文章目录
- 用户故事
- 数据模型
- 选择数据库
- SQL与NoSQL
- H2、Hibernate和JPA
- Spring Boot Data JPA
- 依赖关系和自动配置
- Spring Data JPA技术栈
- 数据源(自动)配置
- 实体
- 存储库
- 存储User和ChallengeAttempt
- 显示最近的ChallengeAttempt
- 服务层
- 控制器层
- 用户界面
- 小结
文章代码可以从这里下载: 前端+后端示例
前端代码可从这里下载:前端示例
后端代码可从这里下载:后端示例
前面的文章:
1、一个测试驱动的Spring Boot应用程序开发
2、2 使用React构造前端应用
在敏捷开发中,学会纵向划分产品需求,可以在构建软件时节省大量时间。这意味着不需要等待一个完整的层完成后再进行下一层的开发,而是要进行多层开发确保业务功能可正常运行。这种开发方式也有助于构建更好的产品或服务。
通过前面的前后端开发,完成了用户猜数游戏,可以进行试用,那么,就可能得到更进一步的需求:如果能够访问自己的统计数据,以便了解一段时间的表现,系统会更好。这就有了新的用户故事。
用户故事
作为用户,希望能够访问以前的尝试,以便了解自己的心算能力是否随时间的推移而有所提高。
将这个用户故事映射为技术解决方案时,就会发现需要存储这些尝试。这里,就将介绍前面例子中缺少的部分:数据层,这通常意味着需要将数据存储在数据库中,而且,也需要将这些新需求集成到其余各层,主要任务如下:
- 存储用户尝试,能够允许用户进行查询。
- 创建新的REST API接口,获取指定用户的最新尝试。
- 创建新的服务(业务逻辑)来检索这些尝试。
- 用户发送新的尝试后,在Web页面上显示用户所有尝试的历史记录。
数据模型
前面已经创建了Challenge,ChallengeAttempt和User三个领域类。设计时,可以搭配Challenge和ChallengeAttempt之间的联系,为了保持域的简单性,可以将Challenge的两个参数(factorA和factorB)都复制到ChallengeAttempt对象中,这就使对象之间只建立了一种模型关系:ChallengeAttempt属于特定用户。前面就是这么做的。
在模型简化过程中,还可以更进一步,ChallengeAttempt对象中也包括User的数据,这样,唯一需要存储的对象就是ChallengeAttempt。这样,可以在同一张表中使用用户别名来查询数据。这样,随着时间的推移,Users域会不断演化,而且会和其他域进行交互,在数据层产生紧耦合混用不同域并不是一个好方法。
还有一种设计选择。可以将域分成两个部分:Users和Challenges,来映射3个单独的对象,将Challenge和ChallengeAttempt及其关系划分为Challenges域。如图所示:
可以使用与User相同的方式完成设计。这样处理类似于DTO模式。
对于是否将DTO、领域类和数据类完全隔离,存在不同意见。实践应用中,更高的隔离度,可替换数据层的实现,而不必修改服务层的代码,这可能是期望获得的,但是,这可能引入大量重复代码,变得更复杂。
现在,可以将相同的类重用于域和数据表示形式,仍然可以保持域隔离,下面的模型表示了数据库中的对象和关系:
选择数据库
SQL与NoSQL
市场上有很多数据库引擎,选择归结为 SQL 和 NoSQL 数据库。SQL和NoSQL与不同类型的数据库交互。SQL是用于与关系数据库(Relational Databases)交互的方法,而NoSQL是用于与非关系型数据库(Relational Databases)交互的方法。
SQL 数据库一直是一种行之有效的选择。它们由高度结构化的表格组成,由行和列组成,通过共同的属性相互关联。每列都需要为其对应的行设置一个值。键定义了表之间的关系。键是表字段(列),其包含每条记录的唯一值。如果将一个字段定义为表的主键,则该字段可以包含在多个表中,并且可以用于同时访问不同的表。一旦使用主键将其表连接到另一个表,它将在另一个表中被称为外键。
虽然 SQL 数据库的标准化模式使它们变得僵硬且难以修改,但它确实具有一些优势。添加到数据库的所有数据都必须符合众所周知的由行和列组成的链接表模式。有些人可能会发现这种局限性,但当数据一致性、完整性、安全性和合规性非常重要时,它会很有帮助。 SQL 数据库符合ACID特性,即原子性、一致性、隔离性和持久性 。
- 原子性:对数据和事务的所有更改都完全执行并作为单个操作。如果这不可能,则不会执行任何更改,即要么全有要么全无。
- 一致性:数据在事务开始和结束时必须有效且一致。
- 隔离性:事务同时运行,不相互竞争。相反,它们表现得好像是连续发生的。
- 持久性:当一个事务完成时,其关联的数据是永久的,不能更改。
与关系数据库不同,非关系型数据库——NoSQL数据库——并不以表和记录的形式存储数据。NoSQL真正的意义是它打破了关系表的束缚,能够同时存储和访问所有结构化和非结构化数据类型。而且,NoSQL非常灵活且易于开发人员使用和修改。相反,在这些类型的数据库中,针对特定的要求设计和优化数据存储结构。
NoSQL数据库不使用关系数据库所使用的SQL,而是使用对象关系映射(ORM)来促进与其数据的通信,NoSQL非常灵活且易于开发人员使用和修改。
NoSQL数据库的四种流行类型为列存储数据库、文档型数据库、键值数据库和图形数据库。这些类型可以单独使用或组合使用。选择将取决于你的应用和你需要存储的数据类型。
那么,该如何在SQL和NoSQL数据库之间进行选择呢?
