MMdetection框架速成系列 第02部分
- 1 MMDetection是什么
- 1.1 模型分类
- 2. 整体算法流程
- 3 detection训练核心组件
- 3.1 Backbone
- 3.2 Neck
- 3.3 Head
- 3.4 Enhance
- 3.5 BBox Assigner
- 3.9 BBox Sampler
- 3.10 BBox Encoder
- 3.11 Loss
- 3.12 Training tricks
- 4 detection测试核心组件
- 4.1 BBox Decoder
- 4.2 BBox PostProcess
- 4.3 Testing tricks
- 4.4 训练测试算法流程
- 5 训练部分与测试部分的两个核心算法
- 5.1 训练部分 bbox_head.forward_train
- 5.2 测试部分 bbox_head.get_bboxes
- 6. 算法搭建流程
- 6.1 准备数据集
- 3.2 编写Config文件
- 6.3 训练网络
- 7.总结
本系列解读主要分享 MMDetection 中已经复现的主流目标检测模型。
众所周知,目标检测算法比较复杂,细节比较多,难以复现,而我们推出的 MMDetection 开源框架则希望解决上述问题。目前 MMdetection 已经复现了大部分主流和前沿模型,例如 Faster R-CNN 系列、Mask R-CNN 系列、YOLO 系列和比较新的 DETR 等等,模型库非常丰富,star 接近 13k,在学术研究和工业落地中应用非常广泛。
任何一个目标检测算法都可以分成 n 个核心组件,组件和组件之间是隔离的,方便复用和设计。
当面对一个新算法时候我们可以先分析其主要是改进哪几个核心组件,然后就可以高效的掌握该算法。
另外还有一些重要的模块没有分析,特别是 dataset、dataloader 和分布式训练相关的检测代码。
1 MMDetection是什么
MMDetection是OpenMMLab家族中的一员,主要负责2D目标检测领域(比如MMDetection3D则负责3D目标检测)。首先我们需要知道为什么会出现MMDetection这个框架。当前目标检测算法众多,方法复杂,细节较多,个人复现起来难度很大,而且由于缺少共享平台和统一规范,就算有人成功实现了某一个算法,也很难被其他人复用。
该模型使用统一的代码规范复现了当前大部分主流和前沿的模型,比如Faster R-CNN系列、YOLO系列,以及较新的DETR等(如下图所示),并提供了预训练模型。其他人只需要遵循这个规范,就能直接“白嫖”,不需要自己再重新实现一遍,而这个规范就MMDetection。
在丰富模型的基础上,MMDetection还支持自定义的扩展,可以在已有模型上进行修改,也可以自己从头搭建一个全新的模型,基本可以满足学术研究和工业落地的需求。
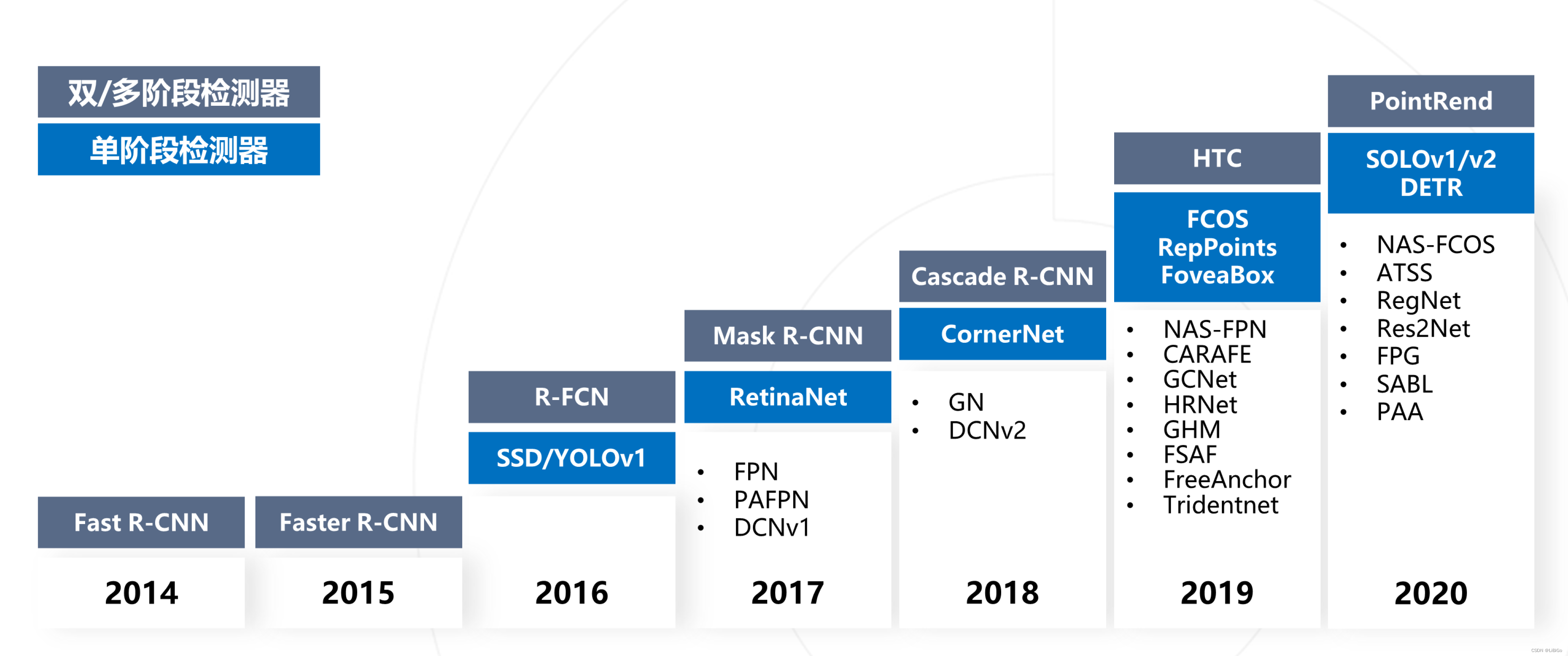
1.1 模型分类
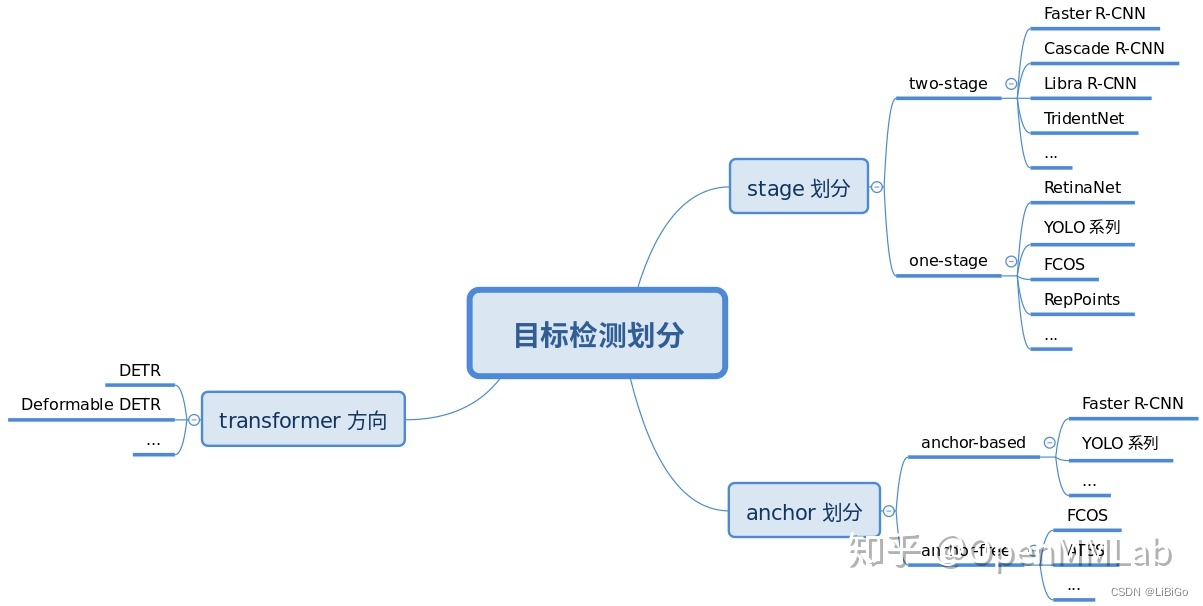
注意上面仅仅写了几个典型算法而已,简单来说目标检测算法可以按照 3 个维度划分:
- 按照 stage 个数划分,常规是 one-stage 和 two-stage,但是实际上界限不是特别清晰,例如带 refine 阶段的算法 RepPoints,实际上可以认为是1.5 stage 算法,而 Cascade R-CNN 可以认为是多阶段算法,为了简单,上面图示没有划分如此细致
- 按照是否需要预定义 anchor 划分,常规是 anchor-based 和 anchor-free,当然也有些算法是两者混合的
