A data-driven dynamic repositioning model in bicycle-sharing systems

爱思唯尔原文
doi:https://doi.org/10.1016/j.ijpe.2020.107909
@article{data2021BRP,
address = {Univ Cambridge, Inst Mfg, Cambridge CB3 0FS, England},
author = {Zhang, Jie and Meng, Meng and Wong, Yiik Diew and Ieromonachou, Petros and Wang, David Z W},
doi = {10.1016/j.ijpe.2020.107909},
issn = {0925-5273},
journal = {INTERNATIONAL JOURNAL OF PRODUCTION ECONOMICS},
mendeley-groups = {rebike21-23},
title = {{A data-driven dynamic repositioning model in bicycle-sharing systems}},
volume = {231},
year = {2021}
}
摘要
新一代共享单车是一种O2O(online-to-offline)(线上到线下)平台服务,使用户users能够通过智能手机应用程序smartphone App访问自行车。该文提出一种具有预测需求的动态重新定位模型(a dynamic repositioning model with predicted demand),其中重新定位时间间隔是固定的(he repositioning time interval is fixed)。引入数据驱动的神经网络(NN)方法来预测自行车共享需求。定义每个时间间隔的重新定位目标函数,以同时最小化操作员成本和惩罚成本(The repositioning objective function at each time interval is defined to simultaneously minimize the operator cost and penalty cost.)。除了静态重新定位问题中的正常约束外,还考虑了流量守恒(flow conservation)、库存平衡(inventory-balance )和行程时间约束( travel time constraints )。针对该模型的非确定性多项式时间硬(NP-hard)特性,采用自适应遗传算法(Adaptive Genetic Algorithm (AGA))(AGA)和粒度禁忌搜索(Granular Tabu Search)(GTS)算法的混合元启发式方法计算解。根据预测需求,AGA 在研究期开始时静态地制定初始重新定位计划,保证了第一个解决方案的全局优化。随着时间的推移,利用 GTS 算法根据实际使用模式对重新定位计划进行检查和更新,具有在较短的计算时间内实现高性能本地搜索的优势。使用真实案例进行数值分析。仿真结果表明**,所提方法能够有效地模拟实时共享单车使用的动态重新定位问题。**所提出的方法可以成为提高自行车共享计划的可行性和可持续性的增值工具。
关键字
- Bicycle-sharing 共享单车
- Dynamic repositioning 动态重新定位
- Demand prediction 需求预测
- Neural network 神经网络
*Data-driven 数据驱动
一简介
随着人们对交通可持续性的日益认可,骑自行车已成为短途旅行的重要替代公共交通方式。许多城市已经成功建立了自行车共享系统,以促进点对点旅行,特别是在第一英里/最后一英里旅行阶段。自行车共享系统Bicycle-sharing system(BSS),也称为公共自行车系统或自行车共享系统,是一种自助式公共自行车租赁计划,使用户能够在任何车站借用公共自行车并将其归还给任何其他车站以完成行程(Zhang and Meng,2019)。新一代自行车共享系统允许用户使用智能手机找到最近的自行车,扫描快速响应代码,然后骑行(The new generation of bicycle-sharing system allows users to find the closest bicycle using their smartphone, scan a Quick Response code and then ride.)。这种单向使用特性往往会导致自行车在时间和空间上的跨站点分布不平衡,在高峰时段可能会迅速升级(Zhang等人,2019)。以早高峰为例,借款利率高的车站(stations with high borrow rate)很快就会空置(例如在居民区附近,靠近最后一英里的公交站点),而回报率高的车站(stations with a high return rate)往往会迅速满员(例如在办公楼附近,靠近第一英里的公交站点)。在这种情况下,用户不能再在空车站借用自行车,也不能将自行车归还给满站。重新定位车辆(例如轻型卡车)用于将自行车从(接近)满站移动到(更多)空站。重新定位问题已经得到研究,但它主要是基于静态的“日终”方法,其中重新定位操作在安静(夜间)期间受到影响,此时共享单车需求可以忽略不计(Caggiani et al., 2018)。 鉴于车站固有的供需(借/回)情况不均衡,应定期进行重新定位,以解决自行车的不平衡问题(Given the inherently uneven demand-supply (borrow/return) situations at stations, repositioning should be done regularly to address the imbalance of bicycles. )。一些BSS方案引入了智能管理系统,通过传感器检测每个站点的自行车和码头的可用性,使用历史数据预测即将到来的需求,并提前从控制中心做出重新定位决策,以确保系统中的最佳使用(Zhang等人,2017)。在这些模块中,自行车检测和需求预测已经得到了很好的研究(Lin等人,2018)。显然,开发一种优化方法,集成这些模块,旨在及时在站点之间重新分配自行车,这是非常宝贵的(t is invaluable to develop an optimization method that integrates these modules aiming at timely redistributing the bicycles among stations)。
本文在BSS中建立了动态重新定位模型,基于数据驱动的神经网络(NN)方法预测未来需求。通过一个案例研究来研究所提出的模型如何最大限度地减少车辆的运输时间和用户的等待时间。本研究的贡献是:
(1)所提出的方法是为数不多的在自行车重新定位中结合需求预测的研究之一,使动态操作更加准确;
(2)数据驱动的NN方法已被证明在自行车重新定位研究中得到引入和应用;
(3)动态重新定位方法可以实现车辆运输时间和用户等待时间的最小。
本文的其余部分组织如下。第2节总结了相关文献,以明确研究问题。第3节介绍了数据驱动的神经网络方法来预测共享单车需求。第 4 节开发了动态重新定位模型,然后是第 5 节中的求解算法。案例研究在第6节中讨论,结论在第7节中给出。
2. 文献综述
BSS中的重新定位依赖于智能监控和调度系统。控制中心首先接收来自共享单车站的实时使用信息,然后计算重新定位服务的请求,最后安排重新定位车辆的路线,如图1所示。
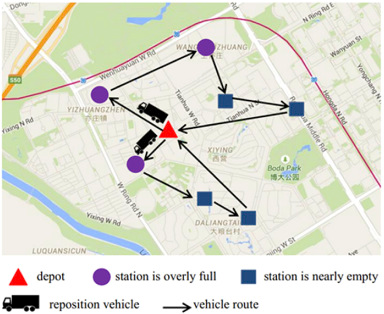
图 1.重新定位路线示意图(地图来源:谷歌地图)。
但是,随着共享单车使用情况随时变化,基于先前时间间隔的重新定位结果可能无法满足实时需求的要求。因此,控制中心通常先预测即将到来的需求,然后再制定重新定位计划。在移动共享需求预测问题的应用中引入了许多预测方法并进行了测试,例如时间序列方法、基于回归的方法、梯度提升机、NN 和贝叶斯网络 (BN)(Dai 等人,2019 年)。表1列出了几种典型的移动共享需求预测模型的性能比较。


从表1可以总结出,没有完美的预测方法可以适用于所有情况。预测方法的选择应基于研究目标、设计和可能的数据来源。本研究课题之一是根据大尺度的历史数据预测下一时间间隔内共享单车的使用情况。在这种情况下,NN可能是最佳候选者之一,因为它能够对动态过程进行建模。使用 NN 的主要优点是,NN 无需为归还或捡起的自行车假设显式函数,因为 NN 直接从历史观察到的自行车使用数据中学习。NN已经证明了在经验数据中捕获微妙的功能关系的能力,即使潜在的关系是未知的或难以描述的。与传统的统计模型不同,NN 是一种数据驱动的非参数模型。它不需要强大的模型假设,并且可以映射任何非线性函数,而无需对数据属性进行先验假设(Meng 等人,2015 年)。因此,本研究应使用NN方法预测共享单车使用情况,作为重新定位模型的输入。
BSS中重新定位问题的主要概念围绕以下三个问题:(a)重新定位车辆要携带多少辆自行车,(b)车辆如何路由,以及(c)重新定位的频率。(The main concept of repositioning problem in BSS revolves around the following three questions: (a) how many bicycles to be carried by the repositioning vehicle, (b) how to route the vehicle, and © the frequency of repositioning. )
前两个问题属于广泛的提货和送货车辆路径问题( Pickup and Delivery Vehicle Routing Problem )(PDVRP),根据不同的标准分为不同的类型:(a)具有单个或多个仓库的PDVRP;(b) 具有单一或多个目标的PDVRP;(c) 有或没有时间窗口的PDVRP;以及(d)有或没有容量限制的PDVRP(Zhang等人,2015年,2018年;阿卜杜勒卡德尔等人,2018 年)。
一般来说,每个站点的自行车数量可以被视为车站的库存(inventory of the station),而送货服务被视为库存补货服务( the inventory restocking service)(Ting和Liao,2013;李等, 2019;贝尔纳多等人,2020 年)。与仅提供供应服务的库存管理不同,BSS中的重新定位同时提供收集(从满站/接近满站)和返回(到空/近空站)服务。重新定位的自行车数量通常是一个变量值,该值是根据实际字段计数计算的,或者在极少数情况下,是一个固定的常数(Raviv 和 Kolka,2013 年;林等, 2013;刘和塞德,2020)。车辆路径优化的目标是最小化总路线成本,这已经被广泛讨论使用各种方法,例如图论方法(graph theoretical approach),数学方法(mathematical approach)和模拟方法(simulation approach.
