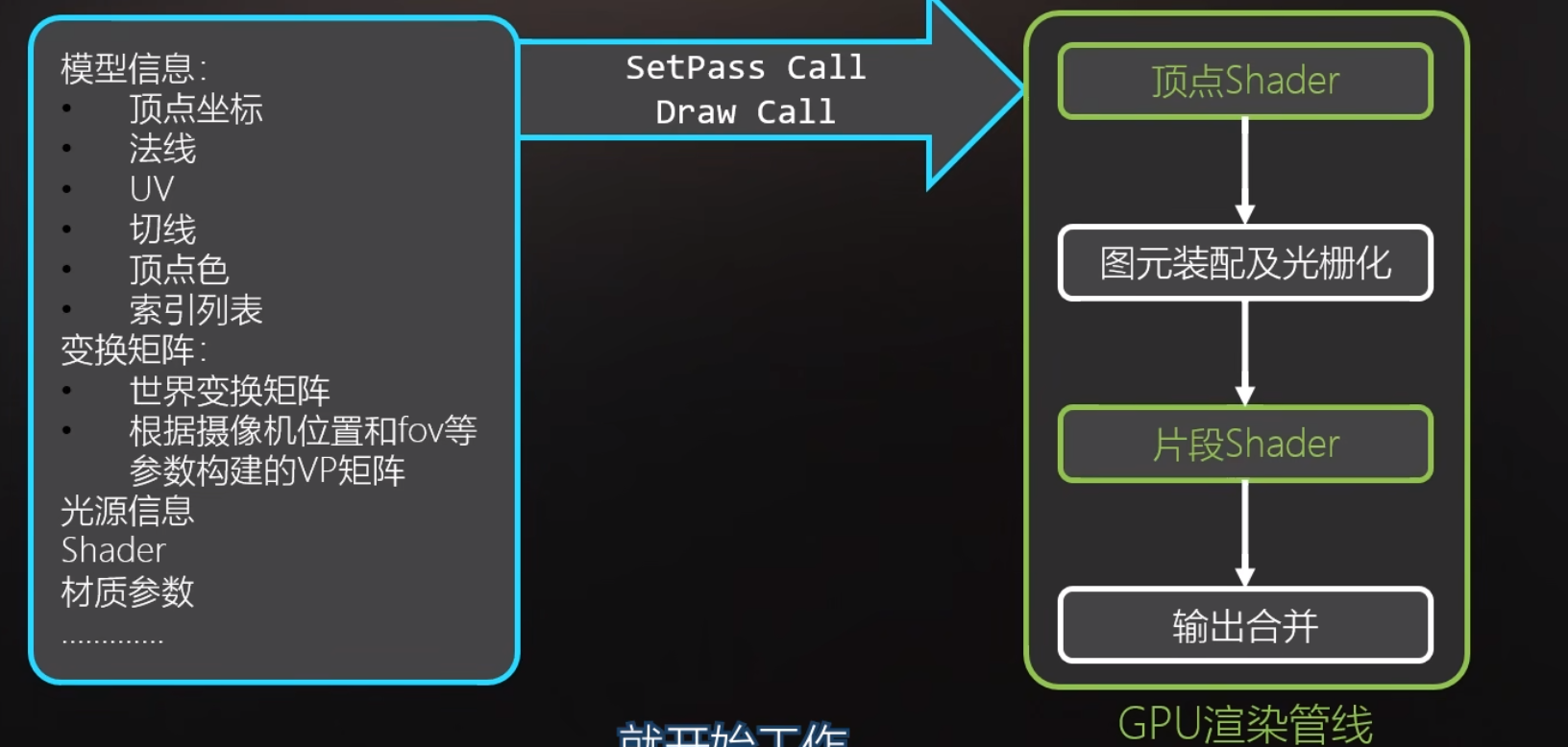
1.元素操作
在成功定位到元素之后,我们需要对元素进行一些操作动作。常用的元素操作动作有:
(1)send_keys()
键盘动作:向浏览器发送一个内容,通常用于输入框输入内容或向浏览器发送快捷键
(2)click()
鼠标左键单击,通常用于点击按钮
(3)clear()
清空内容,通常用于输入框内容清空
注意:在进行测试实战时,向输入框发送内容前,要养成先清空的习惯。如果输入前输入框有内容,则send_keys()会在原内容上追加输入,从而影响测试结果。
代码示例
# 导包
from time import sleep
from selenium import webdriver
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 展示效果
sleep(1)
# 实现需求
element_find = driver.find_element_by_id('kw')
element_Button = driver.find_element_by_id('su')
# 输入文本
element_find.send_keys('元素')
sleep(1)
# 清空
element_find.clear()
sleep(1)
# 再次输入,实际操作中,养成习惯,先清空再输入,防止输入框原本有内容影响脚本执行
element_find.send_keys('定位')
sleep(1)
# 点击搜索
element_Button.click()
sleep(3)
# 关闭浏览器
driver.quit()
2.浏览器操作
除了对元素进行操作外,对浏览器窗口的操作也是必不可少的,常见的浏览器操作如下:
(1)get()
在浏览器窗口打开指定的网页 driver.get(URL)
(2)maximize_window()
将浏览器窗口最大化 driver.maximize_window()
(3)set_window_size()
设置浏览器窗口尺寸(单位是像素) driver.set_window_size(窗口宽,窗口高)
(4)set_window_positions()
设置浏览器窗口打开位置(单位是像素,设置的坐标为窗口左上角的坐标)
driver.set_window_positions(x,y)
(5)back()
页面回退,等于网页地址栏左上角的返回箭头
(6)forward()
页面前进,等于网页地址栏左上角的→箭头
(7)refresh()
刷新页面,等于按住F5快捷键刷新或者点击![]() 按钮
按钮
(8)close()
关闭当前网页,等于点击一个网页标签上的X
(9)quit()
关闭浏览器,等于在浏览器右上角点X,关闭当前浏览器的所有页面。
代码示例
# 导包
from time import sleep
from selenium import webdriver
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 展示效果
sleep(1)
# 最大化浏览器窗口
driver.maximize_window()
sleep(1)
# 设置浏览器窗口为指定大小,单位是像素点
# 浏览器会保证一个最小窗口,能显示URL和基本按钮,不会任意缩小到无限小
driver.set_window_size(800,1000)
sleep(1)
# 设置浏览器打开位置
# 以屏幕左上角为(0,0)
driver.set_window_position(0,0)
sleep(1)
# 任意搜索一个内容(测试准备)
driver.find_element_by_id('kw').send_keys('test')
driver.find_element_by_id('su').click()
