🎇数组简单题Part

文章目录
- 🎇数组简单题Part
- 🍰1.两数之和
- 👑思路分析
- 1.暴力法
- 2.哈希表法
- 🍰26.删除有序数组中的重复项
- 👑思路分析
- 1.双指针
- 2.利用vector容器特性去重
- 🍰27.移除元素
- 👑思路分析
- 1.双指针
- 2.双指针优化
- 3.利用vector容器特性删除
- 🍰66.加一
- 👑思路分析
- 1.找最长后缀
- 🍰88.合并两个有序数组
- 👑思路分析
- 1.直接覆盖+快速排序
- 2.正向双指针(原地操作)
- 3.正向双指针(辅助数组)
- 4.逆向双指针
- 🍰169.多数元素
- 👑思路分析
- 1.哈希表
- 2.排序
- 3.随机化
- 4.摩尔投票法
🍰1.两数之和
两数之和
👑思路分析
1.暴力法
算法实现:
- 不难想到可以暴力枚举数组内的每一个
x,对于每一个x,只需在数组中找到值为target-x的数即可,由于x之前的数已经枚举过,所以只需枚举x之后的元素即可 - 时间复杂度为: O ( n 2 ) O(n^2) O(n2)
补充知识:
对于vector<int> nums
-
头文件:
#include <vector> -
统计元素个数:
nums.size() -
在数组末尾添加单个元素:
nums.emplace_back(value) -
两种遍历方法:
-
f
o
r
for
for循环:
nums.begin()是起始迭代器的意思,起始迭代器指向容器中的第一个元素
nums.end()是终止迭代器,指向容器中最后一个元素的下一个位置
for (vector<int>::iterator it = nums.begin(); it != nums.end(); it++) cout << *it << endl;
-
f
o
r
_
e
a
c
h
(
a
,
b
,
f
u
n
c
)
for\_each(a,b,func)
for_each(a,b,func)函数:
其本质上就是以for循环
前两个参数分别是起始容器的迭代器的位置,和结束容器,是一个区间 [ a , b ) [a,b) [a,b);
第三个参数是一个函数名称(要在函数的外面对他进行实现)
#include<algorithm> //for_each()需要包含算法头文件 for_each(nums.begin(), nums.end(), [&](int value) {cout << value << " "; }); -
f
o
r
for
for循环:
代码实现:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
vector<int> ans;
for (int i=0;i<nums.size();i++){
for (int j=i+1;j<nums.size();j++){
if (nums[i]+nums[j]==target)
{
ans.emplace_back(i);
ans.emplace_back(j);
return ans;
}
}
}
return ans; //没有结果则返回空数组
}
};
2.哈希表法
算法实现:
- 我们对每一个枚举的
x,查找是否存在元素target-x时,是在x之后的元素中找,时间复杂度高 - 但其实我们也可以"向前找",也就是对枚举过的元素建立一个哈希表,哈希表则是通过
vector<map>实现一对一的键值对存储,这样保证能在 O ( 1 ) O(1) O(1) 的时间内找到target-x - 对于当前枚举的元素
num,判断target-num:-
如果
target-num在哈希表中,也就是存在 k e y = = t a r g e t − n u m key==target-num key==target−num,则匹配成功; -
如果哈希表中不存在
key==target-num,则将当前键值对:{num:数组下标}存入哈希表中,继续下一个元素的枚举
-
补充知识:
对于 unordered_map:
-
头文件:
#include <unordered_map> -
unordered_map内部实现了一个哈希表,也叫散列表,通过把关键码值映射到 H a s h Hash Hash 表中一个位置来访问记录,查找的时间复杂度可达到 O ( 1 ) O(1) O(1),其元素的排列顺序是无序的 -
f i n d ( ) find() find() 查找元素:
如果 k e y key key 在 m a p map map 中, f i n d find find方法会返回 k e y key key 对应的迭代器。如果 k e y key key 不存在, f i n d find find 会返回 e n d end end//查找元素并输出+迭代器的使用 auto iterator = uMap.find(2);//find()返回一个指向2的迭代器 if (iterator != uMap.end()) cout<<"查找成功"<<endl; else cout<<"查找失败"<<endl; -