)。
重新定位频率的第三个问题可以是在需求可以忽略不计的安静(夜间/一天结束时)期间,称为静态重新定位(static repositioning),也可以在白天某些站点的库存达到一定水平的任何时候,称为动态重新定位(dynamic repositioning)。目前,静态重定位模型已经得到了大量的研究;已经开发了线性规划公式、非延时混合整数公式和双层优化公式,并在其应用中获得了详细的结果(Forma 等人,2015 年;何和司徒,2014;李等, 2016;王和司徒,2018)。
最近关于动态模型的制定和分析的几项研究已经实现并发表了重要进展,其中考虑了用户随时间推移的需求。理论上,沿连续更新时间的连续动态重新定位模型是优选的。然而,对于实际应用而言,考虑到BSS中重新定位车辆的数量有限以及重新定位车辆的不可持续连续运行,连续动态重新定位模型不一定合理。因此,现有的所有研究都以离散的形式处理动态重新定位问题是合理的,其中研究周期被划分为一定数量的时间间隔,系统状态在每个时间间隔的开始时更新。Contardo等人(2012)正式将这个问题定义为动态公共自行车共享平衡问题,并使用弧流公式提出了时空网络上的数学模型。尽管该模型存在一些缺点,例如忽略了装卸时间,在实践中应用复杂,但该模型代表了从运筹学角度通过嵌套方式结合Dantzig-Wolfe和Benders分解来解决重新定位问题的第一次重大尝试。Raviv和Kolka(2013)通过引入用户不满函数来衡量车站的性能,提出了自行车共享租赁站的动态库存模型。Regue和Recker(2014)提出了一个框架,将需求预测纳入动态自行车共享重新定位问题。该框架包括四个核心模型,即需求预测模型、车站库存模型、再分配需求模型和车辆路径模型。 基于波士顿共享单车数据的仿真结果表明,BSS性能提高了7%,从而在晚高峰期间将空事件和满事件的数量分别减少了57%和76%。Sayarshad等人(2012)和Shu等人(2013)研究了具有固定长时间间隔的重新定位过程,其中一个重新定位周期可以在一个时间间隔内完成。Kaspi等人(2016)以BSS为解释性示例,研究了通过停车预订政策对单向车站车辆共享系统的监管。最近,Ghosh等人(2017)通过使用混合整数线性规划方法对动态重新定位问题进行了建模,其中考虑了重新定位车辆的路线和未来的预期需求。Ghosh和Varakantham(2017b)从自行车拖车的角度进一步考虑了这个问题,为拖车生成了重新定位任务,以更好地满足客户需求。以类似的方式,Lowalekar等人(2017)提出了一种在线方法,使用历史数据中的需求样本来计算动态重新定位和路由策略。上述动态模型处理了更新重新定位计划的非常长的间隔(大约 20、40 和 60 分钟,或超过 1 小时),其中短期使用需求变化可能无法准确反映。
本研究采用固定时间间隔相对较短的动态方法,根据历史数据,采用NN方法预测即将到来的共享单车需求。预测模型的结果应设置为车辆重新定位的输入。仅在时间间隔开始时检查重新定位决策。在时间间隔内,自行车借用/归还计数以及因此需要重新定位的车辆编号被视为在时间间隔开始时发生。进行重新定位的判断标准基于可用的自行车码头(或无桩操作中的放置批次)。由于假设只考虑了本地实时需求,没有提前计算了长时间的计划,因此在同时考虑实时使用水平和库存的同时,保证了模型的很大灵活性,从而大大降低了计算的复杂性。
3. 共享单车需求预测
如前所述,NN方法已广泛应用于移动共享运营中的需求预测,其中NN的四个基本步骤包括:数据收集;网络结构定义;网络培训;和网络模拟。典型神经网络的原理图如图2所示,它由一个输入层、一个输出层和多个隐藏层组成。网络学习过程包括数据流的前向计算和错误信号的反向传播。在正向计算过程中,输入信息通过多个隐藏层的加权处理从输入层处理到输出层。如果期望值与传递函数获得的输出值之间存在误差,则应通过原始连接路径将误差发回,并通过逐层调整权重来减少误差。重复这两个过程,直到输出满足要求。
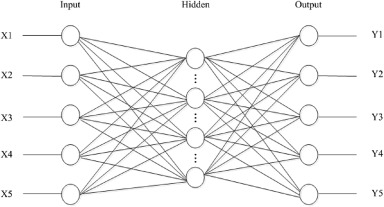 图 2.典型 NN 的示意图。
图 2.典型 NN 的示意图。
在本研究中,使用具有三层的典型NN结构,其中除了一个输入层和一个输出层之外只有一个隐藏层。隐藏层中的神经元数量由以下等式确定:
 其中
n
h
n_h
nh是隐藏层中的神经元数量,
n
p
n_p
np是输入层中的神经元数量,
n
o
n_o
no 是输出层中的神经元数量,
c
o
n
n
conn
conn是一个常数,范围从1到10。
其中
n
h
n_h
nh是隐藏层中的神经元数量,
n
p
n_p
np是输入层中的神经元数量,
n
o
n_o
no 是输出层中的神经元数量,
c
o
n
n
conn
conn是一个常数,范围从1到10。

4. 车辆重新定位建模

每一轮重新定位的目标是最大限度地减少车辆的总运输时间,并最大限度地减少用户因缺少自行车而等待的时间。我们使用运营商成本来表示车辆的运输时间,使用罚款成本来表示用户的等待时间。让
G
(
s
)
∗
G(s)*
G(s)∗ 表示遵循线性结构的时间间隔 s 的一个重新定位回合的最佳目标值:
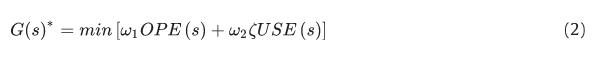
其中 OPE(s )是时间间隔 s 的操作员成本;USE(s)是用户方因车站自行车短缺而造成的罚款费用; 以及
w
1
w_1
w1和
w
2
w_2
w2分别是运营商成本和罚款成本的权重;
ζ
ζ
ζ是运营商成本相对于罚款成本的权重系数。