关于这个问题,需要考虑四个方面:灵活性、可扩展性、一致性和现有技术。
- 灵活性:有时需要——当数据具有不同的结构和不同的类型时。根据定义,NoSQL数据库提供了更多的自由来设计模式并在同一个数据库中存储不同的数据结构。然而,SQL数据库的结构和模式则比较严格。
- 可扩展性:见过日本停车场电梯吗?它允许车辆彼此叠置停放。现在,有一个问题:在当前的电梯上加层以及建造新的电梯,哪个更有效?SQL数据库是可以垂直扩展的,这意味着可以给它添加级层(增加其负载);而NoSQL数据库是可以水平扩展的,可以通过将工作分给多台服务器来增加其负载。
- 一致性:SQL数据库具有高度一致的设计。然而,基于DBMS,NoSQL数据库可以是一致的,也可以是不一致的。例如,MongoDB是一致的,而Cassandra之类的数据库则不一致。
- 现有技术:可能会考虑的一个方面是数据库技术的当前发展阶段。由于SQL数据库已经存在了很长时间,所以它比NoSQL数据库更发达。因此,对于初学者来说,从SQL开始,然后转向NoSQL可能是最佳选择。
根据经验,如果正在处理RDBMS(关系数据库管理系统),想分析数据的行为或构建自定义的仪表盘,则SQL是更好的选择。此外,SQL通常可以更快地进行数据存储和恢复,并且更好地处理复杂的查询。
另一方面,如果想在RDBMS的标准结构上进行扩展,或者需要创建灵活的模式,那么NoSQL数据库是更好的选择。当要存储和日志记录的数据来自分布式数据源,或者只是需要临时存储的时候,NoSQL数据库也是更好的选择。
SQL数据库比较古老,因此研究较多,固定模式设计和结构也比较成熟。NoSQL数据库由于模式灵活,因此易于扩展、灵活,使用起来也相对简单。
这里的数据模型是关系型的,而且,不打算处理数百万个并发的读写操作,为Web应用程序选择一个SQL数据库,以便从ACID特性中受益。
无论如何,使应用程序(微服务)保持足够小,可以在需要时更改数据库引擎,而不会对整个软件体系结构产生重大影响。
H2、Hibernate和JPA
那么,应该选择哪种数据库呢?MySQL、SQL Server、PostgreSQL、H2、Oracle等。这里选择H2数据库引擎,因为它比较小易于安装,很容易嵌入应用程序中,而且,Spring Boot就集成了H2。
Hibernate是一个开放源代码的对象关系映射(ORM)框架,它对JDBC进行了非常轻量级的对象封装,它将 POJO与数据库表建立映射关系,是一个全自动的 orm 框架,hibernate 可以自动生成 SQL 语句,自动执行,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。
JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。JPA规范本质上就是一种ORM规范,注意不是ORM框架,因为JPA并未提供ORM实现,它只是制订了一些规范,提供了一些编程的API接口,但具体实现则由服务厂商来提供实现。
JPA 和 Hibernate 的关系就像 JDBC 和 JDBC 驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。
规范和实现之间的这种松耦合提供了一个明显的优势:可以无缝更换不同的数据库引擎,因为Spring Boot已经提供了相关配置。
Spring Boot Data JPA
依赖关系和自动配置
Spring有许多模块可处理数据库,属于Spring Data系列:JDBC、Cassandra、Hadoop、Elasticsearch等。其中一个就是Spring Data JPA。
Spring Data JPA是Spring基于Spring Data框架对于JPA规范的一套具体实现方案,使用Spring Data JPA可以极大地简化JPA 的写法,几乎可以在不写具体实现的情况下完成对数据库的操作,并且除了基础的CRUD操作外,Spring Data JPA还提供了诸如分页和排序等常用功能的实现方案。合理的使用Spring Data JPA可以极大的提高我们的日常开发效率和有效的降低项目开发成本。
要使用Spring Data JPA,只需要添加spring-boot-starter-data-jpa依赖即可,它还可以自动配置嵌入式数据库H2。
修改pom.xml文件,添加依赖项spring-boot-starter-data-jpa和H2,其中H2只需要运行时支持即可,代码如下:
<dependencies>
...
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
....
</dependencies>
Hibernate是Spring Data JPA的参考实现,启动程序会将Hibernate依赖引入,还包括核心JPA构件以及父模块Spring Data JPA的依赖项。依赖如图所示:
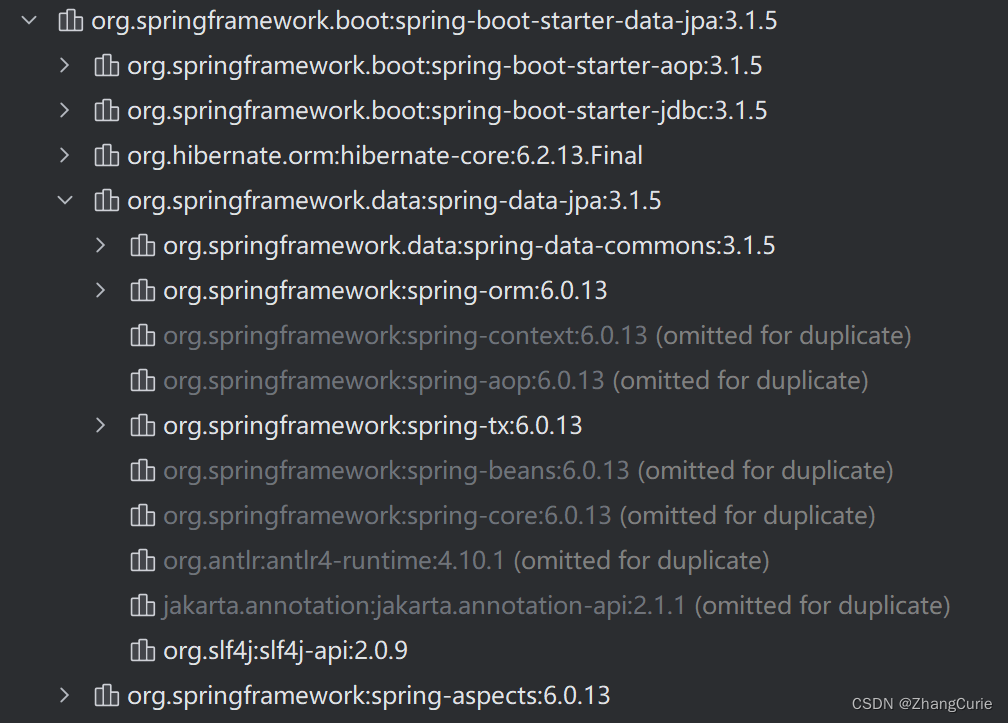
H2可充当嵌入式数据库,不需要自己安装、启动或关闭数据库,Spring Boot应用程序将控制其生命周期。如果想从外部访问数据库,可在application.properties文件中添加如下配置来启用H2数据库控制台:
spring.h2.console.enabled=true
重新启动应用,可以看到控制台日志:
2023-11-24T09:46:37.958+08:00 INFO 44412 --- [ main] c.z.m.MultiplicationApplication : Starting MultiplicationApplication using Java 21 with PID 44412 (Z:\_Learn\multiplication\target\classes started by Juli ZHANG in Z:\_Learn\multiplication)
2023-11-24T09:46:37.961+08:00 INFO 44412 --- [ main] c.z.m.MultiplicationApplication : No active profile set, falling back to 1 default profile: "default"
2023-11-24T09:46:38.375+08:00 INFO 44412 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Bootstrapping Spring Data JPA repositories in DEFAULT mode.