- 按照是否采用了 transformer 结构划分,目前基于 transformer 结构的目标检测算法发展迅速,也引起了极大的关注,所以这里特意增加了这个类别的划分
不管哪种划分方式,其实都可以分成若干固定模块,然后通过模块堆叠来构建整个检测算法体系。
2. 整体算法流程
所有的目标检测算法都可以按照训练和测试流程抽象成若干个模块,对于初学者来说只要理解各个模块的输入输出以及实现的功能即可。这个流程也对应框架的代码构建流程,所以理解这副图很重要。

上述流程对应 MMDetection 代码构建流程,理解每个组件的作用不仅仅对阅读算法源码有帮助,而且还能够快速理解新提出算法对应的改进部分。下面对每个模块进行详细解读。
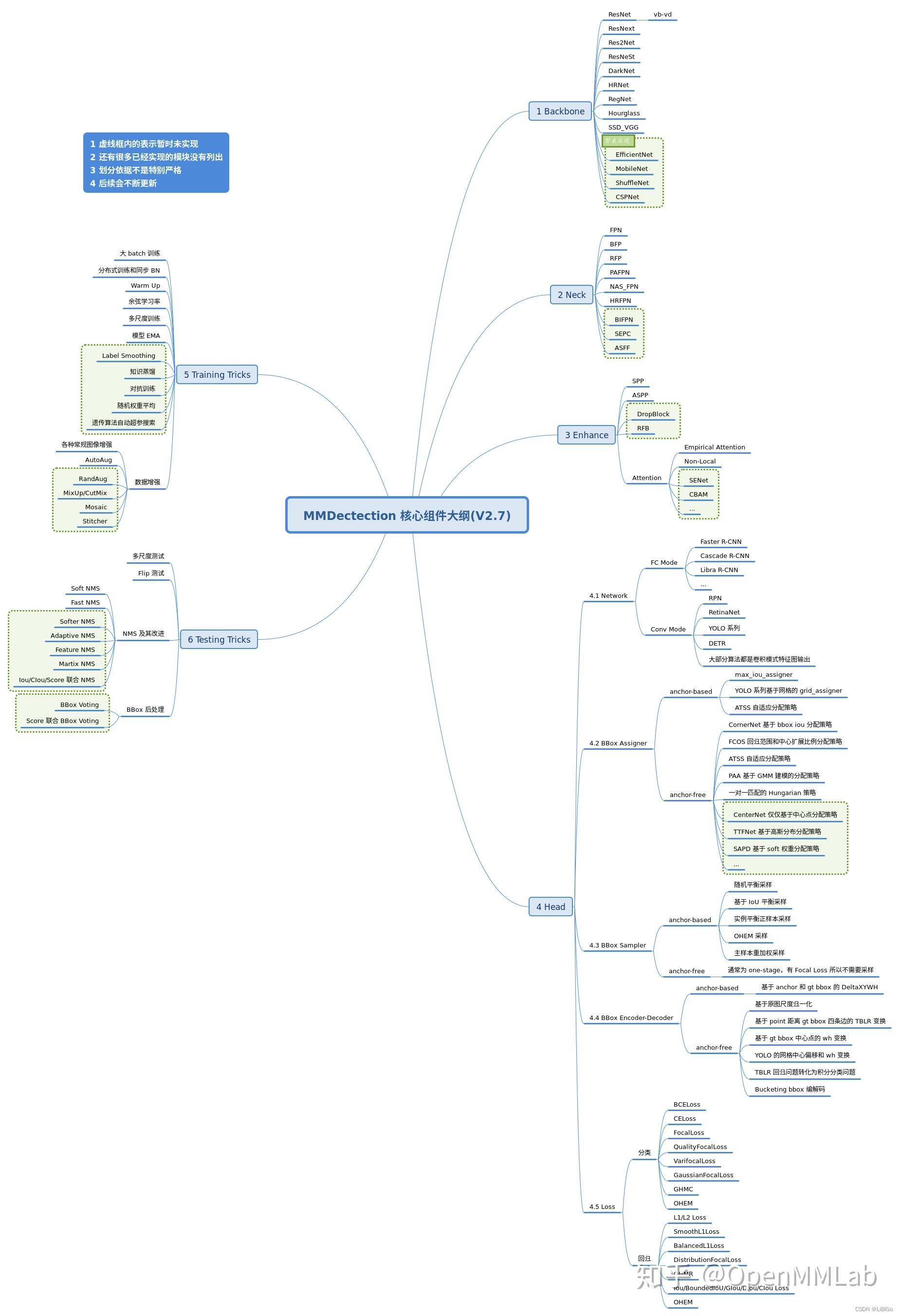
3 detection训练核心组件
训练部分一般包括 9 个核心组件,总体流程是:
①任何一个 batch 的图片先输入到 backbone 中进行特征提取,典型的骨干网络是 ResNet
②输出的单尺度或者多尺度特征图输入到 neck 模块中进行特征融合或者增强,典型的 neck 是 FPN
③上述多尺度特征最终输入到 head 部分,一般都会包括分类和回归分支输出
④在整个网络构建阶段都可以引入一些即插即用增强算子来增加提取提取能力,典型的例如 SPP、DCN 等等
⑤目标检测 head 输出一般是特征图,对于分类任务存在严重的正负样本不平衡,可以通过正负样本属性分配和采样控制
⑥为了方便收敛和平衡多分支,一般都会对 GT-bbox 进行编码
⑦最后一步是计算分类和回归 loss,进行训练
⑧在训练过程中也包括非常多的 trick,例如优化器选择等,参数调节也非常关键
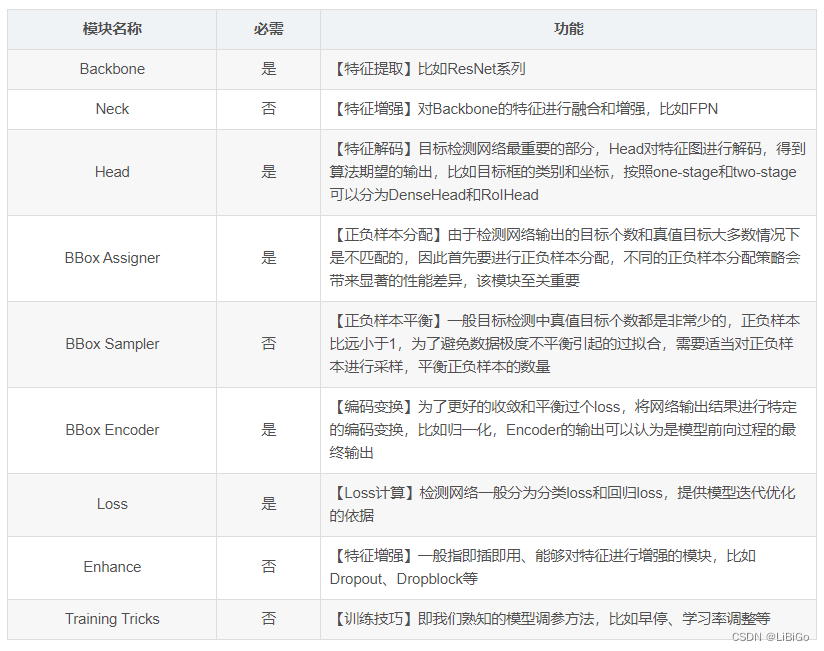
注意上述 9 个组件不是每个算法都需要的,下面详细分析。
3.1 Backbone
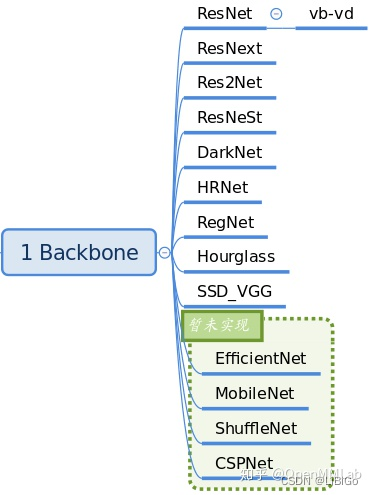
backbone 作用主要是特征提取。目前 MMDetection 中已经集成了大部分骨架网络,具体见文件:mmdet/models/backbones,V2.7 已经实现的骨架如下:
__all__ = [
'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SSDVGG', 'HRNet', 'Res2Net',
'HourglassNet', 'DetectoRS_ResNet', 'DetectoRS_ResNeXt', 'Darknet',
'ResNeSt', 'TridentResNet'
]
最常用的是 ResNet 系列、ResNetV1d 系列和 Res2Net 系列。若需要对backbone 进行扩展,继承上述网络的情况下,通过注册器机制注册使用。
# 典型用法为
# 骨架的预训练权重路径
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet', # 骨架类名,后面的参数都是该类的初始化参数
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
在mmdetection中,可以通过 MMCV 中的注册器机制,可以通过 dict 形式的配置来实例化任何已经注册的类,非常方便和灵活。
3.2 Neck
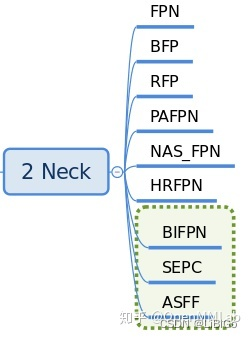
neck 部位: backbone 和 head 的连接层,对 backbone 的特征进行高效融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等。具体见文件mmdet/models/necks,其V2.7 已经实现的 neck 如下:
__all__ = [
'FPN', 'BFP', 'ChannelMapper', 'HRFPN', 'NASFPN', 'FPN_CARAFE', 'PAFPN',
'NASFCOS_FPN', 'RFP', 'YOLOV3Neck'
]
最常用的应该是 FPN,一个典型用法是:
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 骨架多尺度特征图输出通道
out_channels=256, # 增强后通道输出
num_outs=5), # 输出num_outs个多尺度特征图
3.3 Head
目标检测算法输出一般包括分类和框坐标回归两个分支,不同算法 head 模块复杂程度不一样,灵活度比较高。在网络构建方面,理解目标检测算法主要是要理解 head 模块。
MMDetection 中 head 模块又划分为 two-stage 所需的 RoIHead 和 one-stage 所需的 DenseHead,也就是说所有的 one-stage 算法的 head 模块都在mmdet/models/dense_heads中,而 two-stage 算法还包括额外的mmdet/models/roi_heads。
目前 V2.7 中已经实现的 dense_heads 包括:
__all__ = [
'AnchorFreeHead', 'AnchorHead', 'GuidedAnchorHead', 'FeatureAdaption',
'RPNHead', 'GARPNHead', 'RetinaHead', 'RetinaSepBNHead', 'GARetinaHead',
'SSDHead', 'FCOSHead', 'RepPointsHead', 'FoveaHead',
'FreeAnchorRetinaHead', 'ATSSHead', 'FSAFHead', 'NASFCOSHead',
'PISARetinaHead', 'PISASSDHead', 'GFLHead', 'CornerHead', 'YOLACTHead',
'YOLACTSegmHead', 'YOLACTProtonet', 'YOLOV3Head', 'PAAHead',
'SABLRetinaHead', 'CentripetalHead', 'VFNetHead', 'TransformerHead'
]
几乎每个算法都包括一个独立的 head,而 roi_heads 比较杂,就不列出了。
需要注意的是:two-stage 或者 mutli-stage 算法,会额外包括一个区域提取器 roi extractor,用于将不同大小的 RoI 特征图统一成相同大小。
虽然 head 部分的网络构建比较简单,但是由于正负样本属性定义、正负样本采样和 bbox 编解码模块都在 head 模块中进行组合调用,故 MMDetection 中最复杂的模块就是 head。在最后的整体流程部分会对该模块进行详细分析。
3.4 Enhance
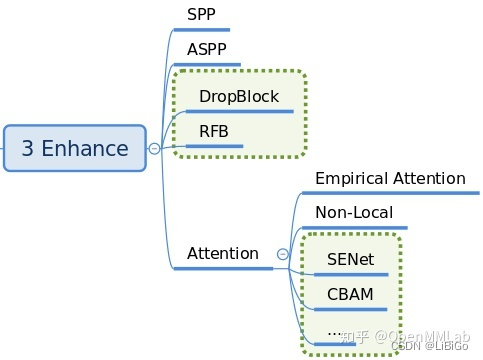
enhance 是即插即用、能够对特征进行增强的模块,其具体代码可以通过 dict 形式注册到 backbone、neck 和 head 中,非常方便(目前还不完善)。
常用的 enhance 模块是 SPP、ASPP、RFB、Dropout、Dropblock、DCN 和各种注意力模块 SeNet、Non_Local、CBA 等。
目前 MMDetection 中部分模块支持 enhance 的接入,例如 ResNet 骨架中的 plugins,这个部分的解读放在具体算法模块中讲解。
3.5 BBox Assigner
正负样本属性分配模块作用是进行正负样本定义或者正负样本分配(可能也包括忽略样本定义),正样本就是常说的前景样本(可以是任何类别),负样本就是背景样本。