运营商成本包括两部分:固定成本和差旅成本(fixed cost and travel cost)。固定成本是指一辆重新定位车辆的成本,例如使用费和人力支出,等于单位成本乘以重新定位车辆的数量。旅行成本是根据车辆的旅行时间计算的。因此,操作员成本 (OPE) 按如下方式获得:
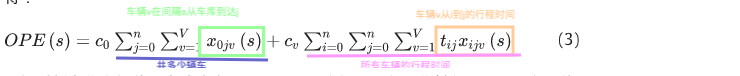
c 0 c_0 c0一辆重新定位车辆的固定成本 ; x i j v ( s ) x_{ijv}(s) xijv(s)是一个二进制变量,如果离开的重新定位车辆 v v v以时间间隔 $s4 直接从节点 i i i 驱动到节点 j j j,则等于 1,否则等于 0; c v c_v cv是每单位时间内平均重新定位车辆的旅行成本; t i j t_{ij} tij是从节点 i i i到节点 j j j 的行程时间。
罚款成本与车站的可用服务直接相关。如果不能按时搬迁自行车,用户不会等待,这将影响满意度和忠诚度。此外,共享单车站的位置会影响该站在该系统中的重要性。然后,系统中的惩罚成本(USE)可以通过以下方式衡量:

 有五类限制:(a) 车站和重新定位车辆的容量限制;(b) 车辆的容量限制;(c) 链路和车辆的流量养护限制;(d) 时间限制;以及(e)非消极约束。部分约束由Forma等人(2015)从静态重新定位模型扩展而来。所有约束都受以下函数的限制。
有五类限制:(a) 车站和重新定位车辆的容量限制;(b) 车辆的容量限制;(c) 链路和车辆的流量养护限制;(d) 时间限制;以及(e)非消极约束。部分约束由Forma等人(2015)从静态重新定位模型扩展而来。所有约束都受以下函数的限制。
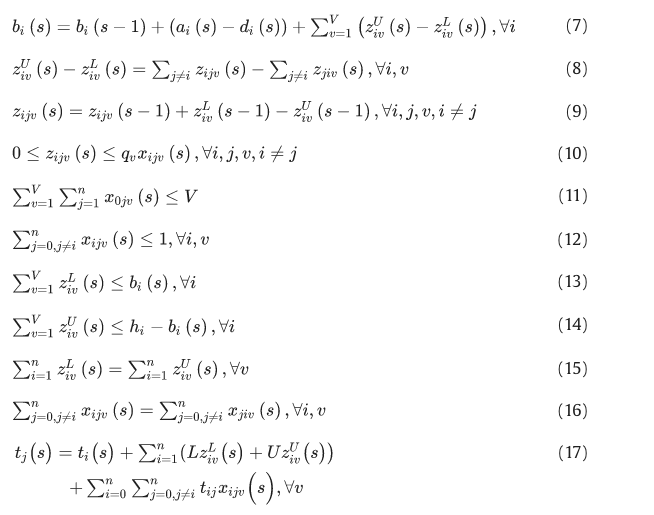

 等式(7)是共享单车站的库存平衡约束。等式(8)和等式(9)是车辆上自行车的保存。等式(10)是一辆重新定位车辆的容量限制。等式(11)限制重新定位的车辆总数,等式(12)确保每个站点最多由一辆车提供服务。等式。(13)、(14)限制所有车辆装卸自行车的数量。等式(15)是装卸自行车总数的守恒,等式(16)是连杆的流量守恒约束。等式(17)为到达时间计算,规定节点j的到达时间等于节点i的到达时间加上节点i的装卸服务时间和节点i与j之间的行程时间。方程 (18) 是一个二进制约束。等式。(19)、(20)分别是车辆重新定位和用户使用的自行车的非负性和完整性约束。等式。(21)、(22)是重新定位车辆上携带的自行车数量和节点处库存的非负性和完整性约束。
等式(7)是共享单车站的库存平衡约束。等式(8)和等式(9)是车辆上自行车的保存。等式(10)是一辆重新定位车辆的容量限制。等式(11)限制重新定位的车辆总数,等式(12)确保每个站点最多由一辆车提供服务。等式。(13)、(14)限制所有车辆装卸自行车的数量。等式(15)是装卸自行车总数的守恒,等式(16)是连杆的流量守恒约束。等式(17)为到达时间计算,规定节点j的到达时间等于节点i的到达时间加上节点i的装卸服务时间和节点i与j之间的行程时间。方程 (18) 是一个二进制约束。等式。(19)、(20)分别是车辆重新定位和用户使用的自行车的非负性和完整性约束。等式。(21)、(22)是重新定位车辆上携带的自行车数量和节点处库存的非负性和完整性约束。
5. 重新定位算法
车辆重新定位问题被证明是一种非确定性多项式时间困难( a type of non-deterministic polynomial-time hard)(NP-hard)问题,其中求解时间随着问题规模的增加而迅速增加。到目前为止,还没有有效的数学方法在实践中为这个问题提供准确的解决方案。本文中,能够加快找到满意解过程的元启发式技术被广泛应用于解决该NP难题的应用中,如遗传算法(GA)、蚁群优化、模拟退火(SA)、禁忌搜索(TS)和引导局部搜索。这些方法通过使用各种知识(如有机进化、人工智能等)在计算工作量和解决方案质量之间提供了很好的实际折衷方案。由于每种方法的局限性,混合算法在该领域的使用很普遍。本研究采用自适应遗传算法(AGA)和颗粒禁忌搜索(GTS)两种众所周知的元启发式方法的混合,为所提模型找到近似最优解。
详细的混合AGA-GTS算法由两部分组成:
(a)构建由AGA解决方案在第一个时间间隔估计的初始重新定位计划(the construction of the initial repositioning plan estimated by the AGA solution at the first time interval),以及
(b)根据实时使用模式使用GTS程序进行重新定位修订()he repositioning revision using GTS procedure according to the real-time usage pattern,如图3所示。对于具有一定数量的车辆仓库和自行车站的系统,使用 AGA 算法来找到近似良好的初始解。随着时间的推移,当新的需求被添加到系统中时(图3(c)左侧的新蓝色工作站),选择GTS来解决重新定位问题。混合算法结合了AGA在初始时间间隔的并行计算,为下一次重新定位设置正确的方向,并结合了GTS的快速本地搜索,以保证计算时间。
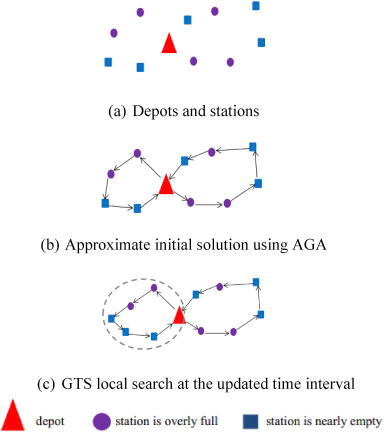 图 3.通过所提出的混合算法获得的解决方案的示例。
图 3.通过所提出的混合算法获得的解决方案的示例。
5.1. 前期准备