三种方法解决添加元素:
1.索引添加:
uMap['key']=value2.emplace():
uMap.emplace ("key", value)3.insert():
uMap.insert("其他容器"); // copy insertion uMap.insert(uMap.begin(), uMap.end()); // range inseration uMap.insert({{"sugar",0.8},{"salt",0.1},{"milk",2}}); // initializer list inseration uMap.insert(pair<type 1,type 2>(key,value)); //添加键值对{key:value}
代码实现:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> hash;
for (int i=0;i<nums.size();i++){
//如果key在map中,find方法会返回key对应的迭代器。如果key不存在,find会返回end
auto it=hash.find(target-nums[i]);
if (it!=hash.end())
return {it->second,i};
hash[nums[i]]=i;
}
//失败返回空
return {};
}
};
🍰26.删除有序数组中的重复项
删除有序数组中的重复项
👑思路分析
1.双指针
算法实现:
首先注意数组是有序的,那么重复的元素一定会相邻,要求删除重复元素,实际上就是将不重复的元素移到数组的左侧
- 因此,考虑用双指针
f
a
s
t
fast
fast 和
s
l
o
w
slow
slow:
- 比较
s
l
o
w
slow
slow和
f
a
s
t
fast
fast位置的元素是否相等
如果相等:表示为重复元素, f a s t fast fast 则后移一位;
如果不相等:表示出现了新元素,将 f a s t fast fast 位置的元素复制到 s l o w + 1 slow+1 slow+1 位置上, s l o w slow slow 和 f a s t fast fast 均向后移一位 - 重复上述过程,直到 f a s t fast fast 超出数组范围
- 返回 s l o w + 1 slow+1 slow+1,即为含有不重复元素的数组长度
- 比较
s
l
o
w
slow
slow和
f
a
s
t
fast
fast位置的元素是否相等
图解算法:

代码实现:
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int n=nums.size();
if (n==0) //判空
return 0;
int slow=0;
for(int fast=1;fast<n;fast++)
{
if (nums[fast]!=nums[slow]) //为新元素
nums[++slow]=nums[fast]; //前移
}
return slow+1;
}
};
2.利用vector容器特性去重
算法实现:
对于 vector<int> nums:
sort(begin,end):对数组进行排序,但由于题目所给的数组已经是有序数组,所以省去此操作unique(begin,end):- 头文件:
#include <algorithm> - 作用范围为 [ b e g i n , e n d ) [begin,end) [begin,end),作用是 伪去除 容器中相邻元素的重复元素,因为它会把重复的元素添加到容器的末尾,而返回值是去重后 不重复元素的后一个地址
- 头文件:
nums.erase():删除容器末尾重复的元素
三种删除的方式:- e r a s e ( p o s , n ) erase(pos,n) erase(pos,n):删除从 p o s pos pos开始的 n n n个字符,为 s t r i n g string string特有删除方式,比如 e r a s e ( 0 , 1 ) erase(0,1) erase(0,1)就是删除第一个字符
- e r a s e ( p o s i t i o n ) erase(position) erase(position):删除 p o s i t i o n position position所指位置的元素
- e r a s e ( f i r s t , l a s t ) erase(first,last) erase(first,last):删除 [ f i r s t , e n d ) [first,end) [first,end) 区间内的字符 ( f i r s t (first (first和 l a s t last last都是迭代器 ) ) )
代码实现:
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int sum=0;
vector <int>::iterator it;
it = unique(nums.begin(),nums.end()); //it为指向不重复元素的后一个地址
nums.erase(it,nums.end()); //删除排放在末尾的重复的元素
sum=nums.size();
return sum;
// cout<<sum<<",";
// for(it=nums.begin();it!=nums.end();it++){
// cout<<*it;
}
}
};
🍰27.移除元素
移除元素
👑思路分析
1.双指针
算法实现:
由于题目要求删除数组中等于 v a l val val 的元素,因此输出数组的长度一定 ≤ ≤ ≤ 输入数组的长度,我们可以把输出的数组直接写在输入数组上,则考虑使用双指针:右指针 r i g h t right right 指向 当前将要处理的元素,左指针 l e f t left left 指向 下一个将要赋值的位置
- 初始时,将 l e f t left left 和 r i g h t right right 同时指向首位置
- 对
r
i
g
h
t
right
right 位置的元素进行判断:
- 如果
nums[right]!=val:将 r i g h t right right 对应位置的元素复制到 l e f t left left 位置上,并将 r i g h t right right 和 l e f t left left 同时向右移动一位 - 如果
nums[right]==val: l e f t left left 不动, r i g h t right right 向后移动一位
- 如果
- 重复上述操作,知道 r i g h t right right 超出数组
最终有效数组区间是 [ 0 , l e f t ) [0,left) [0,left),长度即为 l e f t left left
图解算法:

代码实现:
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int n=nums.size();
int left=0;
for (int right=0;right<n;right++)
{
if (nums[right]!=val) //不等于val时
nums[left++]=nums[right]; //复制+移动
}
return left;
}
};
2.双指针优化
算法实现:
如果要移除的元素恰好在数组的开头,例如序列
[
1
,
2
,
3
,
4
,
5
]
[1,2,3,4,5]
[1,2,3,4,5],当 val=1 时,我们需要依次把每一个元素都左移一位,但由于题目中说:「元素的顺序可以改变」,实际上我们可以直接将最后一个元素
5
5
5 移动到序列开头,取代元素
1
1
1,得到序列
[
5
,
2
,
3
,
4
]
[5,2,3,4]
[5,2,3,4] 即可,这个优化在序列中
v
a
l
val
val 元素的数量较少时非常有效
- 初始时,令
left=0,right=n - 对
l
e
f
t
left
left 所指向的元素进行判断:
- 如果
nums[left]==val:将 r i g h t − 1 right-1 right−1 位置上的元素复制到 l e f t left left 位置上,再将 r i g h t right right 向左移动一位 - 如果
nums[left]!=val:则仅让 l e f t left left 向右移动一位
- 如果
- 重复上述操作,直到
right==left说明此时数组中的所有元素都已经被访问过了
最终有效的数组区间为 [ 0 , l e f t ) [0,left) [0,left),长度为 l e f t left left
图解算法:

为什么不令 r i g h t right right 为 n − 1 n-1 n−1 ?
- 是为了确保当 r i g h t = = l e f t right==left right==left 时,数组内的所有元素都已经被访问
否则,若right=n-1,则nums[left]==val时应该令nums[left]=nums[right--],而此时 r i g h t right right指向位置的元素是未被访问过的,如果之后 l e f t left left 移动至 r i g h t right right 位置上,还需再对 n u m s [ l e f t ] nums[left] nums[left] 进行一次判断,这样会导致长度不能直接确定
代码实现:
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int n=nums.size();
int left=0,right=n;
while(right>left) //当right=left时退出