因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。该模块至关重要,不同的正负样本分配策略会带来显著的性能差异,目前大部分目标检测算法都会对这个部分进行改进,至关重要。
典型的分配策略如下:
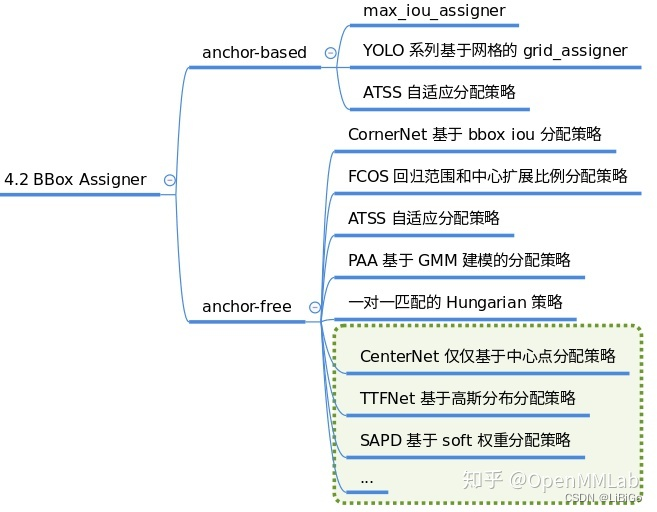
对应的代码在mmdet/core/bbox/assigners中,V2.7 主要包括:
__all__ = [
'BaseAssigner', 'MaxIoUAssigner', 'ApproxMaxIoUAssigner',
'PointAssigner', 'ATSSAssigner', 'CenterRegionAssigner', 'GridAssigner',
'HungarianAssigner'
]
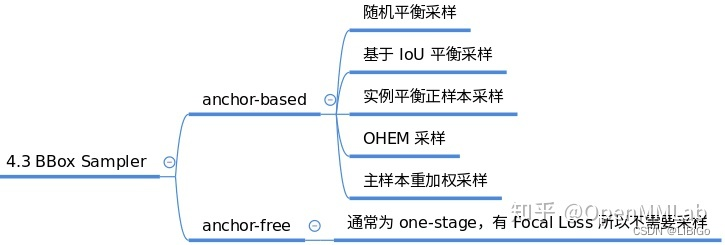
3.9 BBox Sampler
在确定每个样本的正负属性后,可能还需要进行样本平衡操作。
本模块作用是对前面定义的正负样本不平衡进行采样,力争克服该问题。一般在目标检测中 gt bbox 都是非常少的,所以正负样本比是远远小于 1 的。
而基于机器学习观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的,一些典型采样策略如下:
__all__ = [
'BaseSampler', 'PseudoSampler', 'RandomSampler',
'InstanceBalancedPosSampler', 'IoUBalancedNegSampler', 'CombinedSampler',
'OHEMSampler', 'SamplingResult', 'ScoreHLRSampler'
]
3.10 BBox Encoder
为了更好的收敛和平衡多个 loss,具体解决办法非常多,而 bbox 编解码策略也算其中一个,bbox 编码阶段对应的是对正样本的 gt bbox 采用某种编码变换(反操作就是 bbox 解码),最简单的编码是对 gt bbox 除以图片宽高进行归一化以平衡分类和回归分支,一些典型的编解码策略如下:

对应的代码在mmdet/core/bbox/coder中,V2.7 主要包括:
__all__ = [
'BaseBBoxCoder', 'PseudoBBoxCoder', 'DeltaXYWHBBoxCoder',
'LegacyDeltaXYWHBBoxCoder', 'TBLRBBoxCoder', 'YOLOBBoxCoder',
'BucketingBBoxCoder'
]
3.11 Loss
Loss 通常都分为分类和回归 loss,其对网络 head 输出的预测值和 bbox encoder 得到的 targets 进行梯度下降迭代训练。
Loss 的设计也是各大算法重点改进对象,常用的 loss 如下:

对应的代码在mmdet/models/losses中,V2.7 主要包括:
__all__ = [
'cross_entropy', 'binary_cross_entropy',
'mask_cross_entropy', 'CrossEntropyLoss', 'sigmoid_focal_loss',
'FocalLoss', 'smooth_l1_loss', 'SmoothL1Loss', 'balanced_l1_loss',
'BalancedL1Loss', 'mse_loss', 'MSELoss', 'iou_loss', 'bounded_iou_loss',