每个站点的类型和容量各不相同,并且某些站点的需求可能比其他站点大几倍,因此单个重新定位车辆可能无法满足该时间间隔内如此大的重新定位请求。因此,通过将一个工作站分成位于同一位置的多个虚拟工作站,可以为这些工作站添加虚拟节点。虚拟站应被视为与其他台站相同的新台站,但与原始台站共享位置除外。因此,重新定位请求被单独分配给这些虚拟站中的每一个。一个虚拟站代表一个负担得起的重新定位请求,通常设置为重新定位车辆容量的一倍或一半。
重新定位载体约束、非负性和完整性约束在AGA的染色体(个体)中用特定的遗传算子表示,以确保染色体中的每个解决方案都是可行的解决方案。通过引入具有较大值的惩罚参数来处理容量约束。如果染色体中的溶液超过容量限制,它将被分配比最佳值大一百倍的惩罚,以至于由于最小的适应性,它几乎不可能进入下一代。为了维持种群规模,一些不可行的解决方案也可能进入下一代。但经过多轮迭代,近似最优解将占据领先地位。
5.2. 初始解决方案
第一个重新定位解决方案是基于AGA计算的,其中染色体代表所有重新定位车辆的服务序列。AGA 算法的整体流程如图 4 所示。初始化参数后,我们首先根据整数编码规则对节点进行编码并随机生成初始种群,其次计算个体的适应度,第三次实现遗传算子的操作,然后迭代直到达到最大生成。AGA中的基本项目包括编码,初始群体,选择算子,交叉算子,突变算子,适应度函数以及交叉和突变的自适应概率。
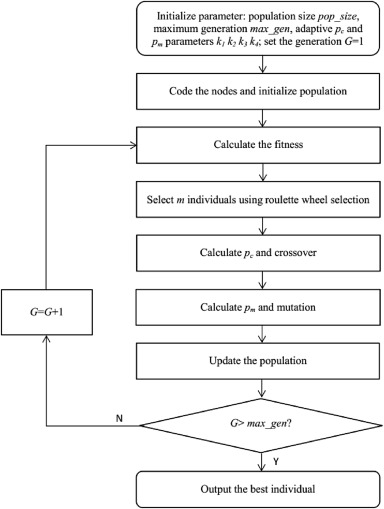 图 4.AGA 流程图
图 4.AGA 流程图
🐸首先,所有节点都按整数编码规则进行编码,其中站点编码为 0,站点(包括虚拟站点)按照其序列 {1, 2, …, n} 进行编码。
🐸其次,初始种群是随机生成的。初始种群的大小应根据实际问题定义,其中常见的大小是 20-100。确定初始种群大小后,随机生成初始种群。
🐸第三,选择算子是通过使用轮盘选择来确定初始群体中适应性更好的父解,其中选择概率是根据个体适应度与群体适应度的比率计算的。
🐸第四,交叉是从多个父解决方案生成子解决方案。它包括两个阶段:根据交叉的自适应概率匹配父解决方案,然后确定交叉点。
🐸第五,为了通过防止染色体群体彼此变得过于相似来避免局部最小值,将突变算子随机添加到一些解决方案中以改变其值。因此,有可能提高搜索速度。
适应度函数(Fitness function )用于计算每个人的适应度,这是搜索过程中的唯一标准,从而影响算法的整体性能。在BSS中的重新定位目标方面,由于目标是找到成本较低的解决方案,因此本研究中的适应度函数如下:
 与传统GA相比,AGA的主要优势在于采用基于每一代人群的适应度统计的交叉和突变概率,正如Srinivas和Patnaik(1994)首次建立的那样,他们发现交叉和突变的概率值应随着种群的最大适应度值和平均适应度值之间的差异而变化,以避免解决方案的重要性水平相同具有最高和最低适应度值。更新交叉和突变概率的自适应策略表示如下:
与传统GA相比,AGA的主要优势在于采用基于每一代人群的适应度统计的交叉和突变概率,正如Srinivas和Patnaik(1994)首次建立的那样,他们发现交叉和突变的概率值应随着种群的最大适应度值和平均适应度值之间的差异而变化,以避免解决方案的重要性水平相同具有最高和最低适应度值。更新交叉和突变概率的自适应策略表示如下:


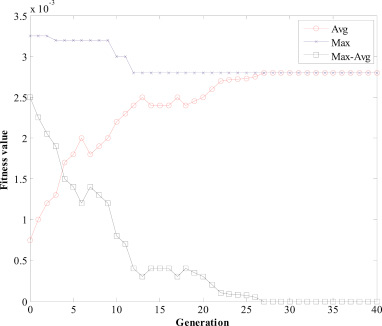
图 5.
f
m
a
x
−
f
a
v
g
f_{max} -f_{avg}
fmax−favg 随着算法收敛而减小。
5.3. 重新定位修订
由于共享单车使用时空变化较大,交通状况不确定(影响车辆行驶时间),初始重新定位方案无法满足系统的实时性要求。因此,需要动态修订重新定位计划,其中可变信息包括需求变化、重新定位车辆变化的数量和网络变化(例如系统容量变化)。
一些新加油站可能会在最初的重新定位计划建立后提交维修请求。这些请求可以作为重新定位修订过程中的初始解决方案插入到初始重新定位计划中。然后,根据修正算法(本研究中的GTS算法)的新结果给出更新的重新定位计划。如果初始车辆的容量无法满足更新的需求,BSS控制中心可以分配新的重新定位车辆来维修系统。有些请求可能会在车辆到达之前被取消,这些取消的请求可以直接从计划中删除,并相应地重新调整计划,除非重新定位的车辆已经在前往该车站的路上。原始请求也可以更改,包括更改自行车数量和/或所需的到达时间窗口。如果修改后的要求可能超过车辆的容量或降低用户的总体满意度,则不会将这些要求添加到当前的重新定位计划中以进行修订。
TS算法以其通过使用最近解决方案的短期记忆来逃避局部最优的智能能力而闻名。TS算法已被许多研究人员开发和改进,而优秀的结果表明TS算法在解决车辆路径问题方面具有巨大潜力。为了根据BSS中的实时请求修改重新定位计划,本研究应用了一种改进的TS算法GTS算法,该算法考虑了严格限制的邻域以加快局部搜索速度。我们使用 AGA 的初始重新定位计划作为初始解决方案,然后创建粒度邻域以找到可接受的最佳解决方案。在此阶段,从Escobar等人(2014)采用的路线内移动(在同一路线中执行)和路线间移动(在分配给同一仓库或不同港口的两条路线之间执行)被视为如下所述,并建立了禁忌列表。
每次在当前解决方案的粒度邻域中搜索改进移动,并从随机选择的一些有希望的移动中获得最佳移动(最小成本),用于获得新的当前解决方案。方程(2)用作任何解决方案的目标函数
构建邻域是为了识别可以从当前解决方案中研究的相邻解决方案。GTS 算法使用受限邻域(称为粒度邻域(granular neighbourhoods)),通过删除大量没有希望的移动并将搜索限制为仅在最有希望的移动的一小部分内。
