高可用集群架构
哨兵模式缺点
- 主从切换阶段, redis服务不可用,高可用不太友好
- 只有单个主节点对外服务,不能支持高并发
- 单节点如果设置内存过大,导致持久化文件很大,影响数据恢复,主从同步性能
高可用集群
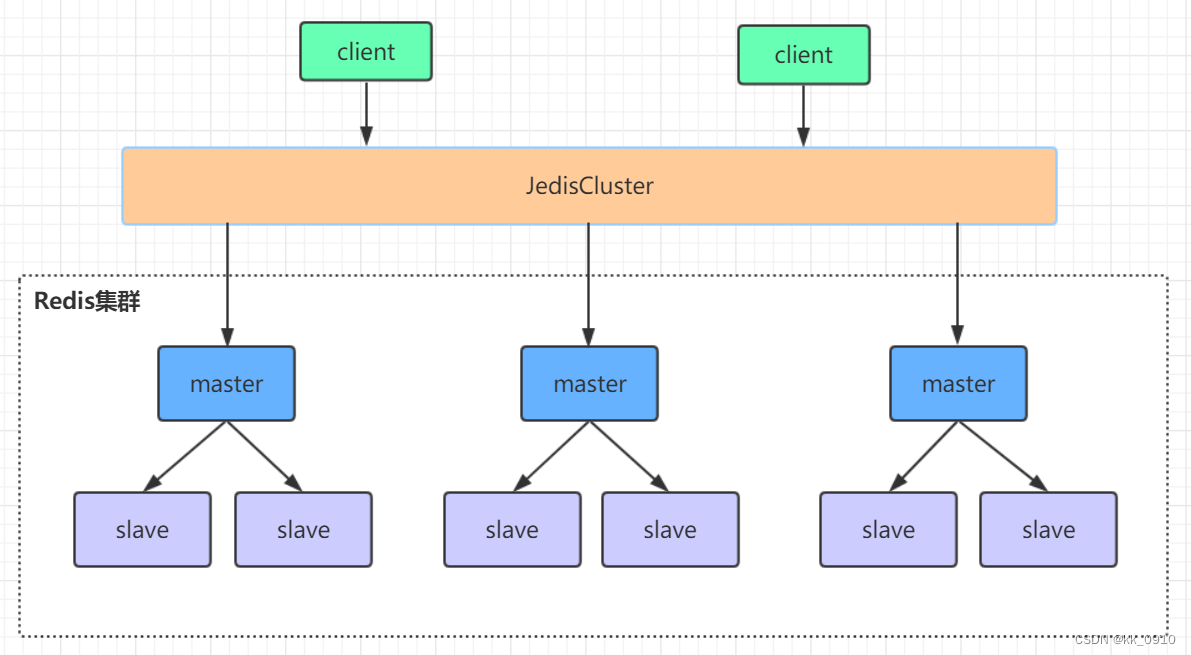
由多个主从节点群组成的分布式集群,具有复制,分片,高可用特性。并且支持水平扩展,官方建议水平扩展不超过1000个。redis集群的性能和高可用性均优于哨兵模式。
高可用集群搭建
redis集群需要至少三个master节点,这里搭建三个(一主一从)小集群,共6个redis节点
1. 把旧的redis.conf配置文件copy到8001文件夹下,并修改如下配置
port 8001 #端口
pidfile /var/run/redis_8001.pid #把pid进程号写入pidfile配置的文件
#指定数据文件存放位置,必须要指定不同的目录位置
dir /home/kk/local/redis-7.2.3/high-cluster/8001
cluster-enabled yes #启动集群模式
cluster-config-file nodes-8001.conf #集群节点信息文件,这里800x最好和port对应上
cluster-node-timeout 100002. 分别启动6个节点
src/redis-server high-cluster/8001/redis.conf
src/redis-server high-cluster/8002/redis.conf
src/redis-server high-cluster/8003/redis.conf
src/redis-server high-cluster/8004/redis.conf
src/redis-server high-cluster/8005/redis.conf
src/redis-server high-cluster/8006/redis.conf3. 创建集群,系统会自动给每个节点分配槽位
src/redis-cli --cluster create --cluster-replicas 1 192.168.6.128:8001 192.168.6.128:8002 192.168.6.128:8003 192.168.6.128:8004 192.168.6.128:8005 192.168.6.128:8006
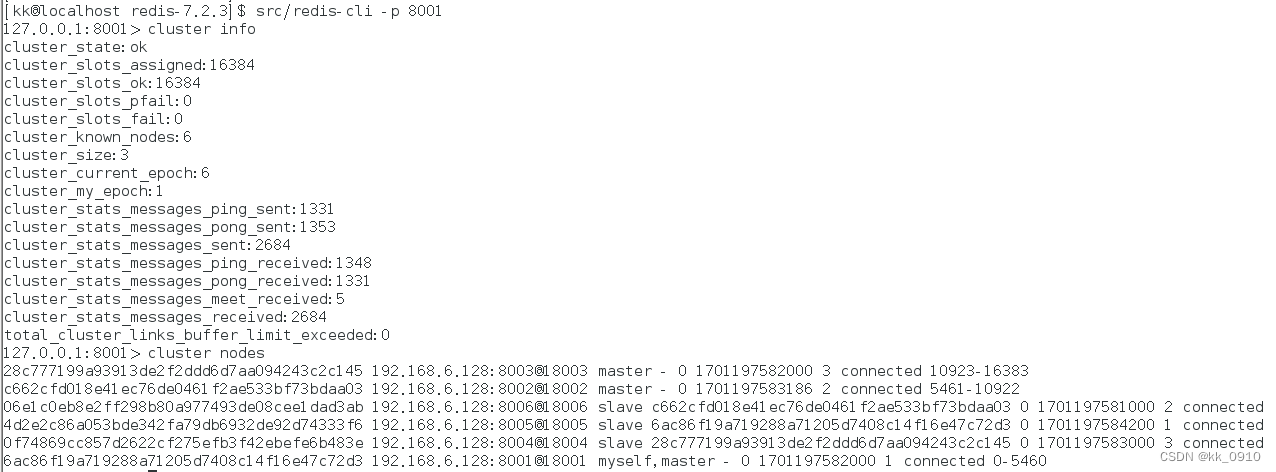
4. 验证集群
连接任意一个客户端,查看集群信息和节点信息
[kk@localhost redis-7.2.3]$ src/redis-cli -p 8001