'IoULoss', 'BoundedIoULoss', 'GIoULoss', 'DIoULoss', 'CIoULoss', 'GHMC',
'GHMR', 'reduce_loss', 'weight_reduce_loss', 'weighted_loss', 'L1Loss',
'l1_loss', 'isr_p', 'carl_loss', 'AssociativeEmbeddingLoss',
'GaussianFocalLoss', 'QualityFocalLoss', 'DistributionFocalLoss',
'VarifocalLoss'
]
可以看出 MMDetection 中已经实现了非常多的 loss,可以直接使用。
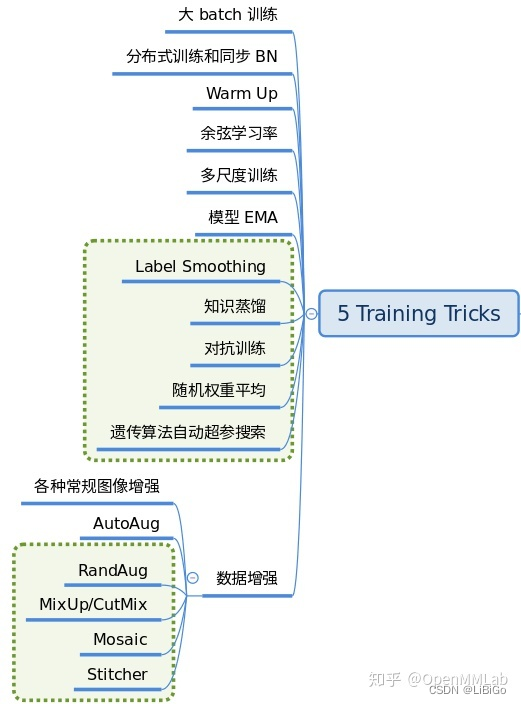
3.12 Training tricks
训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的 tricks 如下所示:
MMDetection 目前这部分还会继续完善,也欢迎大家一起贡献。
4 detection测试核心组件
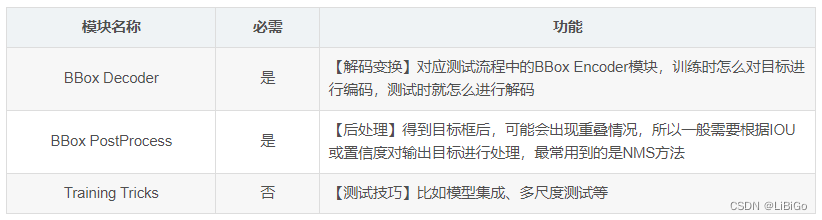
测试核心组件和训练非常类似,但是简单很多,除了必备的网络构建部分外( backbone、neck、head 和 enhance ),不需要正负样本定义、正负样本采样和 loss 计算三个最难的部分,但是其额外需要一个 bbox 后处理模块和测试 trick。
相较于训练流程,测试时只有模型的前向推理过程,因此不需要正负样本分配、平衡、计算loss等操作,流程会更简单一些。
下表是测试流程特有的模块:
4.1 BBox Decoder
训练时候进行了编码,那么对应的测试环节需要进行解码。根据编码的不同,解码也是不同的。举个简单例子:假设训练时候对宽高是直接除以图片宽高进行归一化的,那么解码过程也仅仅需要乘以图片宽高即可。
其代码和 bbox encoder 放在一起,在mmdet/core/bbox/coder中。
4.2 BBox PostProcess
在得到原图尺度 bbox 后,由于可能会出现重叠 bbox 现象,故一般都需要进行后处理,最常用的后处理就是非极大值抑制以及其变种。
其对应的文件在mmdet/core/post_processing中,V2.7 主要包括:
__all__ = [
'multiclass_nms', 'merge_aug_proposals', 'merge_aug_bboxes',
'merge_aug_scores', 'merge_aug_masks', 'fast_nms'
]
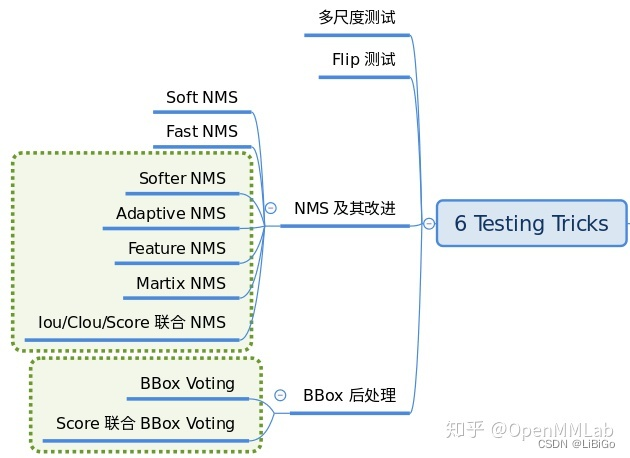
4.3 Testing tricks
为了提高检测性能,测试阶段也会采用 trick。这个阶段的 tricks 也非常多,难以完全统一,最典型的是多尺度测试以及各种模型集成手段,典型配置如下:
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=True,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
4.4 训练测试算法流程
在分析完每个训练流程的各个核心组件后,为了方便大家理解整个算法构建,下面分析 MMDetection 是如何组合各个组件进行训练的,这里以 one-stage 检测器为例,two-stage 也比较类似。
class SingleStageDetector(---):
def __init__(...):
# 构建骨架、neck和head
self.backbone = build_backbone(backbone)