2023-11-24T09:46:38.390+08:00 INFO 44412 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 9 ms. Found 0 JPA repository interfaces.
2023-11-24T09:46:38.729+08:00 INFO 44412 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2023-11-24T09:46:38.735+08:00 INFO 44412 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2023-11-24T09:46:38.735+08:00 INFO 44412 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.15]
2023-11-24T09:46:38.809+08:00 INFO 44412 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2023-11-24T09:46:38.809+08:00 INFO 44412 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 821 ms
2023-11-24T09:46:38.827+08:00 INFO 44412 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
2023-11-24T09:46:38.957+08:00 INFO 44412 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection conn0: url=jdbc:h2:mem:1551ad8d-392a-4d32-8b4c-3038a09c42cc user=SA
2023-11-24T09:46:38.958+08:00 INFO 44412 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
2023-11-24T09:46:38.967+08:00 INFO 44412 --- [ main] o.s.b.a.h2.H2ConsoleAutoConfiguration : H2 console available at '/h2-console'. Database available at 'jdbc:h2:mem:1551ad8d-392a-4d32-8b4c-3038a09c42cc'
2023-11-24T09:46:39.047+08:00 INFO 44412 --- [ main] o.hibernate.jpa.internal.util.LogHelper : HHH000204: Processing PersistenceUnitInfo [name: default]
2023-11-24T09:46:39.080+08:00 INFO 44412 --- [ main] org.hibernate.Version : HHH000412: Hibernate ORM core version 6.2.13.Final
2023-11-24T09:46:39.081+08:00 INFO 44412 --- [ main] org.hibernate.cfg.Environment : HHH000406: Using bytecode reflection optimizer
2023-11-24T09:46:39.260+08:00 INFO 44412 --- [ main] o.s.o.j.p.SpringPersistenceUnitInfo : No LoadTimeWeaver setup: ignoring JPA class transformer
2023-11-24T09:46:39.476+08:00 INFO 44412 --- [ main] o.h.e.t.j.p.i.JtaPlatformInitiator : HHH000489: No JTA platform available (set 'hibernate.transaction.jta.platform' to enable JTA platform integration)
2023-11-24T09:46:39.479+08:00 INFO 44412 --- [ main] j.LocalContainerEntityManagerFactoryBean : Initialized JPA EntityManagerFactory for persistence unit 'default'
2023-11-24T09:46:39.509+08:00 WARN 44412 --- [ main] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
2023-11-24T09:46:39.722+08:00 INFO 44412 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2023-11-24T09:46:39.727+08:00 INFO 44412 --- [ main] c.z.m.MultiplicationApplication : Started MultiplicationApplication in 1.987 seconds (process running for 2.39)
从日志中可以看到,Spring Boot会配置H2数据库,并提供H2控制台访问页面,现在可以在浏览器地址栏中输入:http://localhost:8080/h2-console来查看H2控制台:
在JDBC URL栏输入前面日志中的数据库,单击Connect按钮就可以连接数据库了。如图所示:
Spring Data JPA技术栈
如图所示:
最底层,Java API-Hakari包含了java.sql和javax.sql中一些核心Java API用于处理SQL数据库。这里可以找到DataSource、Connection以及其他用于池化资源的接口,如PooledConnection或ConnectionPoolDataSource,可以找到不同供应商对这些API的多种实现。Spring Boot带有的HiKariCP是DATa Source连接池最流行的一种实现,轻量且性能良好。Hikari 在日语中的含义是光,作者特意用这个含义来表示这块数据库连接池真的速度很快。Hikari 最引以为傲的就是它的性能。
Hibernate使用这些API(以及应用程序中的HikariCP)来连接H2数据库。Hibernate中用于管理数据库的JPA风格是SessionImpl类,包含大量代码来执行语句、执行查询、处理会话的连接等。这个类通过继承来实现JPA接口EntityManager,这是JPA规范的一部分,Hibernate中有其完整实现。
Spring Data JPA在JPA的EntityManager上定义了JpaRepository接口,包含最常用的方法:find、get、delete、update等。SimpleJpaReposity是其默认实现,并使用EntityManager,这意味着不需要使用纯JPA标准或Hibernate,即可使用Spring。
数据源(自动)配置
当使用新的依赖重新执行应用程序时,会发现,并没有配置数据源,却能成功打开H2数据库并连接,这就是自动配置的功能。
通常,可以使用application.properties来配置数据源,这些属性由Spring Boot中的DataSourceProperties类定义,其中包含数据库的URL、用户名和密码等。下面是DataSourceProperties类的关于用户名sa的代码片段:
/**
* Determine the username to use based on this configuration and the environment.
