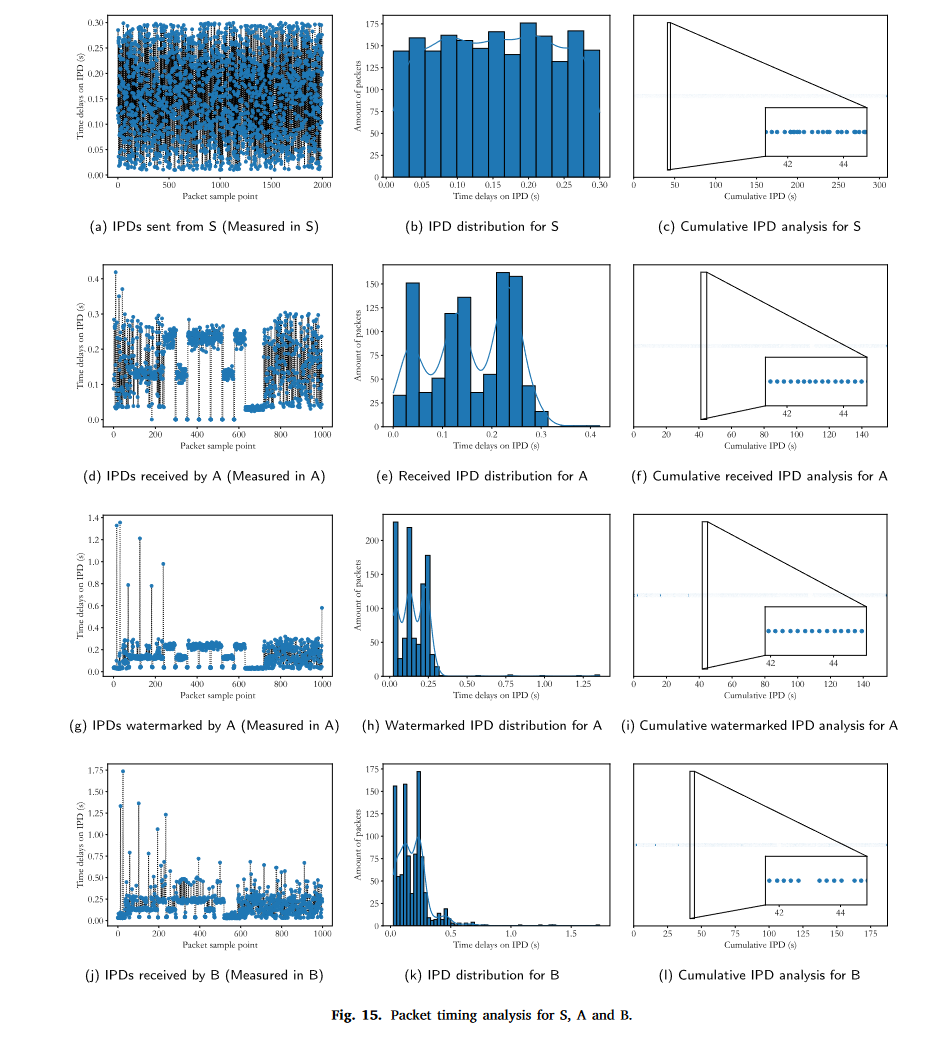
流分析
特征分析
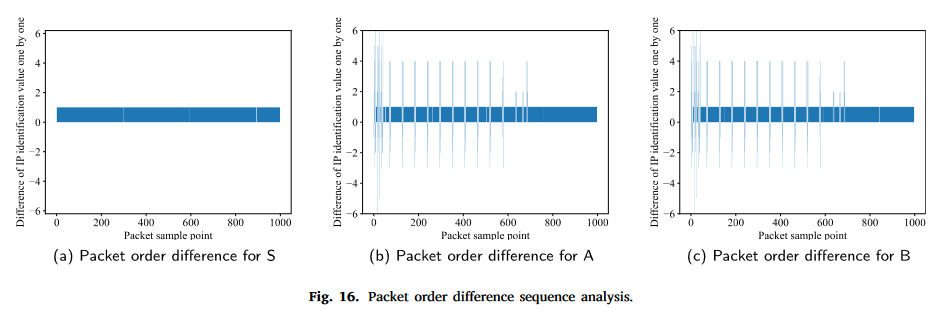
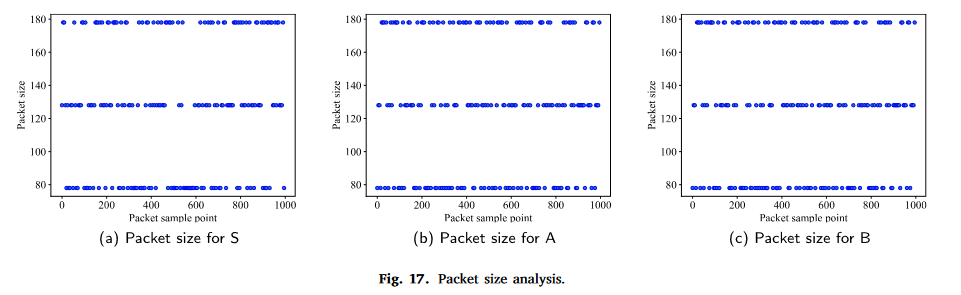
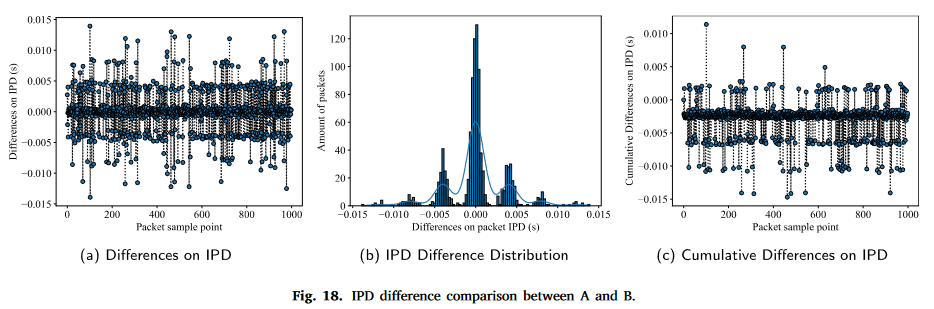
误差分析
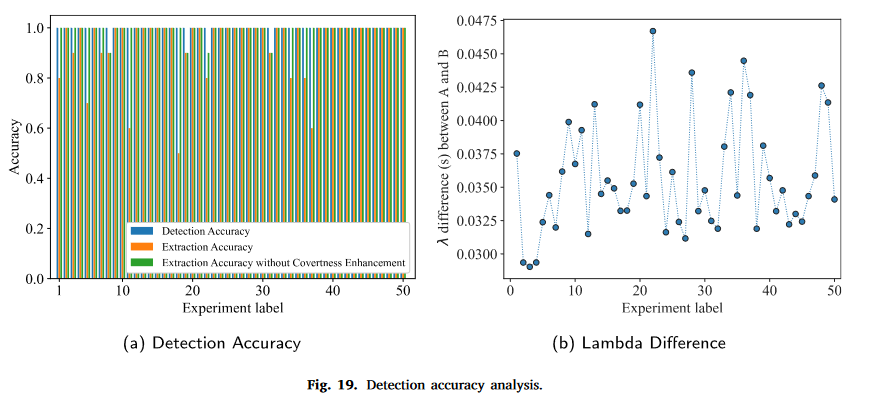
性能分析
三个指标:
- 检测准确度 R d R_{d} Rd:检测到的带水印网络流占所有带水印流的准确率;
- 提取精确度 R e R_{e} Re:正确提取的水印比特数占每个网络流的所有嵌入水印比特的准确率;
- 无遮盖增强的提取精确度 R e c R_{ec} Rec:不考虑基于数据包大小的异或操作,以提高HeteroTiC的隐蔽性。
对局部参数的分析
在实验中,
n
f
n_{f}
nf、
n
l
n_{l}
nl和
δ
h
\delta _{h}
δh由
C
a
C_{a}
Ca和
C
o
C_{o}
Co间接控制。对于实验,上述变量的关系为:
{
C
o
=
C
a
2
n
f
=
C
a
2
n
l
=
10
C
a
δ
h
=
n
f
(
n
f
−
1
)
8
\left\{\begin{matrix} C_{o}=\frac{C_{a}}{2} \\ n_{f}=\frac{C_{a}}{2} \\ n_{l}=10C_{a} \\ \delta _{h}=\frac{n_{f}(n_{f}-1)}{8} \end{matrix}\right.