有希望的邻居是从稀疏图(sparse graph)中获得的,该稀疏图包括成本不大于粒度阈值 ϑ = ε z ˉ \vartheta=\varepsilon \bar{z} ϑ=εzˉ的所有路由 (其中 ε ε ε是稀疏因子, z ˉ \bar{z} zˉ是路由的平均成本),属于最佳可行解决方案的路由,以及距离因子不大于最大持续时间的 路径(i,j) 入射到depot(Escobar等人, 2014).通过这种方式,与完全搜索相比,细粒度邻域可确保更少的计算时间。那些没有希望的举动将被记录在禁忌列表中,这是短期的禁止动作。禁忌列表的长度通常设置为常量值,每次将新路由添加到列表底部时,列表中最早的路由都会从顶部删除。
抽吸标准用于允许重新选择禁忌列表中的移动以避免被覆盖。通常,基于客观价值的愿望标准用于将移动排除在禁忌清单之外。当某个移动具有比其他先前解决方案足够吸引的目标值时,将在下一次迭代中访问此移动。
GTS的详细程序如图6所示。
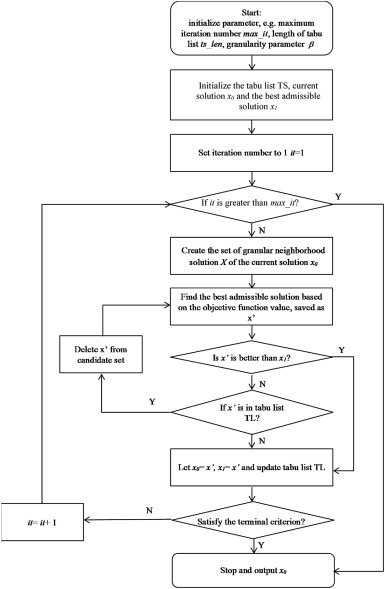 图 6.GTS的流程图。
图 6.GTS的流程图。
5.4. 算法流程
详细过程如下所述:
Step 1: Initialize parameters:
种群大小pop_size;
最大发电max_gen;
自适应
p
c
p_c
pc 和
p
m
p_m
pm, 参数
k
1
,
k
2
,
k
3
,
k
4
k_1,k_2,k_3,k_4
k1,k2,k3,k4 ;
最大迭代次数max_it;
禁忌清单ts_len;
粒度阈值参数ε;
步骤2:初步准备并删除已处理的请求并设置时间s = 1;
步骤3:使用AGA算法生成第一个重新定位计划;
a. Set generation G = 1;
b. Generate the initial population by coding method; 通过编码方法生成初始种群;
c. Decode and calculate the fitness value; 解码并计算适应度值;
d. Implement genetic operator operations;实施基因操作员操作;
i). Select and reproduce according to the fitness value;根据适应度值进行选择和繁殖
ii). Calculate the adaptive probability p c p_c pc and crossover; 计算自适应概率 p c p_c pc 和交叉
iii). Calculate the adaptive probability p m p_m pm and mutation.计算自适应概率 p m p_m pm 和突变
e. Update population and check.更新人口并检查:如果 G > max_gen,请转到步骤 3.f;否则 G = G+1,请转到步骤 3.c;
f. Output the best individual (repositioning plan) 输出最佳个体(重新定位计划)
步骤4:进行重新定位计划s = s并记录行程时间;
步骤5:系统时间是否达到下一个时间间隔?如果是,s = s+1,请转到步骤 6;否则转到步骤 4;
第 6 步:如果 s < S,则执行第 7 步;否则转到步骤 8;
第 7 步:需求是否有任何更新?如果需求已更改,请执行步骤 7。一个;否则转到步骤 4;
a. Code the new request into the repositioning plan;将新请求编码到重新定位计划中;
b. 根据解码的个体随机生成每个站点节点子路由的初始解。初始化禁忌列表 TL、当前解决方案
x
0
x_0
x0 和最佳允许解决方案
x
1
x _1
x1
c. Set iteration it = 1;
d. GTS local searching:
i. 如果it > it_max,请转到步骤 7.e;否则执行步骤 7.d.ii
ii. 基于 2-opt 邻域函数的当前解 x 0 x_0 x0 生成粒度邻域解决方案
iii. 根据客观值确定最佳可接受的解决方案x’
iv. x ′ x' x′ 比 x 1 x_1 x1 好吗,如果是,请执行步骤 7.d.vii。;否则,请转到步骤 7.d.v;
v. x ′ x' x′ 在 TL 中吗?如果是,请执行步骤 7。d.vi;否则,请转到步骤 7.d.vii;
vi. 从粒度邻域解决方案集中删除 x ′ x' x′,然后转到 7.D.III;
vii. 设 x 0 = x ′ , x 1 = x ′ x_0 = x', x_1= x' x0=x′,x1=x′ 并更新禁忌列表 TL;
viii. x 0 x_0 x0 符合愿望吗?如果是,请转到步骤 7.e;否则 it = it +1 并转到步骤 7.d. i;
e) 输出最佳个体(重新定位计划);转到步骤 4;
步骤8:在每个时间间隔停止并输出所有重新定位计划。
5.5. 算法的效率
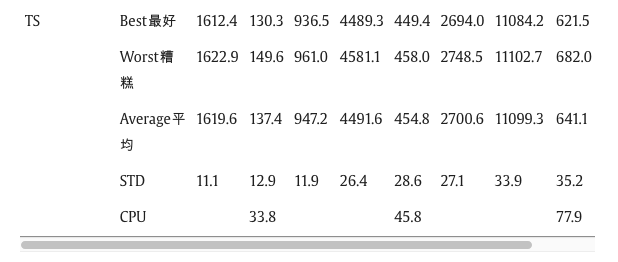