sleep(2)
# 浏览器后退按钮(返回上一页),返回百度首页
driver.back()
sleep(1)
# 浏览器前进按钮(前进回到返回前那一页),返回搜索页
driver.forward()
sleep(1)
# 刷新页面
# 向服务器重新发起请求
driver.refresh()
sleep(2)
# 打开百度热搜页面
driver.maximize_window()
driver.find_element_by_class_name('toindex').click()
driver.find_element_by_xpath('//*[@id="s-hotsearch-wrapper"]/div/a[1]/div').click()
sleep(2)
# 获取当前页title和current_url两个属性(get的这个页面,不是新打开页页面)
# 虽然新打开了百度热搜页面,也在最上层打开了,但是这是浏览器的操作,代码的操作对象还是百度首页
print(driver.title)
print(driver.current_url)
# 关闭单个页面(,没有进行页面切换动作,关闭的是跳转前的页面,不是新打开额页面)
driver.close()
sleep(2)
# 关闭浏览器
driver.quit()
3.获取元素信息
在执行测试任务时,如果只是操作浏览器进行指定动作而不判断交互结果是否符合预期,那么测试就是无效的。获取元素的相关信息并使用断言进行判断,能够帮助我们判断元素是否在进行了指定操作后做出了响应的交互变化,例如勾选、页面切换、URL变化等。获取元素信息主要有以下方法:
(1)text
获取元素的文本信息,通常用于弹窗警告信息的提取
element.text
(2)size
获取元素的尺寸大小,通常用于页面布局判断
element.size
(3)is_displayed()
判断元素是否在页面肉眼可见(是否显示在页面上),通常用于权限验证
element.is_displayed()
(4)is_enabled()
判断元素是否可用,通常用于权限控制(不登录,某些功能能看到但是不能用)
element.is_enabled()
(5)get_attribute()
获取元素的某个属性值,通常用于业务操作之间的依赖参数传递
element.get_attribute(属性名)
(6)is_selected()
判断元素是否被选中,通常用于选择框或选择按钮
element.is_selected()
代码示例
# 导包
from time import sleep
from selenium import webdriver
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 展示效果
sleep(2)
# 实现需求
# 1.size 返回元素大小
# 应用场景:判断页面布局是都符合预期
find_element = driver.find_element_by_id('kw')
print('搜索框的大小是:', find_element.size)
# 2.text获取元素的文本
# 应用场景:切换页面后对特定元素的文本信息进行获取,通常用于断言
find_button = driver.find_element_by_class_name('hot-refresh-text')
print('换一换按钮的文本内容是:', find_button.text)
# 3.get_attribute()获取属性值
# 应用场景:获取指定属性值,当做参数传递给其他方法使用
element1 = driver.find_element_by_xpath('//*[text()="关于百度"]')
driver.get(element1.get_attribute('href'))
sleep(2)