if neck is not None:
self.neck = build_neck(neck)
self.bbox_head = build_head(bbox_head)
def forward_train(---):
# 先运行backbone+neck进行特征提取
x = self.extract_feat(img)
# 对head进行forward train,输出loss
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
def simple_test(---):
# 先运行backbone+neck进行特征提取
x = self.extract_feat(img)
# head输出预测特征图
outs = self.bbox_head(x)
# bbox解码和还原
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale)
# 重组结果返回
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in bbox_list
]
return bbox_results
以上就是整个检测器算法训练和测试最简逻辑,可以发现训练部分最核心的就是bbox_head.forward_train,测试部分最核心的是bbox_head.get_bboxes,下面单独简要分析。
5 训练部分与测试部分的两个核心算法
5.1 训练部分 bbox_head.forward_train
def forward_train(...):
# 调用每个head自身的forward方法
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 计算每个head自身的loss方法
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
# 返回
return losses
对于不同的 head,虽然 forward 内容不一样,但是依然可以抽象为: outs = self(x)
def forward(self, feats):
# 多尺度特征图,一个一个迭代进行forward_single
return multi_apply(self.forward_single, feats)
def forward_single(self, x):
# 运行各个head独特的head forward方法,得到预测图
....
return cls_score, bbox_pred...
而对于不同的 head,其 loss 计算部分也比较复杂,可以简单抽象为:losses = self.loss(...)
def loss(...):
# 1 生成anchor-base需要的anchor或者anchor-free需要的points
# 2 利用gt bbox对特征图或者anchor计算其正负和忽略样本属性
# 3 进行正负样本采样
# 4 对gt bbox进行bbox编码
# 5 loss计算,并返回
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox,...)
5.2 测试部分 bbox_head.get_bboxes
get_bboxes函数更加简单
def get_bboxes(...):
# 1 生成anchor-base需要的anchor或者anchor-free需要的points
# 2 遍历每个输出层,遍历batch内部的每张图片,对每张图片先提取指定个数的预测结果,缓解后面后处理压力;对保留的位置进行bbox解码和还原到原图尺度
# 3 统一nms后处理
return det_bboxes, det_labels...