为了评估AGA-GTS的性能,在Matlab中在ThinkPad T460s笔记本电脑上测试了一系列实验,该笔记本电脑具有2.60 GHz CPU,具有GA和TS算法。据作者所知,对于动态重新定位问题,目前还不存在这样一组基准场景。目前的所有研究都使用自己的随机数据。为了避免数据源和网络结构的影响,我们遵循Contardo等人(2012)的想法随机生成30个实例。平面中有 25、50 和 100 个站点,x 和 y 坐标在区间 [0,60] 内。我们采用了Contardo等人(2012)的一个案例,即总研究时间为2小时,间隔为24个。车站随机分布在飞机上,车站交替是取货点或交货点。对于每个组合,将生成 10 个实例。总共有 30 个实例。更多细节可以在Contardo et al. (2012) 中找到。每个时间间隔的所有实例的需求矩阵都是相同的。其余参数设置为: V = 5 , q v = 18 , L = U = 0.5 , ζ = 2 , β i = 0.037 , w 1 = w 2 = 0.5 V=5, q_v=18, L=U=0.5,\zeta=2,\beta_i=0.037,w_1=w_2=0.5 V=5,qv=18,L=U=0.5,ζ=2,βi=0.037,w1=w2=0.5,pop_size=40,max_gen=200, k 1 = k 2 = 0.3 , k 3 = k 4 = 0.1 k_1=k_2=0.3,k_3=k_4=0.1 k1=k2=0.3,k3=k4=0.1,max_it=500,ts_len=7, ϑ = 1.5 \vartheta=1.5 ϑ=1.5.由于这些算法是随机算法,并且通过多个实现将获得不同的结果,因此每个实例应求解 10 次独立运行,其中记录最佳求解成本(最佳)、最差求解成本(最差)和平均求解成本(平均)以及所有相关实例之间的平均标准偏差 (STD) 和相关实例中一次运行的平均 CPU 时间 (CPU)(以秒为单位)。结果汇总如表2所示。 从表2中可以发现,所提出的AGA-GTS在不同大小的实例中表现良好。对于每种尺寸,AGA-GTS 算法在 CPU 时间方面主要主导其他算法。对于所有测试实例,最佳 AGA-GTS 解决方案成本在其他三种算法中平均偏差 9%。这意味着所提出的AGA-GTS可以显着改善这些启发式解决方案的解决方案,并且我们的算法方法具有很强的竞争力。
6. 仿真实现
6.1. 学习网络
以寿光市BSS为例,对所提方法的有效性进行了检验。该 BSS 包含 1 个仓库、91 个站点和 10 辆重新定位车辆。每辆重新定位车辆的固定成本为 c 0 = 10 c_0 = 10 c0=10,两个节点之间的可变成本为 c v = 3.5 c_v= 3.5 cv=3.5,这是 Qin’s 的研究(2013 年)基于实际操作设置采用的。最大用户惩罚为 c u = 100 c_u = 100 cu=100,避免不可接受的等待的大值设置为 M = 1000 M = 1000 M=1000。 从Qin的研究(2013)中抽象出每个节点之间的距离和行驶时间,其中假设行驶时间是恒定的,而不考虑实时交通状况的影响。因此,可以计算两个节点之间的算子成本。 学习时间为上午 7:20 至上午 9:20,等于 分钟。两站间平均行程时间为5 min,一站平均换位时间为3 min,则时间间隔设置为 Δ = 5 + 3 = 8 \Delta=5+3=8 Δ=5+3=8分钟,时间间隔数为 S = 120 / 8 = 15 S=120/8=15 S=120/8=15 。其他参数根据寿光网络设置如下: q v = 25 , L = U = 0.5 , ζ = 2 q_v = 25,L = U = 0.5,ζ = 2 qv=25,L=U=0.5,ζ=2 , β i = 0.037 , w 1 = w 2 = 0.5 \beta_i=0.037,w_1=w_2=0.5 βi=0.037,w1=w2=0.5 。一个负担得起的请求被设置为重新定位车辆 q v q_v qv容量的一倍。
BSS 控制中心预测初始计划未来 16 分钟(2 个时间间隔)内即将到来的需求,并预测下一个计划未来 8 分钟(1 个时间间隔)的需求。需求矩阵将根据实时使用情况在每个时间间隔更新。需求预测模型应为动态车辆重新定位模型提供输入。因此,需求预测也需要定期更新,其中更新时间间隔与车辆重新定位模型中使用的间隔相同。BSS控制中心将使用GTS算法修改重新定位计划。如果来自站点的新要求不能满足模型约束,控制中心可以增加新的重新定位车辆。
6.2. 需求预测结果
例如,我们预测了每个车站借用的自行车数量。包含 50 天数据点的主数据集分为三个子集,用于训练、验证和测试。每个进程使用的数据设置为 30 天 (60%)、5 天 (10%) 和 15 天 (30%)。因此,使用 30 天 ∗ 24 小时 / 天 ∗ 7.5 时间间隔 / 小时 = 5400 30 天 * 24 小时/天* 7.5 时间间隔/小时 = 5400 30天∗24小时/天∗7.5时间间隔/小时=5400 个数据点组成的训练子集来设置网络。使用 5 天 ∗ 24 小时 / 天 ∗ 7.5 时间间隔 / 小时 = 900 5 天*24 小时/天* 7.5 时间间隔/小时 = 900 5天∗24小时/天∗7.5时间间隔/小时=900 个数据点组成的验证子集来防止网络在训练过程中学习特质。使用 15 天 ∗ 24 小时 / 天 ∗ 7.5 时间间隔 / 小时 = 2700 15 天 *24 小时/天* 7.5 时间间隔/小时 = 2700 15天∗24小时/天∗7.5时间间隔/小时=2700 个数据点组成的测试子集来评估训练网络的性能。整个过程由Matlab和Neural Network Toolbox实现。输入数据被缩放到范围 [0,1]。采用Levenberg-Marquardt算法的标度共轭梯度训练方法对网络进行训练。使用批量训练方法,其中权重和偏差仅在所有输入和目标呈现一次后才更新。该模型被设置为最多训练 10,000 个周期。在每个周期结束时,在验证集上测试训练后的模型,并通过均方误差计算预测误差。如果预测误差小于上一个周期的预测误差,则模型将被保存并继续训练过程。如果验证过程中的预测误差增加指定阈值,则训练过程设置为停止。经过6202轮网络训练后,3个数据集的平均均方误差(MSE)小于0.03(0.0327、0.0023、0.0296)。然后,可以使用经过训练的网络进行预测。