# 4.is_displayed() 判断元素是否肉眼可见(是否在页面显示),可见返回True,不可见返回False
# 应用场景:判断元素是否显示
# 元素隐藏显示,不影响元素定位,不意味着元素一定不存在
driver.get('https://www.baidu.com')
sleep(1)
hotsearch_element = driver.find_element_by_id('hotsearch_data')
print(hotsearch_element.is_enabled())
# 5.is_enabled()判断元素是否可用
# 应用场景:判断元素是否能够进行交互,不符合要求的时候某些功能不能使用时
# 6.is_selected()判断元素是否选中
# 应用场景:判断单选或复选框是否被选中,例如购物车
# 关闭浏览器
driver.quit()
4.鼠标动作
Selenium将鼠标动作全部封装在了ActionChains()类中,在进行鼠标动作时需要以下步骤:
①实例化鼠标对象:action = ActionChains(driver)
②调用鼠标动作方法:action.click()
包括方法如下:
单击 click(element)
双击 double_click(element)
右键单击 context_click(element)
在元素上方悬停 move_to_element(element)
拖拽 dreg_and_drop(初始element,目标element)
③调用.perform()方法执行步骤②的动作
代码示例
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(10)
sleep(2)
# 实例化鼠标对象
action1 = ActionChains(driver)
#
# 单击百度首页新闻按钮
news_element = driver.find_element_by_link_text('新闻')
action1.click(news_element).perform() # 调用动作函数并执行,即点击百度首页新闻超链接
# 以上代码可以简写为
# action.click(driver.find_element_by_link_text('新闻')).perform()
sleep(5)
# 测试准备:关闭新打开的新闻页,当前阶段忽略此段代码
driver.switch_to.window(driver.window_handles[-1])
print(driver.title)
driver.close()
driver.switch_to.window(driver.window_handles[0])
sleep(2)
print(driver.title)
# 在百度输入框输入“test”并双击选中输入的文本
search_element = driver.find_element_by_css_selector('#kw')
search_element.send_keys('test')
driver.find_element_by_id('su').click()
sleep(3)
"""
这里留个疑问,欢迎各位小伙伴解惑:
在下面代码大家可以看到,我新实例化了一个鼠标对象action2。
因为之前实例化的那个鼠标对象action1在切换新闻页面后再次使用就报错了
错误提示‘百度输入框’这个元素在https://news.baidu.com找不到,但是我driver已经切回首页了呀???
代码里也打印了切换页面之后的title,页面是切换成功了的
也就是说,虽然driver层完成了页面切换,action1在切换页面后的操作对象还留在新闻页没有切回来
疑问:为什么没有随driver切换呢?要怎样才能完成切换操作呢?还是说必须得新实例化一个鼠标???