{
if (nums[left]==val)
{
nums[left]=nums[right-1]; //将right位置元素复制给left后,right左移一位
right--;
}
else
left++;
}
return left;
}
};
3.利用vector容器特性删除
算法实现:
- 利用
iterator.erase(pos)对迭代器的指定位置进行删除,需要注意:- 返回值是一个迭代器,指向删除元素的 下一个元素;
- 调用 e r a s e ( ) erase() erase() 函数之后, v e c t o r vector vector 后面的元素会向前移位,形成新的容器,于是被删除的元素对应的迭代器会变成一个野指针
代码实现:
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int res;
int n=nums.size();
for(vector<int>::iterator it=nums.begin();it!=nums.end();){
if (*it==val)
it=nums.erase(it); //此时it指向被删除元素的下一个位置(原来的it变为野指针)
else
it++;
}
return nums.size();
}
};
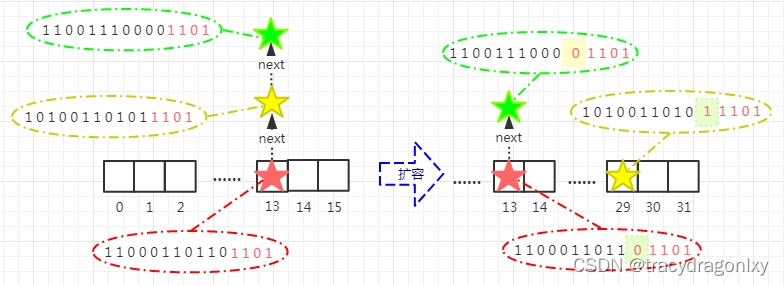
🍰66.加一
加一
👑思路分析
1.找最长后缀
算法实现:
当我们对数组 d i g i t s digits digits 加一时,我们只需要关注 d i g i t s digits digits 的末尾出现了多少个 9 9 9 即可:
-
d i g i t s digits digits 的末尾没有 9 9 9:
例如 [ 1 , 2 , 3 ] [1,2,3] [1,2,3],那么我们直接将末尾的数加一,得到 [ 1 , 2 , 4 ] [1,2,4] [1,2,4] 并直接返回 -
d i g i t s digits digits 的末尾有若干个 9 9 9:
例如 [ 1 , 2 , 3 , 9 , 9 ] [1,2,3,9,9] [1,2,3,9,9],那么我们只需要找出从末尾开始的第一个不为 9 9 9 的元素,即 3 3 3,将该元素加一,得到 [ 1 , 2 , 4 , 9 , 9 ] [1,2,4,9,9] [1,2,4,9,9]。随后将末尾的 9 9 9 全部置零,得到 [ 1 , 2 , 4 , 0 , 0 ] [1,2,4,0,0] [1,2,4,0,0] 并直接返回 -
d i g i t s digits digits 的所有元素都是 9 9 9:
例如 [ 9 , 9 , 9 , 9 , 9 ] [9,9,9,9,9] [9,9,9,9,9],那么答案为 [ 1 , 0 , 0 , 0 , 0 , 0 ] [1,0,0,0,0,0] [1,0,0,0,0,0],我们只需要构造一个长度比 d i g i t s digits digits 多 1 1 1 的新数组,将首元素置为 1 1 1,其余元素置为 0 0 0 即可:vector<int> ans(n+1,0); ans[0]=1;
也可以使用 v e c t o r < i n t > vector<int> vector<int> 中的插入函数
digits.insert(digits.begin(),1)实现头插
代码实现:
class Solution {
public:
vector<int> plusOne(vector<int>& digits) {
int n=digits.size();
for(int i=n-1;i>=0;i--)
{
if(digits[i]+1!=10) //如果不产生进位
{
digits[i]++;
return digits;
}
digits[i]=0; //否则该位置零
}
//能走出循环说明所有位都为0了,需要增长数组,即9999->10000
digits.insert(digits.begin(),1);
return digits;
}
};
🍰88.合并两个有序数组
合并两个有序数组
👑思路分析
1.直接覆盖+快速排序
算法实现:
由于最终结果为 n u m s 1 nums1 nums1,则可以直接将 n u m s 2 nums2 nums2 覆盖到 n u m s 1 nums1 nums1 的尾部,然后对整个数组进行排序,此时时间复杂度为 : O ( ( m + n ) l o g ( m + n ) ) :O((m+n)log(m+n)) :O((m+n)log(m+n)),空间复杂度为 : O ( l o g ( m + n ) ) :O(log(m+n)) :O(log(m+n))
sort(a,b): c + + c++ c++标准库中的排序函数- 头文件:
#include<algorithm> - 时间复杂度: n ∗ l o g 2 ( n ) n*log2(n) n∗log2(n)