* @return the username to use
* @since 1.4.0
*/
public String determineUsername() {
if (StringUtils.hasText(this.username)) {
return this.username;
}
if (EmbeddedDatabaseConnection.isEmbedded(determineDriverClassName(), determineUrl())) {
return "sa";
}
return null;
}
Spring Boot开发者知道这些惯例,进行了预设,因此数据库开箱即用。这里使用的H2是内存中的数据库,关闭应用程序时,所有测试数据都会丢失。当然,也可以通过设置,DB_CLOSE_ON_EXIT=FALSE禁用自动关闭,让Spring Boot决定何时关闭数据库。
通常情况下,需要开发者配置数据库,例如:
# 访问H2数据库的web控制台
spring.h2.console.enabled=true
# 使用指定文件作为数据源
spring.datasource.url=jdbc:h2:file:~/multiplication;DB_CLOSE_ON_EXIT=FALSE
# 在创建或修改实体时创建和更新数据库表
spring.jpa.hibernate.ddl-auto=update
# 在控制台日志中显示数据库操作的SQL语句
spring.jpa.show-sql=true
实体
从数据角度看,JPA将实体称为Java对象,根据前面的分析,将存储User和ChallengeAttempt,就必须将它们定义为实体。
下面为User类添加一些注解,代码如下:
package cn.zhangjuli.multiplication.user;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.Id;
import lombok.*;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
// 将该类标记为要映射到数据库的对象,如果希望使用不同的名称,可以在注解中嵌入值。
// 可以使用JPA的@Transient注解来排除字段。
@Entity
// 聚合了equals方法、hashCode方法、toString、getter和setter,非常适合实体类。
@Data
@AllArgsConstructor
// JPA和Hibernate要求实体具有默认的空构造方法。
@NoArgsConstructor
// 数据库中可能存在user,这里改变一下表名,防止出现标识符错误。
@Table(name = "s_user")
public class User {
// 唯一标识
@Id
// 为一个实体生成一个唯一标识的主键(JPA要求每一个实体Entity,必须有且只有一个主键),
// @GeneratedValue提供了主键的生成策略。
@GeneratedValue
private Long id;
private String alias;
public User(final String userAlias) {
this(null, userAlias);
}
}
对于ChallengeAttempt类,修改如下:
package cn.zhangjuli.multiplication.challenge;
import cn.zhangjuli.multiplication.user.User;
import jakarta.persistence.*;
import lombok.*;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
// 将该类标记为要映射到数据库的对象,如果希望使用不同的名称,可以在注解中嵌入值。
// 可以使用JPA的@Transient注解来排除字段。
@Entity
// 聚合了equals方法、hashCode方法、toString、getter和setter,非常适合实体类。
@Data
@AllArgsConstructor
// JPA和Hibernate要求实体具有默认的空构造方法。
@NoArgsConstructor
public class ChallengeAttempt {
// 唯一标识
@Id
// 为一个实体生成一个唯一标识的主键(JPA要求每一个实体Entity,必须有且只有一个主键),
// @GeneratedValue提供了主键的生成策略。
@GeneratedValue
private Long id;
// 多对一关系。FetchType告诉Hibernate何时为嵌入的User字段收集存储在不同表中的值。
// 如果为EAGER,User数据会在收集ChallengeAttempt数据时一起收集。
// 如果为LAZY,只有当ChallengeAttempt访问这个字段时,才会执行检索这个字段的查询。
// 这里在收集ChallengeAttempt时,不需要用户的数据。
@ManyToOne(fetch = FetchType.LAZY)
// 用1个列来连接2个表。这会转换为CHALLENGE_ATTEMPT表的新列USER_ID,对应USER表的id。
@JoinColumn(name = "USER_ID")
private User user;
private int factorA;
private int factorB;
private int resultAttempt;
private boolean correct;
}
使用惰性关联,可以避免触发对无关数据的额外查询。
将领域类重用为实体应该注意:
JPA和Hibernate需要在类中添加setter和一个空的构造方法。这很不方便,会妨碍创建遵循“不变性”等良好实践的类。或者说,领域类被数据需求破坏了。
当构建小型应用程序且知道这些原因时,问题不大,只需要避免在代码中使用setter或空构造方法即可。但对于大型团队合作或项目,这就是一个问题了。这种情况下,可以考虑拆分域和实体类。这会带来一些代码重复,但可以实施良好实践。
存储库
遵循领域启动设计,使用存储库来连接数据库,JPA存储库和Spring Data JPA包含了相应的功能。
Spring的SimpleJpaRepository类使用JPA的EntityManager来管理数据库对象,而且还增加了一些特性,如分页和排序等,比普通JPA接口更方便。
下面就来实现ChallengeAttemptRepository接口,代码如下:
package cn.zhangjuli.multiplication.challenge;
import org.springframework.data.repository.CrudRepository;
import java.util.List;
/**
* 继承了Spring Data Common中的CrudRepository接口,CrudRepository定义了创建、读取、更新和删除对象的基本方法。
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
public interface ChallengeAttemptRepository extends CrudRepository<ChallengeAttempt, Long> {
/**
* 根据用来别名查找top10,根据id逆序排列
* @param userAlias 用户别名
* @return the last 10 attempts for a given user, identified by their alias.
*/
List<ChallengeAttempt> findTop10ByUserAliasOrderByIdDesc(String userAlias);
}
ChallengeAttemptRepository 接口继承了Spring Data Common中的CrudRepository接口,CrudRepository定义了创建、读取、更新和删除对象的基本方法。Spring Data JPA中的SimpleJpaRepository类也实现了此接口。除了CrudRepository,还有其他两种选择:
- 如果选择扩展普通的Repository接口,就没有CRUD功能。但是,如果不想使用默认方法,而是想微调CrudRepository中公开的方法时,可以用它来注解。
- 如果还需要分页和排序,可扩展PagingAndSortingRepository,这能提供更好的块处理或分页查询。
Spring Data中,可以通过在方法名称中使用命名约定来创建定义查询的方法,Spring Data会处理接口中定义的方法,检索其中没有明确定义查询且符合命名约定的方法来创建查询方法,然后,解析方法名称,将其分解为块,并构建一个与该定义相对应的JPA查询。
有时想执行一些查询方法无法实现的查询,就需要自定义查询了,可使用Java持久性查询语言(JPQL)来编写查询,如下所示:
/**
* 根据用来别名查找后几个ChallengeAttempt,根据id逆序排列
* @param userAlias 用户别名
* @return the last attempts for a given user, identified by their alias.