《共轭梯度算法》
共轭梯度法可以被认为是介于梯度下降和牛顿法之间的方法。它能加快梯度下降法典型的慢收敛,同时避免了牛顿法对Hessian矩阵的评估、存储和反转所需的信息。
在共轭梯度训练算法中,搜索沿着共轭方向执行,通常能比梯度下降方向产生更快的收敛。这些训练方向与Hessian矩阵相关。
用d表示训练方向向量。然后,从初始参数向量w0和初始训练方向向量d0 = -g0开始,共轭梯度法构造训练方向的序列可表示为:
di+1 = gi+1 + di·γi, i=0,1,…
这里γ称为共轭参数,有不同的计算方法。其中两种最常用的方法是Fletcher–Reeves和Polak–Ribière。对于所有共轭梯度算法,训练方向周期性地重置为梯度的负值。
然后,参数根据以下等式改进,训练速率η通常通过线性最小化得到:
wi+1 = wi + di·ηi, i=0,1,…
下图描述了使用共轭梯度法的训练过程。如图所示,参数的改进步骤是先计算共轭梯度训练方向,然后计算该方向上的合适训练速率。
考虑时间间隔持续时间为8时,实际需求水平、各站点平均预测误差和平均百分比误差分布如图7所示。图 7 中的 X 轴和 Y 轴表示站的位置,这与图 9 和图 10 相同。根据右侧的指数,站的不同深浅的黑色代表需求水平、平均绝对预测误差和平均百分比误差。颜色表示数字的值。节点越暗表示数字值越大。结果表明:单站最大预测误差(借用计数与收益计数之差)小于5,单站最大平均百分比误差小于10%。结果表明,低流量需求站点的平均百分比误差普遍高于高流量需求站点,而后者站点的平均预测误差较小。总体预测结果能够满足要求。
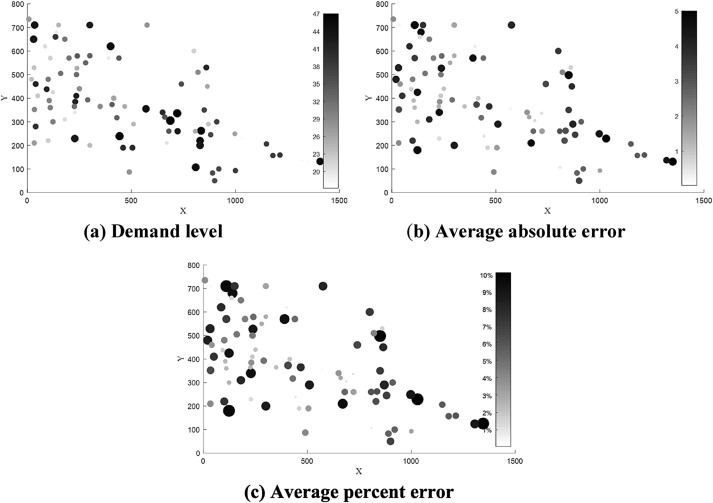
图 7.实际需求水平,分布各站点的平均预测误差和平均百分比误差。
图 8 表明,如果将时间间隔持续时间设置为 4 min,则两个时间间隔之间的使用差异很小,尤其是在非高峰期。因此,图 9 显示了 40 号站借来自行车在典型一天中借出的自行车的预测值和实际值,时间间隔持续时间为 8 分钟和 16 分钟,以显示模型性能。可以看出,该预测方法在高峰期和非高峰期均表现良好,结果可作为重新定位模型的输入。
 图 8.(a) 在典型的一天中,在40号站以8分钟时间间隔的借用自行车的预测值和实际值。(b) 在典型的一天中,在40号站以16分钟时间间隔的借用自行车的预测值和实际值。
图 8.(a) 在典型的一天中,在40号站以8分钟时间间隔的借用自行车的预测值和实际值。(b) 在典型的一天中,在40号站以16分钟时间间隔的借用自行车的预测值和实际值。

.初始重新定位路线。
 图 10.在 7:28 重新定位路线。
图 10.在 7:28 重新定位路线。
6.3. 重新定位仿真结果
AGA 算法中使用的参数设置为:种群大小pop_size=50,种群数max_gen=300,自适应交叉概率和突变率 参数为
k
1
=
k
2
=
0.3
,
k
3
=
k
4
=
0.1
k_1=k_2=0.3,k_3=k_4=0.1
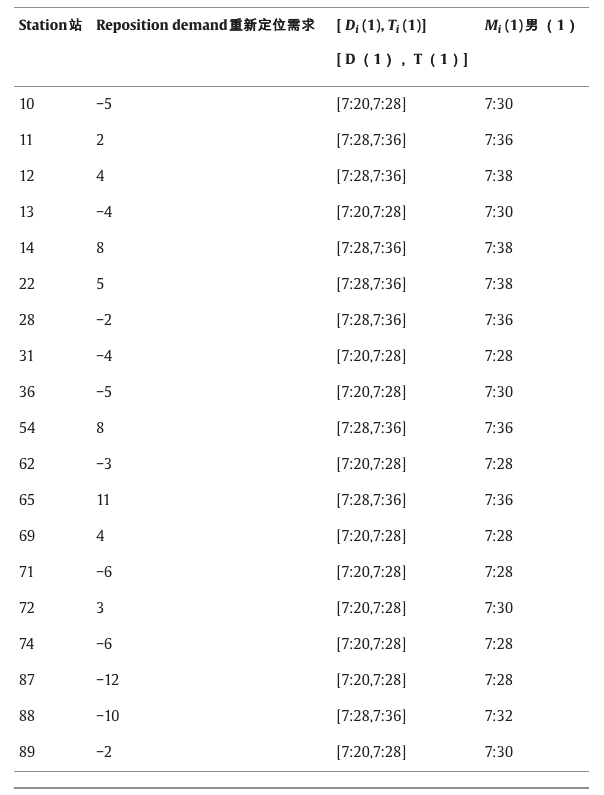
k1=k2=0.3,k3=k4=0.1。如表 3 所示,BSS 控件在开始时间间隔内收到了 19 个重新定位请求,其中负值表示卸载的自行车数量,正值表示装载的自行车数量。使用MATLAB运行AGA算法后,得到如表4所示的初始解,其中需要6辆重新定位车辆来重新定位系统中的自行车。1 号车将从车厂出发,按照 71-72-28-22 的顺序为共享单车站提供服务,然后返回车厂。重新定位车辆的路线如图 9 所示。在这种情况下,运营商总成本为 140.9,总惩罚成本为 0。
表 3.初始重新定位请求
 .初步重新定位计划。
.初步重新定位计划。

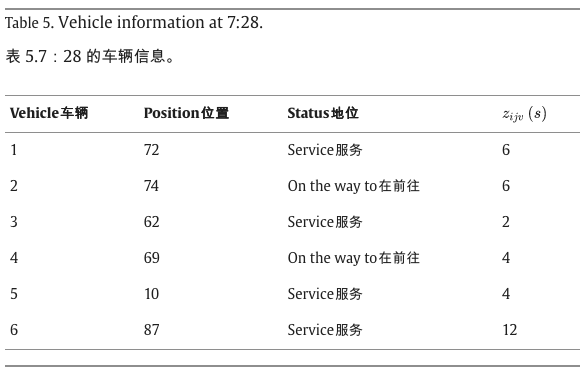
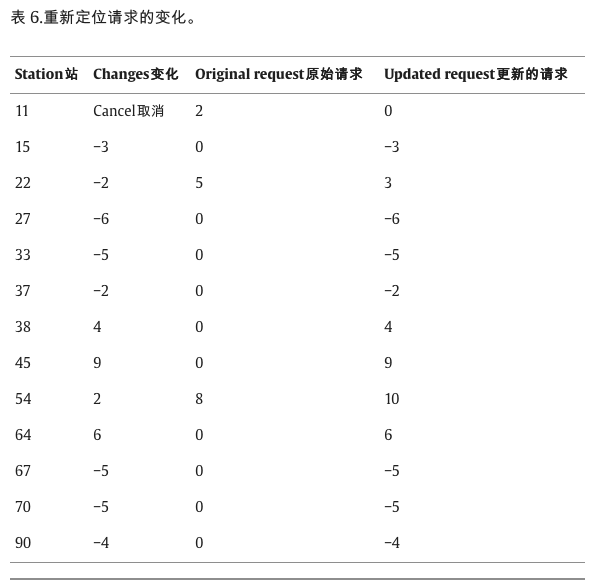
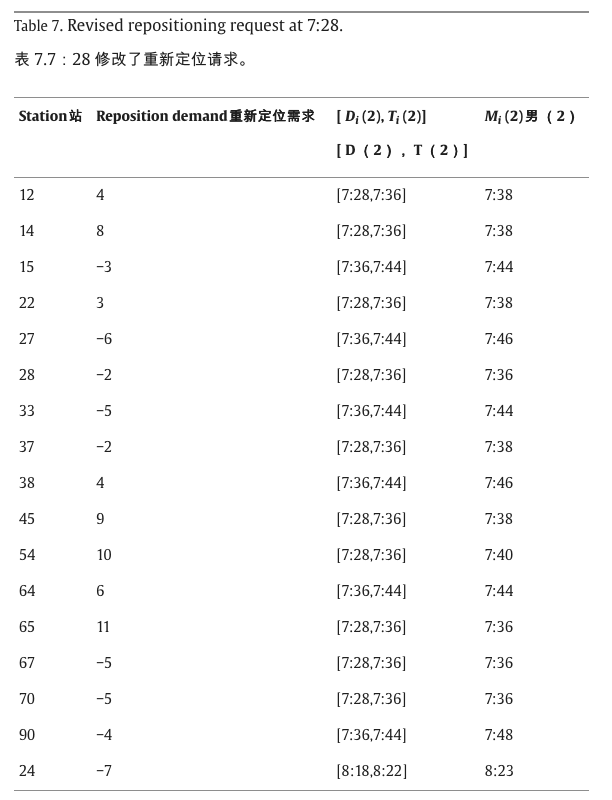
当时间到达7:28,即第一个信息更新点时,重新定位车辆信息如表5所示,其中车辆2和4正在前往下一站的途中,车辆1、3、5和6在车站停靠进行重新定位服务。实时需求发生了变化,如表6所示,此时间间隔的重新定位请求在表7中更新。基于以上信息,GTA在表8中得到了修订后的重新定位计划,其中GTS中的参数列举如下:最大迭代次数max_it=270;禁忌列表的长度 ts_len = 5;粒度阈值参数
ϑ
=
1.5
\vartheta=1.5
ϑ=1.5 。图 10 显示了 7:28 所有车辆的重新定位路线。
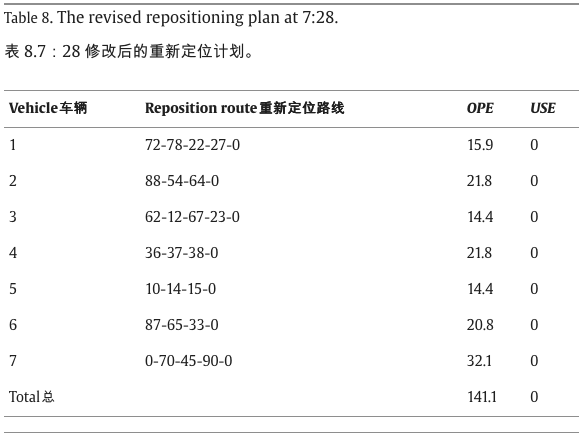
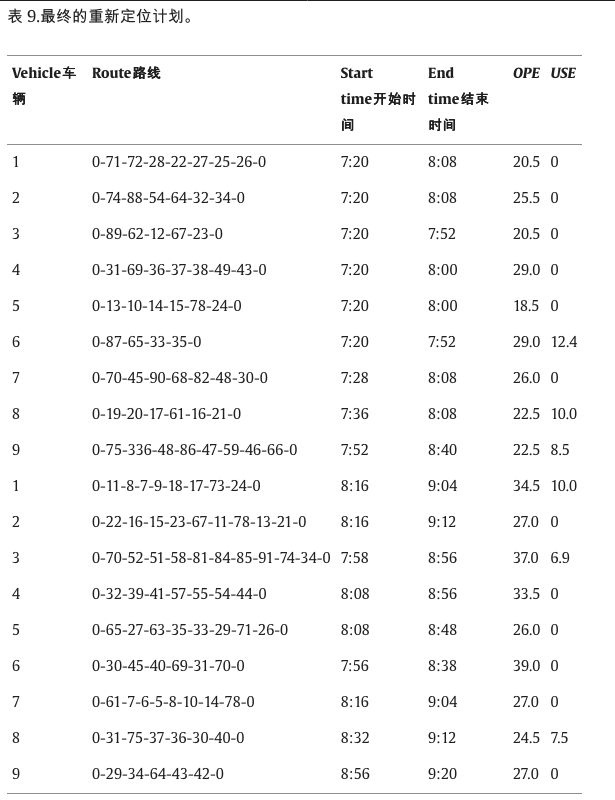