6. 算法搭建流程
以Pytorch训练流程为例,需要编写数据读取、数据预处理、数据增强、算法模型、loss函数、训练策略的代码,最后将其整合进train()函数中开始训练。
MMDetection已经实现上述步骤中的绝大部分方法,因此只需要调用现成的函数即可,具体是在Config文件中配置好相应方法的参数,并将Config文件传给MMDetection自带的train()函数,然后框架就会解析Config文件,自动调用配置好的方法,完成训练流程。
所以在MMDetection上搭建一个算法,要做的事情只有3件:准备数据集、编写Config文件、调用框架自带的train.py开始训练。

先从MMDetection自带的RetinaNet开始,在COCO数据集上打通训练和测试流程。
6.1 准备数据集
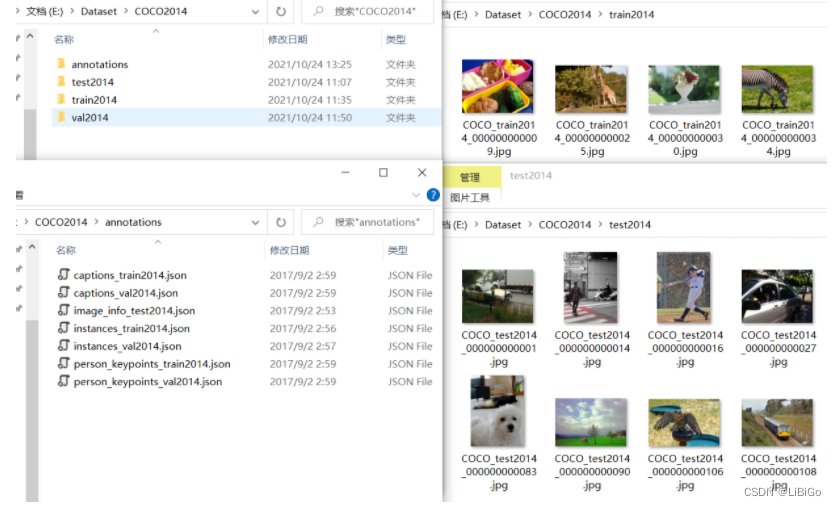
MMDetection已经实现COCO数据集的处理,这里就直接使用COCO 2014数据集。下载好的数据集目录结构如下图所示,annotations文件夹中以json文件格式存放了标注数据,其中目标框的标注信息在instances文件中:
3.2 编写Config文件
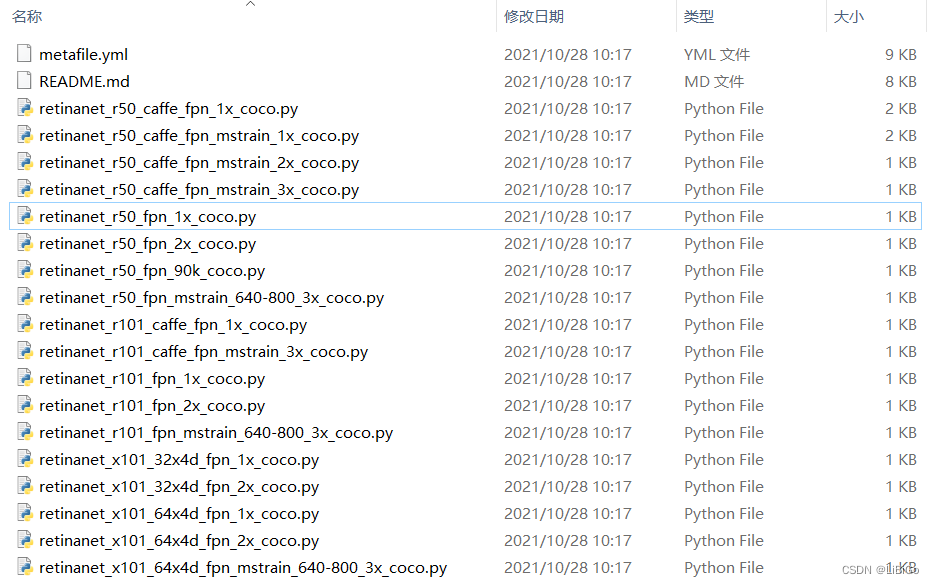
RetinaNet的配置文件位于MMDetection源码的./configs/retinanet路径下,打开目录会发现里面有很多Config文件,文件命名规则遵循:
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
其中大括号表示必选,大括号表示可选。比如我们接下来要使用的配置文件retinanet_r50_fpn_1x_coco.py含义就是:模型名称是RetinaNet,主干是ResNet50,Neck是FPN,训练12个Epoch(1个x是12,2个x就是24),使用COCO数据集。
但当打开配置文件retinanet_r50_fpn_1x_coco.py时,发现里面只有几行代码:
# 原因是MMDetection中配置文件是通过继承 + 修改的方式完成用户自定义配置文件的。
# _ base_ = list()表示需要继承的配置文件,然后通过重写的方式完成对应属性的修改。
_base_ = [
'../_base_/models/retinanet_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
如果想要查看完整的配置文件信息,不需要依据_base_一级一级往上查找,可以通过官方给定的工具./tools/misc/print_config.py来打印配置文件:
# 在 ./tools/misc/print_config.py
python ./tools/misc/print_config.py ./configs/retinanet/retinanet_r50_fpn_1x_coco.py
然后就可以看到retinanet_r50_fpn_1x_coco.py对应的完整的配置文件内容,第二节提到的各个模块都可以在配置文件中找到对应的定义。
配置文件由一串字典dict和变量的定义组成,经由Config.fromfile(filepath)函数加载后会返回一个Config类型的变量(MMCV的一个数据结构),然后MMDetection框架就能根据这个Config调用相关的build_detector()方法构建对应的模块。
build_detector()方法:首先会根据字典中的type找到对应的类(Class),这个类的类名就是type字符串的值,且这个类一定是事先注册(Registry) 好的,MMDetection能够根据type值查询到具体的类,否则就会报错。比如在下面配置文件中,model的type值为RetinaNet,我们可以在./mmdet/models/detectors/retinanet.py中找到定义。
@DETECTORS.register_module() # 表示这个类已经注册
class RetinaNet(SingleStageDetector):
"""Implementation of `RetinaNet <https://arxiv.org/abs/1708.02002>`_"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(RetinaNet, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained, init_cfg)
RetinaNet类构造函数的参数刚好和配置文件中type='RetinaNet'的字典的其他键值对应。所以build_detector()函数的作用就是根据dict中的type找到对应的类,然后使用dict中传入的参数来对类进行初始化操作,并返回这个类的句柄。
# 下面两行调用是等价的
model = build_detector(Config{type='RetinaNet', backbone=xxx, neck=xxx, bbox_head=xxx})
model = RetinaNet(backbone=xxx, neck=xxx, bbox_head=xxx)
然后配置文件中的dict是可以嵌套的,比如说model的backbone属性是type='ResNet'一个字典,同理我们也可以在./mmdet/models/backbones/resnet.py中找到ResNet类的定义,并且字典的键值和构造函数匹配:
@BACKBONES.register_module()
class ResNet(BaseModule):
"""ResNet backbone."""