*/
@Query("SELECT a FROM ChallengeAttempt a WHERE a.user.alias = ?1 ORDER BY a.id DESC")
List<ChallengeAttempt> lastAttempts(String userAlias);
这很像标准的SQL,区别如下:
- 没有用表名,而是使用类名。
- 关联字段没有使用列,而是使用对象字段,使用点遍历对象结构(a.user.alias)。
- 可使用参数占位符,如例子中的?1来引用第一个(也是唯一一个)传递的参数。
下面来实现User存储库,即UserRepository接口,如下所示:
package cn.zhangjuli.multiplication.user;
import org.springframework.data.repository.CrudRepository;
import java.util.Optional;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
public interface UserRepository extends CrudRepository<User, Long> {
Optional<User> findByAlias(final String alias);
}
如果存在匹配项,findByAlias将返回一个封装在Optional中的User,如果没有,则返回一个空的Optional对象。
这两个存储库已经包含了管理数据库实体所需的一切,不需要实现这些接口,甚至不需要添加@Repository注解。Spring通过Data模块,将找到所有扩展了基本接口的接口,注入所需的Bean。
存储User和ChallengeAttempt
完成数据层后,就可以在服务层使用这些存储库了。
首先,用新的预期逻辑扩展测试用例:
- 无论ChallengeAttempt是否正确,都会存储。
- 如果是给定用户的第一个ChallengeAttempt,有别名(Alias)标识,应该创建该用户,如果别名存在,则ChallengeAttempt应该关联到已经存在的用户。
这样,需要对ChallengeServiceTest进行更新,
package cn.zhangjuli.multiplication.challenge;
import cn.zhangjuli.multiplication.user.UserRepository;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import static org.assertj.core.api.BDDAssertions.then;
import static org.mockito.BDDMockito.given;
import static org.mockito.AdditionalAnswers.returnsFirstArg;
import static org.mockito.ArgumentMatchers.any;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@ExtendWith(MockitoExtension.class)
public class ChallengeServiceTest {
private ChallengeService challengeService;
// 使用Mockito进行模拟
@Mock
private UserRepository userRepository;
@Mock
private ChallengeAttemptRepository challengeAttemptRepository;
@BeforeEach
public void setUp() {
challengeService = new ChallengeServiceImpl(
userRepository,
challengeAttemptRepository
);
given(challengeAttemptRepository.save(any()))
.will(returnsFirstArg());
}
//...
}
下面代码进行正确尝试的测试:
@Test
public void checkCorrectAttemptTest() {
// given
// 这里希望save方法什么都不做,只返回第一个(也是唯一一个)传递的参数,这样不必调用真实的存储库即可测试该层。
given(attemptRepository.save(any()))
.will(returnsFirstArg());
ChallengeAttemptDTO attemptDTO = new ChallengeAttemptDTO(50, 60, "john_doe", 3000);
// when
ChallengeAttempt resultAttempt = challengeService.verifyAttempt(attemptDTO);
// then
then(resultAttempt.isCorrect()).isTrue();
verify(userRepository).save(new User("john_doe"));
verify(attemptRepository).save(resultAttempt);
}
这里,添加了一个新用例,用来验证来自同一用户的更多ChallengeAttempt并不会创建新的用户实体,而是重用现有实体。代码如下:
@Test
public void checkExistingUserTest() {
// given
given(attemptRepository.save(any()))
.will(returnsFirstArg());
User existingUser = new User(1L, "john_doe");
given(userRepository.findByAlias("john_doe"))
.willReturn(Optional.of(existingUser));
ChallengeAttemptDTO attemptDTO = new ChallengeAttemptDTO(50, 60, "john_doe", 5000);
// when
ChallengeAttempt resultAttempt = challengeService.verifyAttempt(attemptDTO);
// then
then(resultAttempt.isCorrect()).isFalse();
then(resultAttempt.getUser()).isEqualTo(existingUser);
verify(userRepository, never()).save(any());
verify(attemptRepository).save(resultAttempt);
}
现在,无法编译该测试类,ChallengeService中需要提供两个repository,修改ChallengeServiceImpl类,代码如下:
package cn.zhangjuli.multiplication.challenge;
import cn.zhangjuli.multiplication.user.User;
import cn.zhangjuli.multiplication.user.UserRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Service
@RequiredArgsConstructor
@Slf4j
public class ChallengeServiceImpl implements ChallengeService {
private final UserRepository userRepository;
private final ChallengeAttemptRepository attemptRepository;
@Override
public ChallengeAttempt verifyAttempt(ChallengeAttemptDTO attemptDTO) {
// Check if the attempt is correct
boolean isCorrect =
attemptDTO.getGuess() == attemptDTO.getFactorA() * attemptDTO.getFactorB();
// 检查alias用户是否存在,不存在就创建
User user = userRepository.findByAlias(attemptDTO.getUserAlias())
.orElseGet(() -> {
log.info("Creating new user with alias {}", attemptDTO.getUserAlias());
return userRepository.save(
new User(attemptDTO.getUserAlias())
);
});
// Builds the domain object. Null id for now.
ChallengeAttempt checkedAttempt = new ChallengeAttempt(null,
user,
attemptDTO.getFactorA(),
attemptDTO.getFactorB(),
attemptDTO.getGuess(),
isCorrect);
// Stores the attempt
return attemptRepository.save(checkedAttempt);
}
}
现在,测试就可以通过了。
repository测试
没有为应用程序的数据层创建测试,因为,这没有多大意义,这里并没有编写任何实现。
显示最近的ChallengeAttempt
已经修改了ChallengeServiceImpl的服务逻辑来存储User和ChallengeAttempt,还缺少一些功能:获取最近的ChallengeAttempt并显示在页面上。
服务层可以简单地使用存储库中的查询方法,在控制器层,创建一个新的REST API以通过别名来获取ChallengeAttempt。
服务层
在ChallengeService接口中添加getStatisticsForUser方法,代码如下:
package cn.zhangjuli.multiplication.challenge;
import java.util.List;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
public interface ChallengeService {
/**
* verifies if an attempt coming from the presentation layer is correct or not.
*
* @param resultAttempt a DTO(Data Transfer Object) object
* @return the resulting ChallengeAttempt object
*/
ChallengeAttempt verifyAttempt(ChallengeAttemptDTO resultAttempt);
/**
* Gets the statistics for a given user.
*
* @param userAlias the user's alias
* @return a list of the last 10 {@link ChallengeAttempt}
* objects created by the user.
