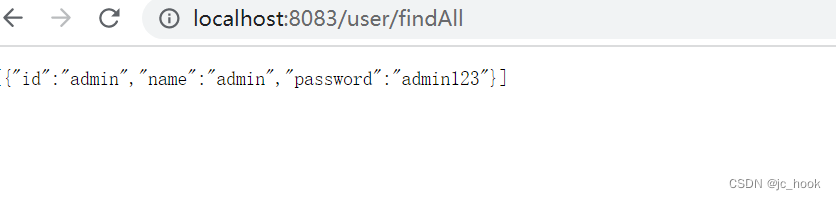
通过bert中文预训练模型得到中文词向量和句向量,步骤如下:
下载 bert-base-chiese模型
只需下载以下三个文件,然后放到bert-base-chinese命名的文件夹中
得到中文词向量的代码如下
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') # 加载base模型的对应的切词器
model = BertModel.from_pretrained('bert-base-chinese')
print(tokenizer) # 打印出对应的信息,如base模型的字典大小,截断长度等等
token = tokenizer.tokenize("自然语言处理") # 切词
print(token) # 切词结果
indexes = tokenizer.convert_tokens_to_ids(token) # 将词转换为对应字典的id
print(indexes) # 输出id
tokens = tokenizer.convert_ids_to_tokens(indexes)# 将id转换为对应字典的词
print(tokens) # 输出词
# 使用这种方法对句子编码会自动添加[CLS] 和[SEP]
input_ids = torch.tensor(tokenizer.encode("自然语言处理")).unsqueeze(0)
print(input_ids)
outputs = model(input_ids)
# cls_id = tokenizer._convert_token_to_id('[CLS]')
# sep_id = tokenizer._convert_token_to_id('[SEP]')
# print(cls_id, sep_id)
sequence_output = outputs[0]
pooled_output = outputs[1]
print(sequence_output)
print(sequence_output.shape) ## 字向量
print(pooled_output.shape) ## 句向量
输出的结果如下
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
['自', '然', '语', '言', '处', '理']
[5632, 4197, 6427, 6241, 1905, 4415]
['自', '然', '语', '言', '处', '理']
tensor([[ 101, 5632, 4197, 6427, 6241, 1905, 4415, 102]])
tensor([[[-0.5707, 0.1999, -0.0637, ..., -0.0916, -0.3997, 0.1751],
[ 0.1549, 0.2454, 0.8372, ..., -0.7411, -0.8433, 0.5498],
[ 0.1983, -0.5007, -0.6416, ..., 0.0322, -0.2561, 0.0599],