按照此过程,表 9 列出了每个时间间隔内的最终重新定位计划。表9显示,研究期间使用了9辆车,每辆车进行了两次重新定位任务。程序在 MatlabR 2014b 中运行,在 Windows 7 Professional 和 4 GB 内存下配备 Intel Core CPU (2.50 GHz) 的联想笔记本电脑上。以下计算中使用的时间单位为秒,而成本单位为人民币。仿真完成后,操作员总成本为 426.9,总惩罚成本为 55.3。
6.4. 敏感度分析
本节评估不同参数设置对性能的影响,包括:(1)需求预测中的隐藏层数;(2)需求预测中的输入数量;(3)车辆重新定位的时间间隔数。
表10显示了40号站需求预测中不同隐藏层数下的平均绝对误差和平均百分比误差。结果表明,随着隐藏层数的增加,需求预测的准确率先升高后降低。当隐藏层数为4时,需求预测精度达到最高水平,平均绝对误差为1,平均百分比误差为1.9。但是,高预测精度牺牲了 CPU 时间。当隐藏层数为4时,预测时间需要60s以上,会影响重定位算法的计算。通过一个隐藏层,该模型可以达到94.8%的准确率,足以支持自行车的重新定位。因此,在所提出的模型中使用一个隐藏层是合理的。
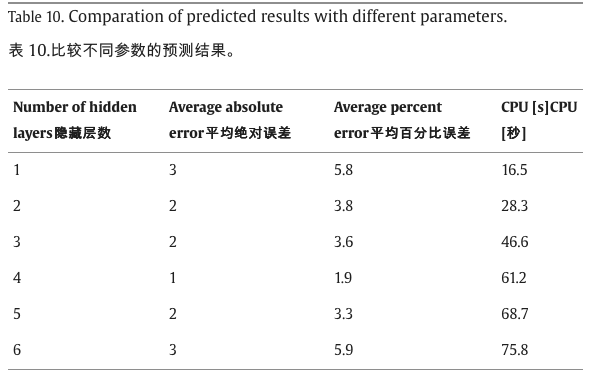 表 11 显示了站点 40 需求预测中不同输入数量下的平均绝对误差和平均百分比误差。它可能会发现,更多的神经元将导致更好的预测准确性,但需要更多的运行时间。该模型具有1个隐藏层和4个神经元,在预测精度高、计算时间短等方面取得了最佳性能。
表 11 显示了站点 40 需求预测中不同输入数量下的平均绝对误差和平均百分比误差。它可能会发现,更多的神经元将导致更好的预测准确性,但需要更多的运行时间。该模型具有1个隐藏层和4个神经元,在预测精度高、计算时间短等方面取得了最佳性能。
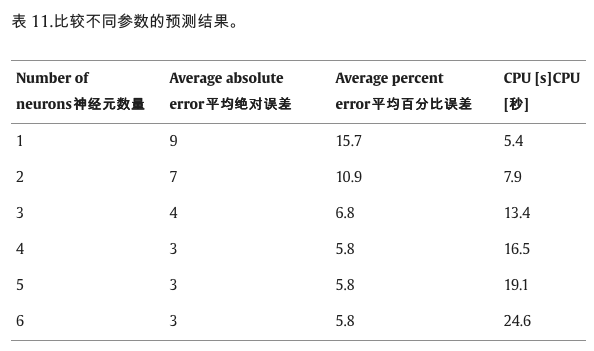 表 12 比较了车辆重新定位中不同时间间隔数的结果。当S=1时,重新定位计划实质上等同于静态计划,是目前寿光BSS中实际的操作方法。Qin (2013) 验证了静态重定位结果。通过应用包含静态情况的动态模型进行比较,其中时间间隔数分别设置为
S
=
1
,
5
,
10
,
15
S=1,5,10,15
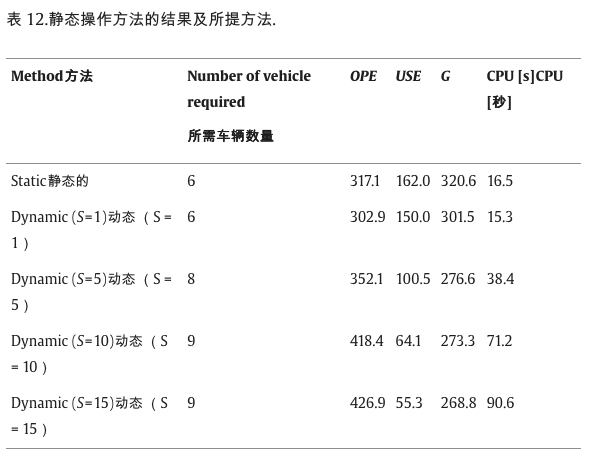
S=1,5,10,15 。静态计划的结果被用于首钢的BSS实际运营,并得到了首钢市政府的支持。因此,在此比较中,此静态模型用作静态验证模型。动态 (S = 1) 是我们算法的结果。单个时间间隔内的动态重新定位需求在时间间隔开始时累积。从表10可以看出,所提方法在S = 1时的结果与静态验证模型的结果一致;随着时间间隔的增加,动态重新定位计划在惩罚成本方面远优于静态模型,其中操作员成本增加了34.6%,惩罚成本降低了65.9%。因此,所提方法能够完美地模拟寿光BBS的真实网络。虽然重新定位计划可以通过静态方法建模,但考虑到惩罚成本的专用动态方法显然更胜一筹。同时,结果还反映出时间间隔集的数量越多,需要的车辆就越多,实现的总成本就越低。较长的时间间隔将影响及时响应实时需求变化的能力,因此某些请求无法得到服务。 时间间隔持续时间过短会导致运营成本增加,但不会增加惩罚成本。因此,有必要将时间间隔持续时间设置在合理的范围内。该环境可在未来的研究中进一步研究。
表 12 比较了车辆重新定位中不同时间间隔数的结果。当S=1时,重新定位计划实质上等同于静态计划,是目前寿光BSS中实际的操作方法。Qin (2013) 验证了静态重定位结果。通过应用包含静态情况的动态模型进行比较,其中时间间隔数分别设置为
S
=
1
,
5
,
10
,
15
S=1,5,10,15
S=1,5,10,15 。静态计划的结果被用于首钢的BSS实际运营,并得到了首钢市政府的支持。因此,在此比较中,此静态模型用作静态验证模型。动态 (S = 1) 是我们算法的结果。单个时间间隔内的动态重新定位需求在时间间隔开始时累积。从表10可以看出,所提方法在S = 1时的结果与静态验证模型的结果一致;随着时间间隔的增加,动态重新定位计划在惩罚成本方面远优于静态模型,其中操作员成本增加了34.6%,惩罚成本降低了65.9%。因此,所提方法能够完美地模拟寿光BBS的真实网络。虽然重新定位计划可以通过静态方法建模,但考虑到惩罚成本的专用动态方法显然更胜一筹。同时,结果还反映出时间间隔集的数量越多,需要的车辆就越多,实现的总成本就越低。较长的时间间隔将影响及时响应实时需求变化的能力,因此某些请求无法得到服务。 时间间隔持续时间过短会导致运营成本增加,但不会增加惩罚成本。因此,有必要将时间间隔持续时间设置在合理的范围内。该环境可在未来的研究中进一步研究。
7. 结论
共享单车是短途出行的一种方便灵活的替代模式,但自行车/码头的需求分布不平衡一直是几乎所有BSS的关键问题,尤其是在高峰时段。该文提出一种固定时间间隔的BSS动态重定位模型,利用神经网络(NN)方法预测共享单车使用情况。目标是最大限度地降低运营商成本,同时减少用户(客户)的损失。采用自适应遗传算法(AGA)和粒度禁忌搜索(GTS)两种著名的元启发式方法的混合算法对重新定位计划进行建模。与GA、TS和TA算法相比,所提动态算法在计算时间方面表现良好。
该方法和实验存在一些局限性:首先,没有考虑外部影响(例如天气)对需求的影响。其次,仅提前一次时间间隔的预测限制了提前几个时间间隔的重新定位计划。最终的重新定位计划可能不是最佳解决方案。第三,每辆自行车的上传和装载时间、出行成本等基本参数在所有场景中都设置为固定数字,这与实际情况变化无关。第四,该模型仅限于只有一个驱逐出境的情况。未来的研究将努力克服这些局限性,并在考虑实时交通状况的情况下,通过车辆路线选择来扩展这个问题。