- 作用范围: [ a , b ) [a,b) [a,b)
- 头文件:
代码实现:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for (int i = 0; i != n; ++i)
nums1[m + i] = nums2[i]; //覆盖尾部
sort(nums1.begin(), nums1.end());
}
};
2.正向双指针(原地操作)
算法实现:
方法一没有利用数组 n u m s 1 nums1 nums1与 n u m s 2 nums2 nums2 已经被排序的性质,由于此时 n u m s 1 nums1 nums1 和 n u m s 2 nums2 nums2 已经是升序排列了,在前面的元素一定比后面更小,因此我们可以使用双指针,分别指向两个数组,每一次选择一个较小的元素放入 n u m s 1 nums1 nums1 中,此时时间复杂度为: O ( n m ) O(nm) O(nm),空间复杂度为 : O ( 1 ) :O(1) :O(1):
- 开始时, p , q p,q p,q 分别指向 n u m s 1 、 n u m s 2 nums1、nums2 nums1、nums2 的首位置
- 当两个数组内的元素都没有被遍历完时,比较
n
u
m
s
1
[
p
]
nums1[p]
nums1[p] 和
n
u
m
s
2
[
q
]
nums2[q]
nums2[q]:
nums1[p]<nums2[q]:
由于 n u m s 1 nums1 nums1 中存放最终结果,因此,此时不用改变 n u m s 1 [ p ] nums1[p] nums1[p] 位置上的数,并让 p p p 指针向右移一位nums1[p]≤nums2[q]:- 此时,我们应该让 n u m s 2 nums2 nums2 中更小(或相等)的元素放入 n u m s 1 nums1 nums1,因此,我们选择删除 1 1 1 个 n u m s 1 nums1 nums1 数组末尾的 0 0 0,而将 n u m s 2 [ q ] nums2[q] nums2[q] 插入(前插);
- 并将指针
p
,
q
p,q
p,q 都各自向右移一位:
p++是因为此时 p p p 指向的是前插的新元素;q++是为了继续遍历 n u m s 2 nums2 nums2 中的下一个元素 - 此外,我们还需要将
n
u
m
s
1
nums1
nums1 数组的有效长度
m++,因为新增了一个元素
- 当循环结束时,只有两种情况:
q!=n:表示 n u m s 2 nums2 nums2 中还存在比此时 n u m s 1 nums1 nums1 中最大元素更大的元素,于是将 n u m s 2 nums2 nums2 中剩余元素全部加入 n u m s 1 nums1 nums1q==n:表示 n u m s 2 nums2 nums2 中所有元素都加入到了 n u m s 1 nums1 nums1 中,也说明此时 n u m s 1 nums1 nums1 已经完成了排序
解释:
- 该双指针操作的优点是:没有使用辅助数组空间,空间复杂度为 : O ( 1 ) :O(1) :O(1),但是缺点是:使用
nums.insert()进行前插操作时,移动产生的时间复杂度较高,导致总的时间复杂度为 : O ( n m ) :O(nm) :O(nm)- 为什么最后无需在意是否 p = = m ? p==m? p==m? 因为 p = = m p==m p==m 不能说明此时是否已经遍历完 n u m s 2 nums2 nums2 和 n u m s 1 nums1 nums1 中的所有元素
图解算法:

代码实现:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int p=0,q=0; //p指向nums1,q指向nums2
while(p<m && q<n) //当有一个数组被全部访问完时退出
{
if (nums1[p]<nums2[q]) //nums1中元素不变,找下一位置
p++;
else if (nums1[p]>=nums2[q]) //nums1中元素改变
{
nums1.pop_back(); //删除nums1的1个末尾0
nums1.insert(nums1.begin()+p,nums2[q]); //插在nusm1[p]之前
m++; //插入一个新元素,将nums1的有效长度加一
p++;
q++;
}
}
//退出循环后,将剩余元素全部放入nums1数组中
// 1. q!=n 说明nums2中仍有残留元素
if (q!=n)
{
for(;q<n;)
nums1[p++]=nums2[q++];
}
// 2. q==n时说明nums2中元素已经全部插入nums1中
// 此时无需进行任何操作
}
};
3.正向双指针(辅助数组)
算法实现:
思想同上,而此时是将比较得到的较小元素放入辅助数组中,最后遍历完两个数组内全部元素后,再将辅助数组复制到 n u m s 1 nums1 nums1 中,此时时间和空间复杂度均为 : O ( m + n ) :O(m+n) :O(m+n)
图解算法:

代码实现:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int p=0,q=0,i=0;
int res[m+n];
//比较
while(p<m && q<n)
{
if (nums1[p]<nums2[q])
res[i++]=nums1[p++];
else if (nums1[p]>nums2[q])
res[i++]=nums2[q++];
else if (nums1[p]==nums2[q])
{
res[i++]=nums1[p++]; //两个都放
res[i++]=nums2[q++];
}
}
//处理nums2中剩余
if (p==m && q!=n)
{
for(;q<n;)
res[i++]=nums2[q++];
}
//处理nums1中剩余
else if (p!=m && q==n)
{
for(;p<m;)
res[i++]=nums1[p++];
}
//复制结果
for(int j=0;j<m+n;j++)
nums1[j]=res[j];
}
};
4.逆向双指针
算法实现:
由于 n u m s 1 nums1 nums1 的后半部分是空的,可以直接覆盖而不会影响结果,因此可以将双指针设置为从后向前遍历,每次取两者之中的较大者放进 n u m s 1 nums1 nums1 的末尾,此时时间复杂度为 : O ( m + n ) :O(m+n) :O(m+n),空间复杂度为 : O ( 1 ) :O(1) :O(1)
- 指针 i i i 表示下一个要插入 n u m s 1 nums1 nums1 的位置
- 初始时,取
m
m
m 和
n
n
n 分别作为指向
n
u
m
s
1
nums1
nums1 和
n
u
m
s
2
nums2
nums2 的指针,
m&n --使其指向数组的有效末尾 - 当
n>=0时,表示 n u m s 2 nums2 nums2 中仍有元素未插入 n u m s 1 nums1 nums1 中,比较此时的 n u m s 1 [ m ] nums1[m] nums1[m] 和 n u m s 2 [ n ] nums2[n] nums2[n]:nums1[m]>nums2[n]:不断令 n u m s 1 [ i ] = n u m s 1 [ m ] nums1[i]=nums1[m] nums1[i]=nums1[m],并不断左移,直到nums1[m]<nums2[n]nums1[m]<nums2[n]:令 n u m 1 [ i ] = n u m s 2 [ n ] num1[i]=nums2[n] num1[i]=nums2[n]
图解算法:

代码实现:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int i=nums1.size()-1; //指针i指向要插入元素的位置
m--;
n--;
while(n>=0) //存在nums2中的元素未加入到nums1中
{
while(m>=0 && nums1[m]>nums2[n])
nums1[i--]=nums1[m--];
nums1[i--]=nums2[n--];
}
}
};
🍰169.多数元素
多数元素
👑思路分析
1.哈希表
算法实现:
可以循环遍历数组一次,用哈希表对数组元素出现的频次进行统计,时间复杂度和空间复杂度均为 : O ( n ) :O(n) :O(n)
- 其中,统计频次的
unordered_map<type,type> count是一个关联容器,存储键 − - −值对,其中每个键都关联到唯一的值,可以使用 c o u n t [ i ] count[i] count[i] 来查询键 i i i 的值 - 当我们访问一个元素时,要将其哈希表内的值加一,可以通过
++count[i]实现注意:如果 i i i 在
unordered_map中不存在,那么这个操作会添加一个键为 i i i 的新元素到unordered_map中,并令其值为 1 1 1
代码实现:
class Solution {
public:
int majorityElement(vector<int>& nums) {
unordered_map<int,int> hash; //哈希表
int n=nums.size();
for(int i=0;i<n;i++)
{
++hash[nums[i]];
if (hash[nums[i]]>n/2)
return nums[i];
}
return NULL;
}
};
2.排序
算法实现:
如果将数组 n u m s nums nums 中的所有元素按照单调递增或单调递减的顺序排序,那么下标为 ⌊ n 2 ⌋ ⌊\frac{n}{2}⌋ ⌊2n⌋ 的元素(下标从 0 0 0 开始)一定是众数,此时,时间复杂度为 : O ( n l o g n ) :O(nlogn) :O(nlogn),空间复杂度为 : O ( l o g n ) :O(logn) :O(logn)
- 使用
s
t
d
std
std库自带的排序函数:
sort(begin,end,pred)- 升序为:
sort(begin,end,greater<T>())T T T为参数类型 - 降序为:
sort(begin,end,less<T>())
- 升序为:

代码实现:
class Solution {
public:
int majorityElement(vector<int>& nums) {
sort(nums.begin(),nums.end(),greater<int>());
return nums[nums.size()/2];
}
};
3.随机化
算法实现:
因为超过 ⌊ n 2 ⌋ ⌊\frac{n}{2}⌋ ⌊2n⌋ 的数组下标被众数占据了,这样我们随机挑选一个下标,检查它对应的数是否是众数,如果是就返回,否则继续随机挑选,由于一个给定的下标对应的数字很有可能是众数,因此会有很大的概率能找到
- 可以利用
rand() % nums.size()随机生成一个数组下标
时间复杂度:理论上最坏情况下的时间复杂度为 O ( ∞ ) O(∞) O(∞),因为如果我们的运气很差,这个算法会一直找不到众数,随机挑选无穷多次,所以最坏时间复杂度是没有上限的,然而,运行的期望时间是线性的,为了更简单地分析,先说服你自己:由于众数占据 超过 数组一半的位置,期望的随机次数会小于众数占据数组恰好一半的情况,因此,我们可以计算随机的期望次数(假设当前情况为 X X X,众数数量为 n 2 \frac{n}{2} 2n 的情况为 Y Y Y):
计算方法:当众数恰好占据数组的一半时,第一次随机我们有 1 2 \frac{1}{2} 21 的概率找到众数,如果没有找到,则两次随机,我们有 1 4 \frac{1}{4} 41 的概率找到众数,以此类推,可以计算出这个期望值为常数 2 2 2,也就是说,平均两次随机挑选就可以找到众数,所以时间复杂度为 : O ( k ∗ n ) = O ( n ) :O(k*n)=O(n) :O(k∗n)=O(n)
空间复杂度 : O ( 1 ) :O(1) :O(1)
代码实现:
class Solution {
public:
int majorityElement(vector<int>& nums) {
int n=nums.size();
while(true)
{
int num=nums[rand()%n];
int count=0;
for(int i=0;i<n;i++){
if (nums[i]==num)
++count;
}
if (count>n/2)
return num;
}
return -1;
}
};
4.摩尔投票法
算法实现:
摩尔投票法:核心理念就是票数正负相消,通过该方法可以找到 绝对众数 (也就是出现次数超过一半的数),此时,时间复杂度为 : O ( n ) :O(n) :O(n),空间复杂度为 : O ( 1 ) :O(1) :O(1),为此题的最优解:
- 首先,设立一个选举人
candidate,我们令其为数组的首元素,将当前选举人的票数 c o u n t count count 设为 1 1 1 - 遍历数组,如果
nums[i]==candidate,表示有人投了当前选举人一票,count++;如果nums[i]!=candidate,说明有人将票投给了其他人,令count-- - 当某一时刻,当前选举人的票数出现
count==0,我们需要更换一个新的选举人,则令下一个元素为新的选举人:candidate=nums[++i],令其票数为 1 1 1 - 最后,数组内所有元素都遍历完成,此时的 c a n d i d a t e candidate candidate 即为 绝对众数(因为是绝对众数,所以此时 c o u n t ≥ 1 count≥1 count≥1)
图解算法:

代码实现:
class Solution {
public:
int majorityElement(vector<int>& nums) {
int candidate=nums[0]; //设立初始选举人
int count=1;
for (int i=1;i<nums.size();i++)
{
if (nums[i]==candidate){ //与当前选举人相同
count++;
continue;
}
else if (nums[i]!=candidate) //与当前选举人不相同
count--;
if (count==0){ //两两相消为0了
candidate=nums[++i]; //重新设定下一个元素为新的选举人
count=1; //新选举人的票数为1
}
}
return candidate;
}
};