def __init__(self,
depth,
in_channels=3,
stem_channels=None,
base_channels=64,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(0, 1, 2, 3),
style='pytorch',
deep_stem=False,
avg_down=False,
frozen_stages=-1,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
dcn=None,
stage_with_dcn=(False, False, False, False),
plugins=None,
with_cp=False,
zero_init_residual=True,
pretrained=None,
init_cfg=None):
super(ResNet, self).__init__(init_cfg)
self.zero_init_residual = zero_init_residual
if depth not in self.arch_settings:
raise KeyError(f'invalid depth {depth} for resnet')
下面是retinanet_r50_fpn_1x_coco.py完整的配置文件信息
Config:
# 1. 模型配置
model = dict(
type='RetinaNet', # 模型名称
# 1.1 Backbone配置
backbone=dict(
type='ResNet', # Backbone使用ResNet50(4阶段,50层)
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3), # 输出ResNet50第1~4阶段的feature map,供后续FPN做多尺度特征融合
frozen_stages=1, # 由于使用了预训练模型,冻结ResNet50第一阶段的网络参数,不参与训练过程
norm_cfg=dict(type='BN', requires_grad=True), # 归一化层配置
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), # 使用pytorch提供的ResNet50在ImageNet上的预训练模型
# 1.2 Neck配置
neck=dict(
type='FPN', # Neck使用FPN
in_channels=[256, 512, 1024, 2048], # 输入通道数对应resnet50四个阶段feature map的维度
out_channels=256, # 输出特征维度为256
start_level=1, # 从Backbone的第一阶段特征图开始
add_extra_convs='on_input',
num_outs=5),
# 1.3 Head配置
bbox_head=dict(
type='RetinaHead', # Head使用RetinaHead
num_classes=80, # COCO数据集包含80类目标
in_channels=256, # FPN层输出特征维度为256
stacked_convs=4,
feat_channels=256,
# 1.3.1 Retina是Anchor-Based方法, 需要生成Anchor
anchor_generator=dict(
type='AnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[0.5, 1.0, 2.0],
strides=[8, 16, 32, 64, 128]),
# 1.3.2 BBox Encoder配置
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
# 1.3.3 分类Loss函数
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
# 1.3.4 回归Loss函数
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
# 1.4 训练配置
train_cfg=dict(
# 1.4.1 BBox Assigner
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False),
# 1.5 测试配置
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
# 2. 数据配置
data = dict(
samples_per_gpu=2, # batch_size大小
workers_per_gpu=2, # 每个GPU的线程数, 影响dataload的速度
# 2.1 训练集配置
train=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
# 数据预处理步骤
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
# 2.2 验证集配置
val=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
# 2.3 测试集配置
test=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
# evalution hook配置
evaluation = dict(interval=1, metric='bbox')
# 优化器配置
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
# optimizer hook配置
optimizer_config = dict(grad_clip=None)
# 学习率配置
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
# Runner配置
runner = dict(type='EpochBasedRunner', max_epochs=12)
# checkpoint配置
checkpoint_config = dict(interval=1)
# logger hook配置
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
# 自定义hook配置
custom_hooks = [dict(type='NumClassCheckHook')]
# 分布式训练配置
dist_params = dict(backend='nccl')
# 日志级别
log_level = 'INFO'
# 预训练模型路径
load_from = None
# 模型断点
resume_from = None
# Runner的工作流
workflow = [('train', 1)]
从配置文件可以看到,当前默认从pytorch官网下载预训练模型,且数据集的路径以及GPU数目和我当前的不符,而且由于电脑内存有限,我不希望每个epoch都保存一次checkpoint,所以我新建了一个配置文件my_retinanet_r50_fpn.py继承了官方的配置文件,并进行了一些修改:
_base_ = [
'D:/Program Files/OpenSourceLib/mmdetection/configs/retinanet/retinanet_r50_fpn_1x_coco.py'
]
model = dict(
backbone=dict(
init_cfg=None) # 不再直接从官网下载预训练模型,使用我自己下载好的预训练模型
)
data = dict(
samples_per_gpu=2, # batch_size=2
workers_per_gpu=1, # 每个GPU的线程数, 影响dataload的速度
train=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_train2014.json', # 修改数据集路径
img_prefix='E:/Dataset/COCO2014/train2014'),
val=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_val2014.json',
img_prefix='E:/Dataset/COCO2014/val2014/'),
test=dict(
type='CocoDataset',
ann_file='E:/Dataset/COCO2014/annotations/instances_val2014.json',
img_prefix='E:/Dataset/COCO2014/val2014/')
)
evaluation = dict(interval=12, metric='bbox') # 12个epoch进行一次评估
checkpoint_config = dict(interval=2) # 2个epoch保存一次checkpoint
load_from = '../ckpts/resnet50-0676ba61.pth' # 自己下载的预训练模型路径
6.3 训练网络
写完配置文件后,就可以直接调用./tools/train.py指定配置文件进行训练。train.py包含了模型配置、数据集配置、训练配置、Hook配置等的解析,以及根据配置信息构造训练,用户的自定义操作可以通过Hook进行配置,一般无需修改train.py文件。
python train.py my_retinanet_r50_fpn.py
成功开始训练:

7.总结
本文利用MMDetection已经实现的RetinaNet模型在COCO上进行训练作为示例,演示了MMDetection的模型训练流程。总的来说分为三个步骤:
1、准备数据集
2、准备配置文件:配置文件由一系列dict组成,dict中的type键值代表注册的类别,build函数可以通过识别dict中的type来初始化对应的类。配置文件一般会继承一个通用配置文件,然后在此基础上根据需求调整。
3、开始训练:调用MMDetection自带的train.py进行训练。
如果需要构建自己的模型,则需要实现一个类然后进行注册,Registry和Hook的机制。

![第四章 vi和vim 编辑器-[实操篇]](https://img-blog.csdnimg.cn/02afdab6666d4d6bb964194c2bd6c5b6.png)