*/
List<ChallengeAttempt> getStatisticsForUser(final String userAlias);
}
在ChallengeServiceTest中,编写测试代码:
@Test
public void retrieveStatisticsTest() {
// given
User user = new User("john_doe");
ChallengeAttempt attempt1 = new ChallengeAttempt(1L, user, 50, 60, 3010, false);
ChallengeAttempt attempt2 = new ChallengeAttempt(2L, user, 50, 60, 3051, false);
List<ChallengeAttempt> lastAttempts = List.of(attempt1, attempt2);
given(attemptRepository.findTop10ByUserAliasOrderByIdDesc("john_doe"))
.willReturn(lastAttempts);
// when
List<ChallengeAttempt> latestAttemptsResult = challengeService.getStatisticsForUser("john_doe");
// then
then(latestAttemptsResult).isEqualTo(lastAttempts);
}
实现这个方法很简单,ChallengeServiceImpl中调用repository即可:
package cn.zhangjuli.multiplication.challenge;
import cn.zhangjuli.multiplication.user.User;
import cn.zhangjuli.multiplication.user.UserRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Service
@RequiredArgsConstructor
@Slf4j
public class ChallengeServiceImpl implements ChallengeService {
// ...
@Override
public List<ChallengeAttempt> getStatisticsForUser(final String userAlias) {
return attemptRepository.findTop10ByUserAliasOrderByIdDesc(userAlias);
}
}
运行测试,可以通过。
控制器层
现在,需要从控制器层连接服务层。这需要通过用户别名(alias)来查询ChallengeAttempt,要使用查询参数alias,实现很简单,调用ChallengeService的方法即可,代码如下:
package cn.zhangjuli.multiplication.challenge;
import jakarta.validation.Valid;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/attempts")
public class ChallengeAttemptController {
private final ChallengeService challengeService;
@PostMapping
ResponseEntity<ChallengeAttempt> postResult(@RequestBody @Valid ChallengeAttemptDTO challengeAttemptDTO) {
return ResponseEntity.ok(challengeService.verifyAttempt(challengeAttemptDTO));
}
@GetMapping
ResponseEntity<List<ChallengeAttempt>> getStatistics(@RequestParam String alias) {
return ResponseEntity.ok(challengeService.getStatisticsForUser(alias));
}
}
类似前面的测试,可以编写测试用例,代码如下:
@Test
public void getUserStatistics() throws Exception {
// given
User user = new User("john_doe");
ChallengeAttempt attempt1 = new ChallengeAttempt(1L, user, 50, 70, 3500, true);
ChallengeAttempt attempt2 = new ChallengeAttempt(2L, user, 20, 10, 210, false);
List<ChallengeAttempt> recentAttempts = List.of(attempt1, attempt2);
given(challengeService.getStatisticsForUser("john_doe"))
.willReturn(recentAttempts);
// when
MockHttpServletResponse response = mockMvc.perform(
get("/attempts").param("alias", "john_doe")
).andReturn().getResponse();
// then
then(response.getStatus()).isEqualTo(HttpStatus.OK.value());
then(response.getContentAsString()).isEqualTo(
jsonResultAttemptList.write(
recentAttempts
).getJson()
);
}
重新启动应用程序,输入如下命令:
> http POST :8080/attempts factorA=50 factorB=60 userAlias=noise guess=5302
HTTP/1.1 200
Connection: keep-alive
Content-Type: application/json
Date: Fri, 24 Nov 2023 09:43:48 GMT
Keep-Alive: timeout=60
Transfer-Encoding: chunked
Vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
{
"correct": false,
"factorA": 50,
"factorB": 60,
"id": 1,
"resultAttempt": 5302,
"user": {
"alias": "noise",
"id": 1
}
}
> http :8080/attempts?alias=noise
HTTP/1.1 500
Connection: close
Content-Type: application/json
Date: Fri, 24 Nov 2023 09:49:58 GMT
Transfer-Encoding: chunked
Vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
{
"error": "Internal Server Error",
"path": "/attempts",
"status": 500,
"timestamp": "2023-11-24T09:49:58.447+00:00"
}
可以看到REST API接口的响应,查询数据库也可以发现已经存储了执行的结果。但是,执行查询时会产生一个服务器错误。在后端日志中可以找到对应的异常。这是ByteBuddyInterceptor造成的,主要是将User配置为LAZY了,如果是EAGER,就不会发生这样的错误,这不是要的解决方案。
要继续使用LAZY模式,第一种方法是自定义JSON序列化,使其能处理Hibernate对象。这需要在pom.xml中添加jackson-datatype-hibernate依赖:
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-hibernate5</artifactId>
</dependency>
<!-- -->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>persistence-api</artifactId>
<version>1.0.2</version>
</dependency>
接着,需要为Jackson的新Hibernate模块创建一个Bean,Spring Boot的Jackson2ObjectMapperBuilder会通过自动配置来使用它,下面是配置代码:
package cn.zhangjuli.multiplication.configuration;
import com.fasterxml.jackson.databind.Module;
import com.fasterxml.jackson.datatype.hibernate5.Hibernate5Module;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Configuration
public class JsonConfiguration {
@Bean
public Module hibernateModule() {
return new Hibernate5Module();
}
}
现在,启动应用程序并验证,可以成功检索ChallengeAttempt,如下所示:
> http ":8080/attempts?alias=noise"
HTTP/1.1 200
Connection: keep-alive
Content-Type: application/json
Date: Sat, 25 Nov 2023 01:04:17 GMT
Keep-Alive: timeout=60
Transfer-Encoding: chunked
Vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
[
{
"correct": false,
"factorA": 50,
"factorB": 60,
"id": 1,
"resultAttempt": 5302,
"user": null
}
]
另一种替代方法是,在application.properties中添加Jackson序列化特性,也可以解决该问题。重新运行应用程序,可得到如下结果
spring.jackson.serialization.fail_on_empty_beans=false
> http GET :8080/attempts?alias=noise
HTTP/1.1 200
Connection: keep-alive
Content-Type: application/json
Date: Fri, 24 Nov 2023 09:56:29 GMT
Keep-Alive: timeout=60
Transfer-Encoding: chunked
Vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
[
{
"correct": false,
"factorA": 50,
"factorB": 60,
"id": 1,
"resultAttempt": 5302,
"user": {
"alias": "noise",
"id": 1
}
}
]
这里出现了非预期的输出,从控制台日志可以发现,序列器获取了用户数据,并触发了Hibernate的额外查询来获取数据,这样LAZY参数就失效了。日志如下:
Hibernate: select c1_0.id,c1_0.correct,c1_0.factora,c1_0.factorb,c1_0.result_attempt,c1_0.user_id from challenge_attempt c1_0 left join s_user u1_0 on u1_0.id=c1_0.user_id where u1_0.alias=? order by c1_0.id desc fetch first ? rows only
Hibernate: select u1_0.id,u1_0.alias from s_user u1_0 where u1_0.id=?