⎩
⎨
⎧Co=2Canf=2Canl=10Caδh=8nf(nf−1)
因此,关于包数量的所有控制变量都与
C
a
C_{a}
Ca相关,通过33次实验,每3次实验的结果取平均值,得到数据如表3所示

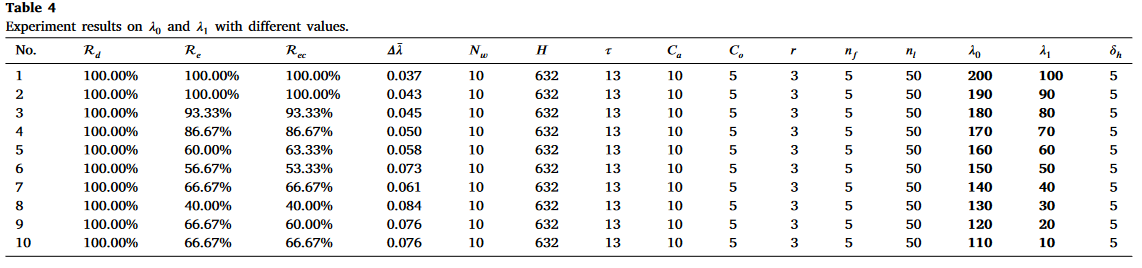
对lambda的分析
对于HeteroTiC,
λ
0
\lambda_{0}
λ0和
λ
1
\lambda_{1}
λ1是控制分组定时嵌入的关键参数。为了分析修改对
λ
0
\lambda_{0}
λ0和
λ
1
\lambda_{1}
λ1值的影响,设计了两组实验:
- λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1之间的距离固定为100。同步降低 λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1来测试HeteroTiC的性能。
- λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1之间的距离逐渐减小。 λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1的值接近默认参数。
两组实验在相同的参数配置下重复执行3次,实验结果是验证HeteroTiC性能的平均值。

讨论
然而,HeteroTiC存在不足,需要改进:
- 对于HeteroTiC,一个水印比特需要至少55个数据包。如果水印识别信息的长度达到32位,则除WEC层外,总数将为1760。在这种情况下,当攻击命令太短时,为了隐蔽性,分组量很难满足。
- λ 0 \lambda_{0} λ0和 λ 1 \lambda_{1} λ1不能配置得太近,这使得调制的包间延迟更大,从而间接降低通信速度。当通信速度足够高时,它对会话流有很大的影响。
- 一旦某些流的包大小保持相等,包大小就不能在没有主动修改的情况下充当相应流的唯一特征。在这种情况下,HeteroTiC不能利用数据包大小来提高隐蔽性。
- 如果用新的分组头替换分组头,则基于分组顺序的同步可能会丢失。因此,HeteroTiC可能会陷入无法按设计工作的状态。为了进一步改进水印技术,在不久的将来还需要采取更多的措施。
(a)删除水印标识信息中的冗余信息。水印的二进制序列中存在连续比特0/1,编码机制仅采用二进制编码。这样的设计带来了大量冗余信息,在嵌入时占了更多的数据包。如果冗余信息可以用压缩码来表示,则可以减少分组的需求。如果时间窗口中的分组可以扩展到3个或更多状态,则水印将获得增强的承载能力。
(b)将信道编码应用于水印的二进制信息序列。信道编码的纠错码可以集成到水印识别信息中。例如最后一个水印位添加奇偶校验码。可以根据场景的需求添加更成熟的编码方法,提高水印的鲁棒性。
(c)利用网络流的上下文信息来估计噪声。由于噪声影响,分组特征可能会被迫偏离嵌入时设计的模式。尽管阈值
δ
h
\delta_{h}
δh用于减少偏差,但就通信质量而言,配置关键参数是非常重要的。当通信质量良好时,可以减少每个时间窗口的分组数,并且
δ
h
\delta_{h}
δh可以更小,以避免高虚警率。
(d)用包顺序主动标记丢包的位置。作为最常见的干扰之一,丢包应该被准确地标记,并且应该根据中断情况使用或不使用相邻包的特征。在检测时,通过分析包顺序的波动,可以主动标记出准确丢包的位置。一旦掌握了丢包的位置,就可以避免将其他分组特征上的坏数据导入到有效的数据集中。
(e)增加分组定时自同步。当分组头被替换并且可靠的分组顺序丢失时,仅依赖于分组顺序的同步不能按设计工作。在复杂网络干扰的情况下,应添加自同步头,并将分组定时作为候选方法。
总结
本文提出了基于异构时间信道的第一种水印方法——HeteroTiC,通过特征融合同时增强了水印的鲁棒性和隐蔽性。多层设计加速了水印存在性的检测。分组定时开始和每个时间窗口的同步克服了嵌入位置的偏差。水印识别信息和分组定时之间的动态映射避免了基于多个流相似性进行参数分析的可能性。综合了数据包的多个特征的优点,使得HeteroTiC能够适应真实网络中各种场景的攻击源跟踪。然而,当数据包头被随机丢弃并被跳板替换时,依赖于包头的IP字段的包顺序可能会失效,这可能会显著降低HeteroTiC的性能。为了进一步提高水印的鲁棒性,需要将破坏包特征的不确定的复杂跳板投入到下一步的研究中。