"""
action2 = ActionChains(driver)
action2.double_click(search_element).perform()
sleep(2)
# 在百度输入框右键
action2.context_click(search_element).perform()
sleep(2)
# 在百度首页,设置上方悬停
action2.move_to_element(driver.find_element_by_css_selector('#u > a.pf')).perform()
sleep(2)
# 将百度热搜拖拽到搜索框,百度热搜地址出现在输入框
search_element.clear()
hot_search = driver.find_element_by_link_text('百度首页')
action2.drag_and_drop(hot_search, search_element).perform()
sleep(2)
# 关闭浏览器
driver.quit()
5.键盘动作
Selenium的键盘动作都使用send_key()函数来实现,如果需要联合使用多个键,可以调用Keys类来实现。
用法如下:
例如Ctrl+C: element.send_keys(Keys.CONTRAL,'c')
其他快捷键用法类似,还好包含了以下常用键:
删除:BACK_SPACE(即键盘上最常用的删除键,一次删除一个字符或汉字,在某些品牌电脑上这个键写的是Delete,某些品牌写的是Backspace)
空格:SPACE
回车:ENTER
制表符:TAB(即键盘上的Tab键)
其他内容可以自行进入底层代码查看(将光标放在Keys上,Ctrl+B可以进入它的底层封装代码,都封装了哪些键盘,有具体说明)
代码示例
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 浏览器窗口最大化
driver.maximize_window()
# 展示效果
sleep(1)
text_element = driver.find_element_by_id('kw')
text_element.send_keys('Test')
sleep(1)
# 删除一个字符
text_element.send_keys(Keys.BACKSPACE)
sleep(1)
# 空格+tab,同时按
text_element.send_keys(Keys.SPACE, Keys.TAB)
sleep(1)
# 回车
text_element.send_keys(Keys.ENTER)
sleep(1)
# 全选
text_element.send_keys(Keys.CONTROL, 'a')
sleep(1)
text_element.send_keys(Keys.CONTROL, 'c')
text_element.send_keys(Keys.CONTROL, 'v')
text_element.send_keys(Keys.ENTER)
sleep(1)
# 关闭浏览器
driver.quit()
6.元素等待
为什么要设置元素等待:由于我们在测试过程当中受网络、测试机性能、加载速度等环境影响,元素并不是永远都能够在打开页面的一瞬间全部加载完成的(还有些页面是动态加载的,例如淘宝),这就会导致代码执行到了,但是元素没有加载完成,代码报错。
为代码添加一个等待机制,等待元素加载完成再进行查找和操作,会大大减少因环境影响而导致的报错,提升工作效率。
(1)隐式等待
①等待机制
在定位元素时,如果找到了元素,则不触发等待
没有找到,则间隔一段时间后再去定位,直到找到元素或达到设定的最长等待时间为止
找不到则抛出异常:NoSuchElementException
②优缺点
优点:全局只需要设置1次,只要有元素找不到就会触发一次。
缺点:
间隔时间不受控制,只能设置最大等待时长
作用于全局,只要有一个找不到则全局等待
遇到动态加载页面会引起执行效率过低。例如:如果遇到动态加载的页面,页面中刚好有元素未加载完成,触发了等待,最长等待时长为10s。但是这个元素很快就加载完成了,只用了2s。但是此时动态加载的元素还需要等待用户操作或者等够动态变换的时间才加载,这时隐式等待是不会关闭的,会等够10s或者等到动态元素加载完成才关闭。大大的浪费了时间。
(2)显式等待
①等待机制
在定位元素时,如果找到了元素,则不触发等待
没有找到,则间隔一段时间后再去定位,直到找到元素或达到设定的最长等待时间为止
找不到则抛出异常:TimeoutException
②优缺点
优点:
等待间隔受控,可以自定义设置。
只作用于一个元素
缺点:
每个需要等待的元素都要设置一次
代码示例
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待:通常设置10s
driver.implicitly_wait(10)
sleep(2)
# 显示等待
"""
解析:
实例化等待对象WebDriverWait(),参数分别是浏览器驱动对象,等待最大时长,等待时间间隔
调用这个WebDriverWait()类的until()方法,参数是要定位的元素
返回值是元素对象,使用element1接收保存,供后续调用
意思是定义一个显式等待,最大等待时长10s,等待间隔为1s,用于查找id为'kw'的元素。
如果元素找到则返回元素对象,没有找到则每隔1s查找一次,直到找到元素或到达指定最大时长10s
注意:在实际测试工作中,最大时长通常设置为10s,实际已上线项目,通常最大等待时长为30s,再大就会影响用户体验了
查找的时间间隔,默认是0.5s,缺省即默认0.5s,也可以自定义
"""
element1 = WebDriverWait(driver,10,1).until(lambda x: x.find_element_by_id('kw'))
# 关闭浏览器
driver.quit()
为什么until的参数要是一个匿名函数呢?我们可以看一下这个方法的底层,它要求参数需要是一个method即方法,那么我们使用匿名函数来充当参数就可以了。使用匿名函数变量X,来充当driver,写一个查找语句。如果不了解匿名函数的,可以去参考我之前的python学习笔记,函数那一篇。