因此,采用第一种方式,使用JSON序列化来处理延迟获取。
Spring Boot背后存在许多隐藏行为,在没有真正理解其含义的情况下,应该避免寻求快速的解决方案。
用户界面
最后,需要将新功能集成到React前端以显示最近的ChallengeAttempt。
现在,在基本界面上添加一个列表,用于显示用户最近的几个ChallengeAttempt。
首先,直接呈现ChallengeComponent:
import React from "react";
import './App.css';
import ChallengeComponent from './components/ChallengeComponent';
function App() {
return (
<ChallengeComponent/>
);
}
export default App;
删除原有的样式,自己定义样式,index.css样式如下:
body {
font-family: 'Segoe UI', Roboto, Arial, sans-serif;
}
App.css修改如下:
.display-column {
display: flex;
flex-direction: column;
align-items: center;
}
.challenge {
font-size: 4em;
}
th {
padding-right: 0.5em;
border-bottom: solid 1px;
}
定义了基本显示,需要在ApiClient.js中检索ChallengeAttempt,代码如下:
class ApiClient {
static SERVER_URL = 'http://localhost:8080';
static GET_CHALLENGE = '/challenges/random';
static POST_RESULT = '/attempts';
static GET_ATTEMPTS_BY_ALIAS = '/attempts?alias=';
static challenge(): Promise<Response> {
return fetch(ApiClient.SERVER_URL + ApiClient.GET_CHALLENGE);
}
static sendGuess(user: string,
a: number,
b: number,
guess: number): Promise<Response> {
return fetch(ApiClient.SERVER_URL + ApiClient.POST_RESULT, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
userAlias: user,
factorA: a,
factorB: b,
guess: guess
})
});
}
static getAttempts(userAlias: string): Promise<Response> {
return fetch(ApiClient.SERVER_URL + ApiClient.GET_ATTEMPTS_BY_ALIAS + userAlias);
}
}
export default ApiClient;
下面,创建一个新的ReactComponent来显示ChallengeAttempt列表,该组件不需要状态,这里通过父组件进行最后的ChallengeAttempt。
import * as React from "react";
class LastAttemptsComponent extends React.Component {
render() {
return (
<table>
<thead>
<tr>
<th>Challenge</th>
<th>Your Guess</th>
<th>Correct</th>
</tr>
</thead>
<tbody>
{this.props.lastAttempts.map(a =>
<tr key={a.id} style={{color: a.correct ? 'green' : 'red'}}>
<td>{a.factorA} x {a.factorB}</td>
<td>{a.resultAttempt}</td>
<td>{a.correct ? "Correct" : ("Incorrect (" + a.factorA * a.factorB + ")")}</td>
</tr>
)}
</tbody>
</table>
)
}
}
export default LastAttemptsComponent;
在渲染React组件时,使用map可以轻松地遍历数组。数组的每个元素都应该使用一个key属性来帮助框架识别不断变化的元素。
同时,还需要对ChallengeComponent类进行修改:
import ApiClient from "../services/ApiClient";
import * as React from "react";
import LastAttemptsComponent from "./LastAttemptsComponent";
// 类从React.Component继承,这就是React创建组件的方式。
// 唯一要实现的方法是render(),该方法必须返回DOM元素才能在浏览器中显示。
class ChallengeComponent extends React.Component {
// 构造函数,初始化属性及组件的state(如果需要的话),
// 这里创建一个state来保持检索到的挑战,以及用户为解决尝试而输入的数据。
constructor(props) {
super(props);
this.state = {
a: '',
b: '',
user: '',
message: '',
guess: '',
lastAttempts: []
};
// 两个绑定方法。如果想要在事件处理程序中使用,这是必要的,需要实现这些方法来处理用户输入的数据。
this.handleSubmitResult = this.handleSubmitResult.bind(this);
this.handleChange = this.handleChange.bind(this);
}
// 这是一个生命周期方法,用于首次渲染组件后立即执行逻辑。