...,
[ 0.1960, 0.4055, 1.6229, ..., 0.1070, -0.2448, 0.1766],
[ 0.0846, 0.9084, 0.5164, ..., 0.0235, 0.6487, -0.0858],
[-0.5326, -0.0390, 1.9163, ..., 0.1597, -0.2909, 0.6810]]],
grad_fn=<NativeLayerNormBackward0>)
torch.Size([1, 8, 768])
torch.Size([1, 768])
当然还可以通过bert-as-service得到词向量,网上有很多,步骤如下:
-
安装肖涵博士的bert-as-service:
pip install bert-serving-server
pip install bert-serving-client -
下载训练好的Bert中文词向量:
https://storage.proxy.ustclug.org/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip -
启动bert-as-service:
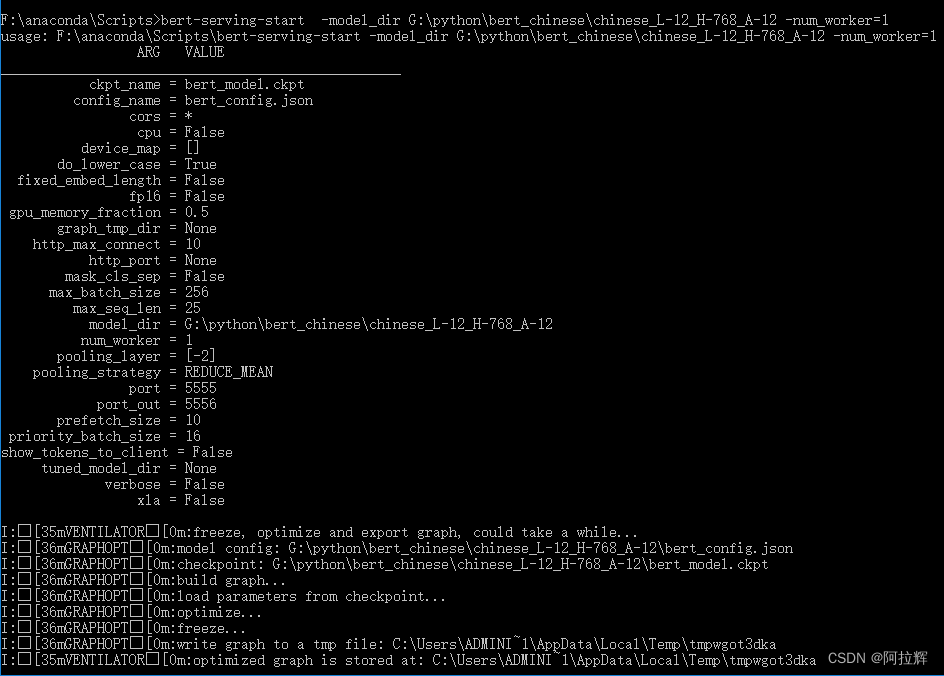
找到bert-serving-start.exe所在的文件夹(我直接用的anaconda prompt安装的,bert-serving-start.exe在F:\anaconda\Scripts目录下。)找到训练好的词向量模型并解压,路径如下:G:\python\bert_chinese\chinese_L-12_H-768_A-12
打开cmd窗口,进入到bert-serving-start.exe所在的文件目录下,然后输入:
bert-serving-start -model_dir G:\python\bert_chinese\chinese_L-12_H-768_A-12 -num_worker=1
#后台启动服务(nohup .... &)
nohup bert-serving-start -model_dir G:\python\bert_chinese\chinese_L-12_H-768_A-12 -num_worker=1 &
即可启动bert-as-service(num_worker好像是BERT服务的进程数,例num_worker = 2,意味着它可以最高处理来自 2个客户端的并发请求。)
启动后结果如下:
获取Bert预训练好的中文词向量:
from bert_serving.client import BertClient
bc = BertClient()
print(bc.encode([“NONE”,“没有”,“偷东西”]))#获取词的向量表示
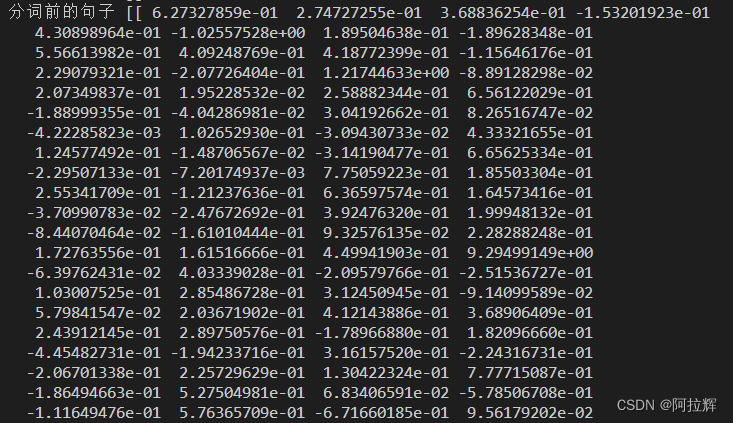
print(bc.encode([“none没有偷东西”]))#获取分词前的句子的向量表示
print(bc.encode([“none 没有 偷 东西”]))#获取分词后的句子向量表示
结果如下:其中每一个向量均是768维。