127.0.0.1:8001> cluster info
127.0.0.1:8001> cluster nodes
5. 关闭集群,依次关闭6个节点
src/redis-cli -p 8001 shutdown槽位
概念
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,需要纠正机制来实现槽位信息的校验调整。
槽定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) % 16384
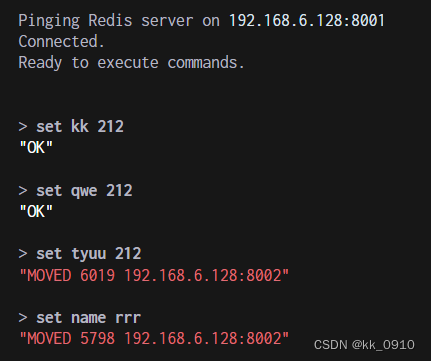
跳转重定位
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽位映射表。
示例
节点间通信机制
通信方式
集群的元数据(集群节点信息,主从角色,节点数量,各节点共享的数据等)通信方式
- 集中式
- gossip
redis cluster节点间采取gossip协议进行通信
网络抖动
当某个节点持续失联时间超过cluster-node-timeout,可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
脑裂数据丢失
网络分区后, 主节点和从节点可能网络通讯中断, 会重新在从节点选举出一个新的主节点, 这个时候这两个主节点都能写数据, 网络恢复后, 旧的主节点会被更新成从节点, 这时旧主节点写入的数据就会丢失。
解决方案:
加上下面配置,往旧的主节点写数据时, 会失败,从节点数量小于1.
此配置虽然提升了一致性,但是会牺牲可用性
min-slaves-to-write 1 //写数据成功最少同步的slave数量集群存在问题
1. 批量操作失败
mset/mget批量操作时, 如果hash槽位不在一个节点, 会写入/读取失败
解决:在key的前面加上{XX},这样参数数据分片hash计算的只会是大括号里的值,确保不同的key能落到同一slot里去
示例:
mset {user1}:1:name kk {user1}:1:age 18水平扩容
集群命令
- create:创建一个集群环境host1:port1 ... hostN:portN
- call:可以执行redis命令
- add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
- del-node:移除一个节点
- reshard:重新分片
- check:检查集群状态
高峰时用add-node扩容, 高峰结束用del-node缩容,用reshard槽位迁移