componentDidMount(): void {
this.refreshChallenge();
}
handleChange(event) {
const name = event.target.name;
this.setState({
[name]: event.target.value
});
}
handleSubmitResult(event) {
event.preventDefault();
ApiClient.sendGuess(this.state.user,
this.state.a,
this.state.b,
this.state.guess)
.then(res => {
if (res.ok) {
res.json().then(json => {
if (json.correct) {
this.updateMessage("Congratulations! Your guess is correct");
} else {
this.updateMessage("Oops! Your guess " + json.reaultAttempt + " is" +
" wrong, but keep playing!");
}
this.updateLastAttempts(this.state.user);
this.refreshChallenge();
});
} else {
this.updateMessage("Error: server error or not available");
}
});
}
updateMessage(m: string) {
this.setState({
message: m
});
}
render() {
return (
<div className="display-column">
<div>
<h3>Your new challenge is</h3>
<div className="challenge">
{this.state.a} x {this.state.b}
</div>
</div>
<form onSubmit={this.handleSubmitResult}>
<label>
Your alias:
<input type="text" maxLength="12" name="user"
value={this.state.user} onChange={this.handleChange}/>
</label>
<br/>
<label>
Your guess:
<input type="number" min="0" name="guess"
value={this.state.guess} onChange={this.handleChange}/>
</label>
<br/>
<input type="submit" value="Submit"/>
</form>
<h4>{this.state.message}</h4>
{this.state.lastAttempts.length > 0 &&
<LastAttemptsComponent lastAttempts={this.state.lastAttempts}/>
}
</div>
);
}
updateLastAttempts(userAlias: string) {
ApiClient.getAttempts(userAlias).then(res => {
if (res.ok) {
let attempts: Attempt[] = [];
res.json().then(data => {
data.forEach(item => {
attempts.push(item);
});
this.setState({
lastAttempts: attempts
});
})
}
})
}
refreshChallenge() {
ApiClient.challenge().then(res => {
if (res.ok) {
res.json().then(json => {
this.setState({
a: json.factorA,
b: json.factorB,
});
});
} else {
this.updateMessage("Can't reach the server");
}
});
}
}
export default ChallengeComponent;
请注意变化的地方,添加了新属性lastAttempts到state中,添加了2个方法:updateLastAttempts和refreshChallenge,render方法也进行了修改,修改了样式,也添加了ChallengeAttempt列表显示。
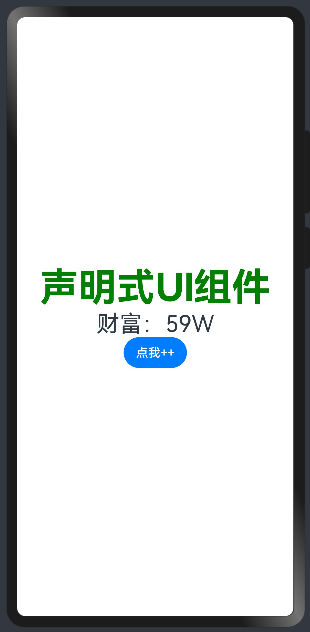
启动后端应用程序,在前端应用程序控制台执行npm start命令,进行体验。在浏览器地址栏输入:http://localhost:3000,访问页面,输入尝试,下面是一种体验:
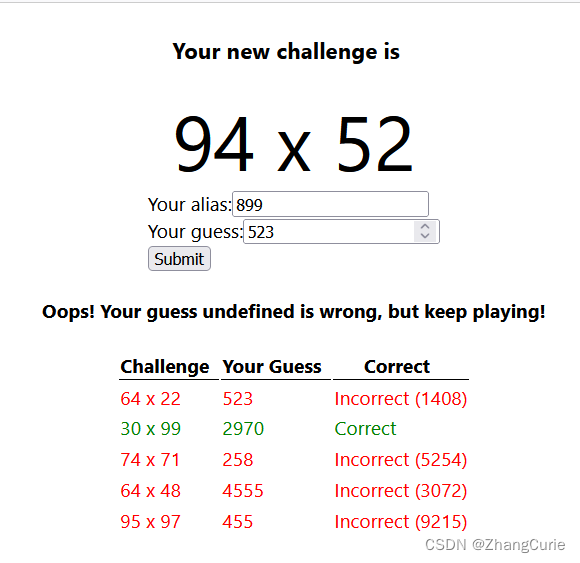
现在,成功地完成了前端应用程序的开发。
如果关心H2数据库,可以在浏览器中访问:http://localhost:8080/h2-console,下面是查询CHALLENGE_ATTEMPT表数据的截图:
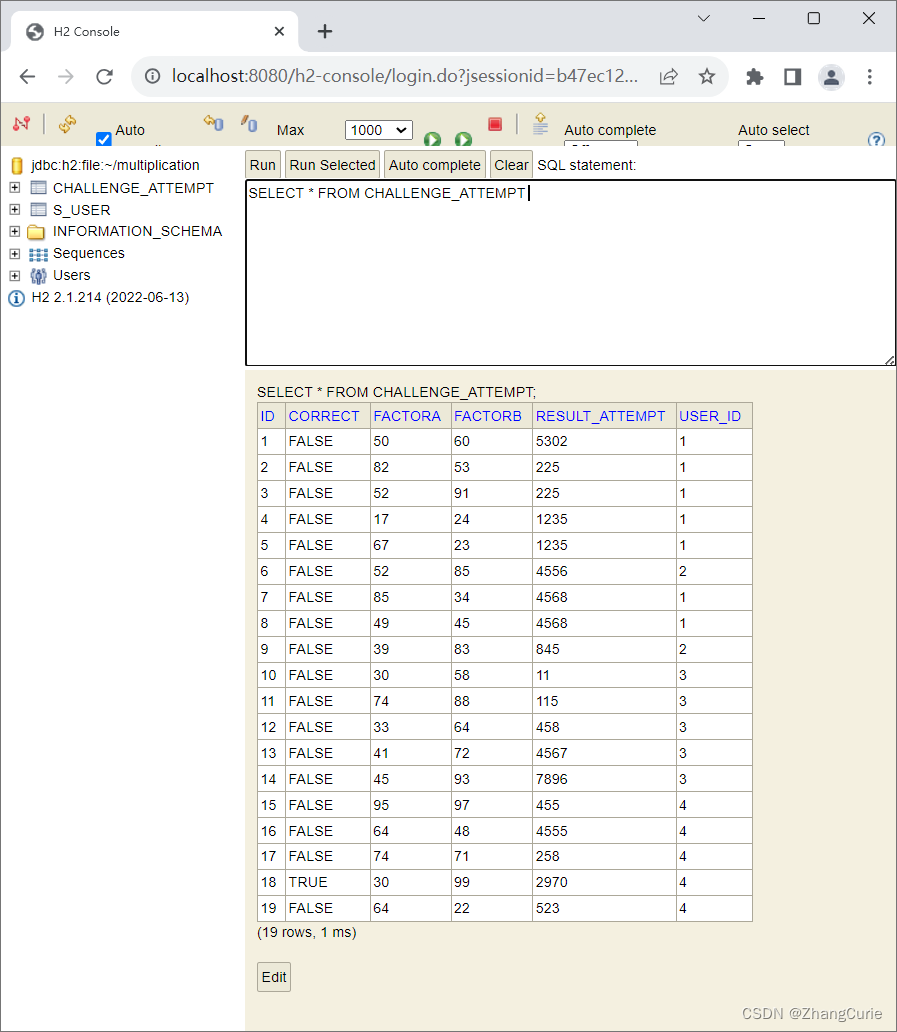
小结
文章介绍了如何持久化建模数据并使用对象关系映射(ORM)将领域对象转换为数据库记录,讲述了使用JPA注解来映射Java类之间的关联,学习使用Spring Data存储库的功能,来高效编写代码的方法。通过扩展前面介绍的用户乘法测数游戏的功能扩展,展示了如何实现存储库、完善服务层,进而完成控制器层的REST API接口构建,以及如何实现前端页面组件的构造和交互。至此已经完成了整个应用程序的构造过程。





![[数据结构]-map和set](https://img-blog.csdnimg.cn/direct/fed1f983c22d4b09abce677a7ee29e56.png)


![解决掘金量化平台,赋权原因导致委托异常(委托价格低于标的[xxxx]当日的跌停价格)](https://img-blog.csdnimg.cn/direct/d07720ac4bd743338aca493949a6c3e1.png)



